






在当今数字化的时代,信息和知识如同浩瀚的海洋,而我们每个人都要在其中寻找属于自己的宝藏。
想象一下,作为一名医生,你手中握有海量的科研资料,它们如同一座座知识的孤岛,等待着被探索和整合。如果能够拥有一位专属的“知识机器人”,它不仅能够学习并吸收你所有的资料,还能在你需要时,迅速为你提供精准的答案,这将是多么令人向往的事情啊!
你无需再耗费大量时间在繁琐的资料检索中,只需简单地向它提问,答案便如自来水般涌现。这,便是本地部署与知识库结合的神奇之处。它不仅仅是一个技术的应用,更是一种对个人智慧的赋能。
而这一切,正是 DeepSeek 等大模型所赋予我们的独特价值。它阳光普照,让知识的边界得以无限拓展,让智慧的光芒得以更加令人唾手可得。
牛刀小试
首先,我们编写一个简单的 markdown 文件,内容如下:
三角形分类
- 黄金三角形就是三个角的大小比例为 1:2:3 的三角形。
- 白银三角形就是三个角的大小比例为 2:3:4 的三角形。
- 青铜三角形就是三个角的大小比例为 1:1:4 的三角形。
- 烂铁三角形就是三个角的大小的比例为 1:3:8 的三角形。
取个名字,比如 知识荒漠.md,当然把它导出为 pdf 格式也是可以的。当然,一般来说你会有很多这类文件。然后,把它们导入到本地知识库,后面会讲具体如何操作。
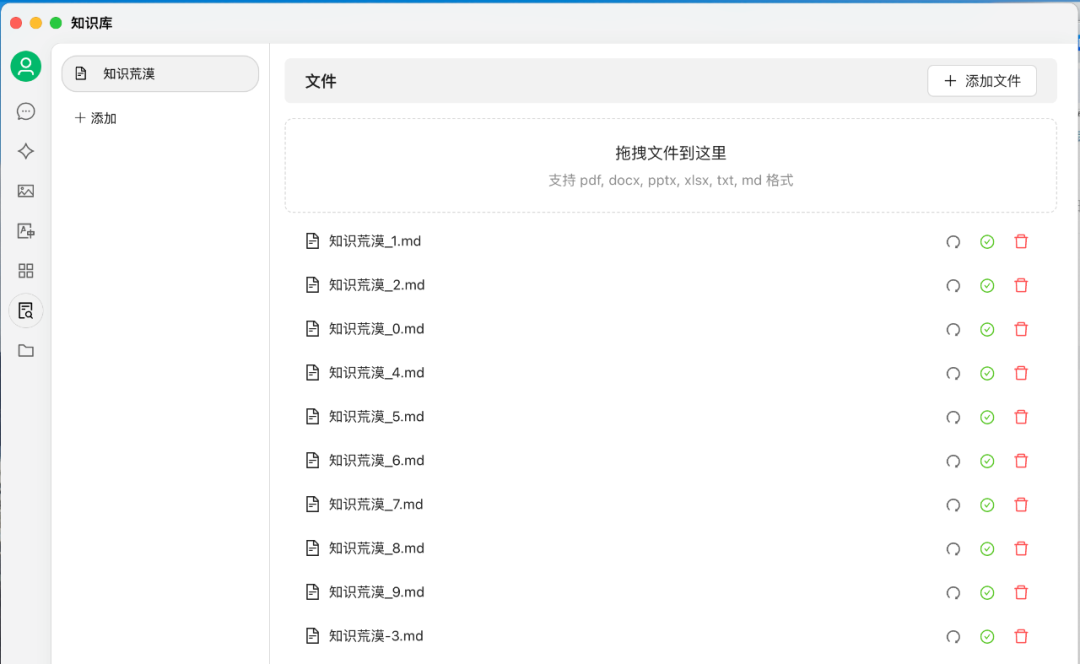
这里提一下,黄金三角形和白银三角形本身是有这样的定义,但我们这里随便下点定义,为了看看 DeepSeek 作何反应。而后面两个是没有的,完全是我们杜撰的,可以理解为要喂给大模型的新知识。
