






1 Agent/Function Call 的定义
Overview of a LLM-powered autonomous agent system:
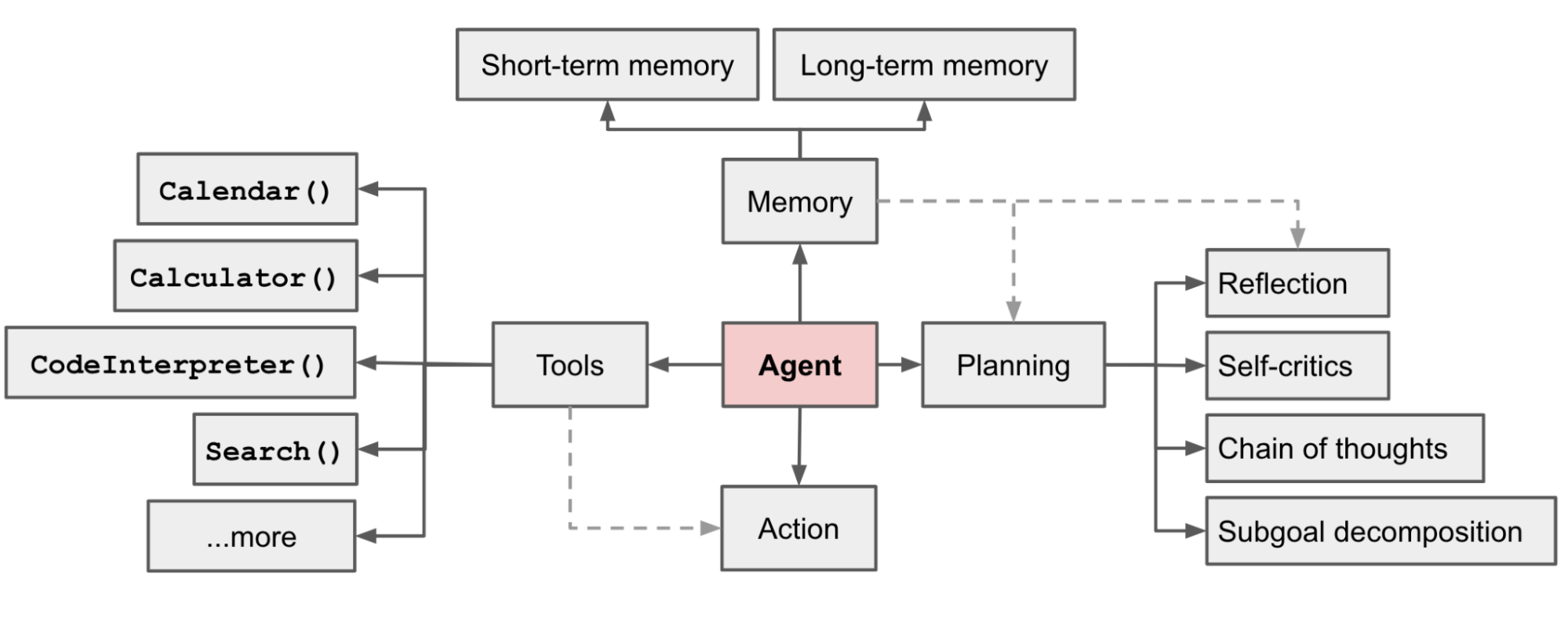
Agent学会调用外部应用程序接口,以获取模型权重中缺失的额外信息(预训练后通常难以更改),包括当前信息、代码执行能力、专有信息源访问权限等。
2 从去年到现在有什么进展?
