







本文介绍了如何使用PolarDB、通义千问和LangChain搭建GraphRAG系统,结合知识图谱和向量检索提升问答质量。通过实例展示了单独使用向量检索和图检索的局限性,并通过图+向量联合搜索增强了问答准确性。PolarDB支持AGE图引擎和pgvector插件,实现图数据和向量数据的统一存储与检索,提升了RAG系统的性能和效果。
业务场景
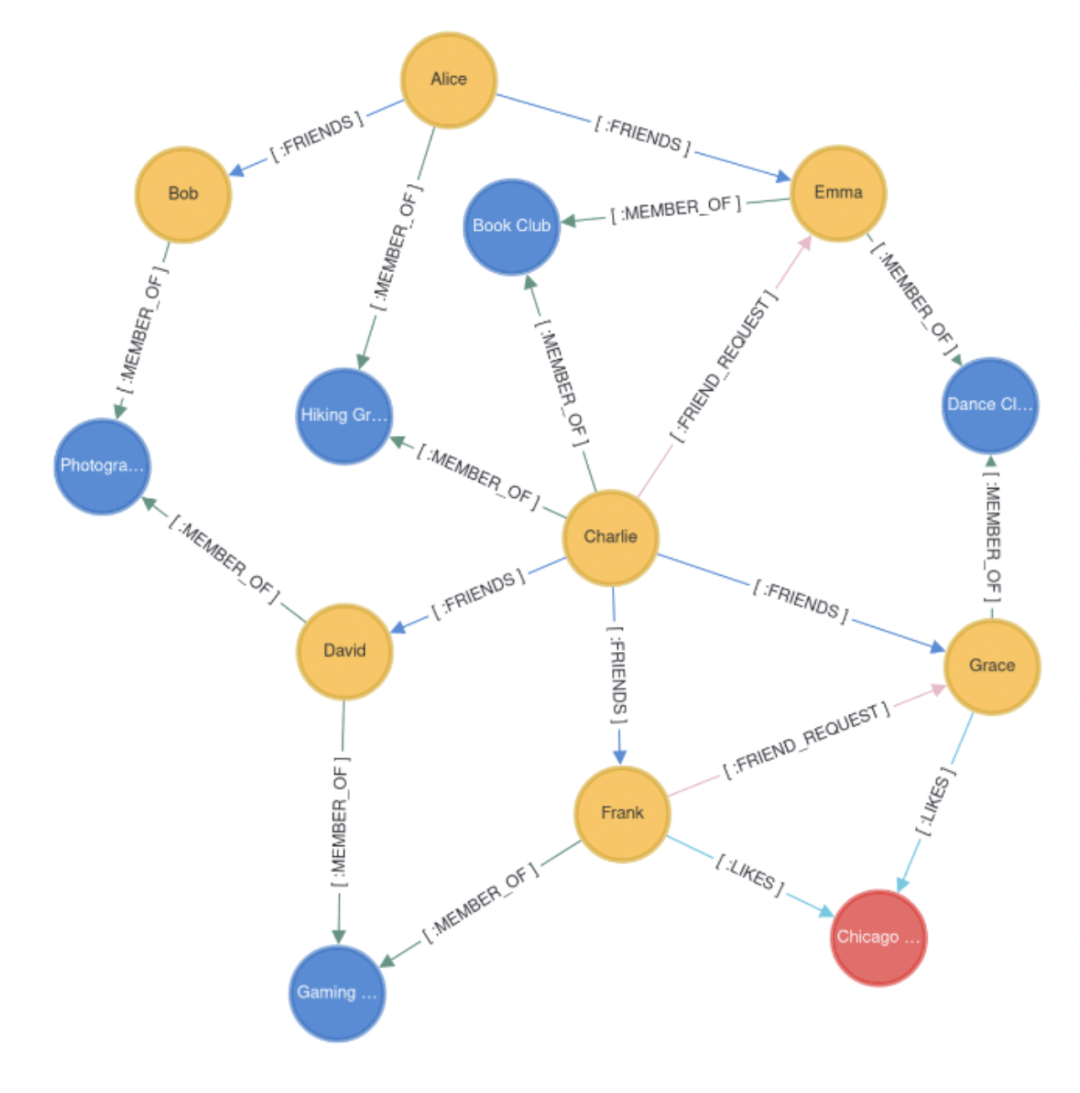
知识图谱
知识图谱(KG)是谷歌提出的一种知识表示形式,它通过互联的节点和实体捕捉知识,以结构化的形式表示关系和信息。
知识图谱具有以下优势:
-
结构化信息:知识图谱将信息以节点(实体)和边(关系)的形式组织,使得复杂信息结构化,便于存储和查询。
-
语义理解:通过明确的关系定义,知识图谱可以帮助系统更好地理解信息之间的语义关系,提升信息检索和自然语言处理的效果。
-
知识关联性:知识图谱能够将不同的知识点联系起来,形成更丰富的知识网络,帮助用户发现隐藏的关联。
-
支持推理:基于知识图谱,系统可以进行逻辑推理,从已知的信息推导出新的信息,提高智能应用的能力。
-
可视化:知识图谱通常可以通过图形化的方式展示,使得复杂关系一目了然,便于用户理解和分析。
知识图谱被广泛应用于金融风控,企业知识管理以及社交网络分析等多种业务场景中。
RAG
检索增强生成(Retrieval Augemented Generation, RAG)作为一种强大的技术,它结合了信息检索与生成模型的创新方法,用来解决大语言模型(LLM)的局限性问题。
RAG通过利用从各种来源检索到的相关数据来增强 LLM 提示,来实现更为准确和上下文相关的文本生成。RAG 系统的准确性在很大程度上依赖于它们获取相关、可验证信息的能力。
RAG中信息检索通常使用诸如关键词匹配或语义相似性等技术来实现的。在语义相似性中,例如,数据被表示为由AI嵌入模型生成的数值向量,这些向量试图捕捉其含义。前提是,相似的向量在向量空间中相互靠近,然后通过近似最近邻(ANN)搜索获取相似的信息;关键词匹配则更为简单,使用准确的关键词匹配来查找信息,通常使用诸如全文检索等算法。
但是,基于关键词或相似性搜索构建的简单RAG系统在需要推理的复杂查询中表现不佳。简单的相似度的检索无法对实体之间的关系进行推理和判断。
GraphRAG
GraphRAG 是一种 新的RAG 系统,它结合了知识图谱和大型语言模型(LLM)的优势。在 GraphRAG 中,知识图谱作为事实信息的结构化资源库,LLM将自然语言转换为知识图谱的查询信息,从图谱中检索相关知识,并生成针对问题的回答。
GraphRAG解决了上述许多局限性,因为它能够对数据进行推理。
GraphRAG具有以下优势:
-
**改善信息检索。**通过理解实体之间的基本联系,GraphRAG 可以更准确地识别相关信息。
-
**增强上下文理解。**知识图谱为查询理解和响应生成提供了更丰富的上下文。
-
**减少幻觉。**通过将响应建立在事实知识上,GraphRAG 可以减轻生成错误信息的风险。
最佳实践
本文以一个开源的股票知识图谱[1]为例,介绍如何使用PolarDB+通义千问+LangChain搭建一个GraphRAG系统。
技术实现
PolarDB
PolarDB PostgreSQL版(下文简称为 PolarDB)是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 的能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB 具有大规模并行计算能力,可以应对OLTP与OLAP混合负载。
PolarDB具备高度兼容apache AGE的图引擎,支持对知识图谱的存储和查询检索。同时PolarDB具备pgvector增强插件,支持对向量数据的存储与检索。
通义千问
通义千问是由阿里云自主研发的大语言模型,用于理解和分析用户输入的自然语言,在不同领域和任务为用户提供服务和帮助。
在RAG场景中,通义千问基于用户的查询或上下文,结合用户兴趣或历史交互相关的信息,生成更加个性化的回复。
LangChain
