






Ollama 是一个用于在本地部署和管理大型语言模型(LLM,Large Language Models)的工具。简单来说,它就像 “搬运工” 一样,可以帮助你将一些强大的 AI 模型(比如类似 ChatGPT 的模型)下载、安装到你的电脑上,然后通过简单的命令让这些模型工作起来。
对于不懂编程或 AI 的朋友来说,Ollama 降低了使用大型 AI 模型的门槛,无需复杂的编程和云服务器配置,只要你的电脑硬件够用,就可以在本地体验 AI 聊天、文本生成、问答等功能。
为什么需要 Ollama?
-
• 本地部署、安全可靠:所有模型数据都存储在你的电脑上,不必担心数据上传到云端带来的隐私风险。
-
• 简化操作:Ollama 将复杂的模型下载、安装、运行过程标准化,使用起来像运行一个命令行工具,非常简单。
-
• 多平台支持:它支持 Windows、macOS、Linux 甚至 Docker 环境,满足不同用户的需求。
-
• 开放与扩展:你不仅可以使用官方预设的模型,还可以自定义和扩展模型,接入其他工具(如知识库系统、Web UI 等)。
安装部署篇
如何安装 Ollama?
Windows: 打开 https://ollama.com/download,选择对应的平台(Windows),点击下载 OllamaSetup.exe 并安装即可。
Macos: 执行下面的命令:
brew install ollama
Linux: 执行下面的命令:
curl -fsSL <https://ollama.com/install.sh> | sh
Docker 运行 Ollama
CPU
docker run -d -v ollama:/root/.ollama \ -p 11434:11434 --name ollama \ ollama/ollama
Nvidia GPU
docker run -d --gpus=all \ -v ollama:/root/.ollama -p 11434:11434 \ --name ollama ollama/ollama
AMD GPU
docker run -d --device /dev/kfd \ --device /dev/dri -v ollama:/root/.ollama \ -p 11434:11434 --name ollama \ ollama/ollama:rocm
Kubernetes 运行 Ollama
配置 Helm Chart
helm repo add ollama <https://feisky.xyz/ollama-kubernetes> helm repo update
部署 Ollama
helm upgrade --install ollama ollama/ollama \ --namespace=ollama \ --create-namespace
开启端口转发
kubectl -n ollama port-forward \ service/ollama-webui 8080:80
访问 WebUI:

Ollama 运行 DeepSeek R1 模型
打开命令行终端,然后运行:
ollama run deepseek-r1
然后愉快的玩耍吧

模型配置篇
下载模型
你可以用 ollama pull 下载 Ollama 支持的 官方模型,比如
ollama pull deepseek-r1
具体支持的模型列表,可以到 https://ollama.com/library 查看,主流的开源大模型都在支持列表里。
模型加载状态
使用 ollama ps 命令查看当前加载到内存中的模型:
ollama ps
输出:
NAME ID SIZE PROCESSOR UNTIL llama3:70b bcfb190ca3a7 42 GB 100% GPU 4 minutes from now
PROCESSOR 列会显示模型加载的内存位置:
-
• 100% GPU 表示模型完全加载到 GPU 显存
-
• 100% CPU 表示模型完全加载到系统内存
-
• 48%/52% CPU/GPU 表示模型同时加载到 GPU 显存和系统内存
设置模型参数
每个模型在加载时都已经内置了一些默认的参数,你可以通过 /show 命令查看:
# ollama run deepseek-r1 >>> /show parameters Model defined parameters: stop "<|begin▁of▁sentence|>" stop "<|end▁of▁sentence|>" stop "<|User|>" stop "<|Assistant|>"
如果这些参数不符合你的要求,你还可以使用 /set 命令进行修改。
比如,默认情况下,Ollama 上下文窗口大小为 2048,要改成 4096 可以执行:
# ollama run deepseek-r1 >>> /set parameter num_ctx 4096 >>> /set system "<system message>"
使用 API 时,指定 num_ctx 参数:
curl http://localhost:11434/api/generate -d '{ "model": "llama3.2", "prompt": "Why is the sky blue?", "options": { "num_ctx": 4096 } }'
模型存储路径
默认情况下,Ollama 的存储路径为:
-
• macOS:
~/.ollama/models -
• Linux:
/usr/share/ollama/.ollama/models -
• Windows:
C:\Users\%username%\.ollama\models
如果你想切换模型存储路径,可以为 Ollama 设置 OLLAMA_MODELS 环境变量,如
export OLLAMA_MODELS=/data ollama serve
模型预加载与卸载
默认情况下,模型会在内存中保留 5 分钟后卸载。如果短时间向 LLM 发送大量请求,这可以提供更快的响应时间。
如果你觉得 5 分钟太短,也可以设置 OLLAMA_KEEP_ALIVE 环境变量增长这个时间,比如:
# 设置为 1 小时 export OLLAMA_KEEP_ALIVE=1h
如果您想立即从内存中卸载模型,请使用 ollama stop 命令:
ollama stop deepseek-r1
启用 Flash Attention
Flash Attention 是大多数现代模型的一项功能,可以在上下文大小增加时显著减少内存使用。
要启用 Flash Attention,请在启动 Ollama 服务器时将 OLLAMA_FLASH_ATTENTION 环境变量设置为 1。
设置 K/V 缓存的量化类型
启用 Flash Attention 时,K/V 上下文缓存可以进行量化,以显著减少内存使用。
要在 Ollama 中使用量化的 K/V 缓存,可以设置 OLLAMA_KV_CACHE_TYPE 环境变量:
-
•
f16- 高精度和高内存使用(默认)。 -
•
q8_0- 8 位量化,使用约为 f16 一半的内存,精度损失非常小,这通常对模型质量没有明显影响。 -
•
q4_0- 4 位量化,使用约为 f16 四分之一的内存,在较大上下文大小时会出现精度损失。
缓存量化对模型质量的影响:
通常 GQA 分高的模型(比如 Qwen2)可能比 GQA 分低的模型更容易受到量化对精度影响。
建议你尝试不同的量化类型,通过测试找到内存使用与质量之间最佳平衡点。
API 访问
默认情况下,Ollama 会监听在 11434 端口,并提供了 OpenAI 兼容的 API。
所以在支持 OpenAI API 的服务或者框架代码中,你都可以无缝集成 Ollama。只要替换 OpenAI baseURL 为 http://localhost:11434/v1/ 即可。
注意:如果你在公有云或者通过反向代理访问 Ollama API 时,一定要额外给 Ollama API 加上认证(比如可以用 Nginx 反向代理加上认证功能)。
运行第三方 GGUF 模型
GGUF 是 llama.cpp 定义的一种高效存储和交换大模型预训练结果的二进制格式。你可以通过 Modelfile 文件中导入 GGUF 模型。
首先创建一个 Modelfile:
FROM <model-path>.gguf PARAMETER temperature 1 PARAMETER num_ctx 4096 SYSTEM You are Mario from super mario bros, acting as an assistant.
