






春节这几天Deepseek的新闻铺天盖地,随着大模型技术指数级发展,越来越多的人从刚开始尝试着在自己的工作和生活中使用某个大模型工具,到现在很多人已经无法在工作和生活中离开它们,且经常是多个大模型工具一起使用,覆盖对话、图片生成、视频生成、文档生成等等,这也更进一步推进了大模型在不同领域朝着应用落地快速发展,同时我们也对大模型有了更多的期待和更高的要求,但其实这些通用大模型就像是一个个知识渊博但还稍显 “泛用” 的智者,它通过在海量数据上进行无特定任务指向的训练,积累了极其丰富的语言知识和语义理解能力,但在面对特定领域、特定任务时,这种通用性无法满足我们更多的、更专业技能的准确支持。
为什么需要做微调
为了能让大模型更好的理解我们的工作内容,提供更针对自己工作领域更专业的帮助,就需要对大模型进行微调了, 以便训练出在某个领域、某个行业更专业的大模型,一般我们管这样的大模型叫行业大模型或者领域大模型等。
什么是大模型微调
简单来说,就是在预训练大模型的基础上,利用特定领域或特定任务的数据,对模型进行进一步训练。
微调的过程主要涉及调整模型的部分参数**。**模型参数就像是控制模型行为和决策的 “旋钮”,预训练时,这些旋钮被大致调整到了适应通用任务的位置。而微调时,通过让模型学习特定数据,就可以对这些旋钮进行更加精细的调校,使模型的输出更贴合特定任务的需求。
如何微调
先确认要微调的模型
目前市面上的大模型可以分为开源大模型和闭源大模型两种,我倾向于用开源大模型做微调,个人认为有这三点独特的优势:
-
成本低:
-
模型代码和权重易于获取无需授权。
-
易定制化:
-
允许用户深入了解模型的内部结构和算法逻辑,并根据自己的特定需求,对模型的架构、参数等进行自由修改和调整,实现高度定制化。
-
知识共享:开源大模型拥有活跃的社区,开发者和研究人员可以在社区中分享自己的微调经验、技巧和代码。
我平时用的比较多的开源大模型是阿里的通义千问v2.5和Deepseek R1,它们微调所使用的工具有些差异,所以,我打算通过两篇文章分别聊一下针对它们的微调过程,这篇就先来讲讲通义千问v2.5的微调。