LangChain是一个开源的工具包和框架,旨在简化和加速基于语言模型的应用程序开发。LangChain的核心在于将强大的语言模型(如OpenAI的GPT系列、阿里云的通义千问等)与实际应用结合起来,帮助开发者构建诸如聊天机器人、文本生成、知识管理、代码辅助等多种自然语言处理(NLP)相关应用。
LangChain中实现了apache age图插件和pgvector插件的支持,可以支持对于知识图谱和向量两种检索方式。

查询流程
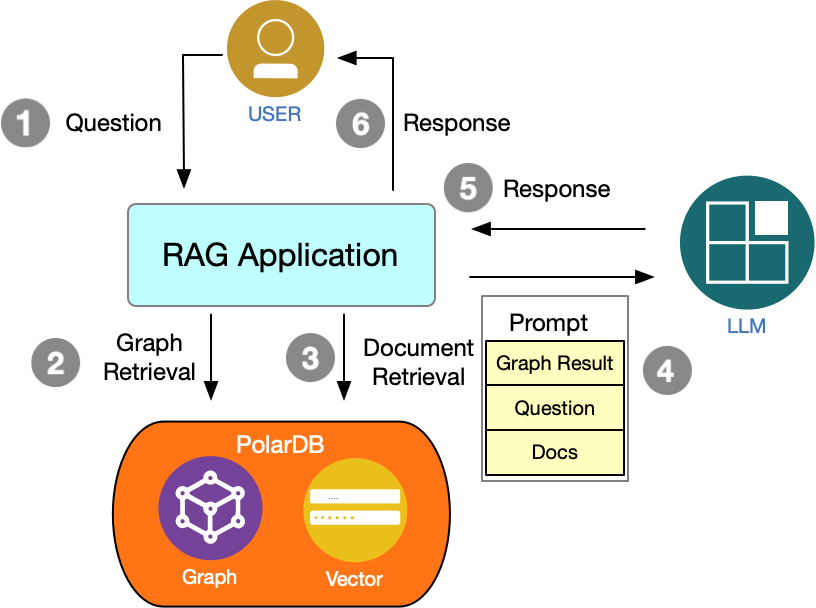
主要的查询流程如下图所示:
-
用户提出相关问题
-
RAG系统在知识图谱中检索相关的答案
-
RAG系统把知识图谱的检索结果作为向量检索的相关信息,用向量相似性检索的方式检索相关的文档
-
RAG系统将多种结果输入给大语言模型
-
大语言模型根据输入的信息组织问答结果
-
RAG系统将问答结果返回给用户
建议配置
为了得到良好的体验,建议使用以下配置:
项目 | 推荐配置 |
PolarDB 版本 | 标准版 兼容PostgreSQL 14 |
CPU | >16 Core |
内存 | >64 GB |
磁盘 | >100GB (AUTOPL) |
版本 | >2.0.14.23.1 |
实战步骤
准备工作
环境准备
-
申请阿里云灵积模型api key(如已有key可略过此步骤)
-
进入阿里云官网,注册或登录;
-
搜索灵积模型服务,开通服务;
-
进入产品控制台,创建api key;
该api key是访问灵积模型服务的凭证,需要妥善保管。
- 环境中安装相关的python包
pip install langchain #安装langchain环境pip install langchain-community #安装第三方集成,就是各种大语言模型pip install python-dotenv #加载工具pip install dashscope #灵积模型服务pip install psycopg # 数据库连接
如遇到一些安装失败的问题,需要升级python版本 > 3.7。
- 修改age_graph.py文件
age_graph.py位于
/site-packages/langchain_community/graphs/age_graph.py 下,需要修改两处地方:
-
LOAD ‘age’; sql 语句修改为
select * from ag_catalog.get_cypher_keywords() limit 0; 确保PolarDB可以正确加载对应的扩展
-
MATCH ()-[e]-() RETURN collect(distinct label(e)) as labels修改MATCH ()-[e]->() RETURN collect(distinct label(e)) as labels加速对图的schema的获取
数据库准备
创建AGE插件
AGE是一个为 PostgreSQL系列数据库打造的扩展,旨在增强其处理图数据的能力。AGE 旨在结合关系型数据库与图数据库的优势,提供一个高性能、灵活且易于扩展的解决方案。
create extension age;
创建vector插件
Vector是一个 PostgreSQL 的扩展插件,用于高效地处理和查询高维向量数据。vector 插件提供了高维向量的存储以及基于向量的近似最近邻(Approximate Nearest Neighbor, ANN)搜索功能。
create extension vector;
数据入库
将数据进行下载。数据分为两部分,一部分为图数据(data/import目录),包含了人员(Executive), 产业(Industry), 股票(Stock), 概念(Concept)等点以及人员-股票, 股票-概念,股票-产业之间的关联关系,这部分数据以图的方式存储到PolarDB中。
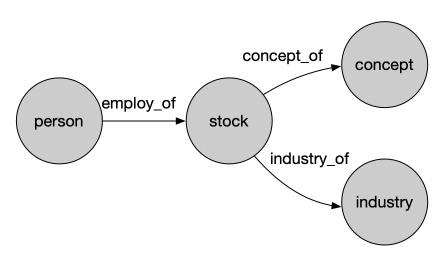
另一部分为每个股票的介绍信息(data/stockpage),原始数据为股票的网页信息,切分后以向量的方式存储到数据库中以提供进一步的信息。
图数据
创建一个名为stock_graph的图用于存储该知识图谱:
SELECT create_graph(‘stock_graph’);
附录1中脚本可以将数据转换为Cypher SQL脚本,配合客户端工具,如psql等可完成数据导入。转换后的sql脚本示意如下:
SELECT create_vlabel(‘stock_graph’,‘person’);SELECT * FROM cypher('stock_graph', $$ CREATE (:person {person_id:'dddbd3ad0f2e3fca80da88296298bb51',name:'杜玉岱',gender:'男',age:'58'}) $$ ) as (n agtype);SELECT * FROM cypher(‘stock_graph’,
C
R
E
A
T
E
(
:
p
e
r
s
o
n
p
e
r
s
o
n
i
d
:
′
2
f
867939
e
123
f
10437
a
15
a
127799248
e
′
,
n
a
m
e
:
′
延万
华
′
,
g
e
n
d
e
r
:
′
男
′
,
a
g
e
:
′
4
5
′
)
CREATE (:person {person_id:'2f867939e123f10437a15a127799248e',name:'延万华',gender:'男',age:'45'})
CREATE(:personpersonid:′2f867939e123f10437a15a127799248e′,name:′延万华′,gender:′男′,age:′45′) ) as (n agtype);SELECT * FROM cypher('stock_graph', $$ CREATE (:person {person_id:'e68b3ae7a003c60cd9d50e371cdb3529',name:'宋军',gender:'男',age:'48'}) $$ ) as (n agtype);…SELECT * FROM cypher('stock_graph', $$ MATCH (a:person), (b:stock) WHERE a.person_id = 'dddbd3ad0f2e3fca80da88296298bb51' AND b.stock_id = '601058' CREATE (a)-[e:employ_of {jobs:'董事长/董事'} ]->(b) RETURN e$$) as (e agtype);SELECT * FROM cypher(‘stock_graph’,
M
A
T
C
H
(
a
:
p
e
r
s
o
n
)
,
(
b
:
s
t
o
c
k
)
W
H
E
R
E
a
.
p
e
r
s
o
n
i
d
=
′
2
f
867939
e
123
f
10437
a
15
a
127799248
e
′
A
N
D
b
.
s
t
o
c
k
i
d
=
′
60105
8
′
C
R
E
A
T
E
(
a
)
−
[
e
:
e
m
p
l
o
y
o
f
j
o
b
s
:
′
副董事长
/
董
事
′
]
−
>
(
b
)
R
E
T
U
R
N
e
MATCH (a:person), (b:stock) WHERE a.person_id = '2f867939e123f10437a15a127799248e' AND b.stock_id = '601058' CREATE (a)-[e:employ_of {jobs:'副董事长/董事'} ]->(b) RETURN e
MATCH(a:person),(b:stock)WHEREa.personid=′2f867939e123f10437a15a127799248e′ANDb.stockid=′601058′CREATE(a)−[e:employofjobs:′副董事长/董事′]−>(b)RETURNe) as (e agtype);SELECT * FROM cypher('stock_graph', $$ MATCH (a:person), (b:stock) WHERE a.person_id = 'e68b3ae7a003c60cd9d50e371cdb3529' AND b.stock_id = '601058' CREATE (a)-[e:employ_of {jobs:'董事'} ]->(b) RETURN e$$) as (e agtype);…
向量数据
