







2025开年以来,各路行业客户纷纷掀起了DeepSeek部署热潮,各种比学赶帮超…
那么,怎样才能不落人后,快速把DeepSeek投入生产呢?目前看,主要有四种路径↓

❶ 采购DeepSeek一体机:
**优点:**本地部署开箱即用;

**缺点:**满血版一次性采购成本较高,蒸馏版则可用度不够,未来模型迭代、算力扩容、系统维护、软硬件升级都受限。

❷ 基于原有基础设施部署:
**优点:**可利旧,盘活闲置算力,本地化;

**缺点:**模型适配、部署、优化有门槛,推理效果不可控。

❸ 基于云端API调用:
**优点:**成本极低,有多家服务商选择灵活,适合尝鲜或测试。
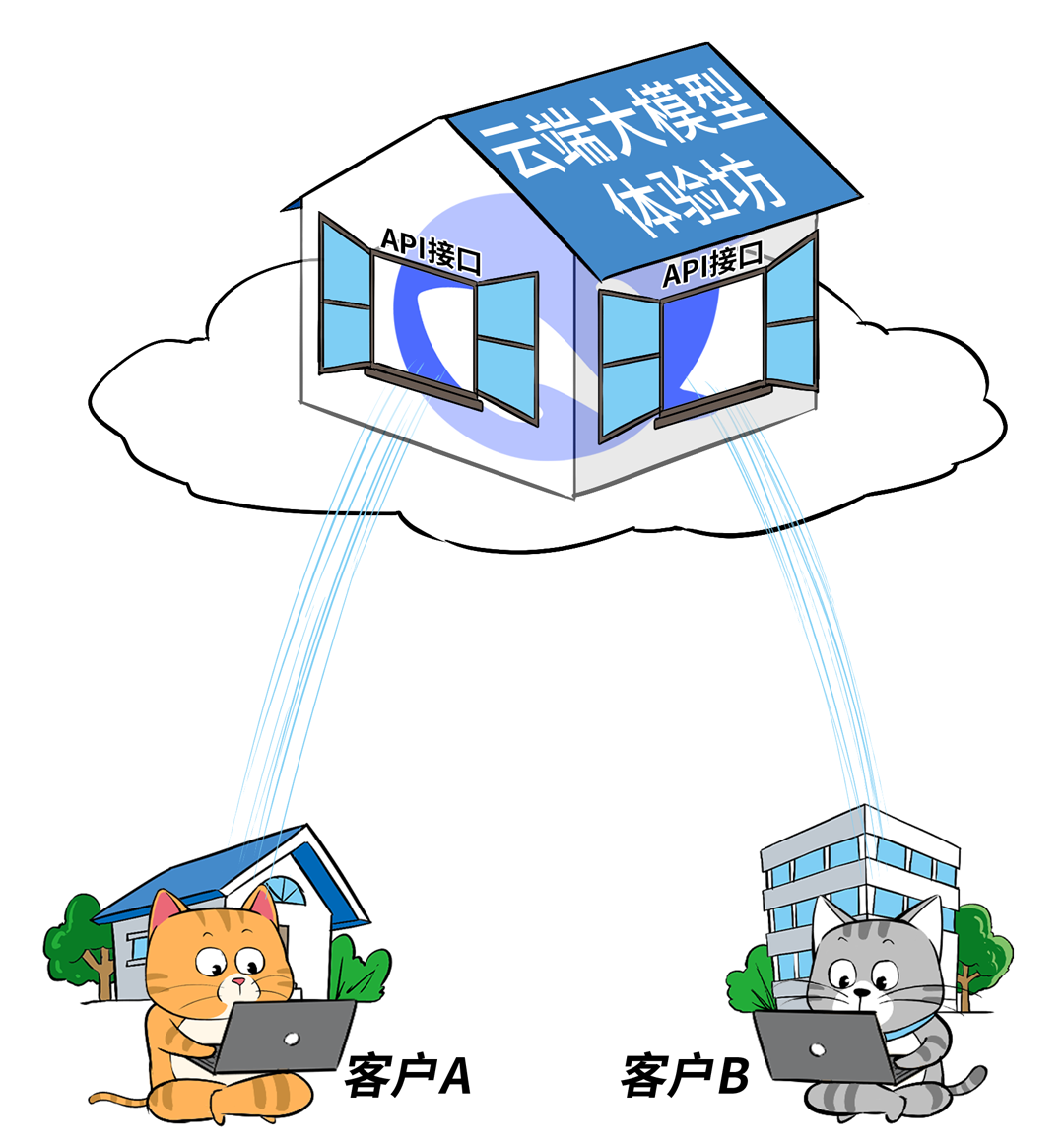
**缺点:**共享算力,容易踩到劣质API的坑,需要一定的甄别能力。
❹ 基于公有云AI Infra部署模型:
**优点:**成本低,部署快,模型独享,安全有保障,模型可持续优化迭代、定制。