然后,执行下面的命令加载运行模型:
# 你可以加上 -q Q4_K_M 对模型量化 ollama create myllama -f Modelfile ollama run myllama
对于其他格式的模型,你可以通过 llama.cpp 转换为 GGUF 格式再使用。
模型需要多大显存
以 DeepSeek R1 为例,以下是各个版本需要的显存以及推荐 GPU 配置:
|
模型版本
| 参数量 (B) | 所需显存 (GB) |
| NVIDIA RTX 4090 24GB ×2 |
https://tools.thinkinai.xyz/ 提供了一个方便易用的 DeepSeek 模型兼容性检测工具,你也可以用它来检查你的电脑可以运行哪个版本。
注:
显存计算公式:
显存 ≈ 参数量 × 精度位数(Bytes)+ 激活值占用
实际部署建议预留 20% 冗余(如 7B FP16 建议 18GB+ 显存)
内存要求:
内存需加载模型权重(约等于显存)及运行时数据,建议为显存的 1.5 倍
量化影响:
8-bit 量化显存占用减半,4-bit 再减半,但可能损失 1-3% 精度
Ollama 默认使用 4-bit 量化模型,显存占用约为 FP16 的 1/4
工具集成篇
聊天 - Cherry Studio(推荐)
Cherry Studio 是一款集多模型对话、知识库管理、AI 绘画、翻译等功能于一体的全能 AI 助手平台 ,适用于Windows、Mac和Linux。
你可以到 https://cherry-ai.com/ 下载并安装 Cherry Studio。
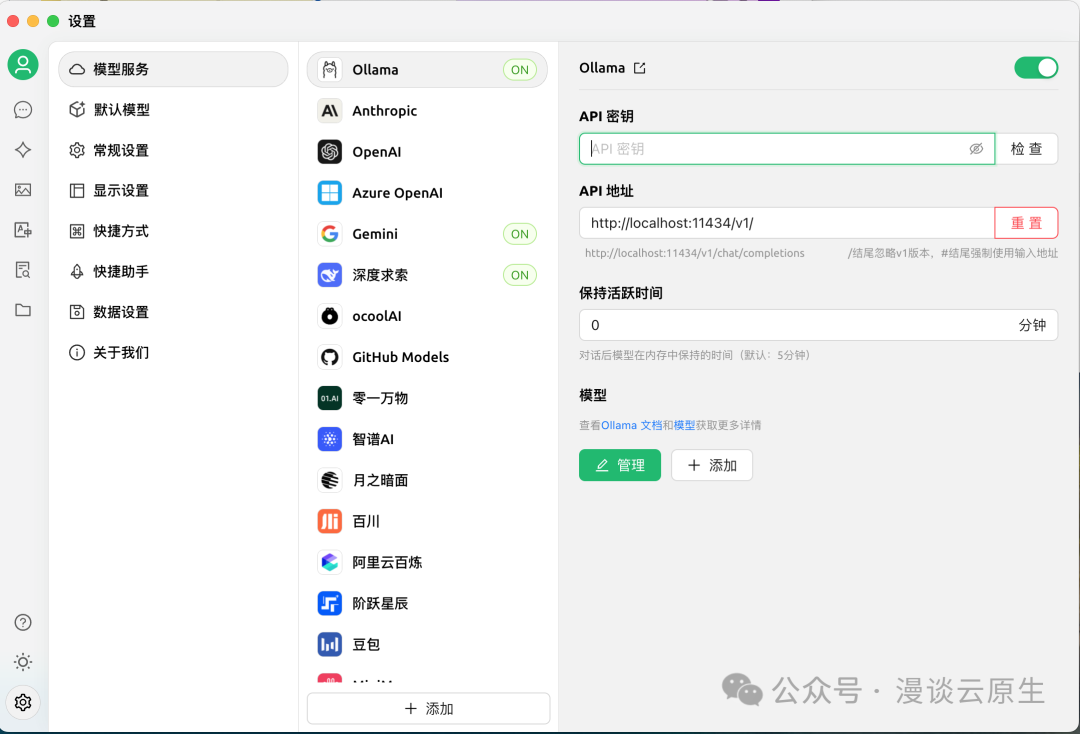
然后,点击左下角的设置,选择 Ollama,在 API 地址中填入 http://localhost:11434/v1/:
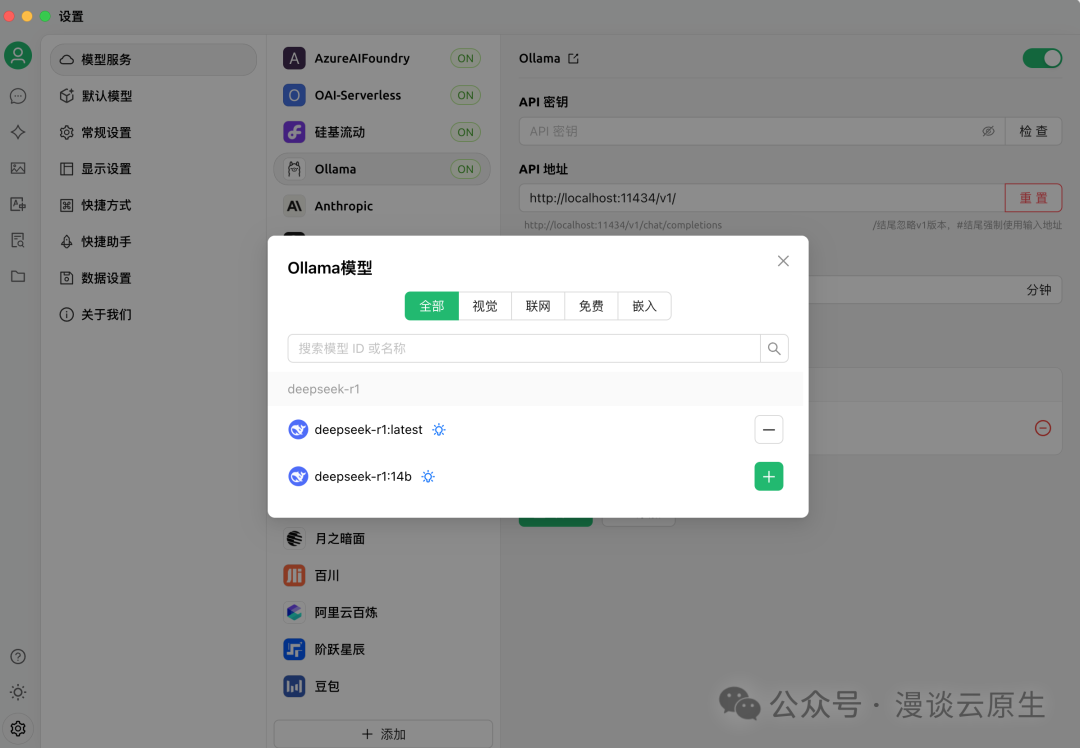
然后点击“模型”下面的“管理”,在弹出的模型列表中选择你想使用的模型(这些都是你已经下载到本地的模型):
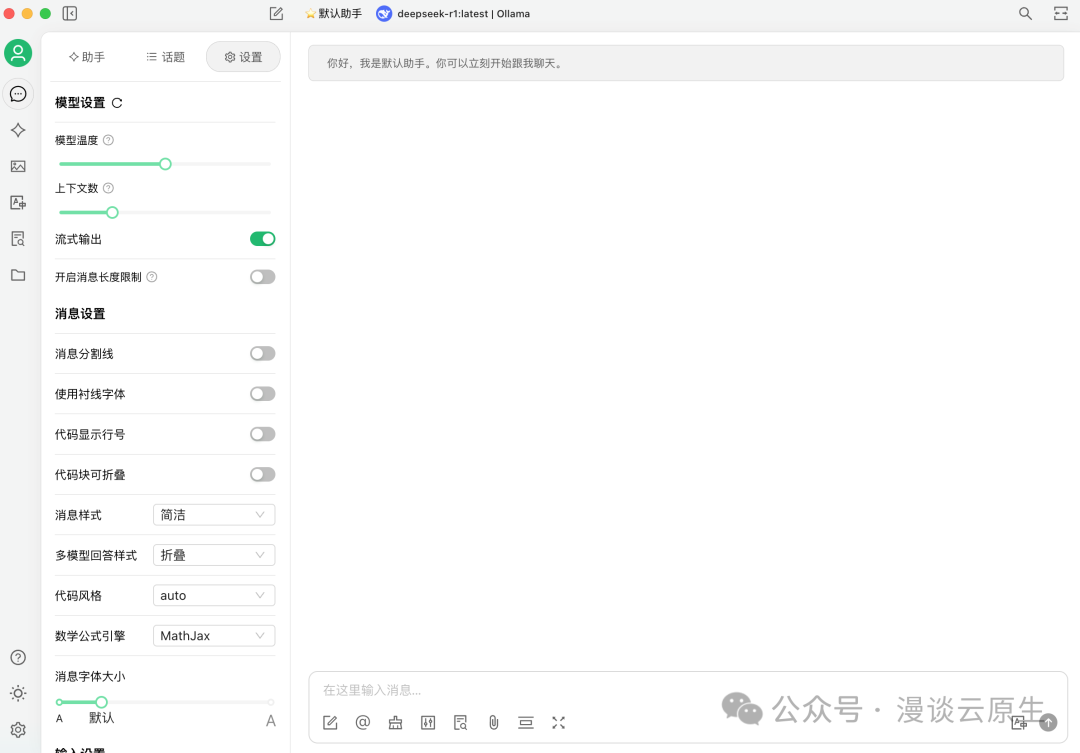
最后回到聊天界面,选择你的模型,就可以开始聊天了:
注:Cherry Studio 本身不直接提供联网功能。但你可以使用支持联网的模型(比如 Google Gemini 或者腾讯混元)来进行网络搜索。
聊天 - Chatbox
