







目录
2.将 VOC 格式的数据集转换为 YOLO 格式的数据集:
引言:
YOLO 是一种 实时目标检测算法,通过单次前向传播直接预测图像中所有物体的类别和位置,兼具高速度和较高精度,广泛应用于自动驾驶、安防监控、工业检测等领域。
YOLOv11作为YOLO系列的最新演进版本,其算法实现流程融合了多项前沿技术改进。
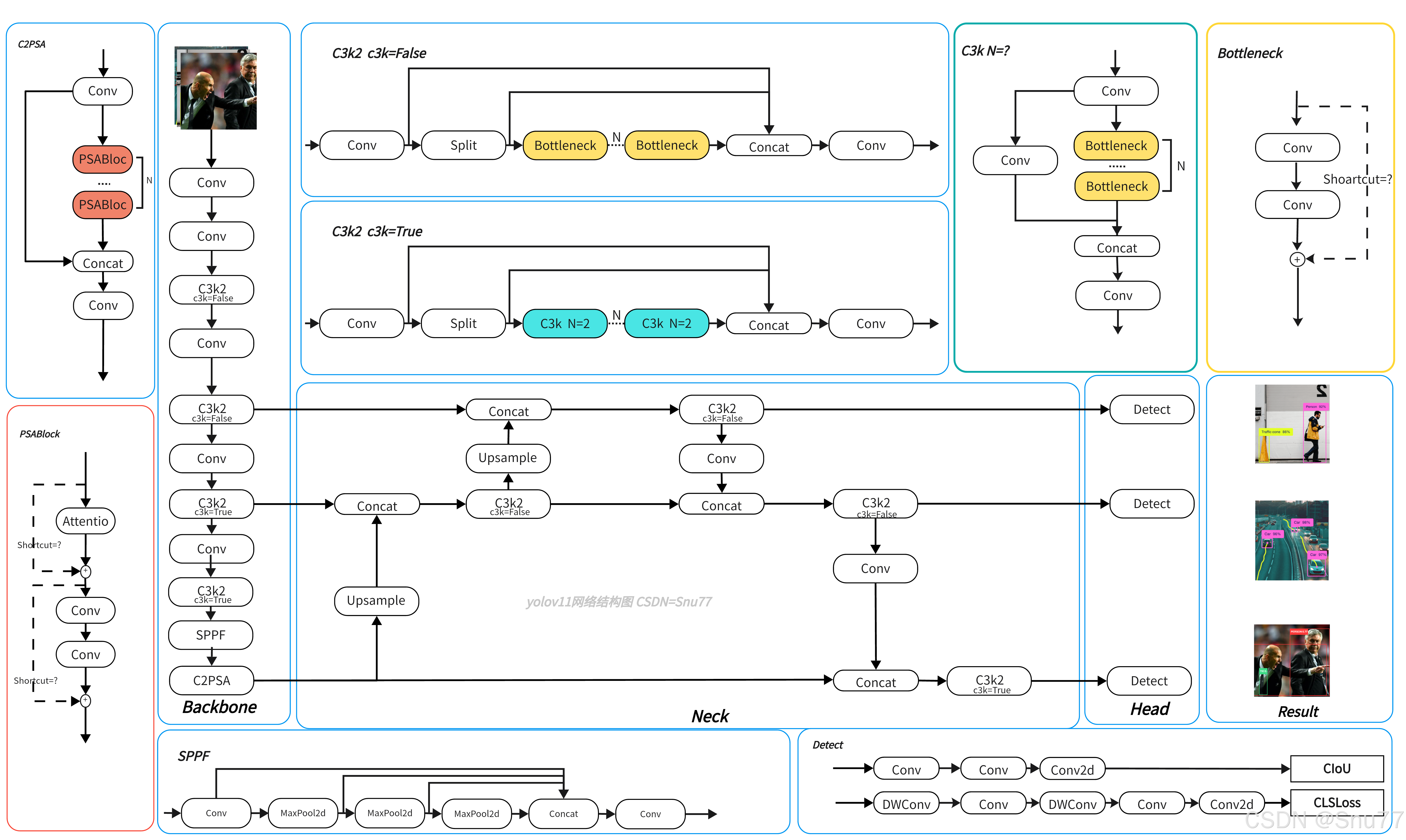
网络架构设计
YOLOv11延续了YOLO系列的经典三阶段结构(Backbone-Neck-Head):
Backbone(骨干网络):从输入图像中提取多尺度特征,保留空间和语义信息。
- C3K2模块:替代YOLOv8的C2f模块,通过动态选择3×3或5×5卷积核(
c3k=True时启用C3k块)优化计算效率,参数量减少22%。- C2PSA模块:集成位置敏感注意力(PSA)机制,通过多头注意力和前馈网络增强关键区域的特征表达。
Neck(颈部网络):增强特征金字塔的语义信息传递,平衡不同尺寸目标的检测性能。
- BiFPN双向特征金字塔:优化多尺度特征融合,结合可学习权重减少冗余。
- SPFF模块:快速空间金字塔池化,通过多尺度池化(如5×5、9×9、13×13)融合不同感受野特征,提升小目标检测能力。
Head(检测头):输出边界框坐标、类别概率及置信度,完成最终检测任务。
- 深度可分离卷积:替换传统卷积,降低计算量并保持精度。
- 多尺度预测头:输出P3-P5特征图,适配不同尺寸目标检测。
| 技术 | 作用 | 性能提升 |
|---|---|---|
| C3K2模块 | 动态选择卷积核,平衡计算效率与特征提取能力 | 参数量减少22%,mAP提升0.5-1.0 |
| C2PSA注意力 | 通过空间和通道注意力聚焦关键区域 | 小目标检测AP提升15% |
| SPFF池化 | 快速融合多尺度特征,增强不同大小目标的检测 | 推理速度提升2% |
算法流程
(1) 输入处理
图像缩放到固定尺寸(如640×640),并划分为 S×S网格(如19×19)。
每个网格单元 负责预测中心落在该网格内的物体。
(2) 预测输出
每个网格预测:
- 边界框(BBox):4个值(中心坐标x/y、宽高w/h,归一化到0-1)。
- 物体置信度(Confidence):表示框内存在物体的概率(0-1)。
- 类别概率(Class):每个类别的条件概率(如"可乐"的概率)。
输出张量形状:
[batch, S, S, (5 + C)]
(5=4坐标+1置信度,C=类别数)
(3) 后处理(NMS)
非极大值抑制(NMS):过滤重叠框,保留置信度最高的预测。
使用YOLOv11检测物体
from ultralytics import YOLO
