







Large-scale and Fine-grained Vision-language Pre-training for Enhanced CT Image Understanding

目录
1. 引言
人工智能(AI)在医疗影像分析中展现出巨大潜力,能够提高放射科医生的诊断效率和准确性。然而,通用AI模型往往需要大量数据和详尽的注释,而在医学领域难以实现。
近年来,利用放射学报告作为高质量的监督信号,通过对比语言-图像预训练(CLIP)开发面向医学影像的语言感知模型。然而,这些方法通常仅对整幅图像和报告进行对比,忽略了图像局部区域与报告语句之间的对应关系,影响了模型的性能和可解释性。
本研究提出了一种细粒度视觉-语言模型(fine-grained visionlanguage model,fVLM),专注于解剖级(anatomy-level)的 CT 图像分析。该模型通过将 CT 图像的解剖区域(anatomical regions)与放射学报告的描述进行匹配,并对每个解剖区域单独进行对比预训练。
由于解剖级对齐会带来大量假阴性问题,例如正常样本的泛滥和疾病类别的相似性,导致病人级别配对的模糊性,因此本文提出了一种方法来识别正常和异常样本的假阴性,并将对比学习从病人级别扩展到基于疾病的配对。
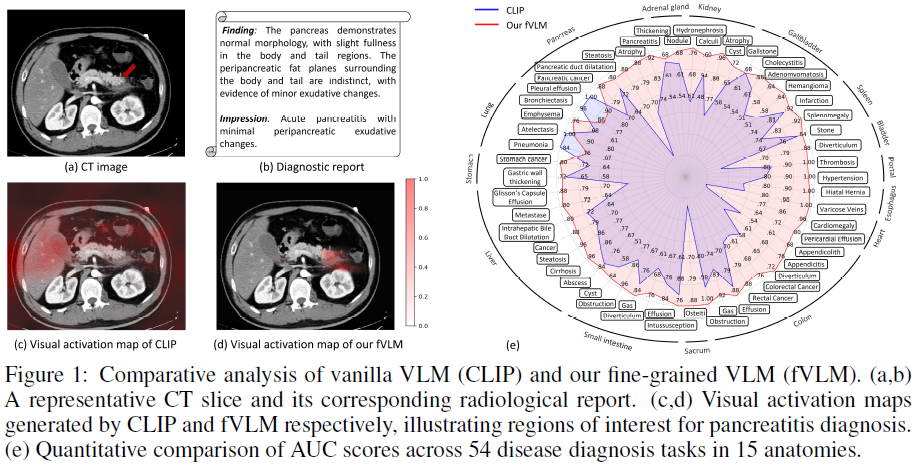
实验基于迄今为止规模最大的 CT 数据集(69,086 名患者),涵盖 54 种主要疾病的诊断任务,涉及 15 个主要解剖结构。实验结果表明,fVLM 在多种医学影像任务中表现卓越。
1.1 关键词
细粒度视觉-语言模型(Fine-grained Vision-Language Model, fVLM),对比学习(Contrastive Learning),医学影像分析(Medical Image Analysis),CT扫描(CT Imaging),人工智能(Artificial Intelligence)
2. 相关工作
2.1 医学视觉-语言预训练(Med-VLP)
现有的医学视觉-语言预训练方法主要关注二维医学影像,如胸部 X 光(CXR),主要通过对比损失对图像和报告进行配对学习。近年来,研究已扩展到更广泛的解剖结构,特别是高分辨率 3D CT 图像,以提供更全面的诊断支持。例如,BIUD 和 CT-CLIP 对胸部 CT 体积和放射学报告进行配对训练,Merlin 则专注于腹部CT,并结合电子健康记录(EHR)作为额外的监督信号。
