







由于Dify最近推出的升级版中,工作流里面新增了非常重要的Agent节点,它的推出,能不能让我们通过拖拉拽快速构建出Manus呢,带着这个问题,我们往下看。
一、Dify版本升级到v1.0.1
在拆解工作流前,我们先把dify升级到最新版v1.0.1,上个版本我使用的是v1.0.0,这个版本由于改动较大,存在比较多bug。
v1.0.1 版本主要修复了 v1.0.0 的稳定性问题(如插件超时、工作流节点错误等),并优化了缓存机制和界面交互,我们到dify github发布页面(https://github.com/langgenius/dify/releases,查看新版发布说明:
Docker部署方式升级步骤详解(源码部署的,请自行查看上述网站)
-
1. Back up your customized docker-compose YAML file (optional)
备份你的自定义 docker-compose YAML 文件(可选)
启动wsl,cd到项目根目录
cd docker
cp docker-compose.yaml docker-compose.yaml.$(date +%s).bak
-
2. Get the latest code from the main branch
从主分支获取最新代码
git checkout main
git pull origin main
-
3. Stop the service,Command, please execute in the docker directory
停止服务,命令,请在 docker 目录执行
docker compose down
-
4. Back up data 备份数据
tar -cvf volumes-$(date +%s).tgz volumes
-
5. Upgrade services 升级服务
docker compose up -d
6. 验证升级结果
-
• 访问 http://localhost,点右上角工作空间位置 --> 关于
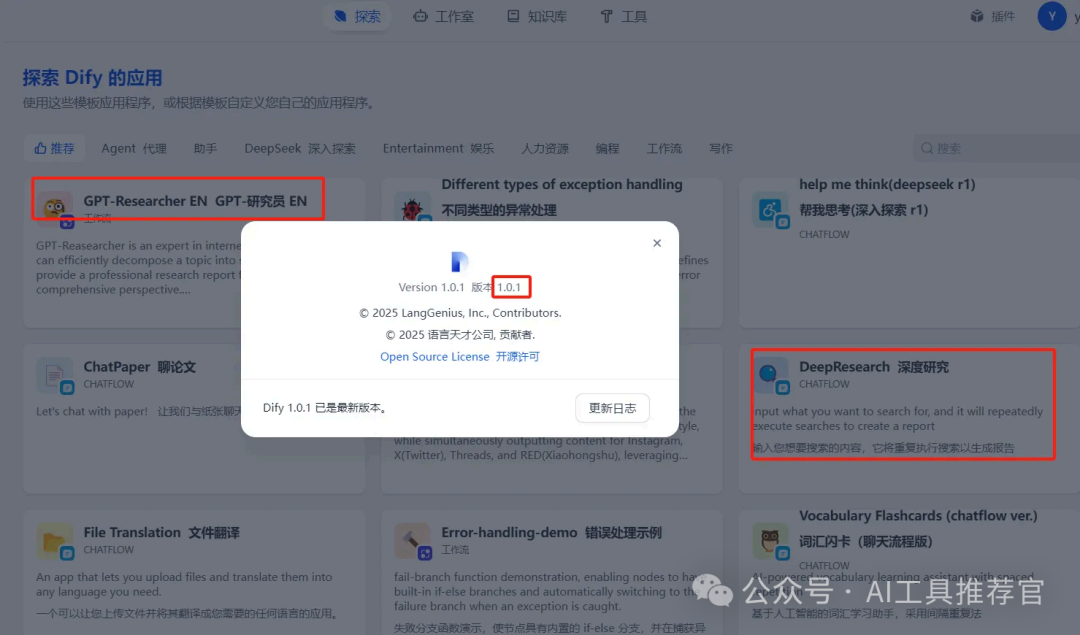
v1.0.1版本升级成功,迫不及待查看下,发现“DeepResearch 深度研究”和“GPT-Reseacher EN-GPT研究员 EN”仍然安稳的躺在推荐页面。
二、DeepResearch深度研究工作流拆解
先把工作流复制到工作区,然后导出DSL
让腾讯元宝根据dsl画一下流程图,
提示词:
这是一个dify工作流的配置文件,请先详细描述一下,工作流的各个节点,然后描述整个流程。最后,用mermaid画出流程图。
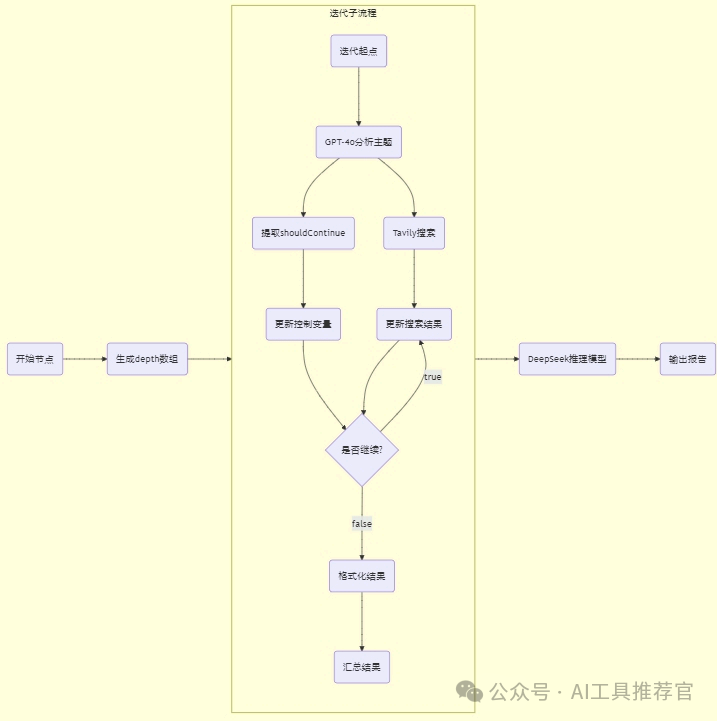
节点的简洁概括如下
-
1. Start Node接收用户输入,触发流程。
-
2. Code Node根据用户输入的
depth生成数组,控制迭代次数。 -
