







 本文探讨了异构计算中的核心概念,包括内存管理、DMA技术在AI领域的重要性,以及Linux中进程地址空间布局、页表、kmalloc/vmalloc、缺页中断、DMA类型(如块DMA和scatter-gatherDMA)、一致性DMA和流式DMA的应用。后续章节将深入讲解线程/进程技术。
本文探讨了异构计算中的核心概念,包括内存管理、DMA技术在AI领域的重要性,以及Linux中进程地址空间布局、页表、kmalloc/vmalloc、缺页中断、DMA类型(如块DMA和scatter-gatherDMA)、一致性DMA和流式DMA的应用。后续章节将深入讲解线程/进程技术。
异构计算关键技术之内存管理与DMA(一)
诞生伊始,计算机处理能力就处于高速发展中。及至最近十年,随着大数据、区块链、AI 等新技术的持续火爆,人们为提升计算处理速度更是发展了多种不同的技术思路。大数据受惠于分布式集群技术,区块链带来了专用处理器(Application-Specific IC, ASIC)的春天,AI 则让大众听到了“异构计算”这个计算机界的学术名词。
“异构计算”(Heterogeneous computing),是指在系统中使用不同体系结构的处理器的联合计算方式。在 AI 领域,常见的处理器包括:CPU(X86,Arm,RISC-V 等),GPU,FPGA 和 ASIC。(按照通用性从高到低排序)。

本系列文章将介绍异构计算涉及到的内存管理技术、DMA技术。结合驱动开发、FPGA/ASIC PCIe DMA engine的实例代码进行详细讲解多线程、DMA scatter-gather list、PCIe TLP等核心技术。
本章将介绍核心的基本概念:主要包括进程空间、页机制、DMA类型。
一、什么是异构计算
同构计算或者说通用计算性能的发展已经远远跟不上应用的需求,如近几年的国内的天河2A和神威超算都属于异构超算,接下来几年研发的超算也都属于异构超算,可见,异构超算已经成为中美两国超算领域的趋势。
这里我们引用网上的一个经典“厨房论”异构计算。
在饭店的厨房,通常会有一个大厨(CPU),它会做各种菜(兼容性极好),但是如果做菜之前的大量重复动作(洗菜、切菜)导致它一天做菜的份数明显减少。
并且,由于最近(人工智能时代到来)客人点菜要求越来越高(花样菜式),大厨开始不堪负重。


本来顾客大多要的「炒白菜」,现在一个个都想吃「上汤娃娃菜」。
一道是家常菜,一道是国宴菜。然而后者复杂程度(大量数据复杂处理)远远不是前者所能比较。
于是,大厨想着,一大菜我一个做着麻烦,但是我可以请个帮手(协处理器)。比如在切菜方面,这个帮手可以同时处理很多菜品(并行计算),而且很熟练,速度很快(低延时)。
于是,一个负责切菜,一个负责做菜,分工明确。当然,大厨挑选这个帮手也是精挑细选,主要体现在以下方面:
1. 多样的菜品处理能力,如洗菜切菜一体化(算法性能)——协处理器需要能全面支持需要用到的场景关键算法。
2. 支持同时、快速加工(数据并行和低延时处理能力)——协处理器需要有大量并行通道,且每个通道支持低延时的数据处理。
3. 便于大厨操作和菜品存取(接口性能)——和主处理器很方便的数据交互
4. 学习能力强,新菜式也能学会(配置灵活)——协处理器可以针对计算需求升级迭代
5. 一天别吃太多(功耗低)——协处理器更低的功耗意味着更低的运行成本,更小的空间占用和更简单的热处理方案。
就这样,我们将一个复杂的工作(做菜)分解成了适合各个processor(工人师傅)任务,最后我们再把他们的结果(成品)封装一下即可(成品)。