Chatbox 是一款 AI 客户端应用和智能助手,支持主流的 AI 模型,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
你可以到 https://chatboxai.app/zh 下载并安装 Chatbox。
安装后点击设置,模型提供方选择 OLLAMA API,API 域名填入 http://localhost:11434,模型选择你要聊天的模型(比如 DeepSeek R1):
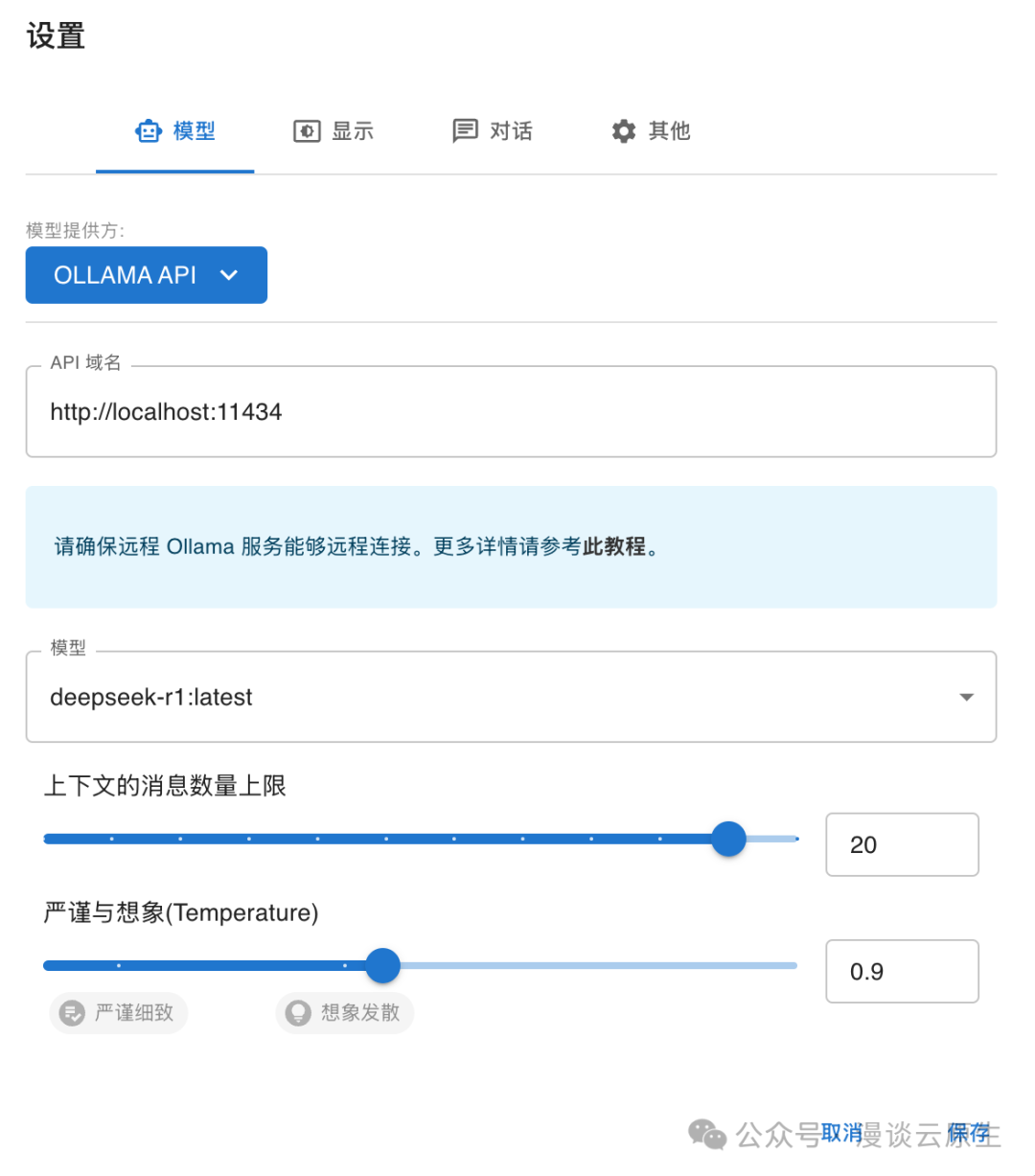
最后回到聊天界面,就可以开始聊天了:
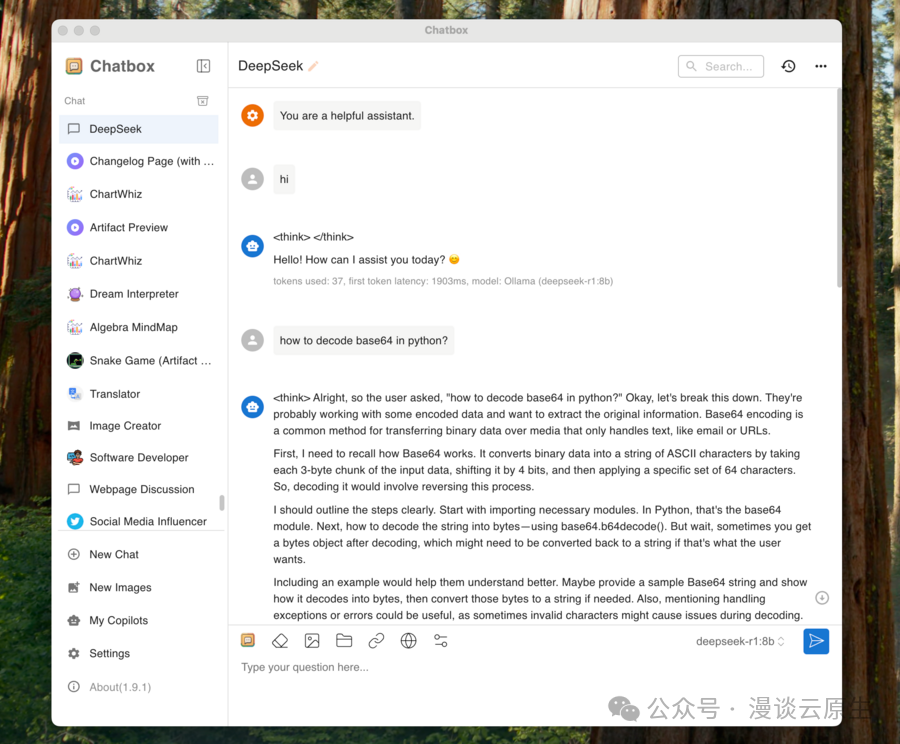
注:Chatbox 同样不直接提供联网功能。但你可以使用支持联网的模型(比如 Google Gemini、Perplexity等)来进行网络搜索。
聊天 - VSCode + ChatGPT Copilot
如果你经常使用 VSCode 进行文档撰写和编程,你还可以使用 VSCode 中的 ChatGPT Copilot 插件。这个插件提供了类似 ChatGPT 的功能(包括基本聊天、文件和图片聊天,代码修复、代码解释、自定义 Prompt等),支持主流的各大模型提供商,主打一个简单直观。