文本信息按照一定规则切割后,以向量的形式存储到数据库中。切分采用langchain的RecursiveCharacterTextSplitter切分器,实际使用中可根据需要进行切分,并使用通义大模型转换为向量。
附录2中脚本可实现向量数据入库过程。
安装使用到的python包:
pip install BeautifulSoup``pip install bs4
数据库中创建了对应的数据表docs用于记录文本以及对应的文本向量。
CREATE TABLE IF NOT EXISTS docs ( id bigserial primary key, title text, content text, – 文本内容 tokens integer, embedding vector(1536) --向量 );
在向量上创建索引,此处使用hnsw索引,并使用欧式距离(l2距离)进行查询。(索引类型和距离计算方式可根据实际需要进行选择)
CREATE INDEX ON docs USING hnsw (embedding vector_l2_ops);
查询
以问题 “李士祎关连的股票信息?”为例进行查询,并对于单独使用向量检索、图检索以及图加向量检索的结果进行对比。
单独使用向量检索
定义大语言模型为通义千问
DASHSCOPE_API_KEY从环境变量中读取:
import osDASHSCOPE_API_KEY=os.environ["DASHSCOPE_API_KEY"]from langchain.embeddings import DashScopeEmbeddingsembeddings = DashScopeEmbeddings(model="text-embedding-v1", dashscope_api_key=DASHSCOPE_API_KEY)from langchain_community.llms import Tongyi``llm_tongyi=Tongyi(temperature=1)
RetrievalQA是LangChain中封装的一个chain,可以实现基于本地知识库的问答。
问答大语言模型过程中需要输入相关文档,来进行答案的生成。这里定义了一个Retriever,通过向量检索的方式来获取相似度最大的5篇文档:
from langchain.schema import Document``from langchain_core.retrievers import BaseRetriever``class CustomRetriever(BaseRetriever):` `def __init__(self):` `super().__init__()` `def _get_relevant_documents(self, query: str) -> list[Document]:` `relevant_docs = []` `cur = conn.cursor()` `# Get the top 5 most similar documents using the KNN <=> operator` `cur.execute("SELECT content FROM docs ORDER BY embedding <=> '{}' LIMIT 5".format(embeddings.embed_query(query)))` `top3_docs = cur.fetchall()` `cur.close()` `for doc in top3_docs:` `relevant_docs.append(Document(page_content=doc[0]))` `return relevant_docs``custom_retriever = CustomRetriever()`` ``
进行问答:
from langchain.chains import RetrievalQA# 创建 RetrievalQAqa_chain = RetrievalQA.from_chain_type( llm=llm_tongyi, retriever=custom_retriever, verbose=True)` `response = qa_chain.invoke("李士祎关连的股票信息?")print(response)
问答结果如下:
根据提供的信息,没有找到与李士祎相关的股票信息。请提供更多的信息以便我能更准确地回答您的问题。如果无法提供更多细节,那么我将无法给出具体的答案。
可见查询结果无法获取正确的答案。
从执行过程中可以看到,直接执行向量相似度的执行结果如下:
(‘科士达(002518) 公司资料_F10_同花顺金融服务网谢谢您的宝贵意见您的支持是我们最大的动力谢谢您的支持同花顺F10最新价:涨跌幅:换肤上一个股下一个股i问董秘科士达002518最新动态公司资料股东研究经营分析股本结构资本运作盈利预测新闻公告概念题材主力持仓财务概况分红融资公司大事行业对比详细情况高管介绍发行相关参控股公司专利状况F10 功能找不到?在搜索框里直接输入您想要的功能!比如输入“龙虎榜”,赶快试一下哦!跳过下一步选股选不好?可以直接输入你想要的问句啦,比如输入“近一周涨幅超过30%的股票”赶紧行动吧!上一步完成详细情况公司名称:深圳科士达科技股份有限公司所属地域:广东省英文名称:Shenzhen Kstar Science & Technology Co.,Ltd所属行业:机械设备 — 电气设备曾 用…’,)('佳士科技(300193) 公司资料_F10_同花顺金融服务网谢谢您的宝贵意见您的支持是我们最大的动力谢谢您的支持同花顺F10最新价:涨跌幅:换肤上一个股下一个股i问董秘佳士科技300193最新动态公司资料股东研究经营分析股本结构资本运作盈利预测新闻公告概念题材主力持仓财务概况分红融资公司大事行业对比详细情况高管介绍发行相关参控股公司专利状况F10 功能找不到?在搜索框里直接输入您想要的功能!比如输入“龙虎榜”,赶快试一下哦!跳过下一步选股选不好?可以直接输入你想要的问句啦,比如输入“近一周涨幅超过30%的股票”赶紧行动吧!上一步完成详细情况公司名称:深圳市佳士科技股份有限公司所属地域:广...',)(‘日签署的股权转让协议,沪士控股及碧景控股将其拥有的本公司的部分股权,分别占股本总额的2%及1%,转让于合拍友联。上述股权转让事宜于2007年1月9日经中华人民共和国商务部以《商务部关于同意沪士电子股份有限公司转股的批复》批准。于2007年7月9日,本公司获发新的营业执照。根据于2008年6月至7月间签署的一系列股权转让协议,沪士控股将其拥有的本公司股权中的部分股权,共占股本总额的16%分别转让予HDFCO.,LTD.、深圳中科汇商创业投资有限公司、湖南中科岳麓创业投资有限公司、MULTIYIELDPLUSCO.,LTD.、碧景控股、昆山爱派尔投资发展有限公司、昆山恒达建设项目咨询服务有限公司、苏州正信工程造价咨询事务所有限责任公司及昆山市骏嘉控股有限公司。该股权转让事宜于2008年9月23日经中华人民共和国江苏省对外贸易经济合作厅以《关于同意沪士电子股份有限公司股权变更的批复》批准。于2009年2月24日,江苏省对外贸易经济合作厅以苏外经贸资[2009]178号,批准本公司的股东合拍友联将其持有的本公司6%的股份转让给合拍友联有限公司。本公司于2010年8月9日向境内投资者发行了80,000,000股人民币普通股,并于2010年8月18日在深圳证券交易所挂牌上市交易,发行后总股本增至人民币692,030,326元。…’,)('5年8月1日,香港碧景将其拥有的本公司全部股权转让给注册于西萨摩亚群岛的沪士集团控股有限公司(“沪士控股”)。同时本公司改名为沪士电子(昆山)有限公司。沪士控股的控股公司为注册于中国台湾的楠梓电子股份有限公司(以下简称“楠梓电子”)。沪士控股受让股权后对本公司进行数次增资。截至2001年12月31日,本公司注册资本增至67,500,000美元。根据于2002年4月签署的股权转让协议,沪士控股将其拥有本公司股权中的55%分别转让与碧景(英属维尔京群岛)控股有限公司(“碧景控股”)、中新苏州工业园区创业投资有限公司、合拍友联公司(“合拍友联”)、杜昆电子材料(昆山)有限公司、昆山经济技术开发区资产经营有限公司及苏州工业园区华玺科技投资有限公司。该股权转让事宜于2002年7月26日经中华人民共和国对外贸易经济合作部以《关于同意沪士电子(昆山)有限公司股权变更的批复》批准。于2002年8月20日,本公司获发新的营业执照,变更为中外合资经营企业,注册资本67,500,000美元。根据于2002年9月22日签署的发起人协议及2002年9月26日的董事会决议,...',)(‘其中合并报表的有:7家。序号关联公司名称参控关系参控比例投资金额(元)被参控公司净利润(元)是否报表合并被参股公司主营业务-黄石沪士电子有限公司子公司100.00%8.00亿-是-昆山沪利微电有限公司子公司100.00%4.69亿-是-昆山先创利电子有限公司子公司100.00%7213.50万-是-昆山易惠贸易有限公司子公司100.00%135.12万-是-沪士国际有限公司子公司100.00%70.00万-是-黄石邻里物业服务有…’,)
