







add the bounding box coordinates and probability score
to our respective lists
rects.append((startX, startY, endX, endY))
confidences.append(scoresData[x])
return a tuple of the bounding boxes and associated confidences
return (rects, confidences)
decode_predictions 函数,在 EAST 文本检测帖子中有详细解释。
然后,解析我们的命令行参数:
construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-i”, “–image”, type=str,
help=“path to input image”)
ap.add_argument(“-east”, “–east”, type=str,
help=“path to input EAST text detector”)
ap.add_argument(“-c”, “–min-confidence”, type=float, default=0.5,
help=“minimum probability required to inspect a region”)
ap.add_argument(“-w”, “–width”, type=int, default=320,
help=“nearest multiple of 32 for resized width”)
ap.add_argument(“-e”, “–height”, type=int, default=320,
help=“nearest multiple of 32 for resized height”)
ap.add_argument(“-p”, “–padding”, type=float, default=0.0,
help=“amount of padding to add to each border of ROI”)
args = vars(ap.parse_args())
我们的脚本需要两个命令行参数:
–image :输入图像的路径。
–east :预训练 EAST 文本检测器的路径。
或者,可以提供以下命令行参数:
-
–min-confidence :检测到的文本区域的最小概率。
-
–width :我们的图像在通过 EAST 文本检测器之前将调整到的宽度。 我们的检测器需要 32 的倍数。
-
–height :与宽度相同,但用于高度。 同样,我们的检测器需要 32 的倍数来调整高度。
-
–padding :添加到每个 ROI 边框的(可选)填充量。 如果您发现 OCR 结果不正确,您可以尝试使用 0.05 表示 5% 或 0.10 表示 10%(依此类推)。
从那里,我们将加载+预处理我们的图像并初始化关键变量:
load the input image and grab the image dimensions
image = cv2.imread(args[“image”])
orig = image.copy()
(origH, origW) = image.shape[:2]
set the new width and height and then determine the ratio in change
for both the width and height
(newW, newH) = (args[“width”], args[“height”])
rW = origW / float(newW)
rH = origH / float(newH)
resize the image and grab the new image dimensions
image = cv2.resize(image, (newW, newH))
(H, W) = image.shape[:2]
图像被加载到内存中并被复制(以便我们稍后可以在其上绘制我们的输出结果)。
我们获取原始宽度和高度,然后从 args 字典中提取新的宽度和高度。 使用原始尺寸和新尺寸,我们计算用于稍后在脚本中缩放边界框坐标的比率。 然后我们的图像被调整大小,忽略纵横比。 接下来,让我们使用 EAST 文本检测器:
define the two output layer names for the EAST detector model that
we are interested in – the first is the output probabilities and the
second can be used to derive the bounding box coordinates of text
layerNames = [
“feature_fusion/Conv_7/Sigmoid”,
“feature_fusion/concat_3”]
load the pre-trained EAST text detector
print(“[INFO] loading EAST text detector…”)
net = cv2.dnn.readNet(args[“east”])
我们的两个输出层名称以列表形式列出。 要了解为什么这两个输出名称很重要,您需要参考我的原始 EAST 文本检测教程。
然后,我们预训练的 EAST 神经网络被加载到内存中。 我再怎么强调都不为过:您至少需要 OpenCV 3.4.2 才能拥有 cv2.dnn.readNet 实现。接下来:
construct a blob from the image and then perform a forward pass of
the model to obtain the two output layer sets
blob = cv2.dnn.blobFromImage(image, 1.0, (W, H),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
net.setInput(blob)
(scores, geometry) = net.forward(layerNames)
decode the predictions, then apply non-maxima suppression to
suppress weak, overlapping bounding boxes
(rects, confidences) = decode_predictions(scores, geometry)
boxes = non_max_suppression(np.array(rects), probs=confidences)
为了确定文本位置,我们:
-
构造一个 blob。
-
将 blob 通过神经网络,获得分数和几何。
-
使用先前定义的 decode_predictions 函数解码预测。 通过我的 imutils 方法应用非最大值抑制。 NMS 有效地获取最可能的文本区域,消除其他重叠区域。
现在我们知道文本区域的位置,我们需要采取措施来识别文本! 我们开始遍历边界框并处理结果,为实际文本识别做好准备:
initialize the list of results
results = []
loop over the bounding boxes
for (startX, startY, endX, endY) in boxes:
scale the bounding box coordinates based on the respective
ratios
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
in order to obtain a better OCR of the text we can potentially
apply a bit of padding surrounding the bounding box – here we
