







 本文介绍了MapStruct,一种用于对象转换的Java工具,它提供了编译时的转换,提高了性能和可维护性。相较于手动硬编码和反射赋值,MapStruct在性能和便捷性上具有优势。通过引入Maven依赖、定义实体对象和Mapper接口,可以轻松实现对象间的转换。
本文介绍了MapStruct,一种用于对象转换的Java工具,它提供了编译时的转换,提高了性能和可维护性。相较于手动硬编码和反射赋值,MapStruct在性能和便捷性上具有优势。通过引入Maven依赖、定义实体对象和Mapper接口,可以轻松实现对象间的转换。
当然,除了这些简单类以外,还有一些包含业务逻辑的实体类,比如 BO(Business Object):业务对象,由Service层输出的封装业务逻辑的对象。
常见的Object Mapping方式
比较常见的对象转换方式主要有两种,我们可以在很多老代码当中看到它们的身影。
-
调用getter/setter方法手动硬编码属性赋值
-
调用BeanUtil.copyProperties进行反射属性赋值
getter/setter手工硬编码的方式相信很多 Java 开发同学都异常熟练,它的痛点也非常明显,就是当一个类有几十个属性的时候,代码编写效率非常低下,而且丑陋,最重要的是,当新扩展一个字段以后,往往容易忽略在 mapping convert 文件中添加相应的属性映射,给业务带来一定的潜在风险(error-prone)。当然硬编码也不是一无是处的,它的执行效率非常高,这个后文会分析。
而使用BeanUtil.copyProperties的方式进行转换的话就要好一些了,我们可以在业务逻辑当中一行代码就解决掉对象转换的问题,不会使得代码非常冗长,但它的坑也不少,由于使用反射的方式去进行转换,如果涉及到频繁对象转换操作就会有性能问题(后文会有分析),同时对开发者定位问题也不友好,出问题后我们很难定位到字段是在哪里进行的赋值操作。
Object Mapping技术分类
Object Mapping 技术从大的角度来说分为两类,一类是运行期转换,另一类则是编译期转换,它们的区别主要是:
-
运行期反射调用 set/get 或者是直接对成员变量赋值。这种方式通过invoke执行赋值,实现时一般会采用beanutil, Javassist等开源库。运行期对象转换的代表主要是Dozer和ModelMaper。
-
编译期动态生成 set/get 代码的class文件,在运行时直接调用该class的 set/get 方法。该方式实际上仍会存在 set/get 代码,只是不需要开发人员自己写了。这类的代表是:MapStruct,Selma,Orika。