好了,开始调戏本地的 DeepSeek。
比如问它:请解释下青铜三角形。
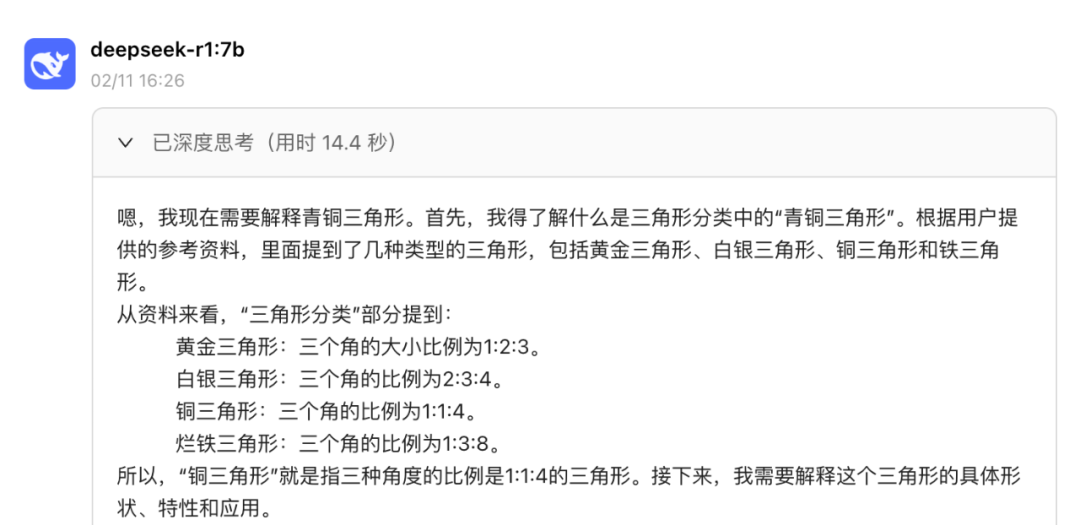
由于实际中并没有这个定义,所以它只能从我们本地知识库中获得这个知识,加上它自己的推理,构建了具体的概念并总结了一些性质,虽然它有些谨慎。

再问它:请解释下黄金三角形。
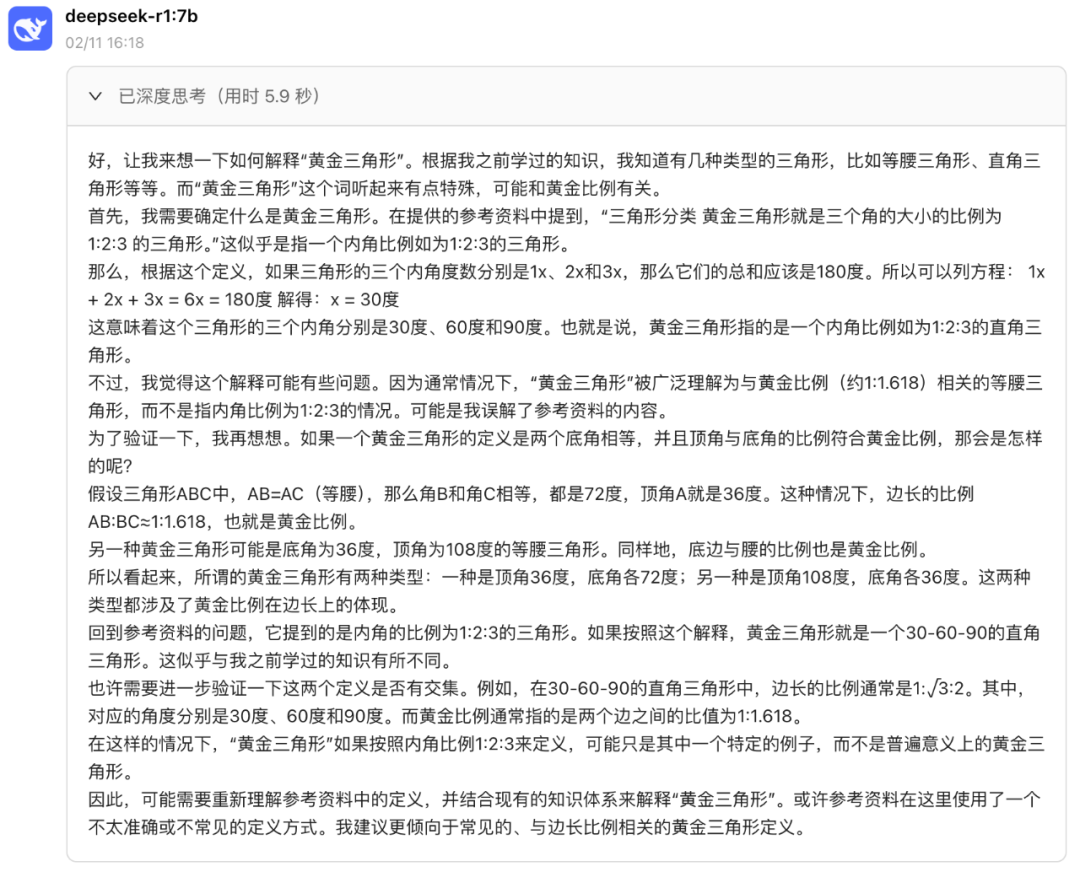
由于实际中有这个定义,但是它又看到了本地知识库中的这个概念,显然它们不一致,所以 DeepSeek 有些纠结,但会结合它自己的推理来决定最终怎么解释。

可见 DeepSeek 还是很聪慧的,不会轻易被外部知识误导。
另外,如果你嫌 AI 大模型翻译得不到位,是不是可以给它喂一些本地知识调教它呢!
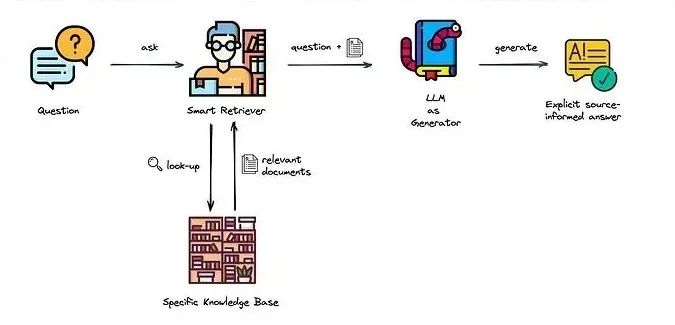
大致原理
DeepSeek 读取本地知识库主要是通过检索增强生成(Retrieval-Augmented Generation,RAG)技术实现的。以下是具体实现过程:
-
向量嵌入模型:需要一个嵌入模型(如
nomic-embed-text或BAAI/bge-m3)将本地知识库中的文本内容转换为向量形式。这些向量会被存储到向量数据库(如 LanceDB)中。 -
知识库的创建与配置:在本地部署 DeepSeek 的基础上,通过相关工具(如
Cherry Studio)配置嵌入模型和向量数据库。创建知识库时,选择已配置的嵌入模型,上传本地文件进行向量化处理。 -