**缺点:**数据要出域,不适用于有强合规需求的场景,同时需要评估各家云服务商的能力。

这么说吧,四种方案各有优缺点,没有一种方案可以满足所有类型的客户需求。
不过我们需要明确一点的是,虽然DeepSeek很牛,但是我们仍然处在“大模型应用的初级阶段”。
在这个档口,无论小型企业还是大中型企业,都应该小步快跑、持续迭代,而不是想着一步到位。

因此,对于小微企业,首选方案❸,能够以极小的投入,快速赋能业务,吃到大模型红利。
对于成长型、大中型企业,首选方案❹,既可以快速切入,又可以满足未来的规模化应用、模型迭代与定制、模型的专属性以及安全性。
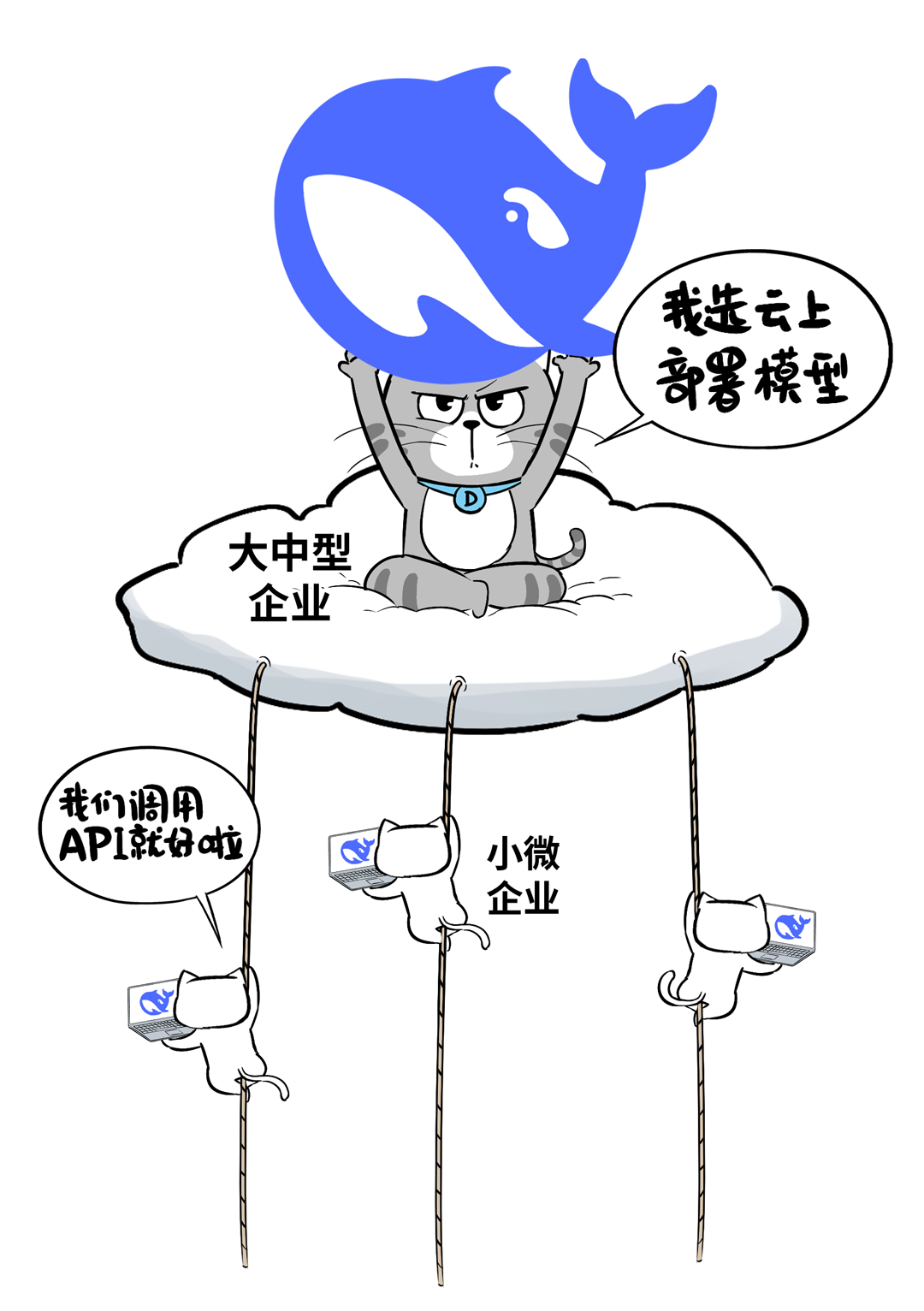
具体怎么选呢?
无论是方案❸调用API,还是方案❹云上自助部署,我们都推荐字节跳动旗下的**「火山引擎」**。