二、进程地址空间布局
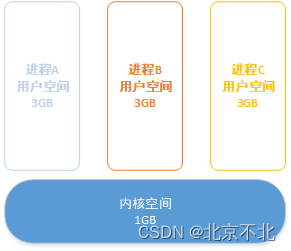
在Linux中每个进程都拥有独立的虚拟地址空间,每个虚拟地址空间都可以认为自己拥有全部内存,比如32位系统中的进程就认为自己拥有4GB的内存。
Linux把一个进程空间中划分为用户空间和内核空间两段。在32位系统中给用户空间划分3GB,给内核空间划分1GB;64位系统中其实目前只用了48位,用户空间和内核空间平分256TB(从4.11内核开始扩展到57位)。
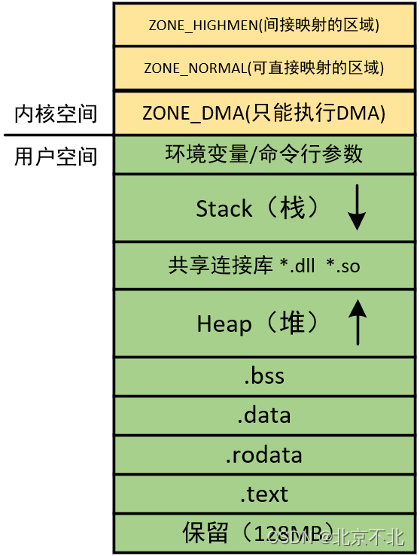
.text段存放二进制代码;
.rodata段存放只读数据,例如const和char *字符串;
.data段存放已初始化的全局变量;
.bss段存放未初始化的全局变量;
Heap是堆内存,向高地址生长,由malloc函数分配,free函数释放;
*.dll、*.so存放运行时的共享库,例如动态编译使用printf的程序,运行时会调用这里存放的库文件;
Stack是栈内存,向低地址生长,函数跳转的现场保护、局部变量、一些中断现场保护等数据存放在栈中。
想看这些段的话可以去linux中写个C程序,编译后再反汇编就能看见了。
虚拟地址:
即使是现代操作系统中,内存依然是计算机中很宝贵的资源,看看你电脑几个T固态硬盘,再看看内存大小就知道了。
为了充分利用和管理系统内存资源,Linux采用虚拟内存管理技术,利用虚拟内存技术让每个进程都有4GB互不干涉的虚拟地址空间。
进程初始化分配和操作的都是基于这个「虚拟地址」,只有当进程需要实际访问内存资源的时候才会建立虚拟地址和物理地址的映射,调入物理内存页。
打个不是很恰当的比方,这个原理其实和现在的某某网盘一样。假如你的网盘空间是1TB,真以为就一口气给了你这么大空间吗?那还是太年轻,都是在你往里面放东西的时候才给你分配空间,你放多少就分多少实际空间给你,但你和你朋友看起来就像大家都拥有1TB空间一样。
虚拟地址的好处:
- 避免用户直接访问物理内存地址,防止一些破坏操作,保护系统;
- 每个进程都被分配了4GB的虚拟内存,用户应用程序可使用比实际物理内存更大的地址空间;
4GB的进程虚拟地址空间被分成两部分:“用户空间”和“内核空间”。
物理地址:
不管是用户空间还是内核空间,使用的都是虚拟地址(逻辑地址),当需进程要实际访存的时候,就由内核的“请求分页机制”,产生“缺页异常”调入物理内存页。
把虚拟地址转换成内存的物理地址,这中间涉及利用MMU 内存管理单元(Memory Management Unit)对虚拟地址分段和分页(段页式)地址转换。

三、页表概述
带有MMU的处理器访存过程主要是通过页表来联系虚拟地址和物理地址。页表是内存中的一片供MMU访问的空间,每个进程都有一个自己页表,用来把自己进程的虚拟地址映射到真正的内存中。
页表以页为单位管理,MMU也以页为单位进行映射。虚拟地址空间和内存都是分页的,一页大小为4KB(4K边界是这么来的)。以32位地址为例,高20位是页号,用于索引页面、低12位是页内偏移,用于找到页内要访问的那个存储单元。如下图所示:
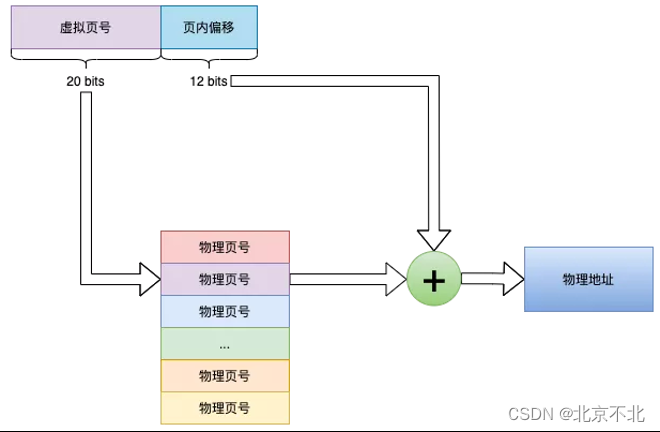
不过都不用上面这种页表,算一笔账啊,一个页表项4Byte,这个页表有2^20项,那就是4MB,这还是一个进程的,而整个物理内存才4GB,显然开销太大了。所以实际应用中都采用多级页表,比如64位的Linux用的四级页表,多级页表的优点是节省空间,因为并不是所有进程的所有虚拟地址都会被用到,没有用到的虚拟地址没有必要建立虚拟地址到物理地址之间的映射关系;缺点是级数多,查找慢,所以才引入了TLB缓存。