# 加载预训练模型
model = YOLO("yolov11n.pt") # 轻量版YOLOv11
# 检测图像
results = model("image.jpg")
# 可视化结果
results[0].show()优缺点
| 优点 | 缺点 |
|---|---|
| ⚡ 实时性(适合边缘设备部署) | 📏 小目标检测精度较低 |
| 🎯 全局上下文理解能力强 | 📦 密集物体易漏检(如堆叠商品) |
| 🔧 易部署(支持ONNX/TensorRT) | 🖼️ 输入尺寸固定,影响灵活性 |
模型地址:
项目首页 - ultralytics:ultralytics - 提供 YOLOv8 模型,用于目标检测、图像分割、姿态估计和图像分类,适合机器学习和计算机视觉领域的开发者。 - GitCode
Ultralytics YOLO11 -Ultralytics YOLO 文档
一.数据准备:
1.数据集格式:
目录结构示例:
datasets/
├── images/
│ ├── train/ # 训练图片
│ └── val/ # 验证图片
└── labels/
├── train/ # 训练标签
└── val/ # 验证标签每张图片对应一个 .txt 标注文件,内容为:
<class_id> <x_center> <y_center> <width> <height> # 归一化坐标(0~1)2.将 VOC 格式的数据集转换为 YOLO 格式的数据集:
把 VOC 格式(XML标注)的数据集,转换成 YOLO 格式(TXT文本标注)的数据集,方便 YOLO 模型直接训练。
关键转换步骤:
(1) 坐标转换(核心)
VOC 的 XML 中存储的是绝对坐标:
<xmin>100</xmin>
<ymin>50</ymin>
<xmax>300</xmax>
<ymax>200</ymax>👉 转换为 YOLO 的相对坐标(0~1):
0 0.25 0.125 0.5 0.375
(格式:类别ID x_中心 y_中心 宽度 高度)(2) 自动生成类别映射
- 扫描所有 XML 文件,自动提取类别名称(如
cat,dog)。 - 为每个类别分配数字 ID(如
cat→0,dog→1)。
(3) 文件结构重组
VOC格式目录结构: YOLO格式目录结构:
D:/dataset/ D:/dataset/
├── Annotations/ ├── images/
│ ├── 001.xml │ ├── 001.jpg
│ └── 002.xml │ └── 002.jpg
└── JPEGImages/ └── labels/
├── 001.jpg ├── 001.txt
└── 002.jpg └── 002.txt为什么需要这个转换?