先看方案❸API云端调用的场景,目前能够提供DeepSeek API服务多达几十家,但接口的性能、延迟、稳定性却大不相同。
这些因素,都将直接影响DeepSeek最终体验。

而目前,从各类第三方评测机构的数据看,API接口性能、稳定性,火山全面领先。
下面我们节选了来自国内知名拨测平台基调听云的测评结果,包括火山引擎、DeepSeek官方在内的五大API。
其中,火山引擎(火山方舟)提供的DeepSeek API接口,在平均速度、推理速度、生成速度上均表现最优,且首tokens延迟最低。
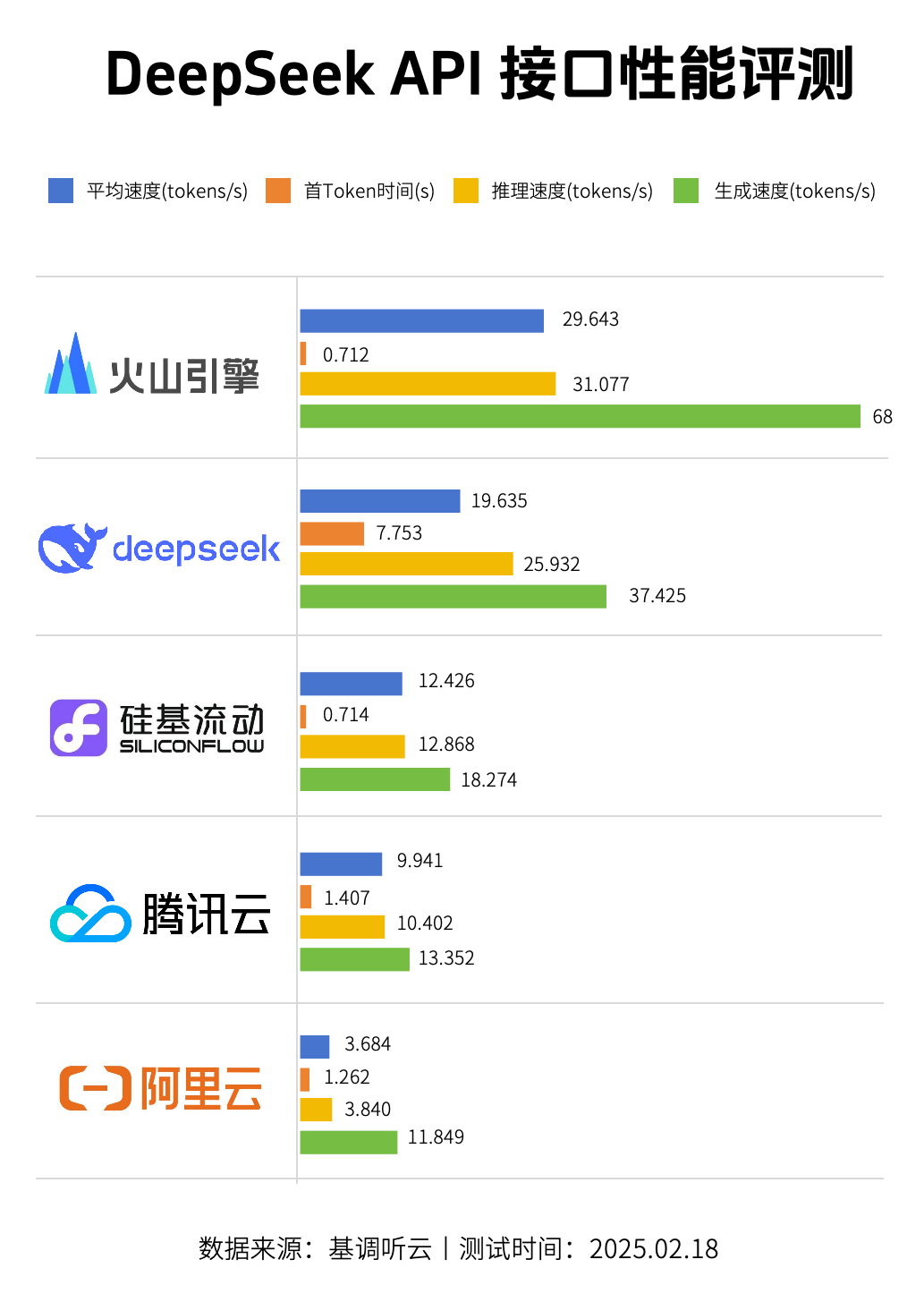
不仅如此,根据该评测报告,火山引擎API接口稳定性高达99.83%。
无独有偶,国内另一家中文大模型评测机构superCLUE也发布了各家API的测评结果,火山引擎在完整回复率、准确率、输出速率等均处于领先地位。
同时,火山引擎的火山方舟平台,提供高达500万TPM的全网最高初始限流,以及超过50亿的初始离线TPD配额。

