






目录
一、导入数据
import pandas
data=pandas.read_csv('决策树.csv',
engine='python',encoding='utf8')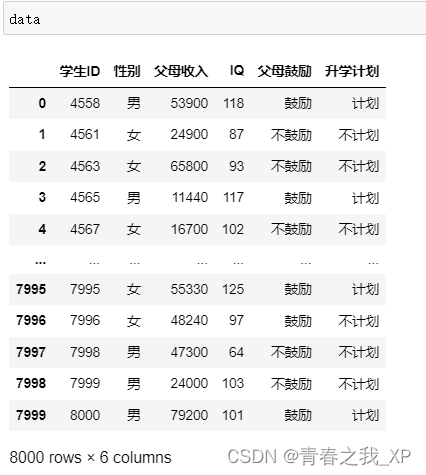
二、进行独热编码
#需要进行独热处理的列
oneHotColumns = ['性别','父母鼓励']from sklearn.preprocessing import OneHotEncoder
#新建独热编码器
oneHotEncoder = OneHotEncoder(drop='first')
#训练独热编码器,得到转换规则
oneHotEncoder.fit(data[oneHotColumns])
#转换数据
oneHotData = oneHotEncoder.transform(data[oneHotColumns])from scipy.sparse import hstack
#将独热编码所得的数据,和父母收入、IQ两列合并在一起
x=hstack([oneHotData, data.父母收入.values.reshape(-1,1),data.IQ.values.reshape(-1,1)])
y=data['升学计划']三、通过网格搜索进行参数调优,选择最优参数
from sklearn.model_selection import GridSearchCV
#全部训练全部测试,会导致过拟合
'''
max_depth=None,
max_leaf_nodes=None,
'''
dtModel = DecisionTreeClassifier()
dtModel.fit(x, y)
dtModel.score(x, y)
dtModel = DecisionTreeClassifier()
#网格搜索,寻找最优参数
paramGrid = dict(
max_depth=[1, 2, 3, 4, 5],
max_leaf_nodes=[3, 5, 6, 7, 8],
)
dtModel = DecisionTreeClassifier()
grid = GridSearchCV(
dtModel, paramGrid, cv=10,
return_train_score=True
)
grid = grid.fit(x, y)
print('最好的得分是: %f' % grid.best_score_)
print('最好的参数是:')
for key in grid.best_params_.keys():
print('%s=%s'%(key, grid.best_params_[key]))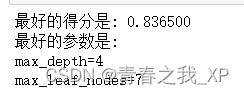
四、利用训练好的参数建立决策树模型并进行交叉验证
dtModel = DecisionTreeClassifier(
criterion='gini',
max_depth=4,
max_leaf_nodes=7
)
cross_val_score(dtModel, x, y, cv=10).mean()![]()
#训练决策树模型
dtModel = DecisionTreeClassifier(
max_depth=4,
max_leaf_nodes=7
)
dtModel.fit(x, y)五、将决策树可视化
#将决策树模型导出为 dot 文件
from sklearn.tree import export_graphviz
with open('data.dot', 'w') as f:
f = export_graphviz(dtModel, out_file=f)#绘图命令
#dot -Tpng data.dot -o tree.png
#导入pydot模块
import pydot_ng as pydot
#导入内存IO模块
#from sklearn.externals.six import StringIO
from six import StringIO
#把dot文件,写入StringIO中
dot_data = StringIO()
'''
class_names: dtModel.classes_
feature_names: oneHotEncoder.get_feature_names()
'''
export_graphviz(
dtModel,
out_file=dot_data,
class_names=["不计划", "计划"],
feature_names=[
'男性', '父母鼓励', '父母收入', '智商'
],
filled=True, rounded=True,
special_characters=True
)
#从字符串中读入dot,生成graph对象
graph = pydot.graph_from_dot_data(
dot_data.getvalue()
)
#设置所有的节点的字体属性为 Microsoft YaHei
graph.get_node("node")[0].set_fontname(
"Microsoft YaHei"
)
#将图形保存到 opt_tree.png 文件中
graph.write_png(
'opt_tree.png'
)
r = data.pivot_table(
index='父母鼓励',
columns='升学计划',
values='学生ID',
aggfunc='count'
)















 4555
4555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