RAG 技术:当用户提问时,RAG 技术会利用向量数据库中的向量数据,通过检索找到与问题最相关的知识库内容。DeepSeek 会结合检索到的知识库内容生成回答。
-
模型与工具:DeepSeek R1 等模型通过 API 配置到各种工具中(如
Cherry Studio),以实现对本地知识库的读取和处理。通过上述技术,DeepSeek 能够高效地读取和利用本地知识库,为用户提供精准的回答。
可能你会想这与直接以附件形式上传给大模型有什么区别?这个留给大家自己琢磨吧。好了,原理大致了解了,让我们动手吧。
本地部署
一、安装 Ollama
- 访问 Ollama 官网:前往 Ollama 官网,点击 Download 按钮。
-
下载安装包:根据你的操作系统选择对应的安装包。下载完成后,直接双击安装文件并按照提示完成安装。
-
验证安装:安装完成后,在终端输入以下命令,检查 Ollama 版本:
ollama --version如果输出版本号(例如
ollama version is 0.2.8),则说明安装成功。
二、下载并部署 DeepSeek 模型
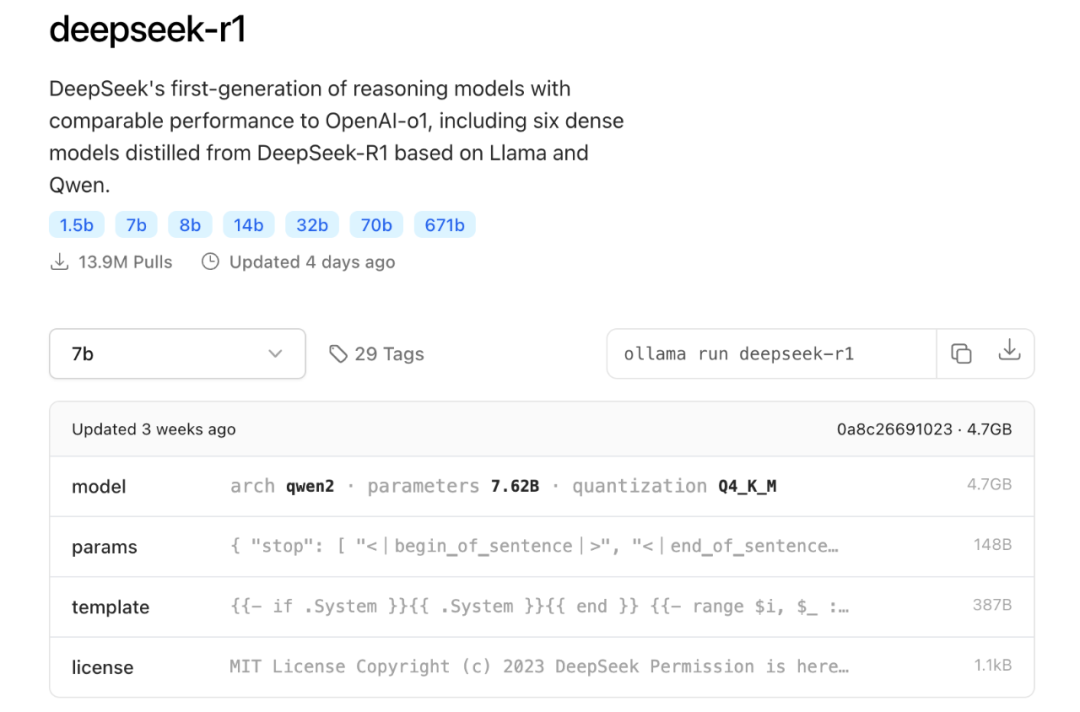
- 选择模型版本:
-
入门级:1.5B 版本,适合初步测试。
-
中端:7B 或 8B 版本,适合大多数消费级 GPU。
-
高性能:14B、32B 或 70B 版本,适合高端 GPU。
-
下载模型:打开终端,输入以下命令下载并运行 DeepSeek 模型。例如,下载 8B 版本的命令为:
ollama run deepseek-r1:8b如果需要下载其他版本,可以参考以下命令:
ollama run deepseek-r1:7b # 7B 版本 ollama run deepseek-r1:14b # 14B 版本 ollama run deepseek-r1:32b # 32B 版本 -
启动 Ollama 服务:在终端运行以下命令启动 Ollama 服务:
ollama serve服务启动后,可以通过访问
http://localhost:11434来与模型进行交互。
三、安装并配置 Cherry Studio
- 下载 Cherry Studio:
-
访问 Cherry Studio 官网,选择适配你操作系统的版本进行下载安装。

- 配置模型服务:
-
打开 Cherry Studio,进入 “模型服务” 设置。
-
添加 Ollama 作为模型服务提供商,输入 Ollama 服务的地址(默认为
http://localhost:11434)。
- 添加 DeepSeek 模型:
-
在 Cherry Studio 中,点击 “管理” 按钮,选择 “添加模型”。
-
输入模型名称
deepseek-r1:8b或其他版本,点击 “添加”。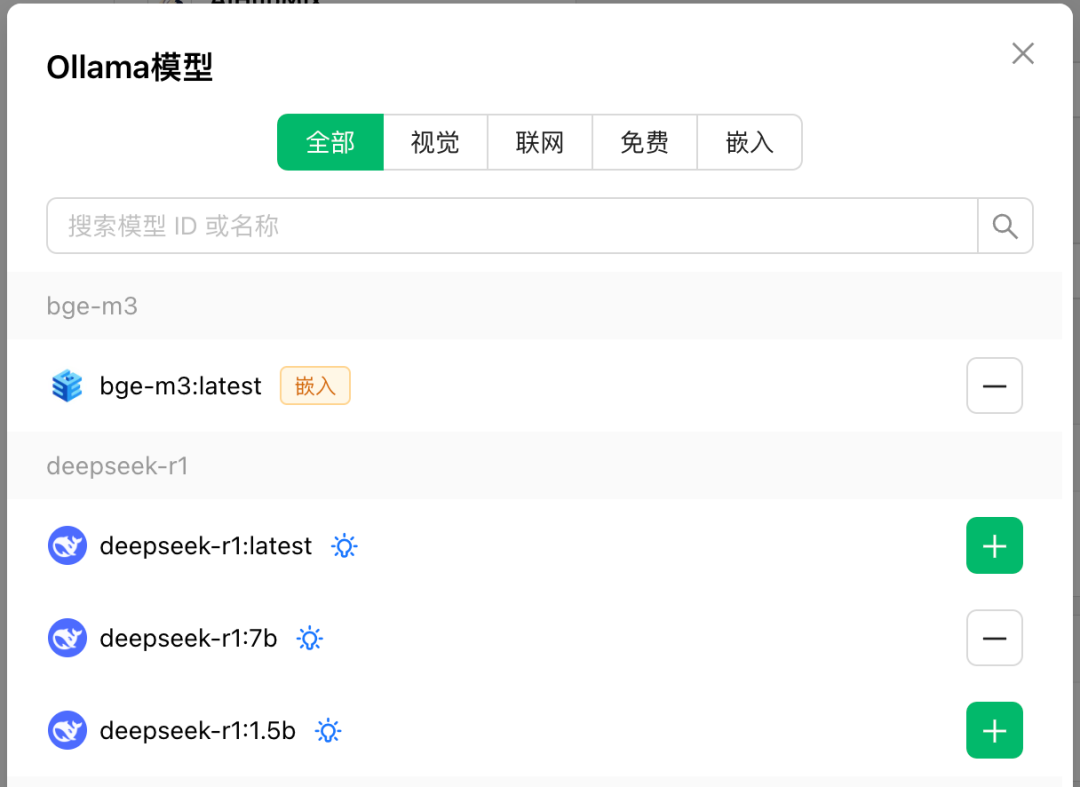
-
测试连通性,点击 “检查” 按钮,看到绿色对勾表示测试通过。
本地知识库
一、搭建本地知识库
- 下载嵌入模型:我们下载 BGE-M3,它是由 BAAI(北京智源人工智能研究院)发布的多语言长文本向量检索模型。BGE-M3 支持超过 100 种语言,训练数据覆盖了 170 多种语言。