你可以在 VSCode 插件市场中搜索 ChatGPT Copilot 安装:
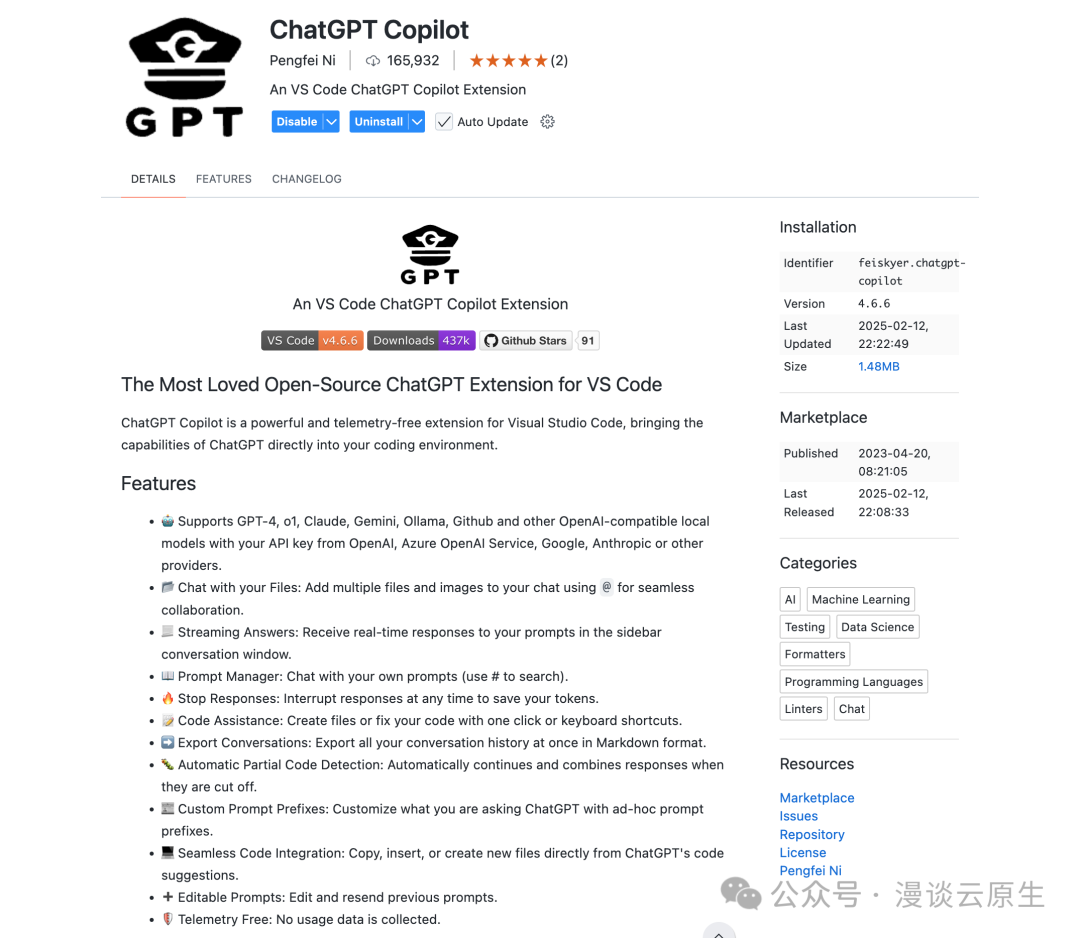
然后打开插件设置,配置你的模型(如 DeepSeek-R1)并填入 Api Base Url 为 http://localhost:11434/v1/:
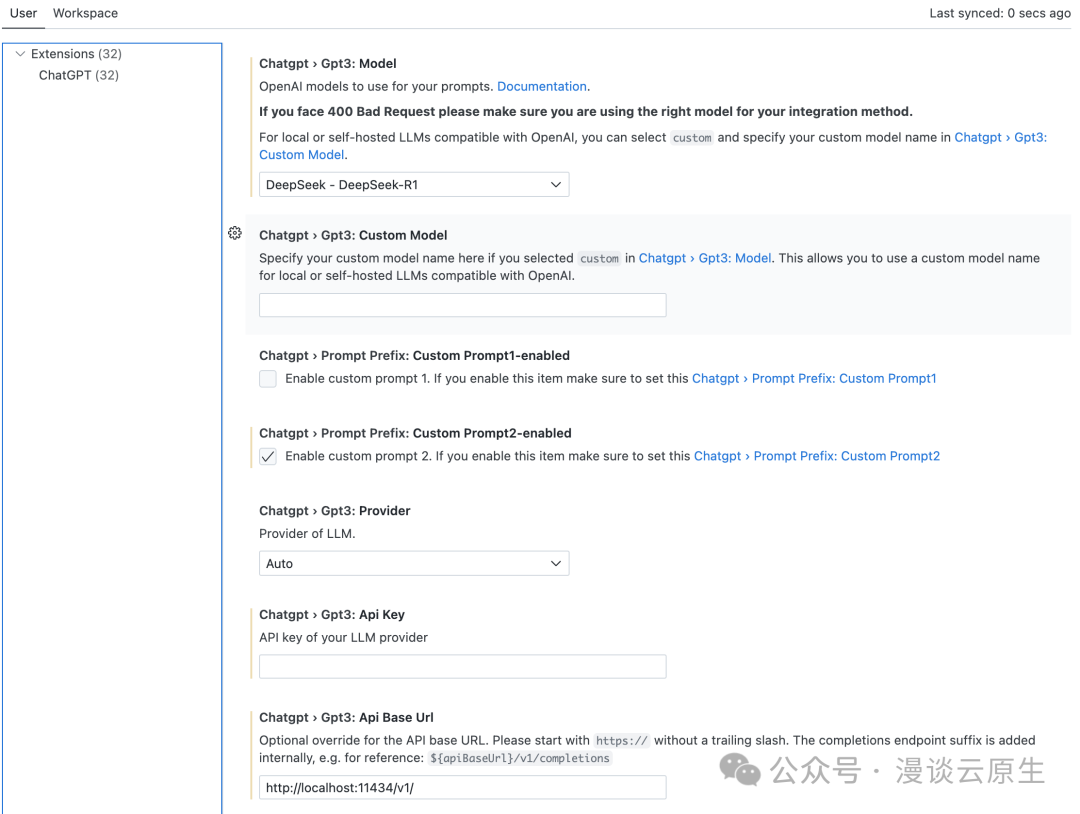
最后,到侧边栏打开 ChatGPT Copilot 聊天窗口,就可以开始使用了。
注意:ChatGPT Copilot 不直接提供代理和联网的功能(可使用支持联网的Gemini联网),主打一个简单易用,可以用于在 VSCode 中替代 ChatGPT 聊天。
编程 - VSCode + Cline
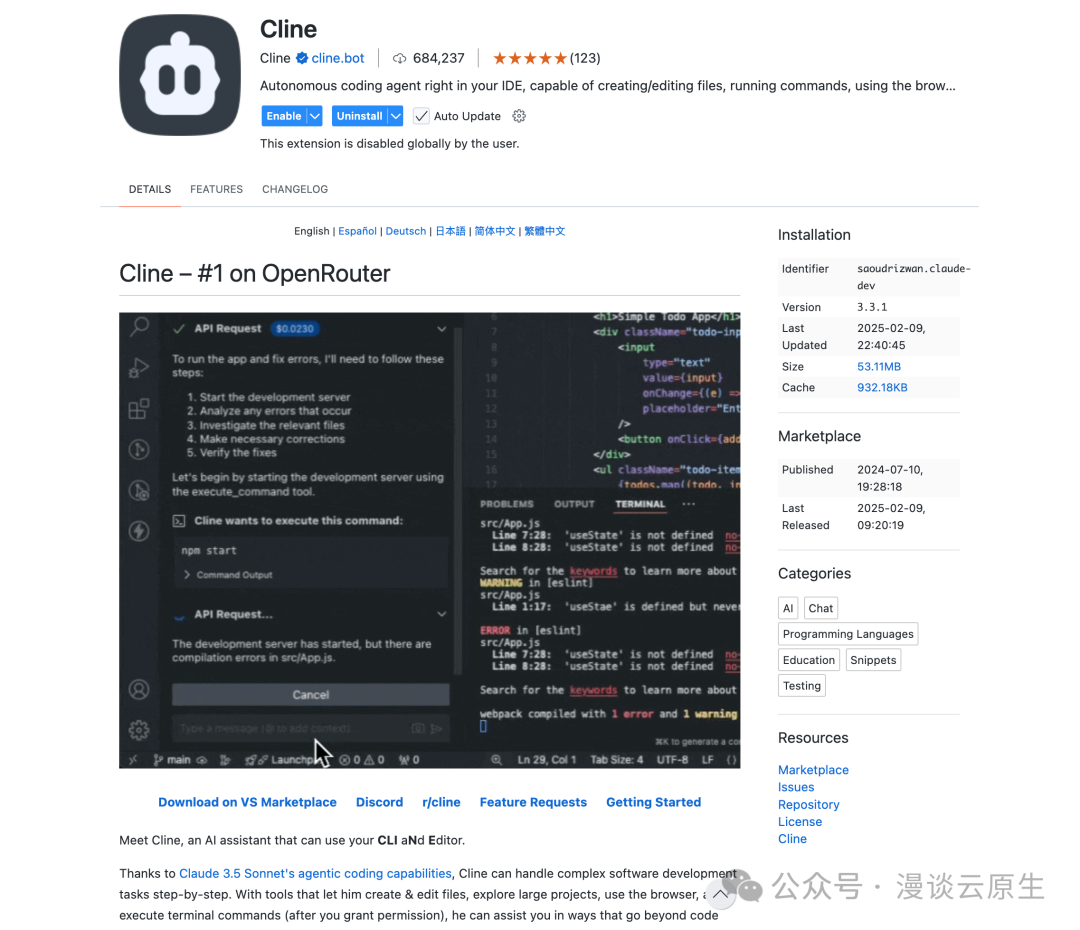
Cline 是一个 VSCode 插件,用于替代 Cursor,实现自动化编程,主打一个免费。
你可以在 VSCode 插件市场中搜索 Cline 安装:
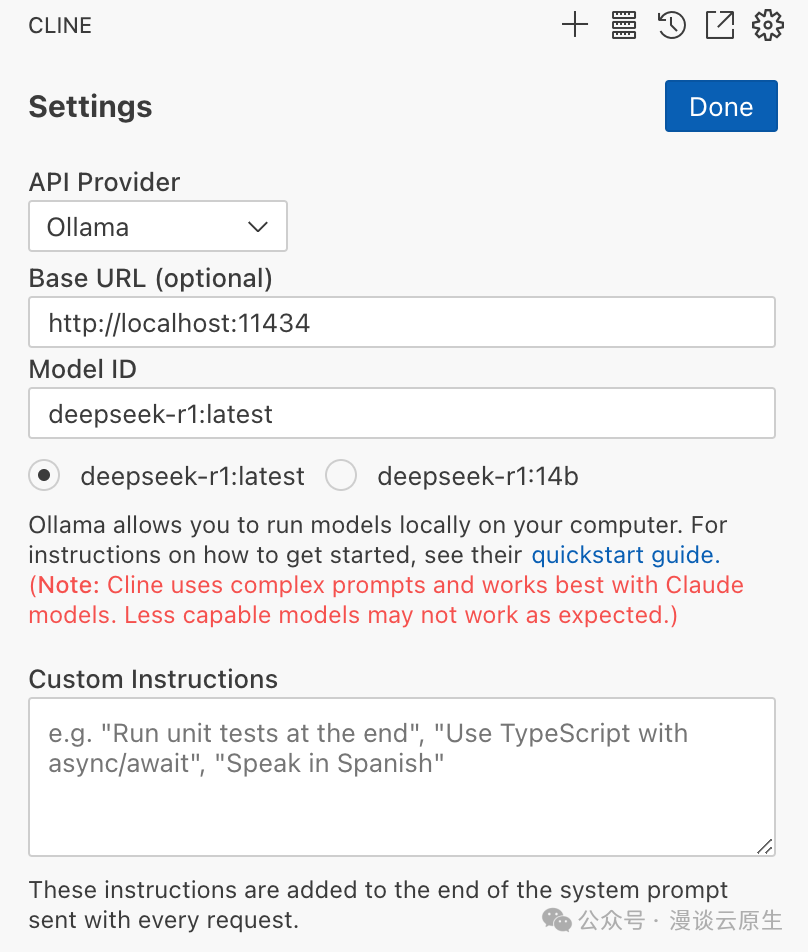