2.2 细粒度对齐在医学视觉-语言预训练中的应用
大多数现有方法采用全局对比学习,即对整个图像和报告进行配对,然而,这种方法容易导致图像与报告之间的错误匹配。例如,CLIP 在特定诊断任务中的注意力图显示,它可能关注与诊断无关的区域,从而影响模型的可解释性。为此,一些方法(如 GLoRIA 和 LoVT)引入局部对齐机制,通过交叉注意力学习图像区域与报告文本的隐式对应关系。然而,这些方法主要针对 2D CXR 图像,直接应用于 3D CT 扫描时,可能由于数据复杂度增加而受到限制。
3. 方法
3.1 数据预处理
3.1.1 解剖解析
为了进行解剖级别的匹配,使用 TotalSegmentator 工具对 CT 影像进行全身解剖分割,提取 104 个解剖结构(包括器官、血管、骨骼、肌肉等)。
由于放射学报告通常不会精确定位病变的具体位置,可将这些 104 个解剖结构进一步合并为 36 个主要解剖部位,以匹配临床报告的粒度。这种合并考虑了图像-文本一致性和数据分布的平衡。

3.1.2 报告分解
放射学报告通常包含两部分:
- Findings(检查结果):详细描述影像发现,如器官大小、形态、异常病变等。
- Impression(临床总结):总结最重要的异常,并给出诊断结论。
由于 Findings 部分包含丰富的解剖细节,而 Impression 部分通常只提及主要病变,我们采用大模型(LLM,如 Qwen 2.5) 结合 字符串匹配算法 进行报告分解,具体步骤如下:
1)解剖识别:使用 LLM 识别报告中提及的解剖部位
2)提取解剖级描述:从 Findings 和 Impression 中分别提取每个解剖部位的描述。
3)融合描述:
- 如果某个解剖部位在 Findings 和 Impression 都被提及,则合并两部分信息;
- 如果某个解剖部位仅在 Findings 被提及,而 Impression 未提及,则视为 正常,并标注为 “无明显异常”;
- 如果某个解剖部位既未出现在 Findings 也未出现在 Impression,则默认该部位无异常,并标注为 “{解剖部位} 无明显异常”。
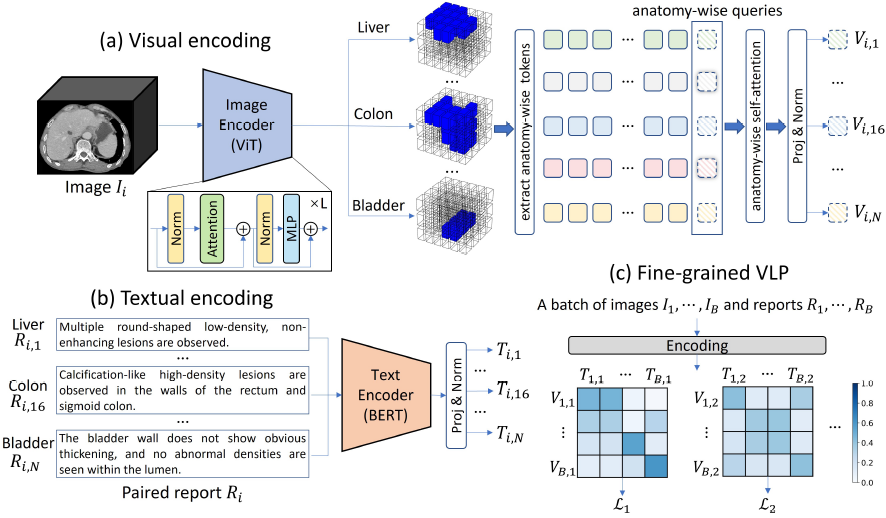
图 3:fVLM 框架
- (a) 视觉编码:输入 CT 数据 I_i 进入图像编码器,并提取每个解剖部位对应的视觉 token。然后,我们在每个解剖部位提取的视觉 token 上附加一个特定于该解剖部位的查询 token。这些查询 token 通过自注意力机制进行更新,最终构成各自解剖部位的视觉表示。N 代表解剖部位的数量。