同样的,再看方案❹云上部署模型的场景↓
首先,API服务的性能和稳定性,已经从侧面证明了火山引擎AI Infra的实力,没有好的底座,上层服务再“妖娆”,也是空中楼阁。
更重要的是,火山引擎为大模型上云,做好了一系列准备↓
一、丰富的GPU云主机机型,支持各种尺寸模型。
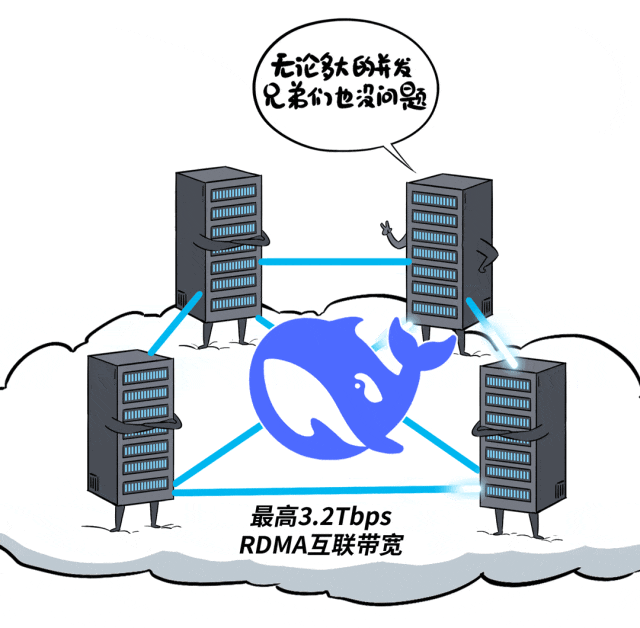