3. Iteration Node遍历数组,执行循环逻辑。
-
4. LLM Node分析当前主题,生成下一个搜索主题和是否继续的标志。 llm的提示词: system prompt:
您正在调查以下主题。您发现了什么?还有哪些问题尚未解决?接下来需要调查哪些具体方面? ## 输出要求 - 不要输出与已搜索主题完全相同的内容。 - 如果需要进一步搜索信息,请设置`nextSearchTopic`。 - 如果已经获取了足够的信息,请将`shouldContinue`设置为`false`。 - 请以JSON格式输出。 { "nextSearchTopic": "str | None", "shouldContinue": bool }user prompt
## Topic {sys.query} ## Findings {findings} ## Searched Topics {topics} -
5. Tavily Search Node执行网络搜索,返回结果。
-
6. JSON Parse Nodes提取
nextSearchTopic和shouldContinue变量。 -
7. Assign Variables Node更新搜索主题列表和控制变量。
-
8. If-Else Node根据
shouldContinue判断是否继续迭代。 -
9. Template Transform Node格式化中间搜索结果。
-
10. Variable Aggregator Node汇总所有中间结果。
-
11. Final LLM Node分析汇总结果,生成最终报告。
-
12. Answer Node输出最终结果。
流程整体功能
这个工作流通过用户输入的深度参数(depth)控制迭代次数,利用LLM动态生成搜索主题并调用Tavily搜索引擎获取信息。每次迭代后,根据LLM的判断决定是否继续搜索。所有中间结果会被汇总,最终由DeepSeek推理模型生成一份综合研究报告。整个流程实现了从动态搜索到智能分析的闭环,适用于需要深度调研的场景。
流程图说明
-
1. 主流程:从用户输入开始,生成数组后进入迭代节点,迭代结束后汇总结果,最终生成报告并输出。
-
2. 迭代子流程:每次迭代中,LLM生成搜索主题,Tavily执行搜索,根据
shouldContinue判断是否继续迭代。中间结果通过模板格式化后汇总。 -
3. 动态控制:通过
shouldContinue变量动态决定是否继续迭代,避免不必要的搜索。
三、让DeepReSearch工作流跑起来,看看效果
为了跑起来,需要做点准备工作:
1、用谷歌邮箱注册一个Tavily账号,获取一个key(每月可以获得1000次免费搜索额度,简单玩一下还是够用的)
2、配置大模型,这里有两个LLM节点
3、在Intermediate Output Format节点一个检索结果输出
{{ index + 1 }}/{{ depth }}th search executed.