- YOLO 不吃 XML:YOLO 系列模型训练时需要的是简单的 TXT 标注文件。
- 统一标准:避免手动标注格式混乱。
- 效率提升:自动化转换比手动处理快100倍。
完整代码:
如何使用?
- 确保你的 VOC 数据集有
Annotations/和JPEGImages/目录。 - 修改代码中的路径:
voc_data_path = '你的/VOC/数据集路径' yolo_data_path = '输出的/YOLO/路径' - 运行脚本,得到可直接用于 YOLO 训练的数据集。
import os
import shutil
import xml.etree.ElementTree as ET
# VOC格式数据集路径
voc_data_path = 'D:/YOLO/ultralytics-8.3.39/fall'
voc_annotations_path = os.path.join(voc_data_path, 'Annotations')
voc_images_path = os.path.join(voc_data_path, 'JPEGImages')
# YOLO格式数据集保存路径
yolo_data_path = 'D:/YOLO/ultralytics-8.3.39/data'
yolo_images_path = os.path.join(yolo_data_path, 'images')
yolo_labels_path = os.path.join(yolo_data_path, 'labels')
# 创建YOLO格式数据集目录
os.makedirs(yolo_images_path, exist_ok=True)
os.makedirs(yolo_labels_path, exist_ok=True)
# 自动生成类别映射
class_mapping = {}
class_id = 0
for voc_annotation in os.listdir(voc_annotations_path):
if voc_annotation.endswith('.xml'):
tree = ET.parse(os.path.join(voc_annotations_path, voc_annotation))
root = tree.getroot()
for obj in root.findall('object'):
cls = obj.find('name').text
if cls not in class_mapping:
class_mapping[cls] = class_id
class_id += 1
print("自动生成的类别映射:", class_mapping)
def convert_voc_to_yolo(voc_annotation_file, yolo_label_file):
tree = ET.parse(voc_annotation_file)
root = tree.getroot()
size = root.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
with open(yolo_label_file, 'w') as f:
for obj in root.findall('object'):
cls = obj.find('name').text
if cls not in class_mapping:
continue
cls_id = class_mapping[cls]
xmlbox = obj.find('bndbox')
xmin = float(xmlbox.find('xmin').text)
ymin = float(xmlbox.find('ymin').text)
xmax = float(xmlbox.find('xmax').text)
ymax = float(xmlbox.find('ymax').text)
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
f.write(f"{cls_id} {x_center} {y_center} {w} {h}\n")