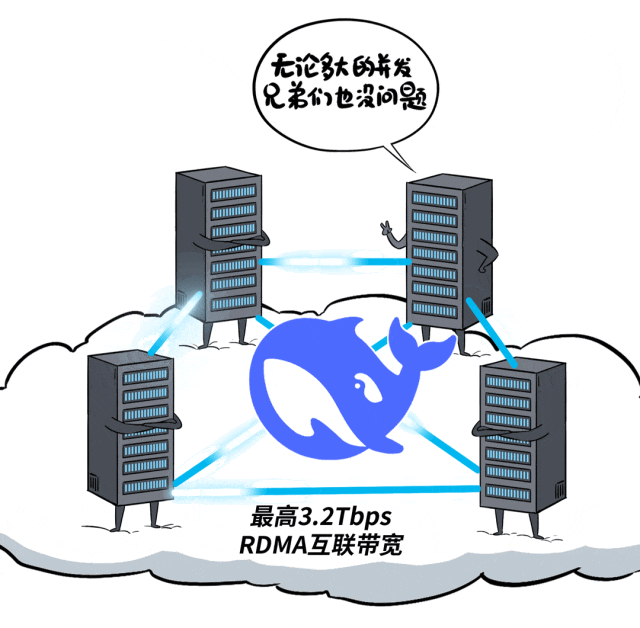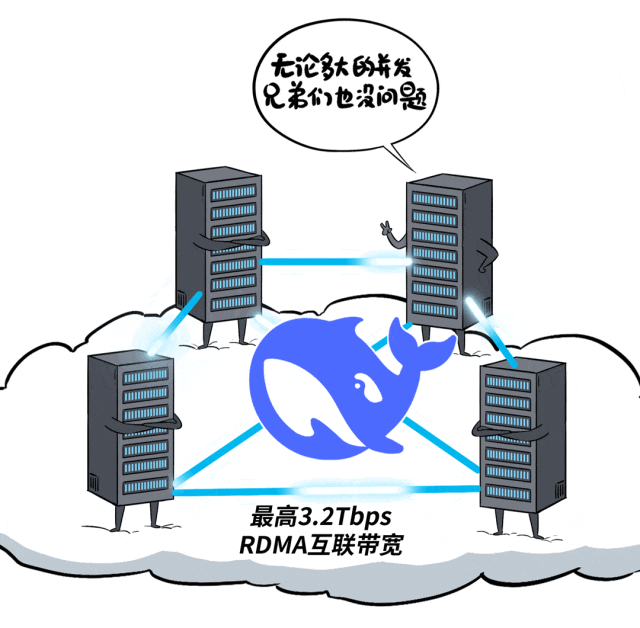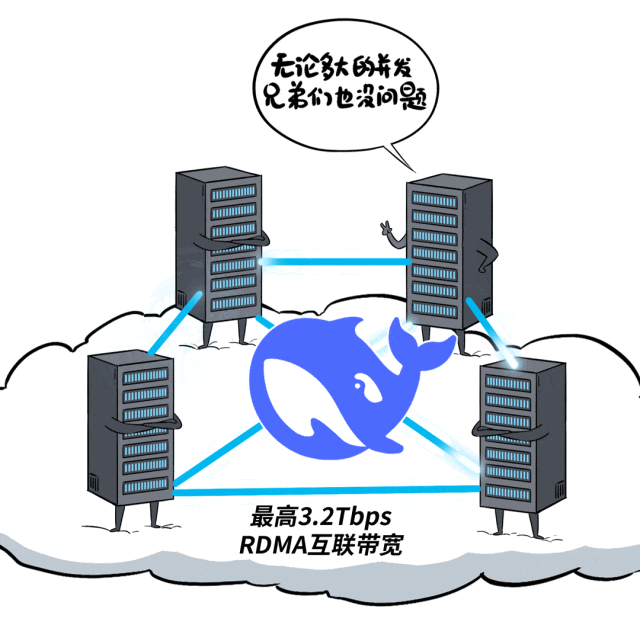
火山引擎可以提供24G、48G、80G、96G等多种显存规格的计算实例,单机最大可支持768G显存,满足满血版DeepSeek R1/V3模型的部署。