四、kmalloc和vmalloc
kmalloc和vmalloc是Linux内核提供的两个在内核空间分配内存的API。
kmalloc能够分配物理地址连续的内存空间,然后把这片内存空间的首地址映射为虚拟地址返回给内核空间,不过kmalloc因为要求物理地址连续,所以仅用于分配比较小的内存空间,比如结构体等。随着系统运行时间的越来越长,内存碎片越来越多,kmalloc有分配失败的可能。
vmalloc是分配虚拟地址连续的api,但是物理地址不一定连续,用于分配大的内存空间。不过vmalloc分配的内存用起来效率不高,Linux社区不太推荐用它。
五、缺页中断概述
我们上面提到:当需进程要实际访存的时候,就由内核的“请求分页机制”,产生“缺页异常”调入物理内存页。
页表中记录着已经分配空间的物理地址和虚拟地址间的映射关系,但如果虚拟地址空间中存在一个没有被真正分配物理内存的虚拟地址,那么访问这个虚拟地址时MMU无法找到对应的物理地址,这时MMU会向CPU抛出一个异常,即缺页中断。
比如上一小节说的kmalloc函数,在调用kmalloc时,系统首先会在虚拟地址空间中分配一段虚拟空间,此时还没有分配对应的物理空间,然后访问这个虚拟空间,此时MMU找不到对应的物理地址,向CPU产生一个缺页中断,然后在缺页中断里才真正地分配物理内存并建立映射关系。
SGDMA是分配多个连续的物理内存块,用链表联系起来,把它们当成一块内存用,优点是不用要求大片物理地址连续,故能进行大批量数据传输;而且SGDMA因为有链表,所以当链表所表述的所有内存块全传输完了才会发中断,一批传输只要中断一次(指的是数据传输完成中断)。
SGDMA虽然牛,但Block DMA也不是完全没用,比如PCIe的SGDMA应用中,传输SG链表的缓冲区用的就是Block DMA(因为SG链表用的空间不大),而传输数据的那部分缓冲区用的才是SGDMA,所以SGDMA的使用其实离不开BDMA!
六、DMA类型
DMA分为块DMA(Block DMA)和分散/聚集式DMA(Scatter-Gather DMA)。
Block DMA就是分配一个连续的物理内存块,然后进行DMA,缺点是要求物理地址连续,很难分出来较大的块;而且如果想要传输多个内存块的数据,需要每DMA完一个块处理一次中断,响应中断可是很麻烦的!
七、一致性DMA和流式DMA
DMA是直接内存存取,也就是DMA控制器是直接操作内存的,而CPU直接可见的存储器是Cache,若DMA控制器改写完内存数据后CPU直接去读那片内存,其实读到的是Cache中的老数据,新数据已经被DMA改了,这个称为DMA一致性问题,解决问题的方法有两种:
关了Cache直接读内存;
DMA结束后刷新Cache。
一致性DMA用的是第一种—关了cache,直接读内存,为一致性DMA分配缓冲区时,这片缓冲区会在页表中被标记上不带Cache,CPU访问时就从主存中去读取了。上节说的BDMA就是一致性DMA。
流式DMA用的是第二种,有两种情况:
1. 从内存向外设DMA传输:首先CPU将要传的数据写入Cache,然后Cache把数据刷新进内存,再用内存进行DMA。
2. 从外设向内存DMA传输:CPU设置目标内存缓冲区对应的Cache line为脏数据(设置Cache上的dirty bit),就是无效数据,CPU下次访问这个Cache line时会从主存中重新刷进来。
上一小节里的SGDMA就属于流式DMA。
那么一致性DMA和流式DMA都在什么情景下用呢?