# 遍历VOC数据集的Annotations目录,进行转换
for voc_annotation in os.listdir(voc_annotations_path):
if voc_annotation.endswith('.xml'):
voc_annotation_file = os.path.join(voc_annotations_path, voc_annotation)
image_id = os.path.splitext(voc_annotation)[0]
voc_image_file = os.path.join(voc_images_path, f"{image_id}.jpg")
yolo_label_file = os.path.join(yolo_labels_path, f"{image_id}.txt")
yolo_image_file = os.path.join(yolo_images_path, f"{image_id}.jpg")
convert_voc_to_yolo(voc_annotation_file, yolo_label_file)
if os.path.exists(voc_image_file):
shutil.copy(voc_image_file, yolo_image_file)
print("转换完成!")注意!!!这个代码运行完成会输出每个物品对应的编号,这个对于编写data.yaml非常关键。
二.模型处理:
1.训练模型:
imgsz默认是640*640的正方形,长宽比非 1:1 的图像会被自动填充(padding):YOLO 会保持原始图像比例,并在边缘填充灰色或黑色像素,使其变为正方形。
如果数据集图像本身不是正方形,YOLO 会自动填充(无需手动调整)。
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
from ultralytics import YOLO
model = YOLO("yolo11n.pt") # Load a pretrained model
results = model.train(data="D:/YOLO/ultralytics-8.3.39/data.yaml",
epochs=100, imgsz=640, batch=16,device=0,workers=0, iou=0.4)
因为我训练照片是5422张,尺寸是960*720的矩形,所以使用的是下面的参数:
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
from ultralytics import YOLO
model = YOLO("yolo11n.pt") # Load a pretrained model
results = model.train(
data="data.yaml",
epochs=200,
imgsz=(960, 720),
batch=16,
device=0,
workers=0,
rect=True,
amp=True, # 是否启用混合精度训练
optimizer='SGD', # 使用的优化器(SGD)
flipud=0.5, # 随机上下翻转概率
fliplr=0.5, # 随机左右翻转概率
lr0=0.01, # 初始学习率(SGD推荐0.01-0.1)
lrf=0.1, # 学习率衰减至lr0*lrf(余弦衰减)
momentum=0.937, # SGD动量参数
name='ema_train',
iou=0.4
)YOLO 训练参数配置表
| 参数 | 值/选项 | 说明 |
|---|---|---|
data | data.yaml | 数据集配置文件路径(包含类别、路径等信息) |
epochs | 200 | 训练总轮次 |
imgsz | (960, 720) | 输入图像尺寸(宽×高),YOLO 会自动填充为非正方形图像 |
batch | 16 | 每批次的样本数(根据显存调整) |
device | 0 | 使用 GPU 0(device='cuda:0') |
workers | 0 | 数据加载线程数(0 表示禁用多线程) |
rect | True | 启用矩形训练(减少填充,提升速度) |
amp | True | 启用混合精度训练(降低显存占用,加速训练) |