- (b) 文本编码:将配对的放射学报告 R_i 按解剖部位进行分解,并分别输入文本解码器,以获取针对各个解剖部位的文本表示。
- (c) 细粒度视觉-语言预训练(Fine-grained VLP):针对不同 CT 扫描中的各个解剖部位,执行局部对齐。L_j 代表针对第 j 个解剖部位计算的对比损失。
3.2 细粒度对比预训练
fVLM 采用对比学习(Contrastive Learning)框架,基于 CLIP 进行优化。采用 Vision Transformer(ViT)和 BERT 作为图像与文本编码器。
通过解剖区域掩码提取解剖级的视觉特征,并使用自注意力机制生成最终的解剖级视觉表示。
采用基于解剖结构的局部对比学习,将 CT 图像的局部区域与相应的文本描述进行配对。
3.3 假阴性减少策略
传统对比学习会将所有不同患者视为负样本,但在医学影像中:
- 正常样本过多:CT 数据中某些解剖部位的正常样本占比高达 99%,这会导致模型错误地将相似的正常样本视为负样本。
- 疾病间语义相似性:例如,两个患者的胰腺影像可能都显示 “胰腺炎”,但传统对比学习会错误地拉远它们的特征。
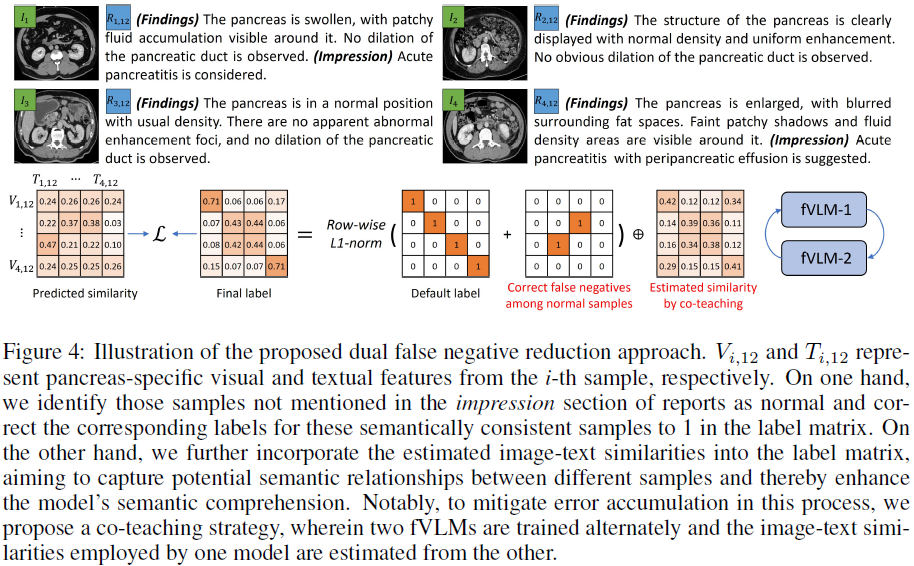
本文提出 双重假阴性校正(Dual False Negative Reduction, FNR):
- 基于报告 Impression 进行正常样本校正:如果解剖部位未在 Impression 提及,则视为正常,并调整损失函数。
- 基于模型预测进行异常样本语义校正:使用 fVLM 自己的预测相似度动态调整损失函数,使得相似异常样本被正确配对。
- 协同教学(Co-Teaching):训练两个独立的 fVLM 模型,每个模型用于指导另一个模型的标签校正,以减少错误传播。
最终损失函数:
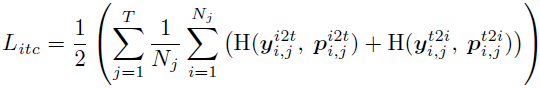
其中,H 为交叉熵损失,p 为模型预测图文相似度。y 表示与真实值的相似度,其中负对的概率为 0,正对的概率为 1。
4. 实验
4.1 实验设置
数据集:
- MedVL-CT69K(自建数据集):69,086 名患者,272,124 个 CT 扫描,涵盖 54 种疾病。
- CT-RATE & Rad-ChestCT(公开基准):用于评估模型的零样本泛化能力。
评估指标:
- 零样本异常检测:AUC、ACC、Specificity、Sensitivity、Precision、F1-score。
- 放射学报告生成:BLEU、ROUGE-L、METEOR、CIDEr。
4.2 零样本异常检测
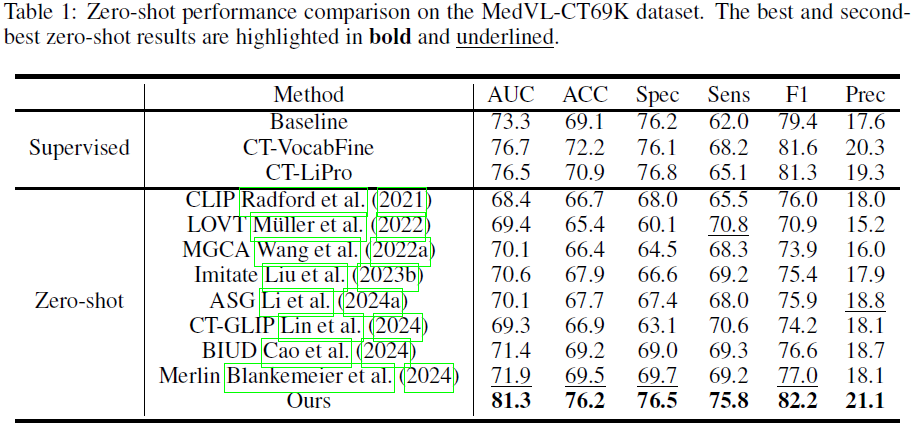
在 MedVL-CT69K 上,fVLM 的 AUC 达到 81.3%,比 CLIP 提高 12.9%。
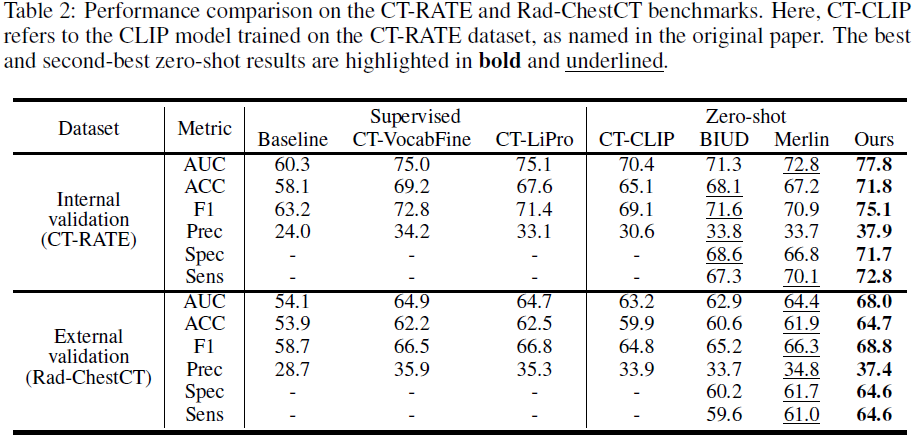
在 CT-RATE 和 Rad-ChestCT 数据集上,分别提高了 7.4% 和 4.8% 的 AUC。
4.3 放射学报告生成
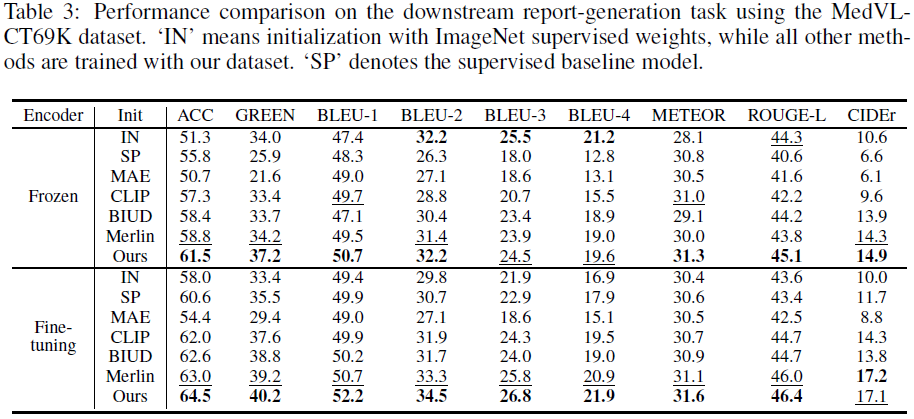
fVLM 生成的报告在 BLEU、ROUGE 等指标上均优于现有方法,表明其在医学文本生成上的有效性。
4.4 分析
消融实验:
- FGA(细粒度对齐) 带来了最大增益(AUC 提升 5.1),表明解剖级别的对齐在医学影像理解中的重要性。
- FNCN(正常样本假阴性校正) 进一步提升了模型性能(AUC 提升 2.7),减少了正常样本的误分类。
- CoT(协同教学) 也带来了稳定的性能提升,但其影响小于 FGA 和 FNCN。
- 完整 fVLM(FGA + FNCN + CoT) 达到最优性能,AUC 提高到 79.8,ACC 提高到 75.9,证明三个模块协同作用带来了显著的改进。
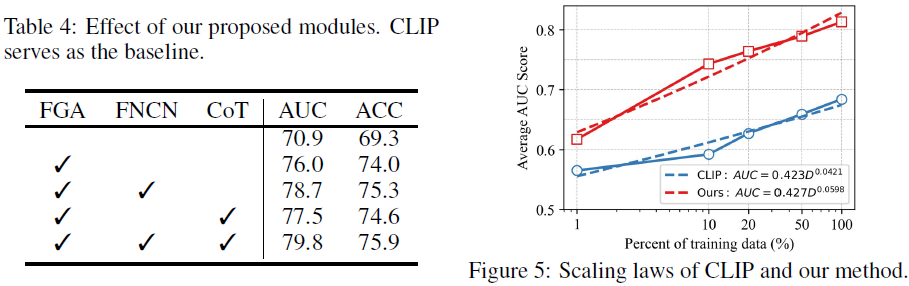
模型扩展:fVLM 在 所有数据规模下均优于 CLIP,说明解剖级别的细粒度对齐提升了数据利用效率。
5. 结论
本文提出了一种新的细粒度视觉-语言模型(fVLM),用于增强CT影像理解。该方法通过解剖级别的对齐,提高了模型的可解释性和诊断性能。实验结果表明,fVLM 在零样本诊断和放射学报告生成任务上均取得显著提升。
未来工作包括进一步优化模型,使其能够生成解剖级别的诊断报告,并探索更高效的数据处理方法,以减少计算资源消耗。
论文地址:https://arxiv.org/abs/2501.14548
项目页面:https://github.com/alibaba-damo-academy/fvlm
进 Q 学术交流群:922230617

















 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