Not a research seminar but good to know…
一些Datasets:
- 基础 Knowledge-intensive/Decision-making tasks: HotpotQA, AlfWorld Enve
- 行生 In-the-wild: Glaive-Function-Calling, InternLM/Agent-FLAN, THUDM/AgentTuning
一些Eval(NoTool/Retrieval-based/Action-based)
- Berkeley Gorilla Function Call Leaderboard, THUDM/AgentBench, CMU/WebArena
一些框架/产品/Demo:
- GPTs, Camel-Al, Modelscope-agent, Agent Hospital
优秀的工作很多,只是不完整的列举一部分
Agent 需要和现实世界的信息进行收集和交互。其核心本质严重依赖于LLM自身的Instruction Following, Complex Reasoning, Long Term Planning能力。
3 普惠智能体
- 从技术角度看,agent 是帮助人类做事的装置,提供便利、提高效率、节约成本、增加乐趣等
- 从经济角度看,agent 需要给人类提供明显的经济价值,需要可靠地执行繁琐的任务,结果精确可靠、充实、无害,并简单易用
满足普惠的 Agent 应当满足的要求:
1.能执行繁琐、繁重的任务(太轻松的任务不需要agent)。
2.能给出可靠、充实、无害的结果(错误率容忍度较低)。
3.易学易用,不需要使用说明(zero shot,不依赖于用户的prompt水平)
4.链路完整,使用场景不需要经常跳出(不能破碎)。
5.可以与外部工具和功能的交互,在没有人为干预的情况下完成多步骤的工作流程。
6.会学习与自我纠正,越用越聪明。
但现状是
智能体名词被滥用 Over promise,Under deliver:
- 简单的工具调用,本质上只是一个Instruction Following的问题
- 复杂推理 GPT4 还是爸爸(但 WebArena 依然只有不到3成的准确率)
- 给出指令并观察其执行。依然是 RPA 路线
- 简单的 demo nb,没有稳定的使用。严重依赖人工经验判断简单的
- 缺乏多模态理解,still LLM grounding (OSU Mind2Web)
- 面对缺少context和语言歧义的情况,依然会’硬答’
- 一些设计繁琐的agent产品,节约了做事的时间成本,却增加了学习成本,违背了初衷
- 甚至部分产品’图一乐’,严格意义上只能算 prompt engineering