为什么实验室端系统的PCIe使用一致性DMA来缓存SG链表呢而不把它也换成SGDMA呢?
如果CPU和DMA要频繁地操作一块固定的内存区域,那么这个区域用一致性DMA比较好,因为这个内存块老进行DMA,如果用流式DMA的话每进行一次DMA就得刷一次Cache,刷新Cache很耗时间的,尤其是大片地刷。
八、Linux中建立一致性DMA
物理地址、虚拟地址和总线地址的关系:
物理地址就是内存的物理地址;
虚拟地址就是虚拟空间的地址;
总线地址指的是总线内部的地址,就像PCIe有它自己的总线地址,PCIe发起TLP请求时目的地址都是总线地址,是由**RC**映射成**物理地址**后才能写进内存的。
Linux提供了建立一致性DMA的API,dma_alloc_coherent,其声明如下:
/**
* Allocate DMA-coherent memory space and return both the kernel remapped
* virtual and bus address for that space.
*/
void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *handle, gfp_t gfp)
{
...
}
这个API有两个返回地址:
1. 一个是void*型的返回值,它返回的是一致性DMA缓冲区映射到内核空间的虚拟首地址,方便驱动程序向缓冲区里写描述符;
2. 另一个返回地址就是dma_addr_t*类型的指针,dma_addr_t是Linux中定义的总线地址类型(注意是总线地址不是物理地址),这个地址是一致性缓冲区在总线上的首地址,这是给外面的设备用的,万不能在驱动中访问这个地址
参数*dev是4.6节中说的device结构体指针,指向设备;
参数size是缓冲区大小,真正的大小是2^size字节;
flag是选择分配空间如果不足时怎么办,填宏GFP_ATOMIC是不阻塞等待,填GFP_KERNEL是阻塞等待。
Linux也为PCI设备驱动提供了分配一致性DMA的API,pci_alloc_consistent,定义如下:
static inline void *
pci_alloc_consistent(struct pci_dev *hwdev, size_t size,
dma_addr_t *dma_handle)
{
return dma_alloc_coherent(hwdev == NULL ? NULL : &hwdev->dev, size, dma_handle, GFP_ATOMIC);
}
可见,pci_alloc_consistent其实就是把dma_alloc_coherent又封装了一下,调用时填入pci_dev结构体指针就好了,flag被强制设为GFP_ATOMIC,即空间不足时不阻塞。
九、Linux中建立SGDMA
SG缓冲区是一个一个不连续的内存块,但块内是物理地址连续的,每个内存块是以页为单位的,如下图所示:
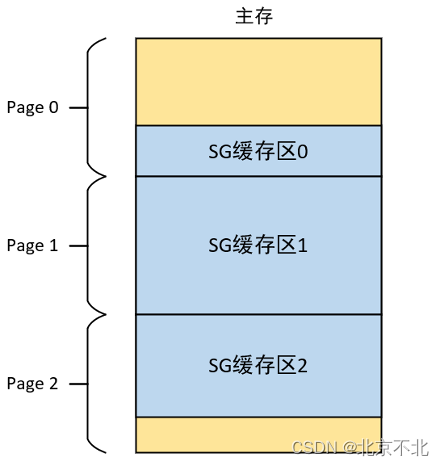
每个SG缓存块都在其所属的页内,所以想要获得一个SG缓存块需要知道页号、页内偏移(SG块的首地址)和SG缓存块长度。
Linux为SG缓存块提供了一个描述类型,即scatterlist结构体,其定义如下:
struct scatterlist {
#ifdef CONFIG_DEBUG_SG
unsigned long sg_magic;
#endif
unsigned long page_link;
unsigned int offset;
unsigned int length;
dma_addr_t dma_address;
#ifdef CONFIG_NEED_SG_DMA_LENGTH
unsigned int dma_length;
#endif
};