然后,打开插件设置,选择 API Provider 为 Ollama,配置你的模型(如 DeepSeek-R1)并填入 Base URL 为 http://localhost:11434:
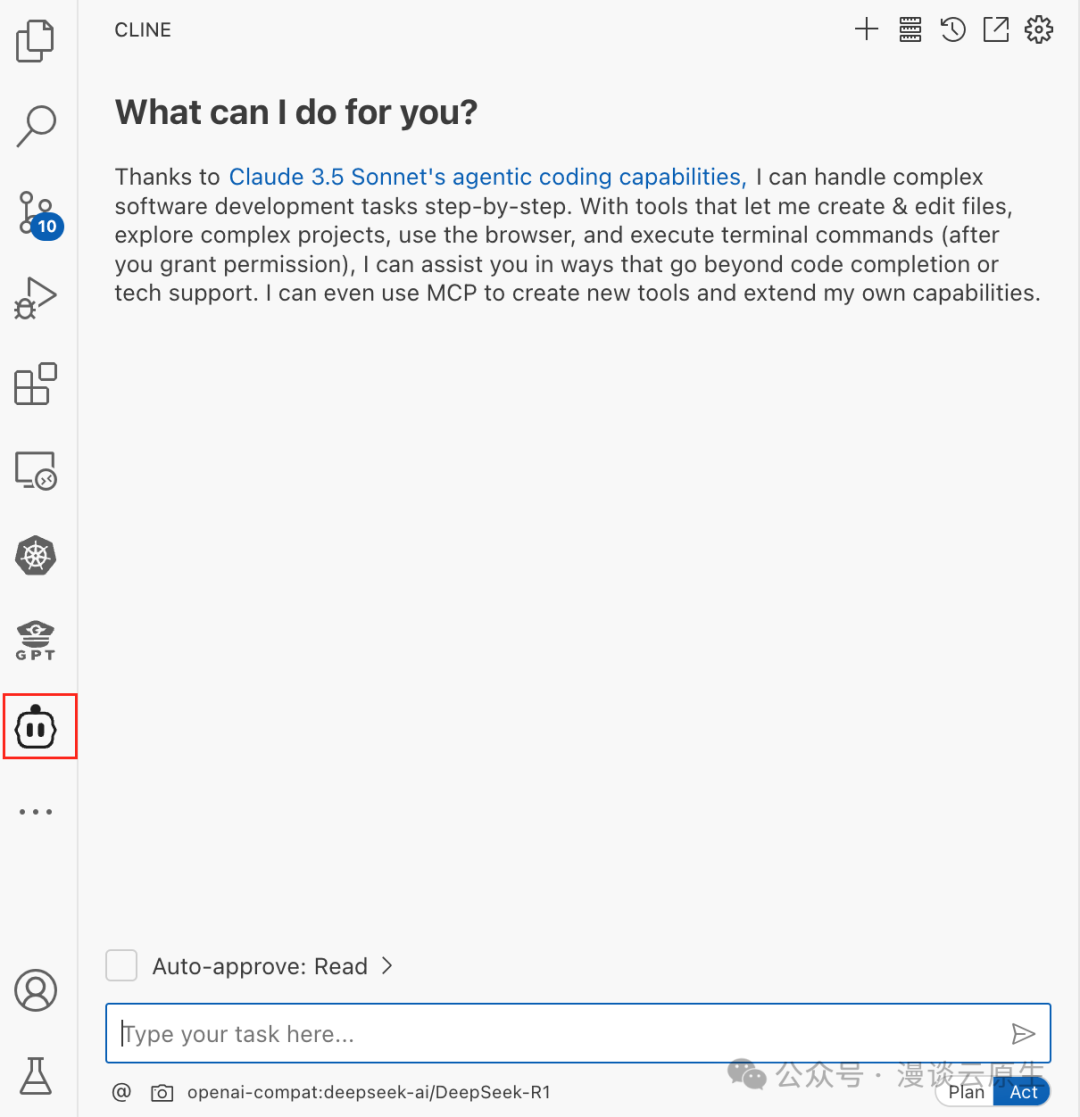
最后,打开侧边栏 Cline 的聊天窗口,提交你的任务就可以让 AI 帮你开发了。
注:实际体验上,Cline 不如 Cursor 好用,且消耗 token 特别快。对于使用 Ollama 来说不用关心 token 消耗问题,但在使用第三方 API 时需要特别小心,不要超支。
编程 - Cursor
Cursor 是一款目前功能最强大的 AI 编程神器,不仅可以像 Github Copilot 那样提供编程建议,还可以通过代理(Composer)自动实现你想要的功能并自动修复开发过程中的问题。Cursor 提供一定的免费额度,超额后需要订阅($20/月)。
但是很不幸的是,Ollama 提供的 API 跟 Cursor 的调用方式并不兼容,所以并不能直接在 Cursor 中使用 Ollama 模型。如果你想体验 Deepseek R1,可以订阅 Cursor,或者使用硅基流动、DeepSeek 或者各大公有云提供的 API。
