






Transformer可以说是AI领域最重要的模型之一,但其可解释性和可靠性较差,无法满足诸多重要现实场景的需求(医学、金融、自动驾驶等),限制了其使用和自身技术进步。而这些则是因果推理的优势,当两者结合,便能优势互补,显著提升模型的准确性、可靠性、泛化性,为解决复杂问题提供全新的思路。
因此,Transformer+因果推理成为了研究热门!光是ICLR2025就有多篇!其中模型AT-Transformer便是麻省理工的倾力之作,其通过这两者的结合,就实现了比GPT-4还高26%的性能。
对这方向感兴趣的伙伴,可以从高效因果推理算法、与多模态融合结合、可解释性研究等入手,更容易被审稿人青睐!
为方便大家研究的进行,我给大家准备了12篇必读参考论文和源码。
论文原文+开源代码需要的同学看文末
Treatment Learning Causal Transformer for Noisy Image Classification
内容:这篇文章的核心内容是提出了一种名为TLT的新型架构,旨在提高深度学习模型在面对噪声图像时的分类准确性。文章从因果推断的角度出发,将噪声信息作为“处理”因素纳入图像分类任务中,通过联合估计处理效应来改进预测精度。TLT基于因果变分推断,利用潜在生成模型从观测输入中估计鲁棒的特征表示,并根据估计的噪声水平(作为二元处理因子)分配相应的推理网络进行预测。此外,作者还创建了新的噪声图像数据集,涵盖了多种噪声因素(如对象遮挡、风格迁移和对抗性扰动),用于性能基准测试,并通过多种反驳评估指标验证了TLT在噪声图像分类中的优越性能。
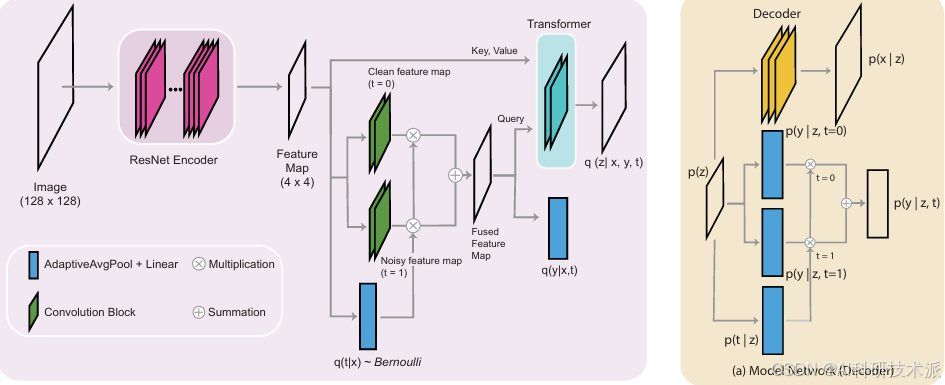
G-Transformer: Counterfactual Outcome Prediction under Dynamic and Time-varying Treatment Regimes