同时,火山引擎提供成熟的高性能多机互联集群,跨计算节点可提供高达3.2Tbps的无损互联带宽。
通过扩展高性能集群,可以满足更大规模的并发推理需求。
二、模型部署与推理全栈加速
大模型的推理服务,并不是你显卡够牛、显存够大就完事OK了,更需要端到端的全栈优化加速。
火山引擎从底层的IaaS、PaaS再到上层的机器学习平台、火山方舟API调用,每个对应的层级都有针对性的优化,从而系统化、立体化地支撑DeepSeek快速部署与推理服务
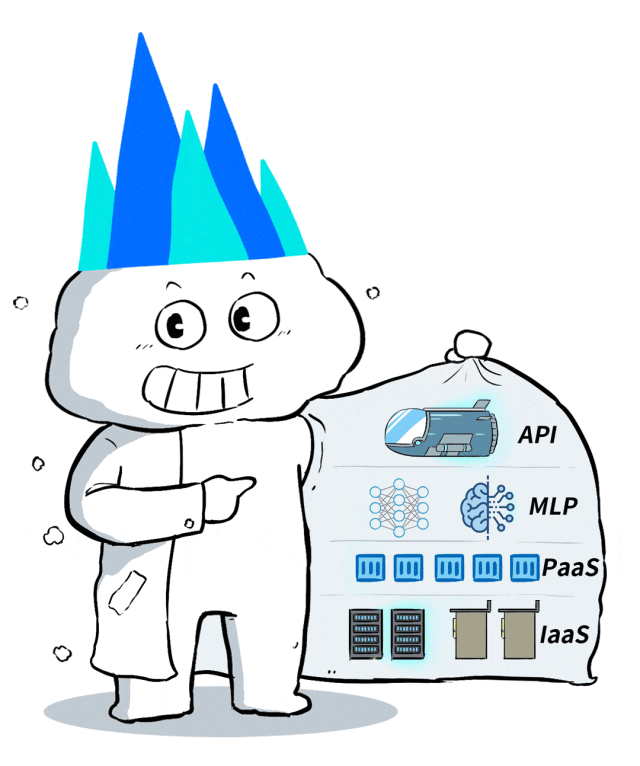