API 直接调用
对于开发者来说,你还可以通过 API/SDK 直接调用 Ollama API,直接跟大模型进行交互。
Ollama 支持两种格式的 API:
第一种是 Ollama 自身 API,你可以执行 pip install ollama 安装 Ollama 提供的 SDK,然后调用 SDK 使用大模型:
from ollama import chat from ollama import ChatResponse response: ChatResponse = chat(model='deepseek-r1', messages=[ { 'role': 'user', 'content': 'Why is the sky blue?', }, ]) print(response['message']['content']) print(response.message.content)
第二种是 OpenAI 兼容的 API,可以通过 OpenAI API 进行调用。比如执行 pip install openai 安装 OpenAI SDK 后,通过下面的方式调用 Ollama:
from openai import OpenAI client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama") completion = client.chat.completions.create( model="deepseek-r1", messages=[ {"role": "system", "content": "You are a helpful assistant."}, { "role": "user", "content": "Write a haiku about recursion in programming." } ] ) print(completion.choices[0].message.content)
总结
使用 Ollama 本地运行大模型的好处:
-
• 本地化部署:无需依赖云端服务,保护数据隐私
-
• 极简操作:命令行一键式管理模型(下载/加载/卸载)
-
• 硬件友好:支持多平台运行,智能分配 CPU/GPU 资源
-
• 开放生态:兼容主流开源模型及社区工具链
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