简单易用,符合普惠对AI的想象即使名字里不带Agent,也可以是一个好产品。
4 收窄:RAG是一种信息Agent
初步认知:大模型作为信息容器
- 通过预训练注入:中高频、持久化信息(事实)
- 通过 Post Train注入:能力/套路,而不是事实
- 通过 context 注入:长尾、易变、符号化、数字化、和业务相关的数据
早期的初步认知:大模型之上
打造agent技术中,大模型并非处于最顶层,它上面还需要有针对agent的业务逻辑,称为SOP。只有SOP才能保证涉及多个步骤的agent的可靠性。SOP会生成指导大模型工作的计划planner。
RAG能增强模型context,在推理过程中增加辅助生成答案的材料(RAG),使答案更加准确、充实、贴合场景。这种素材通常通过检索实现(广义讲是一些信息agent),应满足:
- 提供LLM缺失的,和用户意图相关的素材
- 满足时间、空间等限定性要求
- 高精度的数据,精度需要高于搜索引擎提供的还需要用户筛选的内容
- 结构化的,能提供可靠的关系推演能力
- 专业的,满足产品创新需求
综上,为能打造agent,需要以大模型为中心,以数据结构化RAG为支撑(尤其是精确的结构化数据),SOP为顶层抽象一个平台。
基于这个认知的架构
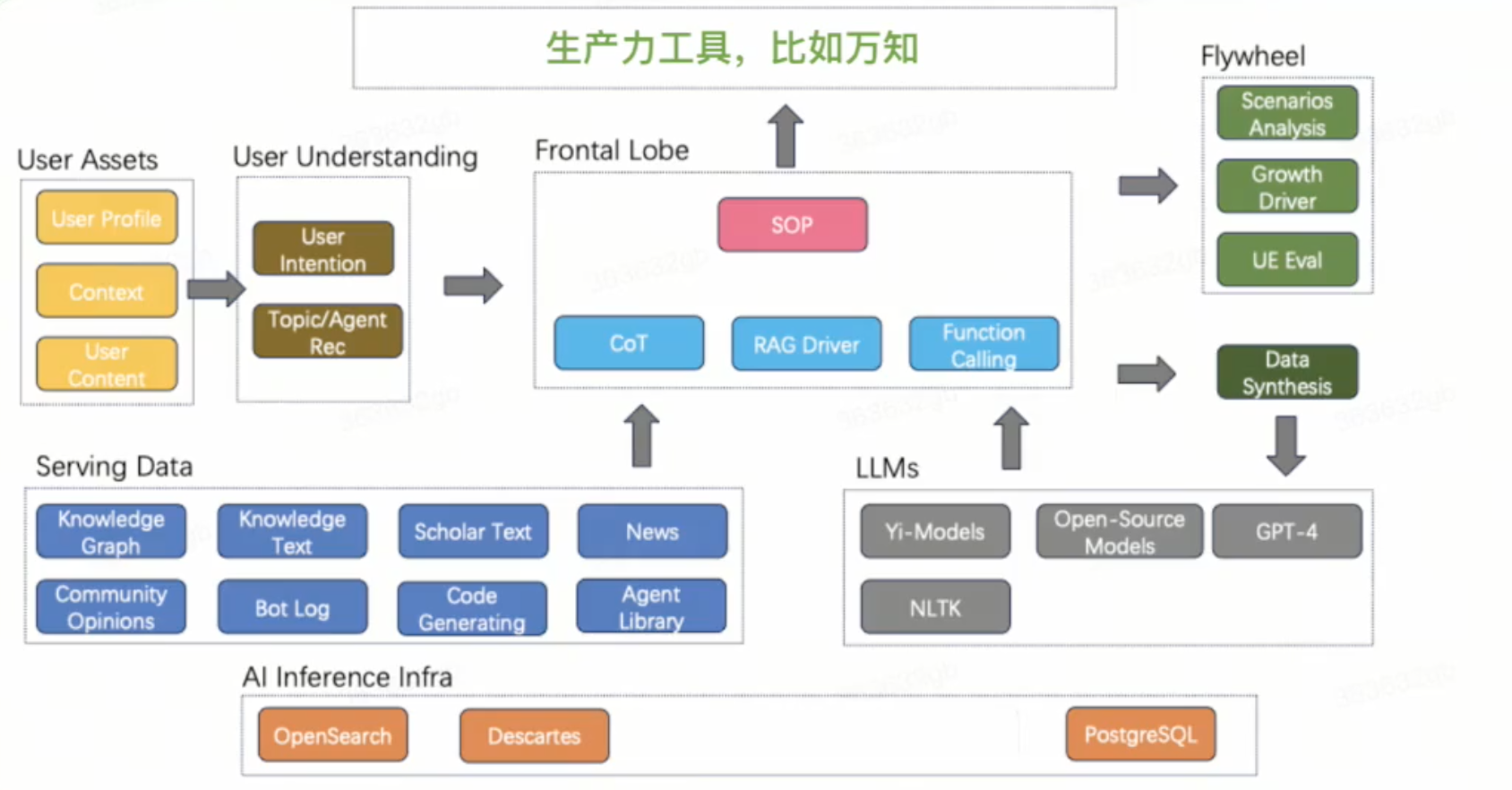
初步的技术实现
服务侧实现
- 分析用户的 prompt 和 context ,获取用户意图,表达为实体、关键词、向量
- 利用用户意图从搜索引擎/关系数据库召回相关素材
- 对素材进行相关性排序
- 对排序后的素材进行摘要(抠词)
- 将摘要作为 context 送入大模型,并生成结果
设计的算法和模型
- 用户意图分析模型
- 实体提取模型
- 句子分析和关键词提取模型
- 素材-意图相关性模型
- 高速摘要模型
数据侧实现
- 筛选优质语料,能提供事实、情节、数据等信息,精度较高
- 对语料进行预处理,切成片段
- 对片段进行结构化,提取实体、关键词、向量
- 对结构化内容进行改写,面向用户需求提取标签
需要抓取的数据
- 一般知识性数据,如百科 wiki 类
- 社区重要数据,如 twitter、知乎上的大V数据、机构数据
- 新闻源:质量和权威性很重要
- 学术文献,学术文献索引
- 产品和业务需要的数据,如ppt、ppt素材、故事情节、桥段
- 网络众投数据,如针对重点 query 的谷歌排序结果
5 好用的生产力工具
远不只一个 LLM + 搜索 API。平时搜集信息时,每人都有自己的习惯和一些相似点:
- 找政务/官宣/时效性 ->微信公众号
- 找生活攻略 ->小红书
- 看LLM相关研究->知乎/小红书/twitter
他能不能做到速度快?