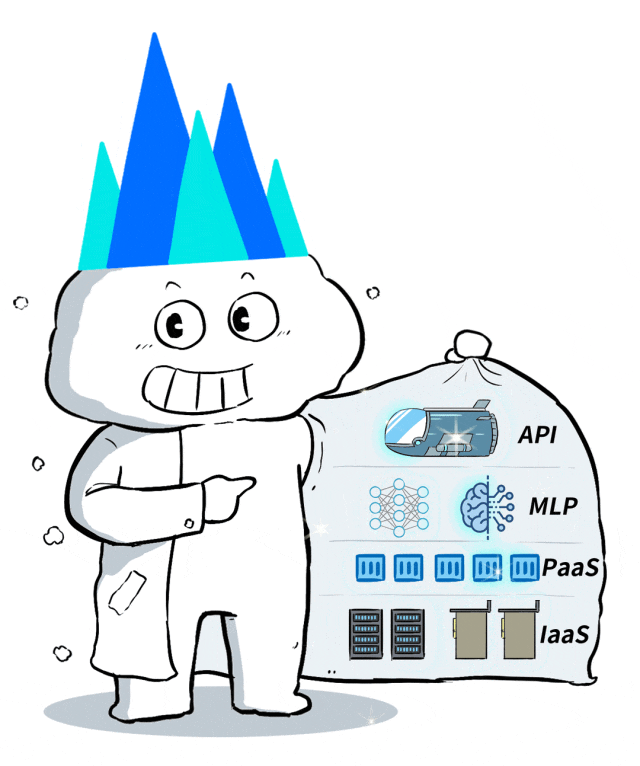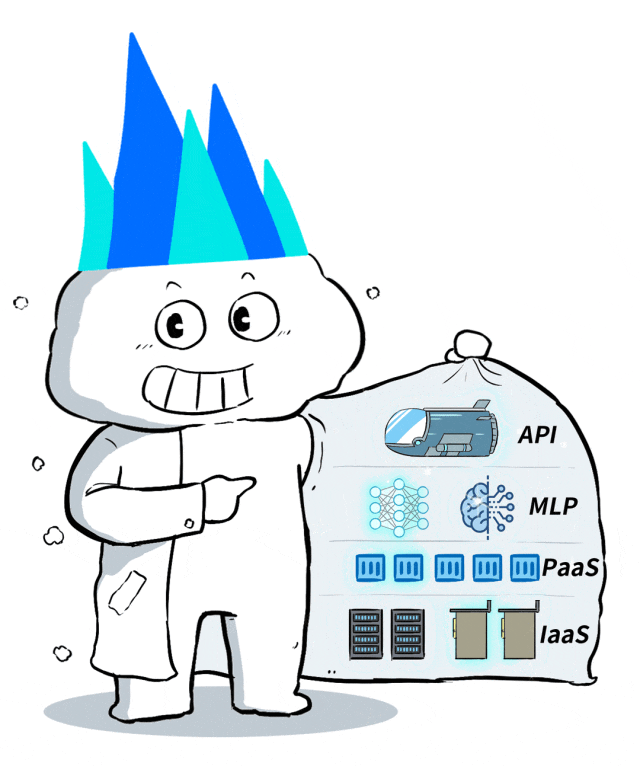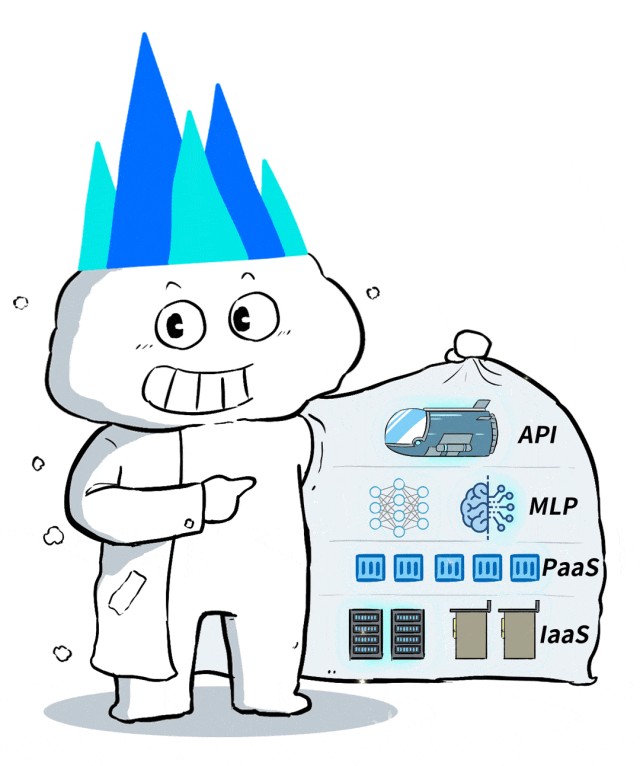
这里面有些独门黑科技,我们单拎出来说——
❶ 支持PD分离架构:
Transformer架构大模型干活的过程,可以分为两步:并行处理的Prefill阶段和串行处理的Decode阶段。
Prefill阶段可以一次性算完,而Decode阶段每生成一个新token,都要依赖前面的结果,串行输出,速度天然慢。