微调过程(0代码)
其实网上介绍微调通义千问v2.5的文章挺多的,方法也不止一个。这里我推荐官方的方法。
1. 打开官方文档。
可以从Qwen2.5在Github上的入口进入官方文档。在README页面中,官方文档介绍了如何做后训练,目前只支持SFT,后续会支持RLHF。
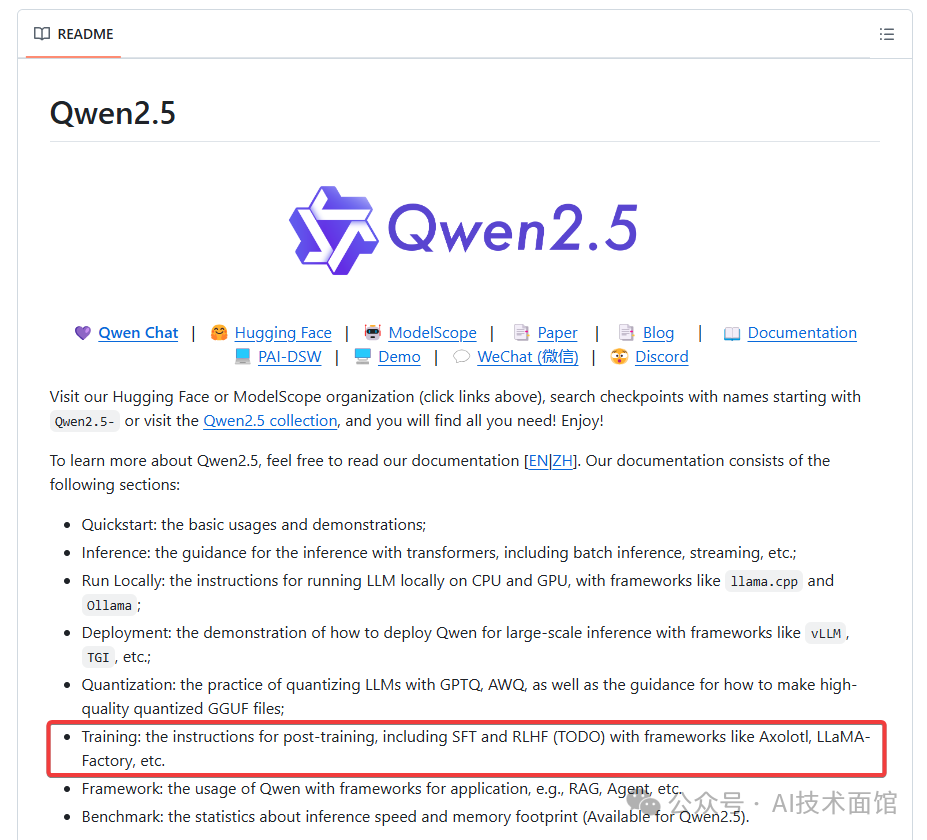
2. 点击Documentation,进到文档页面后,从左边的目录中找到TRAINING及SFT,就可以看到官方推荐的Llama Factory训练框架了。
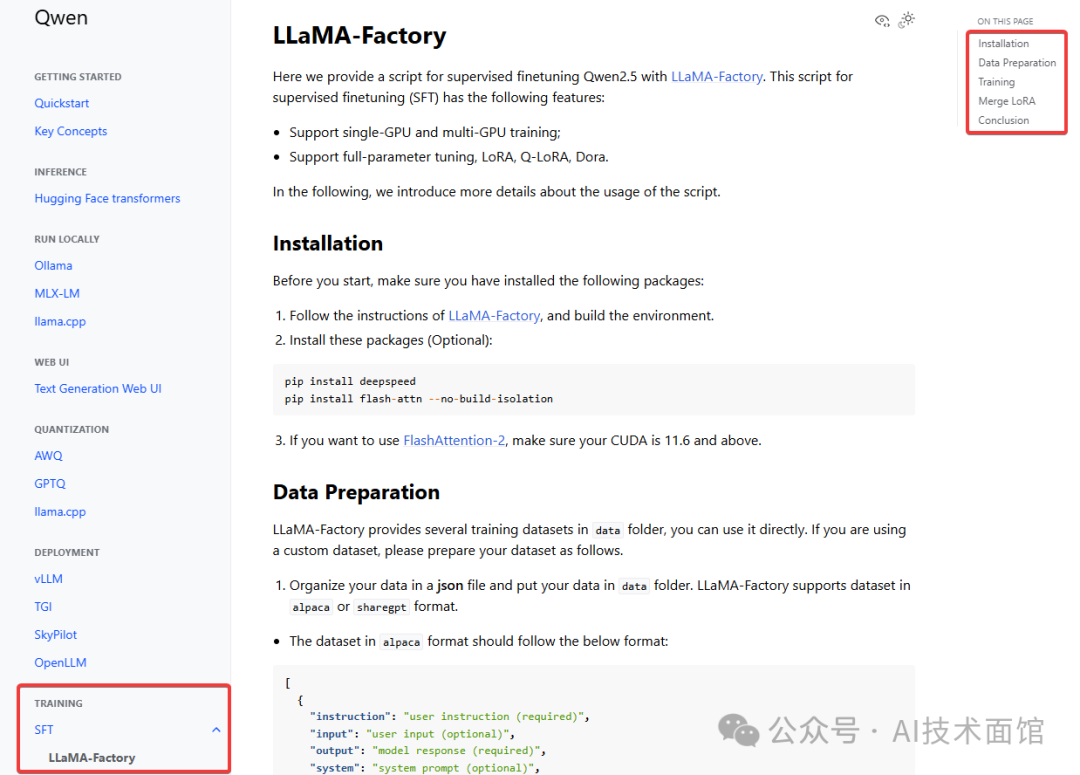
Llama Factory简单介绍:
它是由零隙智能(SeamlessAI)开发的低代码大模型训练开源框架,支持100 多种主流开源大语言模型,集成 Lora、QLora 等技术,在不改变预训练模型原始权重参数的情况下,引入小的可训练矩阵实现微调,缓解内存和计算资源限制。重要的是,它提供在 Web UI方式,可以通过前端页面快速进行训练参数选择,无需手写代码就可以进行训练。
回到Qwen的微调训练页面,整体微调内容分5个章节,主要流程集中在1~4章节,那我们就按照文档的顺序一步一步的进行微调吧。
3. “工欲善其事,必先利其器”
3.1 安装python环境,搞大模型怎么离得开python。安装方法非常简单,百度搜索python官网,根据自己的操作系统版本下载最新的安装包,并进行安装即可,注意要把python设置到系统环境中,方便随时可以调用。
3.2 安装Llama factory及配置,Llama factory安装过程可以参考Llama Factory官网教程,教程通过图文非常详细的介绍了安装步骤。官网安装说明链接如下(点击打开):
安装 - LLaMA Factory
3.2.1. 安装Cuda
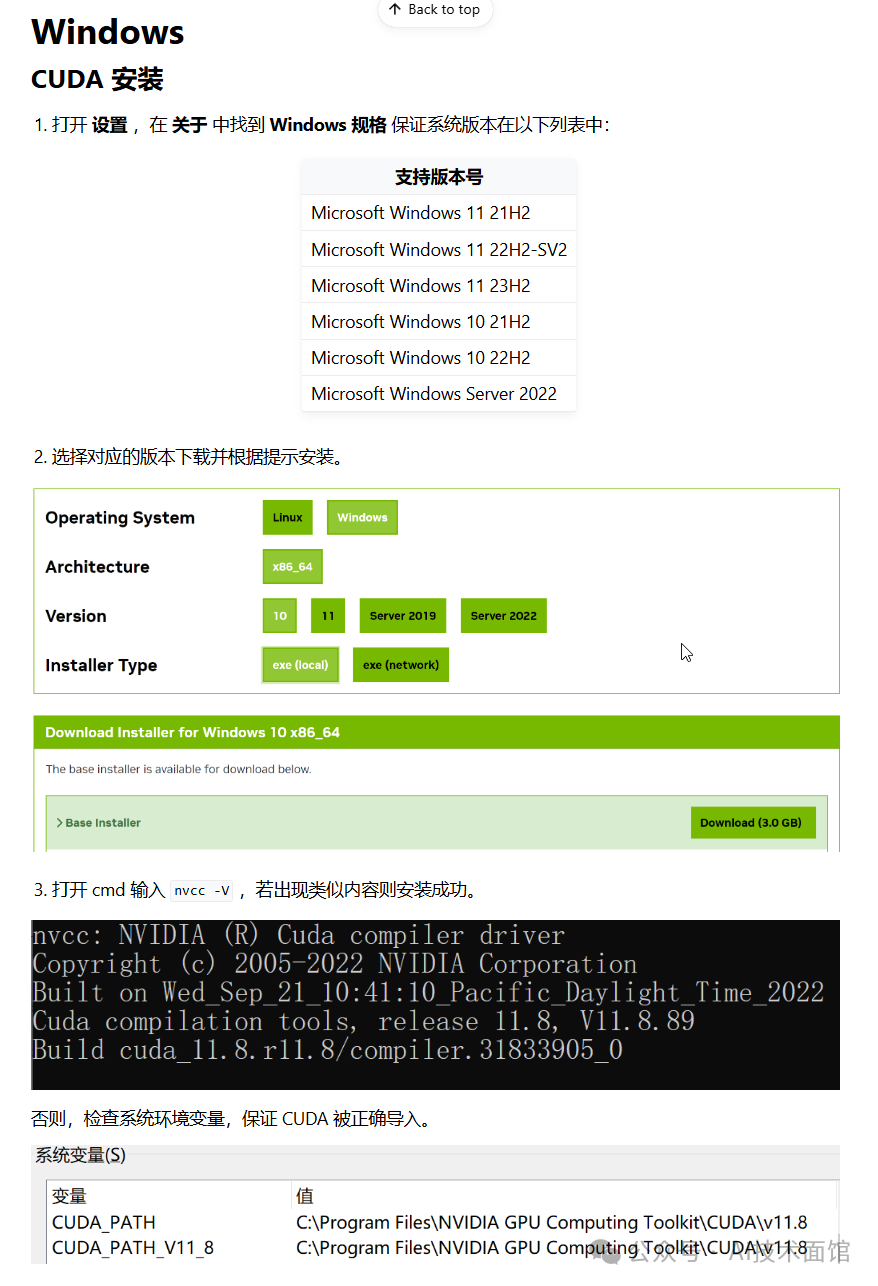
3.2.2 安装Llama Factory
分别执行下面的指令,将Llama Factory从github上面下载下来,并安装相应的依赖。