他的知识深度与准确性,是否能够代替搜索引擎?
海量的优质知识文本(新闻,论文…)
分钟级索引更新,sub秒级查询相应
有效的把context控制在16k内
尽量接近大众对于AGI的想象,而不是尝试向用户解释幻觉/不擅长数学等。这听起来似乎是个 搜索推荐问题的Pro Max版本!
于是,架构又变成:
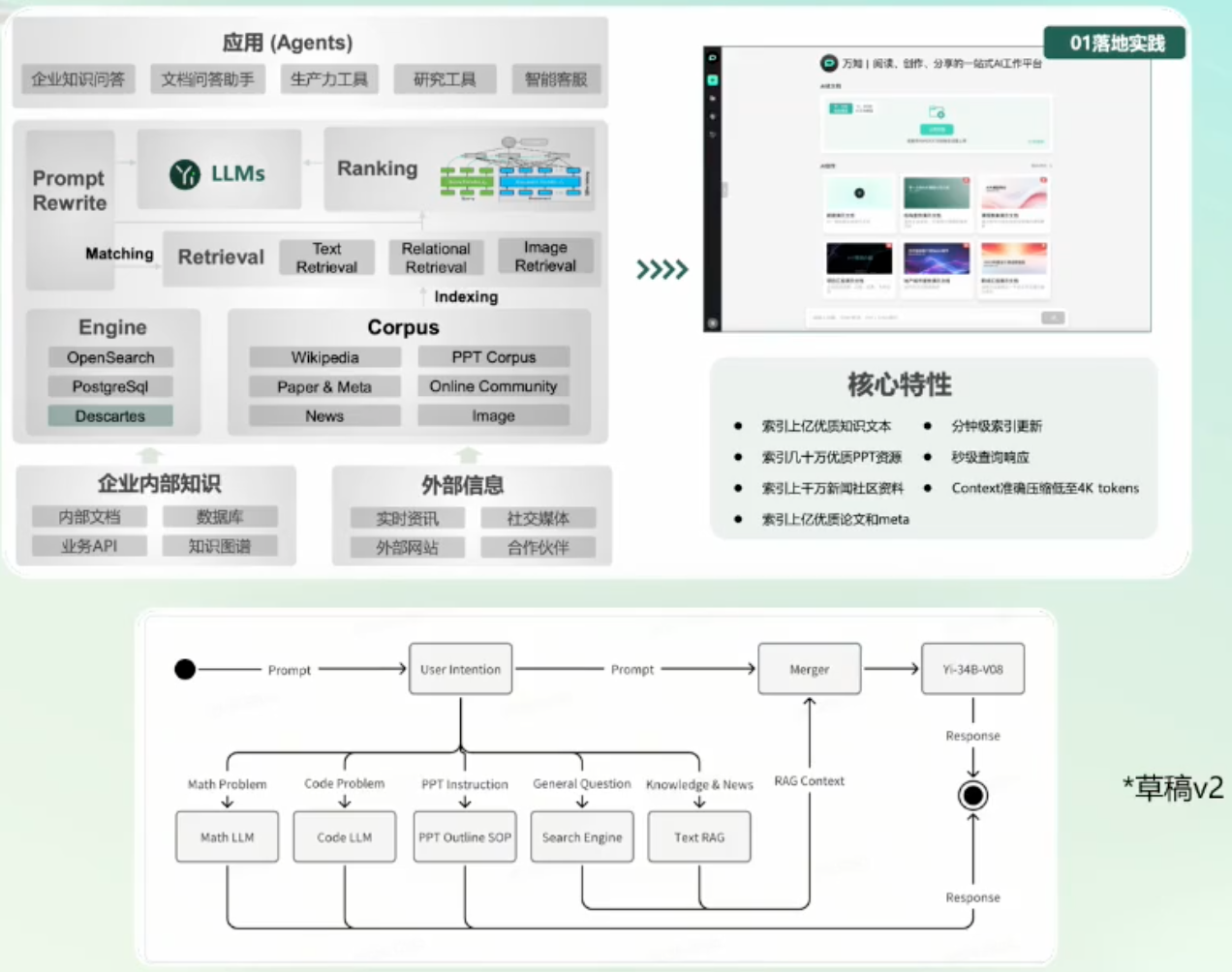
常见的用户问题类型

6 生产力场景,6种意图识别
Default:直接用 Yi 模型回答,不带RAG
知识RAG:通用知识/专业知识,百科/学术研究类数据,
新闻时事RAG:国内,国际,时政,财经,娱乐,体育,民生。并提供reference。
搜索引擎RAG:从搜索引擎获取摘要内容和网页内容,并提供reference。
Code/Math:CoT/PoT + Code Interpreter.
PPT模式:创作PPT大纲,….
得到大致架构(简易示意):
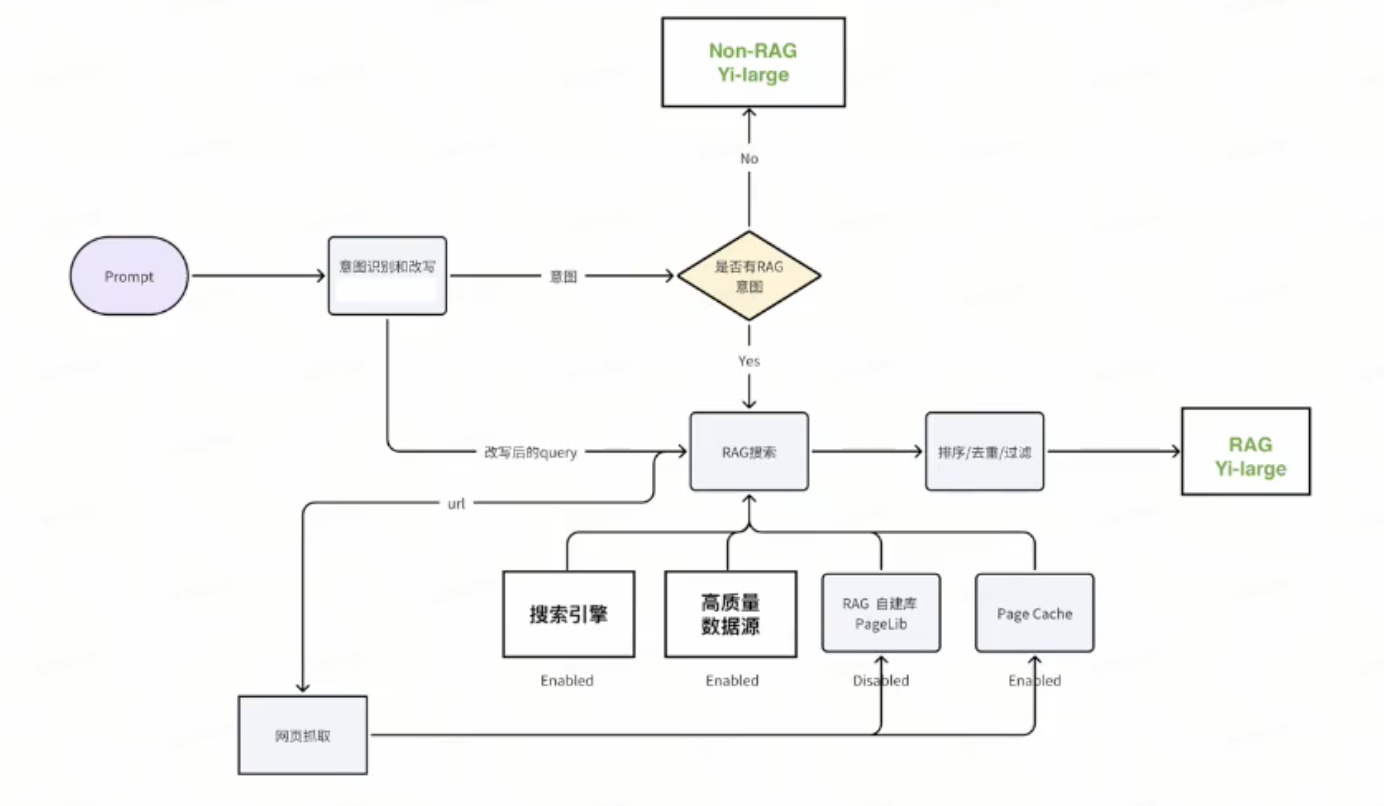