内容:这篇文章介绍了一种名为G-Transformer的新型架构,用于在动态和时变治疗策略下进行反事实结果预测,特别是在医疗决策领域。G-Transformer基于Transformer架构,能够捕捉时变协变量中的复杂长程依赖关系,并支持g-计算(一种因果推断方法),用于估计动态治疗策略的效果。研究者通过模拟的纵向数据集和真实世界的败血症ICU数据集(来自MIMIC-IV)对G-Transformer进行了广泛的评估,结果表明它在反事实预测方面优于传统的和最先进的模型。据作者所知,这是第一个支持在动态和时变治疗策略下进行反事实结果预测的基于Transformer的架构。
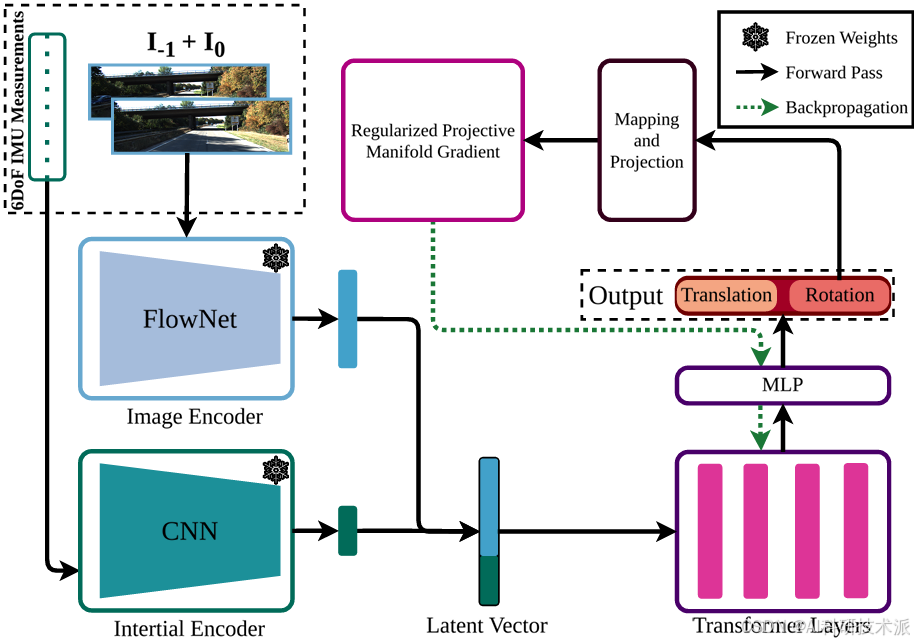
Causal Transformer for Fusion and Pose Estimation in Deep Visual Inertial Odometry
内容:这篇文章提出了一种名为因果视觉-惯性融合Transformer(VIFT)的方法,用于深度视觉-惯性里程计(VIO)中的姿态估计。VIFT利用Transformer架构中的注意力机制,通过更新潜在向量来提高姿态估计的准确性,尤其是在处理时序数据和旋转估计方面。该方法通过引入归纳偏差来解决Transformer在小数据集上的训练问题,并采用Riemannian流形优化技术来改进旋转学习。实验结果表明,VIFT在KITTI数据集上达到了最先进的性能,仅需要单目相机和惯性测量单元(IMU)即可进行推理。
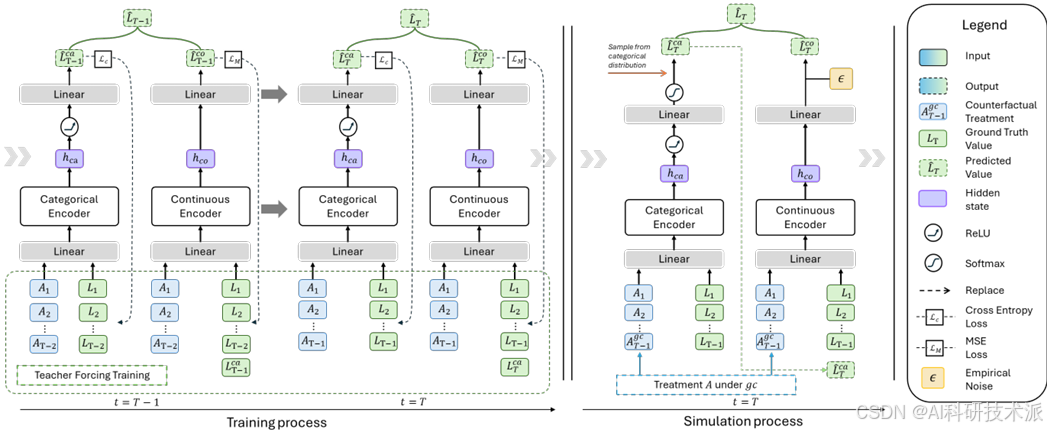
SELECTIVE INDUCTION HEADS: HOW TRANSFORM ERS SELECT CAUSAL STRUCTURES IN CONTEXT
内容:这篇文章的核心内容是研究Transformer模型如何在上下文中选择因果结构。作者提出了一个新颖的合成框架,通过交错马尔可夫链来动态处理因果结构。通过理论分析和实验验证,揭示了Transformer在处理因果结构选择任务时的内部工作机制,并提出了选择性归纳头这一新的概念,为理解Transformer的内部计算和提高其可解释性提供了新的视角。
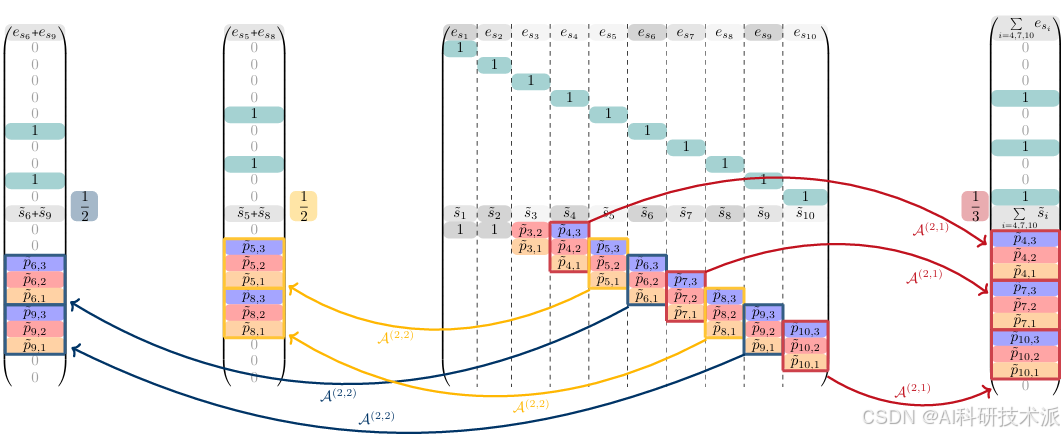

















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