这是因为涉及到的网页材料中与人名关联度较低,主要提供的是上市公司的相关信息,两者关联性不大,因此向量检索模式无法获取答案。
单独使用图搜索
LangChain中图引擎实现了对于AGE的支持,使用时需要先定义一个图对象,并获取图的模式。这里图的模式是指点和边的类型信息,用于生产图的查询语言。
from langchain.chains import GraphCypherQAChainfrom langchain_community.graphs.age_graph import AGEGraphconf = { “database”: “xxx”, “user”:“xxx”, “host”:“pc-xxxx.rwlb.rds.aliyuncs.com”, “port”:“1921”, “password”:“xxx”,}graph = AGEGraph(graph_name=“stock_graph”, conf=conf)``graph.refresh_schema()
GraphCypherQAChain是LangChain中封装的一个chain,可以将自然语言转为图查询,实现本地图谱的问答。
graphchain = GraphCypherQAChain.from_llm( llm_tongyi, graph=graph, verbose=True, top_k=5,)response = graphchain.invoke(“李士祎关连的股票信息?”)``print(response)
问答结果如下:
根据提供的信息,这里有关于股票的信息:股票名称为酒鬼酒,代码为799。但是,没有直接提到李士祎相关的具体股票信息。所以,基于给出的数据,我们不知道李士祎具体的关联股票详情。
可见基于图的查询虽然查到了李士祎关联的股票为酒鬼酒,且股票代码为799,但是由于图中并没有存储酒鬼酒的信息,因此也无法给出具体的信息。
从执行的过程中可以看到,langchain生成了Cypher语句并在知识图谱中进行了执行,查询到了酒鬼酒的名称以及股票代码。
Generated Cypher:MATCH (p:person)-[r:employ_of]->(s:stock) WHERE p.name = "李士祎" RETURN s.name, s.codeFull Context:``[{‘name’: ‘酒鬼酒’, ‘code’: ‘799’}]
注意:如果langchain中生成的Cypher不正确,还可以使用prompt的方式给langchain提供示例Cypher以帮助生成。当然,也可以自定义一个Retriever,通过连接数据库的方式执行自定义的Cypher以获得更加准确的回答。
图+向量联合搜索增强
以上两种查询的结果都不尽人意,因为向量检索和知识图谱都只存储了独立的内容,无法独自生成问答结果。将以上两种查询方式进行结合,把知识图谱的查询结果作为向量查询的输入信息,通过向量查询获取相关文档后,由LLM最终生成更加完整的问答结果。
此处定义了一个prompt的模版,把知识图谱的查询结果作为向量检索的输入,来获得更为准确的问答结果。
from langchain_core.prompts.prompt import PromptTemplatefrom langchain.chains import LLMChaingraphchain = GraphCypherQAChain.from_llm( llm_tongyi, graph=graph, verbose=True, top_k=5, return_direct=True, #此处直接返回查询结果,不需要llm来组织回答)template = “”“Task:Generate more detailed information about the raw answer.The question