are computing the deltas in both the x and y directions
dX = int((endX - startX) * args[“padding”])
dY = int((endY - startY) * args[“padding”])
apply padding to each side of the bounding box, respectively
startX = max(0, startX - dX)
startY = max(0, startY - dY)
endX = min(origW, endX + (dX * 2))
endY = min(origH, endY + (dY * 2))
extract the actual padded ROI
roi = orig[startY:endY, startX:endX]
我们初始化结果列表以包含OCR 边界框和文本。
然后我们开始遍历框,我们:
-
根据先前计算的比率缩放边界框。
-
填充边界框。
-
最后,提取填充的 roi(第 144 行)。
我们的 OpenCV OCR 管道可以通过使用一点 Tesseract v4 “魔法”来完成:
in order to apply Tesseract v4 to OCR text we must supply
(1) a language, (2) an OEM flag of 4, indicating that the we
wish to use the LSTM neural net model for OCR, and finally
(3) an OEM value, in this case, 7 which implies that we are
treating the ROI as a single line of text
config = (“-l eng --oem 1 --psm 7”)
text = pytesseract.image_to_string(roi, config=config)
add the bounding box coordinates and OCR’d text to the list
of results
results.append(((startX, startY, endX, endY), text))
记下代码块中的注释,设置了 Tesseract 配置参数。
注意:如果您发现自己获得了不正确的 OCR 结果,您可能需要使用本教程顶部的说明配置 --psm 值。
pytesseract 库负责处理我们调用 pytesseract.image_to_string 的第 152 行的其余部分,传递我们的 roi 和 config string 。
接下来的两行代码中,您使用 Tesseract v4 识别图像中的文本 ROI。
请记住,幕后发生了很多事情。 我们的结果(边界框值和实际文本字符串)被附加到结果列表中。 然后我们对循环顶部的其他 ROI 继续这个过程。 现在让我们显示/打印结果,看看它是否真的有效:
sort the results bounding box coordinates from top to bottom
results = sorted(results, key=lambda r:r[0][1])
loop over the results
for ((startX, startY, endX, endY), text) in results:
display the text OCR’d by Tesseract
print(“OCR TEXT”)
print(“========”)
print(“{}\n”.format(text))
strip out non-ASCII text so we can draw the text on the image
using OpenCV, then draw the text and a bounding box surrounding
the text region of the input image
text = “”.join([c if ord© < 128 else “” for c in text]).strip()
output = orig.copy()
cv2.rectangle(output, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(output, text, (startX, startY - 20),
cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 3)
show the output image
cv2.imshow(“Text Detection”, output)
cv2.waitKey(0)
我们的结果根据边界框的 y 坐标从上到下排序(尽管您可能希望对它们进行不同的排序)。然后,循环结果,我们:
-
将 OCR 的文本打印到终端。
-
从文本中去除非 ASCII 字符,因为 OpenCV 不支持 cv2.putText 函数中的非 ASCII 字符。
-
绘制 (1) 围绕 ROI 的边界框和 (2) ROI 上方的结果文本。
-
显示输出并等待按下任意键。
========================================================================
现在我们已经实现了我们的 OpenCV OCR 管道,让我们看看它的运行情况。
打开一个命令行,导航到您下载并解压缩 zip 的位置,然后执行以下命令:
python text_recognition.py --east frozen_east_text_detection.pb \
–image images/example_01.jpg
[INFO] loading EAST text detector…
OCR TEXT
========
OH OK
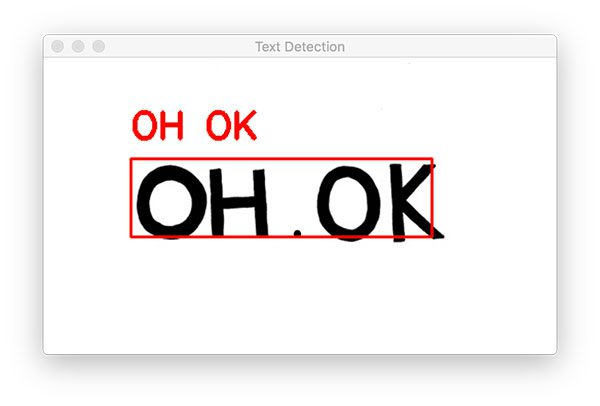
我们从一个简单的例子开始。 请注意我们的 OpenCV OCR 系统如何能够正确 (1) 检测图像中的文本,然后 (2) 也识别文本。 下一个示例更能代表我们在现实世界图像中看到的文本:
python text_recognition.py --east frozen_east_text_detection.pb \
–image images/example_02.jpg
[INFO] loading EAST text detector…
OCR TEXT
========
® MIDDLEBOROUGH

=============================================================
在今天的教程中,您学习了如何应用 OpenCV OCR 来执行以下两项操作:
-
文本检测
-
文字识别
为了完成这项任务,我们:
-
利用 OpenCV 的 EAST 文本检测器,使我们能够应用深度学习来定位图像中的文本区域
-
我们提取了每个文本 ROI,然后使用 OpenCV 和 Tesseract v4 应用文本识别。 我们还研究了在单个脚本中执行文本检测和文本识别的 Python 代码。
我们的 OpenCV OCR 管道在某些情况下运行良好,但在其他情况下也失败了。为了获得最佳的 OpenCV 文本识别结果,我建议您确保:
- 尽可能多地清理和预处理您的输入 ROI。在理想的世界中,您的文本会与图像的其余部分完美分割,但实际上,这并不总是可能的。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

b93cf63939786134ca.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)
[外链图片转存中…(img-83g7oOaT-1711874178356)]














 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