针对官方说的第三步的依赖安装,我还安装了swanlab工具,SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,提供了一个跟踪、记录、比较、和协作实验的平台。具体命令如下
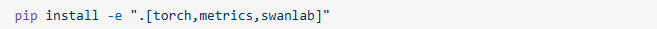
swanlab不是必须的,仅供参考。

Llama Factory代码下载
3.3 Deepspeed和Flash Attention安装
-
DeepSpeed 是微软开源的一个用于深度学习训练的优化库,专为大规模模型和数据集设计,可显著提升训练效率和可扩展性。
-
FlashAttention 是由斯坦福大学和谷歌大脑的研究人员开发的一种高效注意力机制算法,旨在解决传统注意力机制在处理长序列数据时存在的计算和内存效率问题。
这两项安装属于可选安装,所以,大家根据自己情况选择是否安装即可,具体安装命令如下:

以上就完成了所有需要工具的安装和环境的配置。
4. 微调训练的数据准备
这步我认为是整个微调过程中最需要我们关注和重点投入的步骤,前面说了我们进行微调的一个主要目标是可以根据自己的特定需求,对模型进行高度定制化的训练,实现在特定领域提供更专业更准确支持的要求。
4.1 准备数据文件
创建一个Json形式的文档,例如:
{
"instruction":"计算这些物品的总费用。",
"input":"输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output":"汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},
由于Llama Factory当前支持 Alpaca 格式和 ShareGPT 格式的数据。所以,我们也可以根据自己的需求提供符合这两种格式的数据来微调Qwen。
4.2 Alpaca格式
Alpaca格式支持以下5类任务,不同任务的格式是有差异的,这里我们的微调工作主要是指令监督微调任务,所以,此处我只介绍一下这个任务的格式。
-
指令监督微调
-
预训练