7 一些误解
Q:大模型拥有很强的能力理解用户的意图。
这点对GPT-4成立;对其他大模型,较困难!
Q:检索内容不相关时,大模型生成的内容质量也不应该变差。
大模型能分辨出内容是否相关的能力也是一个需要重点训练的能力。没有针对增强的LLM遇到不相关的检索内容,RAG结果会显著变差。
Q:高质量内容多,就能做好RAG。
内容质量不仅要高,要多,还得是用户需求的新鲜、准确、完整的内容。
Q:有了RAG就能消灭生成幻觉。
RAG确实能消除一部分幻觉,更重要的是让模型了解到它没有学过的内容,从而把无法回答的问题变得能够回答,而不是能够回答的问题回答变得更好。
8 一些弯路
通过小模型实现一个复杂的意图路由,结果将非常不准确。拆解出的用户意图通过不同技术路线实现,最后汇总成统一的聊天体验,也存在巨大挑战。
通过prompt调整通用大模型,让它能适应RAG的任务。无论生成内容的格式、内容相关性、篇幅都存在着巨大的不确定性,效果相当不稳定。
试图通过post-train对模型已有的能力进行增强,很不容易。
试图从0到1造一个搜索,直接满足RAG的需求,门槛非常高,光是索引有价值的内容一点就很难做。
结果要准,响应要快,成本要低 ->需要一个新鲜、完整的索引。但Google>Bing>自建库。
单个的信息点检索已经有不错的效果。但是回答综合性问题(比如胖猫事件始末),需要整理多方面的信息,并形成回答草稿,以供RAG回答好综合性问题。
9 多模态理解/检索/生成(以PPT为例)
利用多模态理解,对于目标文档生成完整的文字描述,理解PPT中的概念和关系。如果仅对PPT进行OCR来提取文本信息,可能丢失大量的上下文和视觉信息,导致检索结果不够准确或者缺乏深度。能够将文本和视觉信息结合起来,构建更加完整的内容表示。识别PPT之间的逻辑关系和内容流程,有助于构建知识图谱或上下文模型。
利用多模态生成,能够有效的规避版权侵权,召回图片不准,风格不统一。生成的内容与PPT的设计和布局相匹配,保持视觉一致性。
10 有了1M长文本能力,还要RAG吗?