is:{question}the raw answer from knowledge graph in format:{answer}please give more detailed answer about raw answer”""prompt = PromptTemplate(` `input_variables=["question", "answer"],` `template=template)llm_chain = LLMChain(llm=llm_tongyi, prompt=prompt)def dynamic_query(question): # first round use graph cypher qa answer = graphchain.invoke(question) if answer[‘result’] == ‘’: return “没有找到答案” # 格式化输入提示 formatted_prompt = prompt.format(question=question, answer=answer[‘result’][0]) answer = qa_chain.invoke(formatted_prompt) return answerresponse = dynamic_query("李士祎关连的股票信息?")print(response[‘result’])
问答结果如下:
根据提供的信息,与李士祎相关的股票“酒鬼酒”的详细信息如下:``- **公司名称**:酒鬼酒股份有限公司``- **股票代码**:000799``- **所属地域**:湖南省``- **英文名称**:Jiugui Liquor Co., Ltd.``- **公司网址**:www.jiuguijiu000799.com``- **主营业务**:从事生产、销售曲酒系列产品。``- **主要产品**:` `- 酒鬼系列` `- 湘泉系列` `- 内参系列``- **控股股东及实际控制人**:中皇有限公司(持有酒鬼酒股份有限公司股份比例:31.00%)``请注意,以上信息是基于所提供的上下文得出的结论,如果需要更详细的财务数据或其他具体信息,请参考官方公告或相关财经网站。
该问答结果不但准确地回答出相关的股票为 “酒鬼酒”,并且给出了酒鬼酒的相关信息。相比只使用向量查询和图查询,该结果更加符合预期,满足实际应用需求。
从执行过程中可以看到,当知识图谱中检索了相应的结果后,问题转换为:
Task:Generate more detailed information about the raw answer.The question is:李士祎关连的股票信息?the raw answer from knowledge graph in format:{‘name_0’: ‘酒鬼酒’, ‘code’: ‘799’}``please give more detailed answer about raw answer
在向量检索中包含了酒鬼酒的相关信息,使得向量检索的结果更加准确:
('酒鬼酒(000799) 公司资料_F10_同花顺金融服务网谢谢您的宝贵意见您的支持是我们最大的动力谢谢您的支持同花顺F10最新价:涨跌幅:换肤上一个股下一个股i问董秘酒鬼酒000799最新动态公司资料股东研究经营分析股本结构资本运作盈利预测新闻公告概念题材主力持仓财务概况分红融资公司大事行业对比详细情况高管介绍发行相关参控股公司专利状况F10 功能找不到?在搜索框里直接输入您想要的功能!比如输入“龙虎榜”,赶快试一下哦!跳过下一步选股选不好?可以直接输入你想要的问句啦,比如输入“近一周涨幅超过30%的股票”赶紧行动吧!上一步完成详细情况公司名称:酒鬼酒股份有限公司所属地域:湖南省英文名称:Jiugui Liquor Co., Ltd.所属行业:食品饮料 — 饮料制造曾 用...',)``('名:*ST酒鬼公司网址:www.jiuguijiu000799.com主营业务:从事生产、销售曲酒系列产品。产品名称:酒鬼系列、湘泉系列、内参系列可能存在产品:中高端酒、酒类业务展开\xa0▼收起\xa0▲主营产品名称出自摘要中高端酒公司中高端酒鬼酒系列实现营收5.26亿元,同比增长11.68%,毛利率80.39%,同比增加1.70pct;湘泉系列实现营收1.24亿元,同比增长1.67%,毛利率51.62%,同比增加7.96pct。