optimizer | SGD | 使用随机梯度下降优化器 |
flipud | 0.5 | 随机上下翻转概率(50% 概率) |
fliplr | 0.5 | 随机左右翻转概率(50% 概率) |
lr0 | 0.01 | 初始学习率(SGD 推荐范围 0.01-0.1) |
lrf | 0.1 | 最终学习率衰减至 lr0 * lrf(余弦衰减) |
momentum | 0.937 | SGD 动量参数(控制梯度下降的惯性) |
name | ema_train | 训练结果保存的目录名称(含模型权重、日志等) |
iou | 0.4 | IoU 阈值(用于 NMS 或计算 mAP) |
2.使用模型:
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
from ultralytics import YOLO
# Load a model
model = YOLO("D:/YOLO/ultralytics-8.3.39/runs/detect/train5/weights/best.pt")
# Perform object detection on an image
results = model("图片地址")
results[0].show()
3.pt转onnx:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
from ultralytics import YOLO
# 加载 YOLOv11 模型
model = YOLO('D:/YOLO/ultralytics-8.3.39/runs/detect/train3/weights/best.pt')
# 导出为 ONNX 格式
model.export(format='onnx', imgsz=640)4.Tensorboard:
TensorBoard 是 TensorFlow 生态系统中的一个可视化工具包,主要用于帮助开发者理解、调试和优化机器学习模型的训练过程。它通过直观的交互式仪表盘,将模型训练中的各种指标、数据和计算图可视化,从而提升开发效率。
pip install tensorboard -i https://mirrors.aliyun.com/pypi/simple/ # 阿里源import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 放在文件开头
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image # 用于图像处理
# 初始化 Writer(日志保存到 logs/ 目录)
writer = SummaryWriter('logs')
# 示例1:记录标量数据(如损失)
for i in range(100):
writer.add_scalar('y=x', np.exp(-i / 10), i) # 模拟损失下降曲线
# 示例2:记录图像(需要实际的图像数据)
# 生成随机图像数据(3x256x256 的RGB图像)
dummy_img = np.random.randint(0, 255, size=(3, 256, 256), dtype=np.uint8)
writer.add_image('sample_image', dummy_img, global_step=0) # global_step 是时间步
# 关闭 Writer
writer.close()然后运行下面命令:
tensorboard --logdir=logs --port=6007三.Matplotlib数据分析:
对比不同训练过程的结果(如不同模型或训练策略),通过图表展示以下指标:
- 精度指标:Precision、Recall、mAP@50、mAP@50-95
- 损失指标:训练集和验证集的Box/Class/DFL损失
项目目录:
项目目录/
├── plot_results.py # 当前脚本
├── env/ # 存放训练结果的目录
│ ├── results.csv # 第一次训练结果
│ └── results-final.csv # 第二次训练结果然后修改配置文件路径:
results_files = [