有了大的context,就不用在检索相关性、摘要的精简准确方面做工作了。❌
1M 的context length技术上并不难达到,但需要:
- 更多的卡和推理成本
- 更慢的推理速度
- 更难从一大块文本内容中找到所需要的有效内容
所以长文本能力的提升,和RAG技术并不冲突,甚至可以互相促进。重要的是RAG提供什么内容能提升 LLM 的结果,而不是因为上下文长度不足,才不得已用RAG来截断筛选长文本信息。实验证明,不是提供的上下文越多,回答越好。更多的上下文中一定会有被遗漏的信息。所以怎样从中找到更重要的信息,压缩提供给LLM的prompt的长度,永远是值得被研究的技术,无论上下文窗口有多大。
11 FAQ
有Google搜索引擎,咋还自己搭建RAG搜索服务?
专用搜索引擎和通用搜索引擎的差异
通用搜索引擎为了保证能搜到一切,不得不容忍很多长尾的低效信息,同时在用户的特定场景中,Google并不知道场景信息。如若LLM主要针对学生或科研人员的场景中,搜索Transformer时,专用搜索引擎给出的都是学术科研相关的transformer算法或Huggingface的transformer库。但google给出的更可能是普通人更加熟悉的变形金刚相关/变压器的信息(这个例子只是示意通用搜索和专用搜索的差别,不是在讨论哪个结果是更加正确的)。
网页搜索和知识搜索的差异
真实的搜索引擎:搜索->打开链接->发现不是想要的内容->返回到搜索页面->打开新的链接->…->修改query重新搜索->.
理想的知识搜索:“我询问一个问题终于可以直接告诉我答案了。”既提供,将"google搜索+查看对应的网页内容+判断内容与问题的相关程度+自动修正query检索词”的工作打包合并后的信息。
难点:诸如幻觉、不准确、信息没有实时性等等问题,交互体验提升了,但真实使用体验依然没有办法跟有长期积累的传统搜索引擎想媲美。
更加先进的检索技术
知识搜索相比传统搜索的技术提升:
- 用户的Query改写
- 对引擎索引的内容,利用LLM生成补足更多的相关信息,包括不限于:实体提取、摘要生成生成用户可能的问题等等。这些信息都可以非常有效的提升用户搜索的精确度
- 对搜索召回的结果进行判别和加工,正常召回的是引擎中保存的原文信息,但是往往跟用户query相关的只是其中一部分的信息,甚至可能是意外召回的无关信息。有了LLM可以根据用户的query定向的对召回结果进行简单处理,提升召回结果的相关程度
和大模型Post train没关系了吧?
RAG需要SFT配合。传统LLM的SFT都是没有RAG信息的情况下,与人类进行校准。当模型可以获得RAG提供的信息后,如何更好的利用RAG的信息回答用户的问题,是需要进一步SFT的。包括RAG的流程中也还有很多需要利用LLM能力的地方,这些地方都是需要通过SFT将模型能力调整到更专业的程度,才能获得更好的效果。
但针对RAG和意图识别等进行针对性的调优,会损伤型的原有能力。
避免 cherry-pick,而是退一步优化整个大类别,否则容易按下葫芦起了瓢。
没提到向量检索 Vector-Search 啊?