详情>>酒类业务公司酒类业务收入6.5亿元,同比增长9.62%。详情>>控股股东:中皇有限公司(持有酒鬼酒股份有限公司股份比例:31.00%)实际控制人:中皇有限公司(持有酒鬼酒股份有限公司股份比例:31.00%)最终控制人:旗下上市公司一览股票代码股票名称000016深康佳A000021深科技000022深赤湾A000026飞亚达A000028国药一致000031中粮地产000032深桑达A000043中航地产000050深天马A000066长城电脑000069华侨城A000400许继电气000423东阿阿胶000519中兵红箭000537广宇发展000550江铃汽车000553沙隆达A000554泰山石油000591太阳能000625长安汽车000635英力特000666经纬纺机000717韶钢松山000720新能泰山000727华东科技000731四川美丰000733振华科技000736中房地产000738航发控制000748长城信息000758中色股份000768中航飞机000777中核科技000778新兴铸管000780*ST平能000786北新建材000798中水渔业000799酒鬼酒000800一汽轿车000815美利云000819岳阳兴长000831五矿稀土000851高鸿股份000852石化机械000862银星能源000875吉电股份000877天山股份000883湖北能源000898鞍钢股份000901航天科技000916华北高速000920南方汇通000922*ST佳电000927一汽夏利000928中钢国际000930中粮生化000958东方能源000962*ST东钽000966长源电力000969安泰科技000985大庆华科000999华润三九002025航天电器002039黔源电力002046轴研科技002051中工国际...',)``('其中合并报表的有:0家。序号关联公司名称参控关系参控比例投资金额(元)被参控公司净利润(元)是否报表合并被参股公司主营业务-酒鬼洞藏酒销售有限公司合营企业50.00%3155.40万-198.36万--酒鬼酒湖南销售有限责任公司联营企业20.94%-1956.07万-主营业务详情:同花顺个股页面|F10论坛|模拟炒股|股民学校|手机炒股|联系我们免责声明:本信息由同花顺金融研究中心提供,仅供参考,同花顺金融研究中心力求但不保证数据的完全准确,如有错漏请以中国证监会指定上市公司信息披露媒体为准,同花顺金融研究中心不对因该资料全部或部分内容而引致的盈亏承担任何责任。用户个人对服务的使用承担风险。同花顺对此不作任何类型的担保。同花顺不担保服务一定能满足用户的要求..',)``('华谊B股(900909) 公司资料_F10_同花顺金融服务网谢谢您的宝贵意见您的支持是我们最大的动力谢谢您的支持同花顺F10最新价:涨跌幅:换肤上一个股下一个股i问董秘华谊B股900909最新动态公司资料股东研究经营分析股本结构资本运作盈利预测新闻公告概念题材主力持仓财务概况分红融资公司大事行业对比详细情况高管介绍发行相关参控股公司专利状况F10 功能找不到?在搜索框里直接输入您想要的功能!...',)``('华电B股(900937) 公司资料_F10_同花顺金融服务网谢谢您的宝贵意见您的支持是我们最大的动力谢谢您的支持同花顺F10最新价:涨跌幅:换肤上一个股下一个股i问董秘华电B股900937最新动态公司资料股东研究经营分析股本结构资本运作盈利预测新闻公告概念题材主力持仓财务概况分红融资公司大事行业对比详细情况高管介绍发行相关参控股公司专利状况F10 功能找不到?在搜索框里直接输入您想要的功能!...',)
总结
如何有效利用私有数据一直是RAG系统中面临的重大挑战,其中知识图谱是企业私有数据的重要组成部分。得益于PolarDB的可扩展性,PolarDB数据库中可同时存储向量数据和图谱数据,进行统一的存储和检索。同时相较于传统的向量检索,PolarDB中可将图检索与向量检索相结合,提供更高质量的RAG问答结果,满足应用需求。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 3911
3911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