'./env/results.csv', # 第一个训练结果文件
'./env/results-final.csv' # 第二个训练结果文件
]
custom_labels = [
'yolov11', # 第一个结果的图例标签
'yolov11-ema' # 第二个结果的图例标签
]- 替换路径:将
./env/改为你的实际结果文件路径(如runs/train/exp1/results.csv) - 自定义标签:修改
custom_labels中的名称,用于区分不同曲线(如"yolov11-baseline")
修改对比指标:
# 示例:添加F1分数对比
metrics = [
'metrics/precision(B)', 'metrics/recall(B)', 'metrics/mAP50(B)', 'metrics/F1'
]
labels = [
'Precision', 'Recall', 'mAP@50', 'F1 Score'
]下面是完整代码:
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
# 训练结果列表
results_files = [
'./env/results.csv',
'./env/results-final.csv'
]
# 与results_files顺序对应
custom_labels = [
'yolov11',
'yolov11-ema',
]
#
def plot_comparison(metrics, labels, custom_labels, layout=(2, 2)):
fig, axes = plt.subplots(layout[0], layout[1], figsize=(15, 10)) # 创建网格布局
axes = axes.flatten() # 将子图对象展平,方便迭代
for i, (metric_key, metric_label) in enumerate(zip(metrics, labels)):
for file_path, custom_label in zip(results_files, custom_labels):
df = pd.read_csv(file_path)
# 清理列名中的多余空格
df.columns = df.columns.str.strip()
# 检查 'epoch' 列是否存在
if 'epoch' not in df.columns:
print(f"'epoch' column not found in {file_path}. Available columns: {df.columns}")
continue
# 检查目标指标列是否存在
if metric_key not in df.columns:
print(f"'{metric_key}' column not found in {file_path}. Available columns: {df.columns}")
continue
# 在对应的子图上绘制线条
axes[i].plot(df['epoch'], df[metric_key], label=f'{custom_label}')
axes[i].set_title(f' {metric_label}')
axes[i].set_xlabel('Epochs')
axes[i].set_ylabel(metric_label)
axes[i].legend()
plt.tight_layout() # 自动调整子图布局,防止重叠
plt.show()
if __name__ == '__main__':
# 精度指标
metrics = [
'metrics/precision(B)', 'metrics/recall(B)', 'metrics/mAP50(B)', 'metrics/mAP50-95(B)'
]
labels = [
'Precision', 'Recall', 'mAP@50', 'mAP@50-95'
]
# 调用通用函数绘制精度对比图
plot_comparison(metrics, labels, custom_labels, layout=(2, 2))
# 损失指标
loss_metrics = [