Vector-Search只是在简单的本地化的RAG应用中(如针对特定文档的问答),能更便捷提供RAG能力,从而成为当下较火热的技术。Vector-Search只是一种先进的文本相似度算法,但相比一套完整搜索引擎,计算相关性仅是其中的一个子问题,甚至很多时候都不是最关键问题。
搜索引擎的完整架构至少包括:索引(索引结构、全量更新、增量更新)、QP(query理解、意图判别/类目判别、query改写)、召回、粗排、精排(rank model,静态质量分)、打散(相似的内容不需要重复出)等等。而Vector-Search只为搜索引擎的架构中提供了精排中的文本相关性信息,是不足以撑起整个引擎架构的。早期的Google搜索,对结果影响更为重要的是PageRank,这个其实就是个静态质量分。一个引擎哪怕只利用关键词召回+PageRank,其结果也往往远好于Vector-Search。
12 成功的Al-native产品需三者兼顾
模型能力
Yi-Large 模型能力优秀。100B+的稠密模型,成本较低。Yi-Large 在国际公认的榜单上取得第一梯队的良好成绩。
➋ 模型 + Infra(模基共建)
模型的训练/服务/推理设计,与底层 Infra 架构和模型结构必须高度适配
多方面优化后,实现先进的 FP8 训练框架,模型训练成本同比降幅达一倍之多
自研性能/召回率最佳的向量数据库笛卡尔Descartes*,成本只需第三方18%
零一万物与 Google、Inflection Al一起入选24年3月 NVIDIA GTC 大会 FP8 最新成功案例;
自研全导航图向量数据库,权威榜单评测 6项第一。
3 模型 + 应用(模应一体)
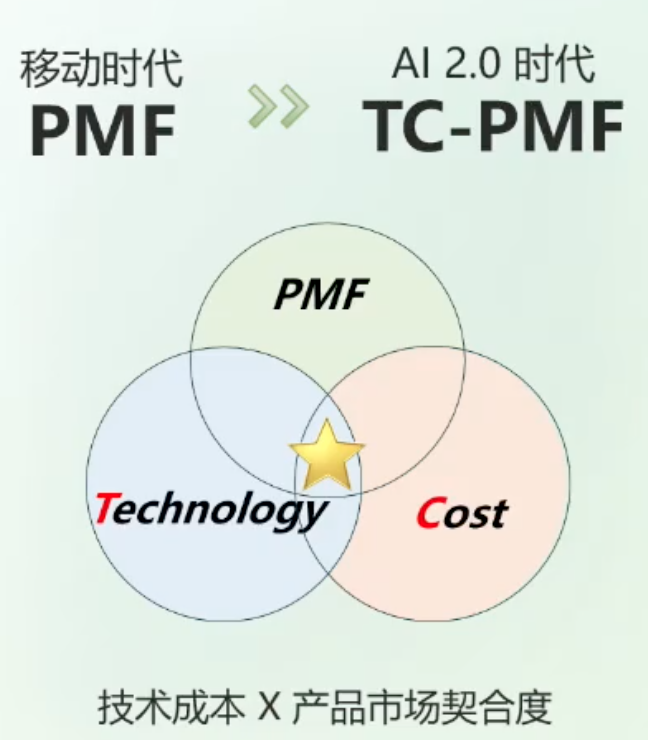
去年在海外验证 TC-PMF,以真实用户体验,和模型迭代形成正循环
多模态理解与生成,结合真实场景,解锁2C应用的创新
单一产品上线9月,用户近干万,收入1亿,ROI接近1
使用量较大的2C类AI应用聚集在欧美Saas profitability
多模态 Vision 模型:结合LLM的读文档“截图提问”创新
大模型赛道从狂奔到长跑,取决于有效实现 TC-PMF
当前任何产品要实现大规模应用,需兼顾技术路径和推理成本
基于 Scaling Law,大模型能力快速增长,超过任何技术
大模型训练和推理的成本持续大幅下降(GPT价格年内多次下调)
需要顶级模型推理能力,才能实践最佳 Al-First 应用
但有些应用会先爆发,同时要考虑推理成本和商业模式的平衡
寻找 TC-PMF 难度远远大于 PMF,是大模型行业集体的挑战与机运
持续演进的技术所创造的商用价值和推理成本均是“移动目标”
与其坐等风来,不如成为造风者。需建立基建到应用的良性 ROI
双轨模型策略
闭源探索商业化及 AI-First + 开源赋能生态
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