-
偏好训练
-
KTO
-
多模态
\[
{
"instruction":"user instruction (required)",
"input":"user input (optional)",
"output":"model response (required)",
"system":"system prompt (optional)",
"history":\[
\["user instruction in the first round (optional)","model response in the first round (optional)"\],
\["user instruction in the second round (optional)","model response in the second round (optional)"\]
\]
}
\]
其中,instruction、input、output3项是必填内容。另外,system 列对应的内容将被作为系统提示词。history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
4.3 ShareGPT 格式
ShareGPT 格式支持以下3类任务,和Alpaca格式一样,这3类任务的格式也是有差异的,针对我们的微调工作,我们仍然只会用到指令监督微调任务,所以,此处我也只介绍这个任务的格式。区别于Alpaca格式,sharegpt 格式支持更多的角色种类,例如 human、gpt、observation、function 等等。
-
指令监督微调
-
偏好训练
-
OpenAI格式
\[
{
"conversations":\[
{
"from":"human",
"value":"user instruction"
},
{
"from":"gpt",
"value":"model response"
}
\],
"system":"system prompt (optional)",
"tools":"tool description (optional)"
}
\]
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
大家基于自己的情况,选择其中一种格式,按照每个字段内容的介绍,输入想要微调的领域知识和内容就好了,当然数据量越多越好呀。
4.4 数据存储和配置
-
将以上Json形式的数据文档保存在Llama Factory安装路径下的data子文件夹内。
-
将数据的定义输入到data子目录下的dataset_info.json文件中
-
Alpaca格式:
-
"dataset\_name":{ "file\_name":"dataset\_name.json", "columns":{ "prompt":"instruction", "query":"input", "response":"output", "system":"system", "history":"history" } } -
ShareGPT格式
-
"dataset\_name":{ "file\_name":"dataset\_name.json", "formatting":"sharegpt", "columns":{ "messages":"conversations", "system":"system", "tools":"tools" }, "tags":{ "role\_tag":"from", "content\_tag":"value", "user\_tag":"user", "assistant\_tag":"assistant" } }
5. 使用Llama Factory进行微调
这里我们使用Llama Factory的Web UI来进行微调,直观且0代码。
在命令行终端输入如下命令即可打开页面:

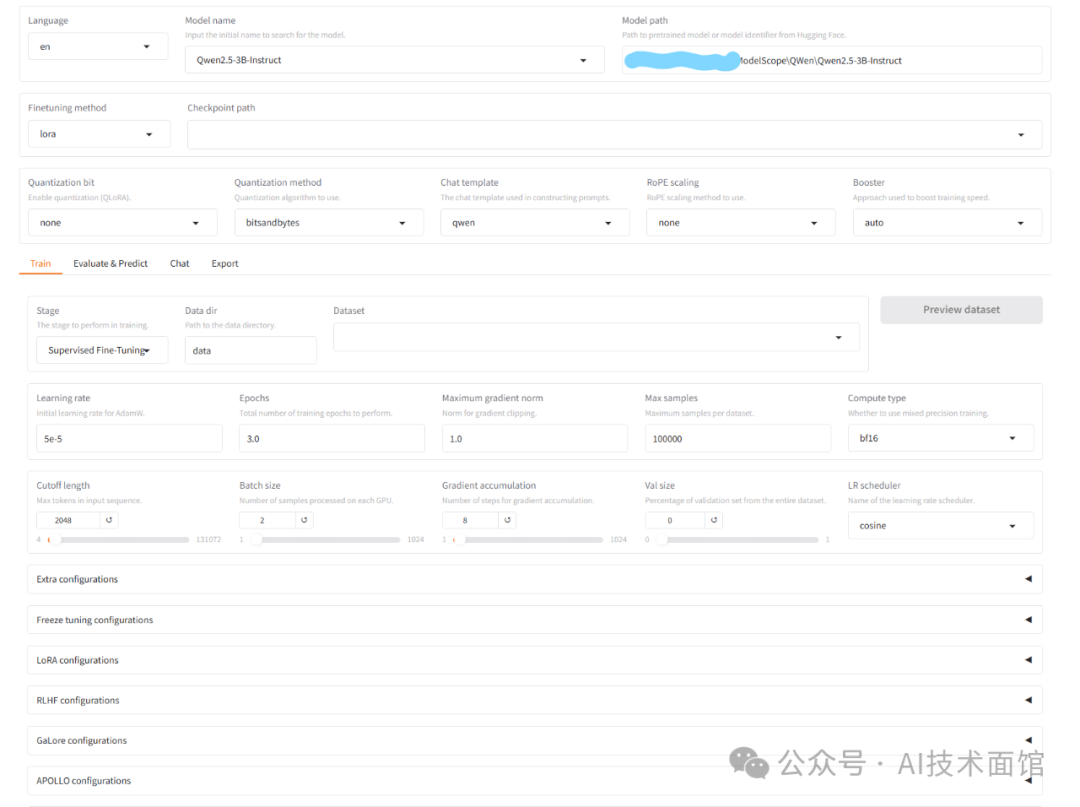
5.1 在最上面的模型选择下拉框中选择想要微调的模型,这里我选择的参数量3B的Qwen2.5模型,右边的路径输入模型在本地的位置。
小建议:建议大家将被微调的模型下载到本地来进行,我是从魔塔网站下载的,另外,魔塔网站上面也有很多不同领域的数据集可以下载使用。