'train/box_loss', 'train/cls_loss', 'train/dfl_loss', 'val/box_loss', 'val/cls_loss', 'val/dfl_loss'
]
loss_labels = [
'Train Box Loss', 'Train Class Loss', 'Train DFL Loss', 'Val Box Loss', 'Val Class Loss', 'Val DFL Loss'
]
# 调用通用函数绘制损失对比图
plot_comparison(loss_metrics, loss_labels, custom_labels, layout=(2, 3))
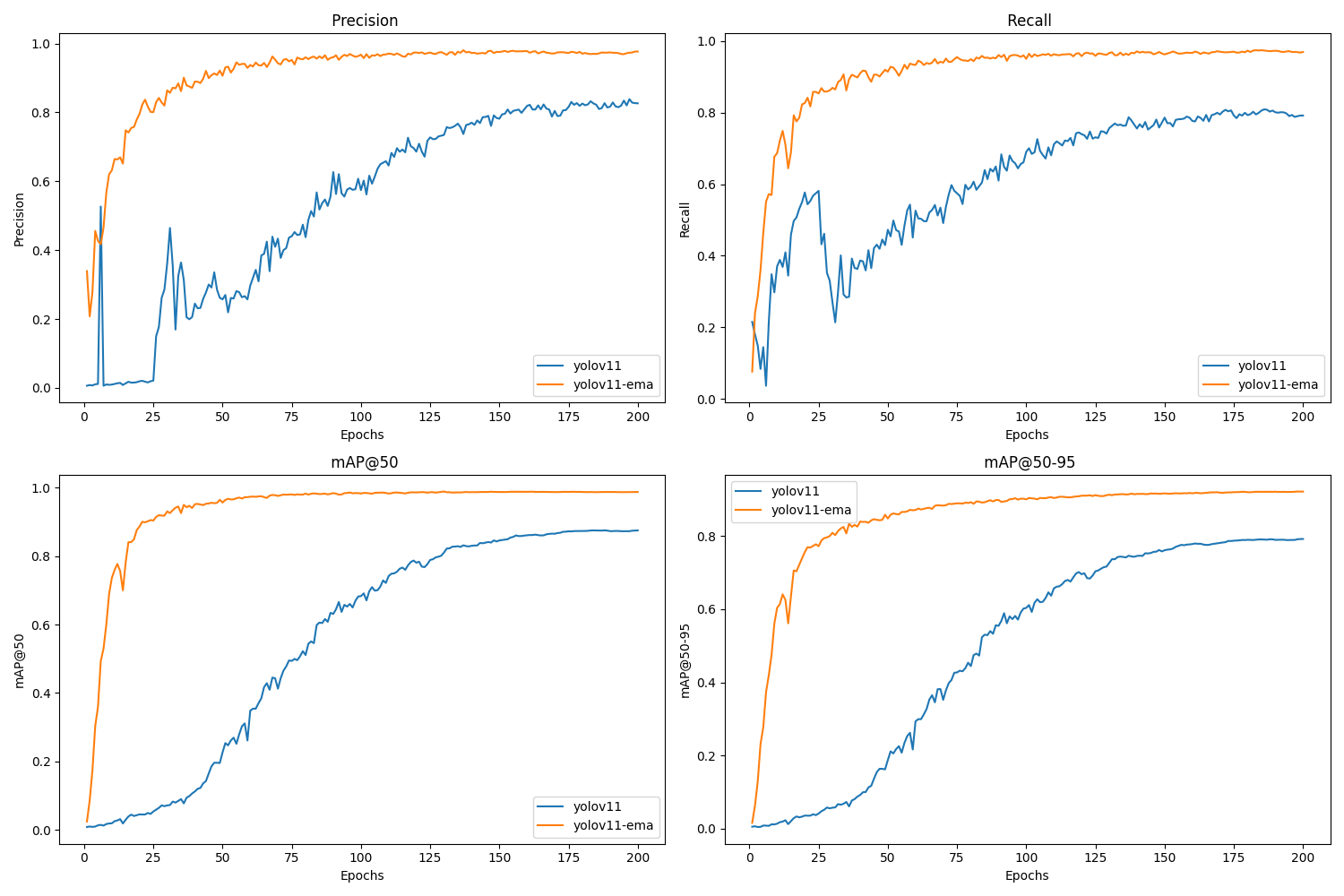
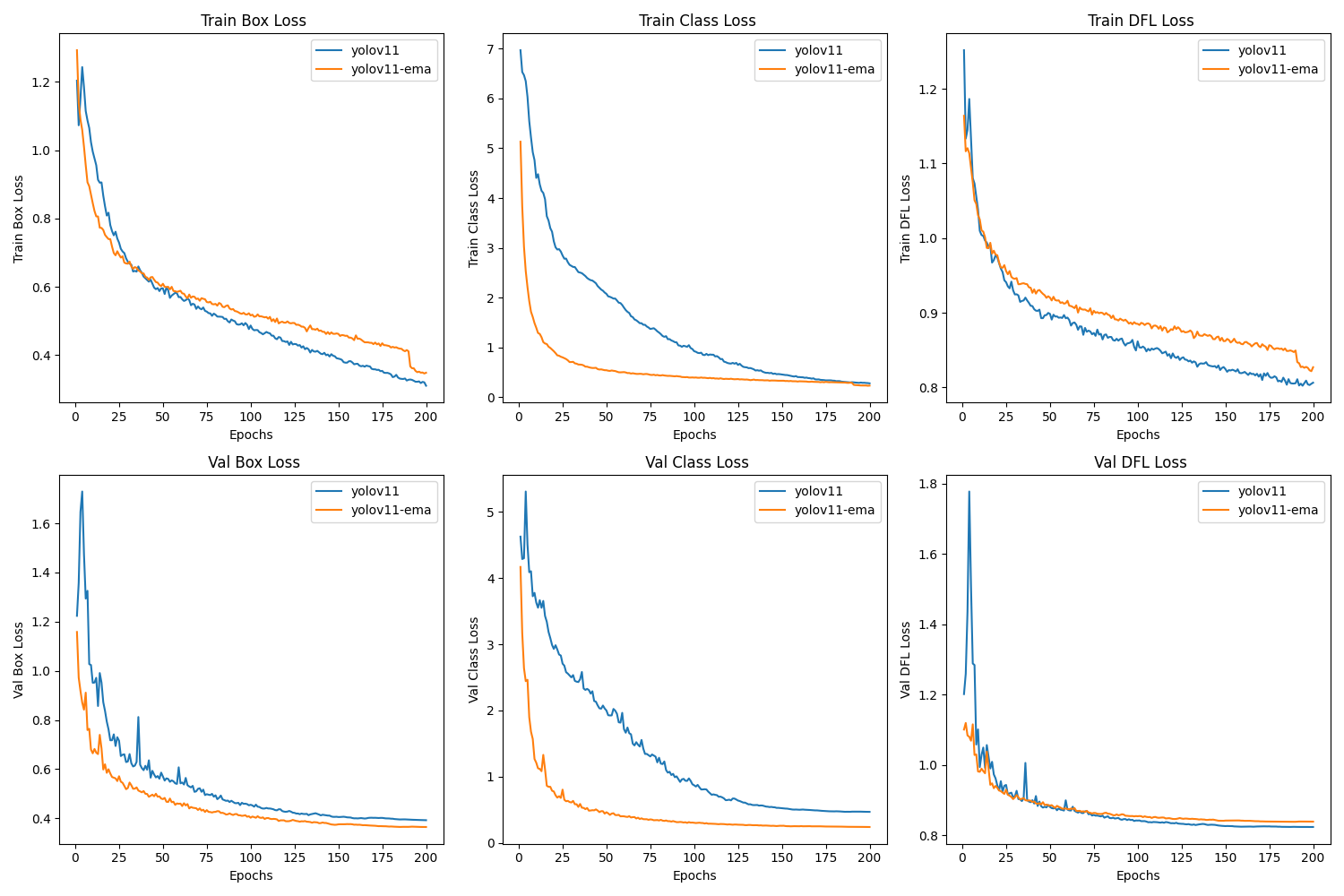
下面讲解一下yolo训练完成的result.csv内的数据都是什么意思?
results.csv 文件结构示例:
| epoch | train/box_loss | train/cls_loss | train/obj_loss | metrics/precision | ... | val/box_loss | val/cls_loss | val/obj_loss | x/lr0 | ... |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.123 | 0.456 | 0.789 | 0.85 | ... | 0.111 | 0.333 | 0.555 | 0.001 | ... |
在 YOLO(Ultralytics YOLOv8)训练完成后,生成的 results.csv 文件记录了训练过程中的各项指标数据,每一列代表不同的评估指标或损失值。以下是各列数据的详细解释:
| 列名 | 含义 | 正常范围 | 优化方向 |
|---|---|---|---|
epoch | 当前训练轮次(从 0 开始) | 0 到 epochs-1 | —— |
train/box_loss | 训练集的边界框回归损失(越小越好) | 逐渐下降趋近于 0 | 目标检测框越准,损失越低 |
train/cls_loss | 训练集的分类损失(越小越好) | 逐渐下降趋近于 0 | 分类错误越少,损失越低 |
train/dfl_loss | 训练集的分布焦点损失(DFL,用于优化边界框概率分布,越小越好) | 逐渐下降趋近于 0 | —— |
val/box_loss | 验证集的边界框回归损失 | 低于 train/box_loss | 过高可能过拟合 |
val/cls_loss | 验证集的分类损失 | 低于 train/cls_loss | 过高需检查数据标注质量 |
val/dfl_loss | 验证集的分布焦点损失 | 低于 train/dfl_loss | —— |
metrics/precision | 验证集的精确率(TP / (TP + FP),越高越好) | 0.5~1.0 | 降低误检(FP) |
metrics/recall | 验证集的召回率(TP / (TP + FN),越高越好) | 0.5~1.0 | 减少漏检(FN) |
metrics/mAP50 | 验证集的 mAP@0.5(IoU阈值为0.5时的平均精度,越高越好) | 0.5~1.0 | 主要优化目标 |
metrics/mAP50-95 | 验证集的 mAP@0.5:0.95(IoU阈值从0.5到0.95的平均精度,综合指标) | 低于 mAP50 | 模型泛化能力的核心指标 |
lr/pg0 | 第0参数组(通常是骨干网络)的学习率 | 根据优化策略变化 | 学习率过高可能导致震荡 |
lr/pg1 | 第1参数组(通常是检测头)的学习率 | 通常比 pg0 高 | —— |
lr/pg2 | 第2参数组(通常是分类头)的学习率 | 可能为 0 | —— |
x/lr0 | 初始学习率(lr0 参数的值) | 固定值 | 用户设定(如 0.01) |
x/lrf | 最终学习率(lr0 * lrf) | 固定值 | 用户设定(如 0.1) |
x/momentum | 优化器的动量参数(momentum 参数的值) | 固定值 | 用户设定(如 0.937) |
