







 本文盘点了2023年各大公司如华为、谷歌和Stability AI发布的最新文生图模型,包括PanGu-Draw、Imagen、SDXL Turbo等,涵盖了高效训练、深度语言理解和对抗性扩散等技术。每个模型都展示了在文本到图像合成领域的创新和突破,提升了生成质量和效率。
本文盘点了2023年各大公司如华为、谷歌和Stability AI发布的最新文生图模型,包括PanGu-Draw、Imagen、SDXL Turbo等,涵盖了高效训练、深度语言理解和对抗性扩散等技术。每个模型都展示了在文本到图像合成领域的创新和突破,提升了生成质量和效率。
2023年真是文生图大放异彩的一年,给数字艺术界和创意圈注入了新鲜血液。从起初的基础图像创作跃进到现在的超逼真效果,这些先进的模型彻底变革了我们制作和享受数字作品的途径。
最近,一些大公司比如华为、谷歌、还有Stability AI等人工智能巨头也没闲着,纷纷推出了自己的最新文生图模型。
今天就给大家盘点一下近期新推出的文生图模型,为了让各位更全面地理解这些技术,我还特别准备了相关的研究论文和代码分享!
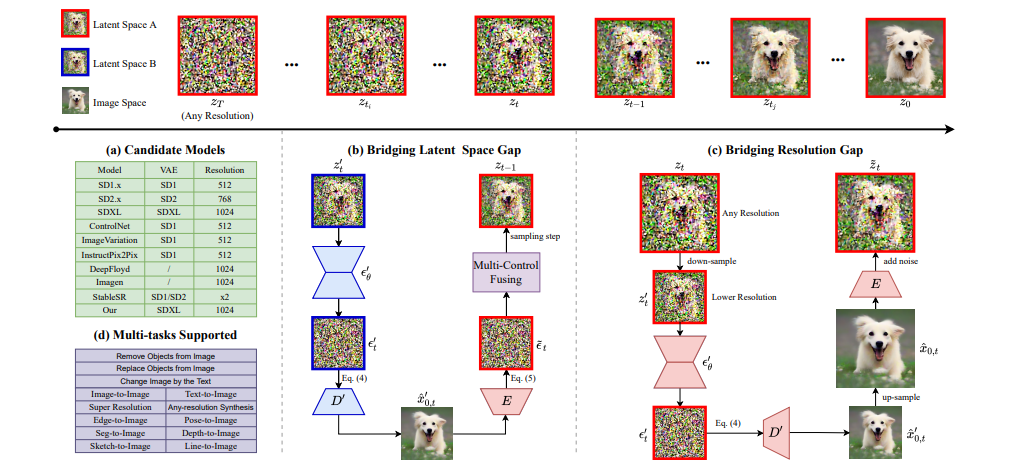
1、PanGu-Draw(华为)
论文:PanGu-Draw: Advancing Resource-Efficient Text-to-Image Synthesis with Time-Decoupled Training and Reusable Coop-Diffusion
PanGu-Draw:通过时间解耦训练和可重用 Coop-Diffusion 推进资源节约型文本到图像合成
简述:本文提出了PanGu-Draw,一种高效的文本到图像潜在扩散模型,能适应多控制信号。该模型采用时间解耦训练策略,分为结构器和纹理器,大幅提升数据和计算效率。同时,研究人员引入Coop-Diffusion算法,允许不同潜在空间和分辨率的模型协同工作,无需额外数据或重新训练。PanGu-Draw在文本到图像和多控制图像生成上表现出色,指向了训练效率和生成多功能性的新方向。
2、Imagen & Imagen 2(谷歌)
论文:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
具有深度语言理解的逼真文本到图像扩散模型
简述:本文提出了Imagen,一款新型的文本到图像扩散模型,实现了极高的真实
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