page_link指示该SG缓存块所在的页面;
offset为页内偏移;
length为SG缓存块的长度;
dma_address是该内存块的实际起始地址(已经映射为总线地址);
dma_length是对应的长度信息(也是给DMA用的)。
一个scatterlist结构体变量只是描述了一个SG缓存块,如果想描述整个SG缓冲区,需要定义一个scatterlist的结构体数组,数组元素都是scatterlist结构体,表示一个个缓存块。
Linux提供了包括scatterlist结构体数组的类型,即sg_table结构体,不过RIFFA驱动没有用它,而是直接定义的scatterlist结构体数组。
SG缓存块依附于页,Linux使用struct page结构体描述一个物理页面,出于节省内存的考虑,struct page中使用了大量的联合体。
十、SG缓冲区的建立流程
SG缓冲区的建立流程如下所示:
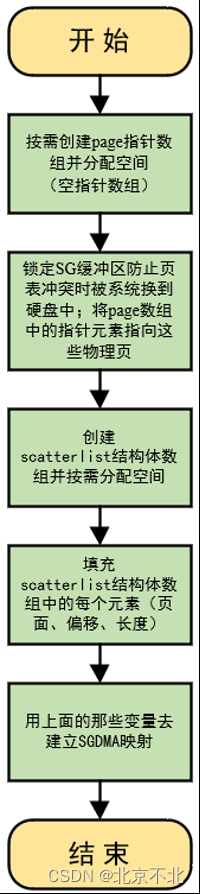
(1)首先要明白的是,所谓SG缓冲区的建立不是说去申请SG缓冲区空间,SG缓冲区本身就在内存中,为什么?
因为SG缓冲区本身就是从用户空间传进内核的一片数据,在物理地址上自然是不连续且分块的,这已经满足SG缓冲区的特征了,所以并不是去建立SG缓冲区,而是将这片已经存在的、不连续的普通内存空间变成DMA真正可用的SG缓冲区。
(2) 首先需要计算这片从用户空间传进来的数据用了多少页,然后定义跟页数一样多个数的page指针,形成一个指针数组,此时这个page指针数组是个空指针数组,即不描述任何物理页。
(3) 然后使用get_user_pages函数从SG缓冲区的虚拟首地址开始锁定这些SG缓存块所在的页,防止页表冲突时这些页被系统换出到硬盘中,都换走了那还DMA啥啊。get_user_pages函数同时能够将page数组中的指针元素指向SG缓冲区的每个物理页。此时page指针数组才真正地有用了。
(4) 创建scatterlist结构体数组并按需分配空间(数组长度和页数一致),用sg_init_table函数分配scatterlist结构体数组的长度。注意此时scatterlist结构体数组是空数组。
(5) 上一小节说到scatterlist结构体描述SG缓存块的,包含页面、页内偏移、长度等信息,Linux提供了sg_set_page函数来把这些信息存入scatterlist结构体中(遍历scatterlist结构体数组一个一个分配)。
(6) 最后调用dma_map_sg函数建立SGDMA映射,此时SGDMA的环境就建立好了。dma_map_sg函数定义在/asm/dma-mapping.h中,如下所示:
int dma_map_sg(struct device *dev, struct scatterlist *sglist,
int nents, enum dma_data_direction dir)
{
...
}
参数*dev是设备结构体;
参数*sg是scatterlist结构体数组;
参数nents是页数,也就是SG缓存块的个数;
参数direction是DMA传输方向,它是一个枚举类型变量;
常用的是DMA_TO_DEVICE(内存→外设)和DMA_FROM_DEVICE(外设→内存)。
DMA_TO_DEVICE用于PCIe的RxMEM传输、DMA_FROM_DEVICE用于PCIe的TxMEM传输。
十一、未完待续
下章将继续介绍核心的基本概念:线程/进程技术。
十二、参考文献
https://zhuanlan.zhihu.com/p/149581303
https://www.icspec.com/news/article-details/2123995


















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