各列数据的详细解释:
(1) 训练损失(Training Losses)
| 列名 | 含义 | 理想趋势 |
|---|---|---|
train/box_loss | 边界框回归损失(预测框与真实框的误差,如 IoU、CIoU) | 逐渐下降 |
train/cls_loss | 分类损失(预测类别与真实类别的交叉熵误差) | 逐渐下降 |
train/obj_loss | 目标置信度损失(检测到目标的概率误差) | 逐渐下降 |
- 如果损失不下降,可能是学习率(
lr)不合适或数据标注有问题。 - 剧烈波动可能预示批次大小(
batch_size)过小或数据噪声大。
(2) 验证损失(Validation Losses)
| 列名 | 含义 | 理想趋势 |
|---|---|---|
val/box_loss | 验证集边界框损失 | 平稳下降 |
val/cls_loss | 验证集分类损失 | 平稳下降 |
val/obj_loss | 验证集目标置信度损失 | 平稳下 |
- 若验证损失远高于训练损失,可能模型过拟合(需增加数据增强或减少模型复杂度)。
- 若验证损失上升,可能学习率过高或训练轮次(
epochs)过多。
(3) 评估指标(Metrics)
| 列名 | 含义 | 计算公式 | 理想值 |
|---|---|---|---|
metrics/precision | 精确率(预测为正的样本中真实为正的比例) | TP / (TP + FP) | 接近 1 |
metrics/recall | 召回率(真实为正的样本中被正确预测的比例) | TP / (TP + FN) | 接近 1 |
metrics/mAP@0.5 | 平均精度(IoU阈值=0.5时的mAP) | Area under PR曲线 | 越高越好 |
metrics/mAP@0.5:0.95 | mAP(IoU阈值从0.5到0.95的平均值) | 多阈值积分 | 越高越好 |
mAP@0.5:0.95是更严格的指标,适用于通用目标检测评估。- 低精确率高召回率 → 模型漏检少但误检多(可提高置信度阈值
conf-thres)。
(4) 学习率与超参数
| 列名 | 含义 | 调整建议 |
|---|---|---|
x/lr0 | 初始学习率(通常指优化器的第一个学习率) | 参考范围:1e-3 到 1e-5 |
x/lr1 | 第二个学习率(如有分组学习率) | - |
x/lr2 | 第三个学习率 | - |
学习率策略:YOLO 默认使用 余弦退火(Cosine Annealing),学习率会先上升后下降。
关键分析场景:
(1) 正常训练曲线
- 损失曲线:训练和验证损失均平稳下降,最终趋于稳定。
- 指标曲线:mAP 和精确率/召回率逐步上升至稳定值。
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('results.csv')
plt.plot(data['epoch'], data['train/box_loss'], label='Train Box Loss')
plt.plot(data['epoch'], data['val/box_loss'], label='Val Box Loss')
plt.legend()
plt.show()(2) 过拟合(训练损失持续下降,验证损失先降后升)
过拟合(Overfitting)是机器学习模型在训练过程中过度适应训练数据,导致在训练集上表现极好,但在新数据(测试集或真实场景)上表现很差的现象。简单来说,模型“死记硬背”了训练数据的细节和噪声,而未能学到真正的泛化规律。
现象:训练损失持续下降,但验证损失上升或波动。
解决:
方法 作用 示例 简化模型 降低模型复杂度 用 YOLOv5s 代替 YOLOv5x 早停(Early Stopping) 在验证损失上升时终止训练 patience=10监控验证损失正则化 约束参数值,防止过大 L2 正则化、Dropout(丢弃部分神经元)


















 2126
2126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