5.2 微调选项可以选择Lora,第一次微调不需要输入Checkpoint path,这个是输入将微调后的新模型路径的。
5.3 Stage下拉框选择"supervised fine tuning"。Dataset输入框输入上一步的数据文档。(这里为了Demo目的,我选择工具自带的alpaca_zh_demo.json)
5.4 其它的选项大家根据自己电脑的配置来适当选择就可以了。需要注意的一个参数是"Cutoff Length",它是训练数据的最大长度,控制此参数以避免 OOM 错误。
这里我还打开了前面安装的swanlab,别忘了输入swanlab的apikey。
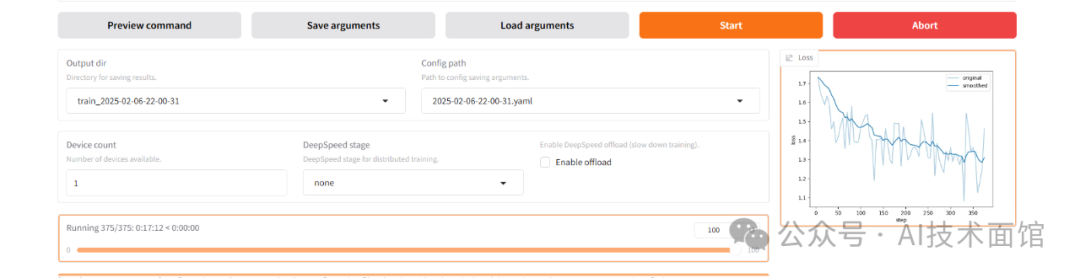
5.5 点击"Start"按钮就可以开始训练了。在命令行终端可以看到随着训练的进行,模型的loss在下降。在工具界面也有对应的图形方便查看训练的趋势。

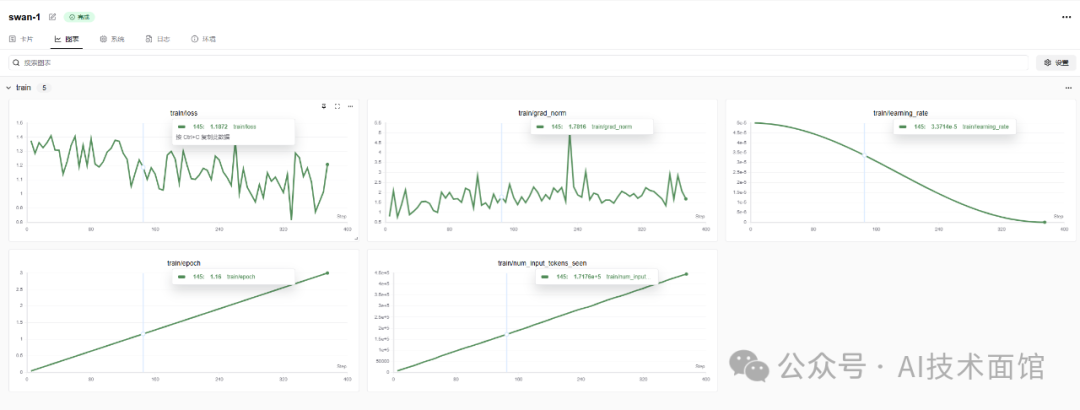
这里swanlab的优势就显示出来了,提供了更多更全面的图形来帮助我们判断本次训练的效果。
5.6 通过在工具中选择"Chat"标签来快速验证微调的效果。在输入框输入相关问题看模型的回答内容。别忘了在"Checkpoint path"输入微调版本的路径,然后再到"Chat"标签来看效果。
6. 合并 LoRA
官方文档特别提到了,如果使用 LoRA 训练模型,则可能需要合并适配器参数添加到 main 分支上。需要执行如下命令来合并。

以上就是基于官方推荐的方案进行通义千问v2.5模型微调的步骤。微调次数很大程度上取决于数据的质量和数量,以及个人制定的衡量指标的标准。另外,对于显存不大的机器,建议直接下载参数量较小的原始模型。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 4104
4104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