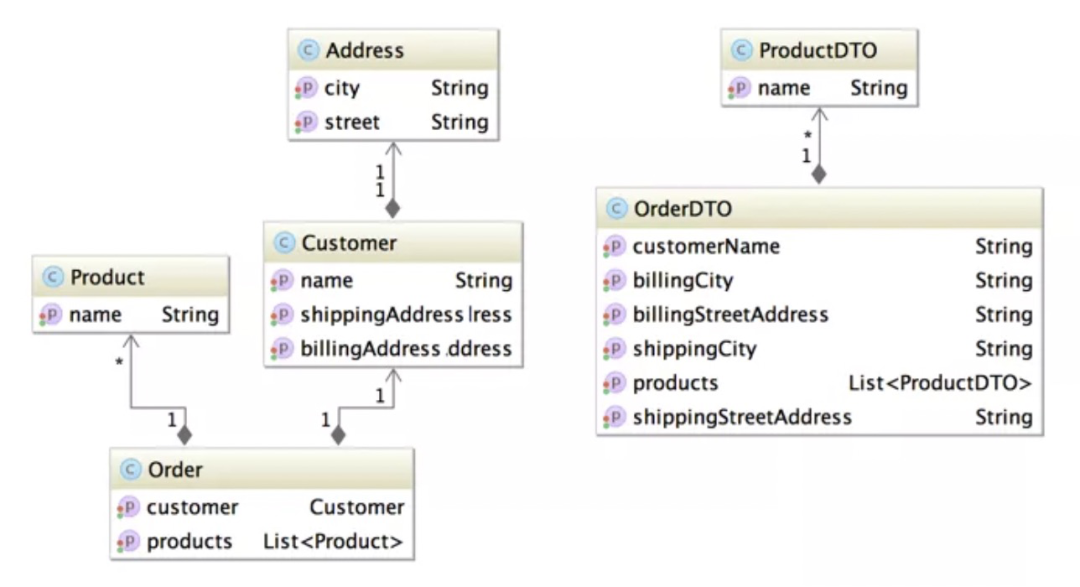
说完它们的区别,那么它们的Object Mapping表现差异究竟如何?我们可以写代码验证,这里方便起见就直接引用 GitHub 上面java-object-mapper-benchmark的项目结果说明,要转换的对象是 Order 实体与 OrderDTO,它们的关联关系如下图所示。
机器配置如下:
-
OS: macOS High Sierra
-
CPU: 3.1 GHz Intel Core i7, 2 cores, L2 Cache (per Core): 256 KB, L3 Cache: 4 MB
-
RAM: 16 GB 1867 MHz DDR3
-
JVM: Oracle 1.8.0_74-b02 64 bits
运行结果如下:
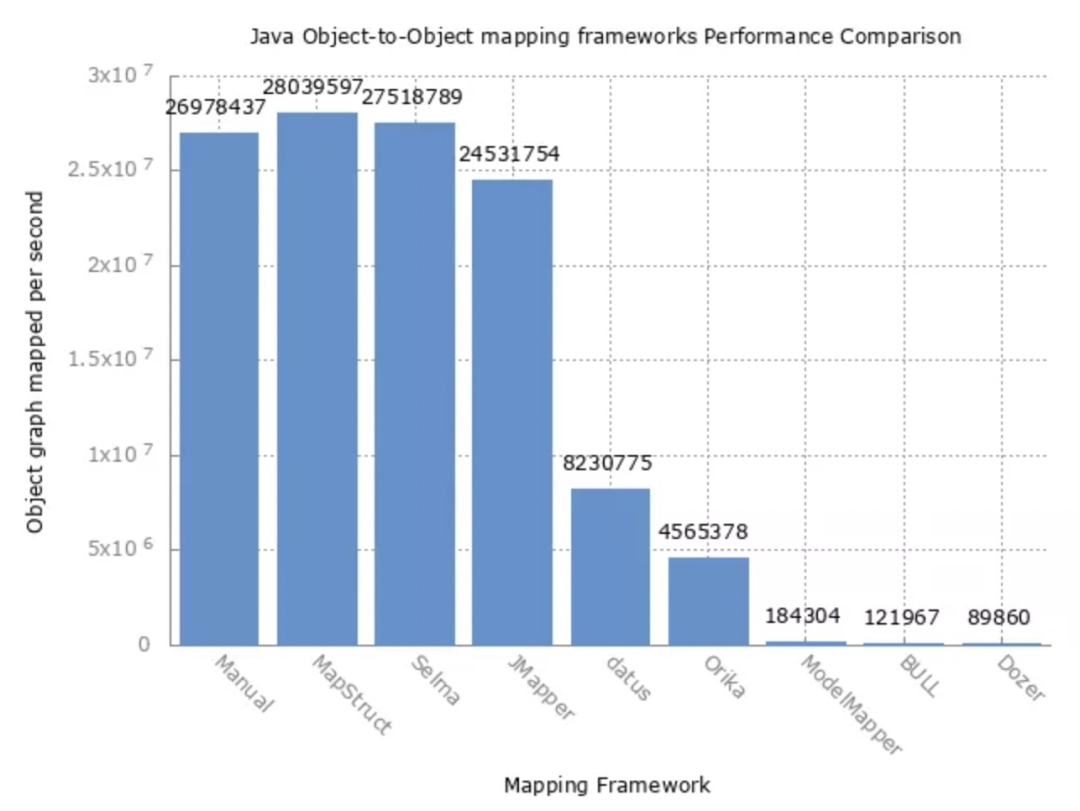
感兴趣的同学可以去把代码下载下来亲自验证一下。从图中可以很明显感受到的是,反射 Object Mapping 确实比 get/set 的方式慢很多。另外,综合比较性能、问题排查、文档、成熟度、扩展性等因素,MapStruct 是一个不错的 Object Mapping 选择。
MapStruct如何使用
- 引入Maven依赖。
… <org.mapstruct.version>1.3.1.Final</org.mapstruct.version>… org.mapstruct mapstruct o r g . m a p s t r u c t . v e r s i o n < / v e r s i o n > < / d e p e n d e n c y > < / d e p e n d e n c i e s > . . . < b u i l d > < p l u g i n s > < p l u g i n > < g r o u p I d > o r g . a p a c h e . m a v e n . p l u g i n s < / g r o u p I d > < a r t i f a c t I d > m a v e n − c o m p i l e r − p l u g i n < / a r t i f a c t I d > < v e r s i o n > 3.5.1 < / v e r s i o n > < c o n f i g u r a t i o n > < s o u r c e > 1.6 <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