这两个阶段对算力的要求其实是不一样的。如果把PD混在一起跑,效率会大打折扣,而PD分离就可以提升效率、节省资源、优化延迟。
举个通俗的例子:不分离像是你边看菜谱边炒菜,PD分离是先把菜谱背熟(Prefill),然后专心炒(Decode),效率高到飞起。

这下明白PD分离的重要性了吧。
而火山引擎是国内公有云平台中,最先支持DeepSeek PD分离的,对于P和D阶段用什么卡、比例多少,可以为用户提供最佳实践。
客户只需选择平台预置的模型文件、支持自研xLLM推理引擎的环境镜像、推理算力,即可一键完成DeepSeek R1满血版PD分离集群化部署,最高推理吞吐提升5倍。

❷ 自研vRDMA网络,大幅提升互联效率:
火山引擎自研vRDMA网络,具备国内首创的基于标准RoCE v2协议的vRDMA能力,可以低门槛的、无侵入式的支撑各种AI框架和软件栈。
有了强大的网络支撑,各种PD分离计算、跨池计算、算存互联的效率可以大大提升,整体通信性能提升最高达80%,时延降低超过70%。

❸ KV Cache优化:
KV Cache可以有效加速推理速度,但也会吃掉更多的内存和显存(尤其超长序列任务)。
为此,火山引擎提供弹性极速缓存产品,专门针对大模型推理所需的KV-Cache进行优化,通过多级缓存、GDR零拷贝等手段,使推理时延降低至1/50,GPU开销降低20%。

❹ 自研推理加速引擎xLLM:
火山引擎提供自研推理加速引擎xLLM,提升大模型推理性能100%以上,同时还支持SGlang和vLLM开源引擎,为大家提供更多灵活选择。

三、模型调优与一站式模型定制
云上部署大模型的优势,不仅仅是企业可以独享模型,更重要的是可以进行按需调优和定制。
在火山引擎部署DeepSeek,可以使用其机器学习平台进行全尺寸模型调优服务。

同时,火山引擎还提供了高性能自研模型蒸馏框架veTuner、强化学习框架veRL,以及训推一体、任务优先级调度和故障自愈能力。
用户可以在自己的专属VPC网络中,基于推理形成的业务数据,进行模型蒸馏、强化学习…
整套方案也可以基于火山引擎混合云,适配本地/云上混合部署。
如此,企业级客户最希望的模型调优和定制需求,都可以一站式搞定。

四、长期技术驱动打造极致性价比
以目前最热门的、支持满血版DeepSeek部署的8卡GPU云服务器(显存96G×8)为例,火山引擎在市场上做到了价格最优。

凭啥火山引擎能做到更优的价格?其实是长期技术驱动打造出极致性价比。
首先是资源成本被“摊薄”了,字节系抖音、今日头条等多个头部业务拥有海量的算力资源池,在内外统一的云原生基础架构加持下,火山引擎与字节跳动国内业务实现资源并池。
凭借规模优势和自研服务器能力,火山引擎把机器资源的采购、生产、规模化运营成本都降到业界极低的水平。
同时,通过“削峰填谷”的极致调度能力,字节跳动国内业务的空闲计算资源可以极速调度到火山引擎,分钟级调度10万核CPU、上千卡GPU的资源量,并通过抢占式实例和弹性预约实例,做到GPU资源潮汐复用。

五、安全性与稳定性
火山引擎自研大模型应用防火墙,具备强大的 All in One 安全防护能力,可为云上部署DeepSeek保障企业级生产流量稳定吞吐和全栈保护。
除此之外,火山引擎的云上模型服务,还增加了各种高可用机制(可观测性、检测与恢复),从而提供超强的稳定性。
这一点,大家看前面的API稳定性测试报告,心中就有谱了吧。

还有一点,针对部分客户对一体机模式的“偏爱”,火山引擎也没有让大家失望:AI一体机DeepSeek版闪亮登场!
火山引擎AI一体机支持DeepSeek R1/V3全系列模型、HiAgent AI应用创新平台、大模型防火墙以及轻量模型训练平台,涵盖模型部署、管理、推理、微调、蒸馏以及AI应用开发等全链路能力。


好了,我们总结一下↓
小微企业、个人开发者轻量应用选API调用,大中型企业重度应用、定制选云上部署,一体机“铁粉”们,当然也可以选择一体机开箱即用。
无论哪种选择,火山引擎AI云原生,都是AI时代云基础设施的最优解。

还想了解更多信息?您可以扫描加入「火山引擎官方大模型技术交流群」,与大模型研发、算法、产品、服务等同学交流互动。
也可以点击阅读原文,前往火山方舟免费体验DeepSeek R1满血版↙
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 3069
3069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