通过如下命令下载这个嵌入模型。
ollama pull bge-m3
- 添加嵌入模型:
-
点击 “管理” 按钮,选择 “嵌入”,添加嵌入模型(如
bge-m3),用于文档拆分和理解。 -
点击 “确认” 后,嵌入模型将被添加到系统中。
- 添加本地知识库:
-
点击左侧的 “知识库” 按钮,选择并添加本地文档。
-
填写知识库名称,选择嵌入模型。
-
上传本地文件(支持文件、目录、网址、笔记等),例如你要学习的一堆文献。
二、使用知识库
- 选择知识库:
-
在
Cherry Studio的聊天窗口中,点击知识库图标,选中之前创建的知识库。 -
例如,选择名为 “知识荒漠” 的知识库。
- 聊天、提问:
- 在聊天区域输入问题,
Cherry Studio将调用 DeepSeek 模型,结合知识库内容生成回答。
通过上述步骤,你可以在本地成功部署 DeepSeek 模型,构建了本地知识库,并通过 Cherry Studio 的可视化界面进行交互。Cherry Studio 提供了丰富的功能,包括对话知识库、联网搜索、多模型接入等,非常适合新手快速上手。
最后,如果还想要 DeepSeek 结合搜索的话,可以使用浏览器插件 Page Assist。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1807
1807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