{{ text }} # 添加检索结果输出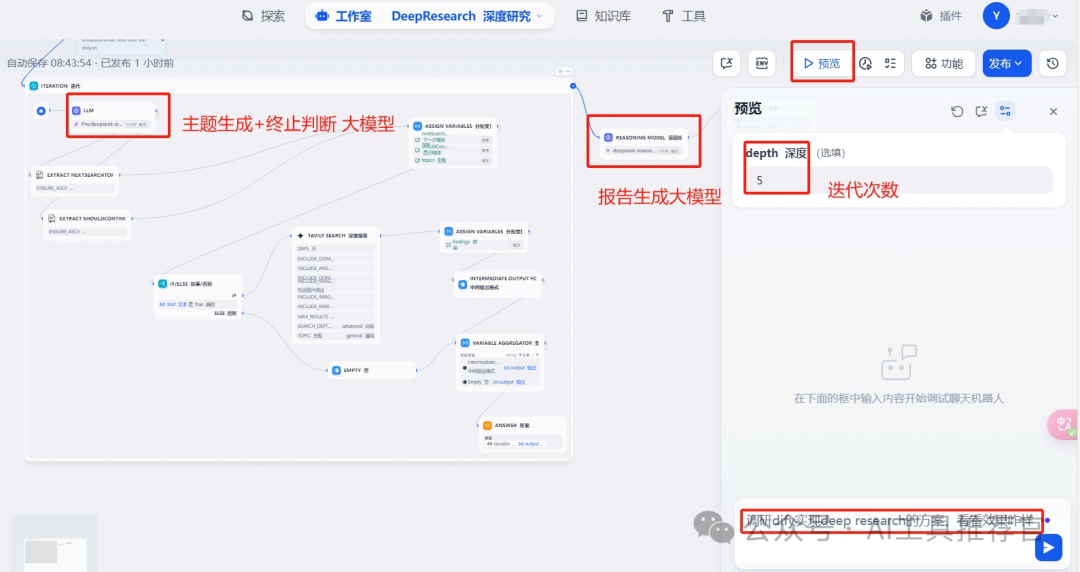
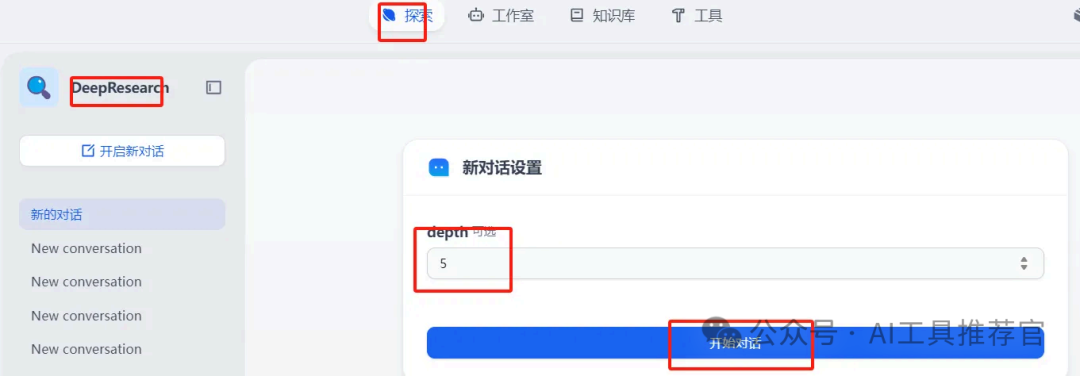
做完以上准备工作,我们既可以发布工作流了,这里我们先点开预览看看,可以看到这个工作流只需设置一个depth深度参数(如上文,它是用来控制迭代次数,继而控制检索次数的),然后就可以输入你的研究题目让deepresearch自动研究了。
预览没问题后,点发布工作流,来到探索页面,输入depth和问题启动DeepResearch。
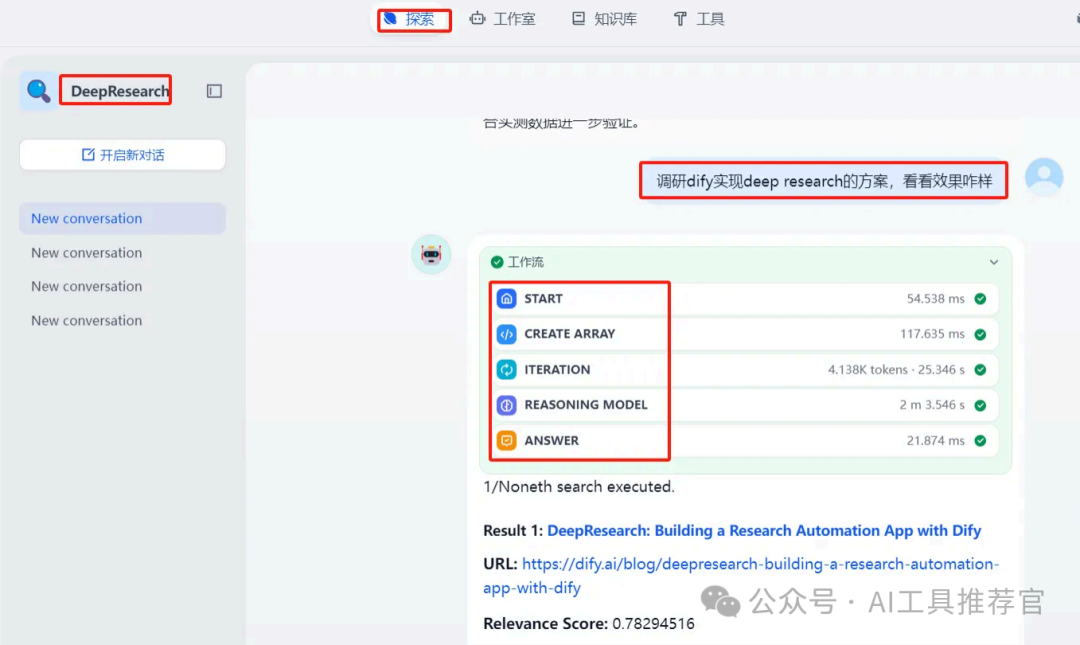
我们再转到工作流日志界面,查看工作流内部节点执行详细日志
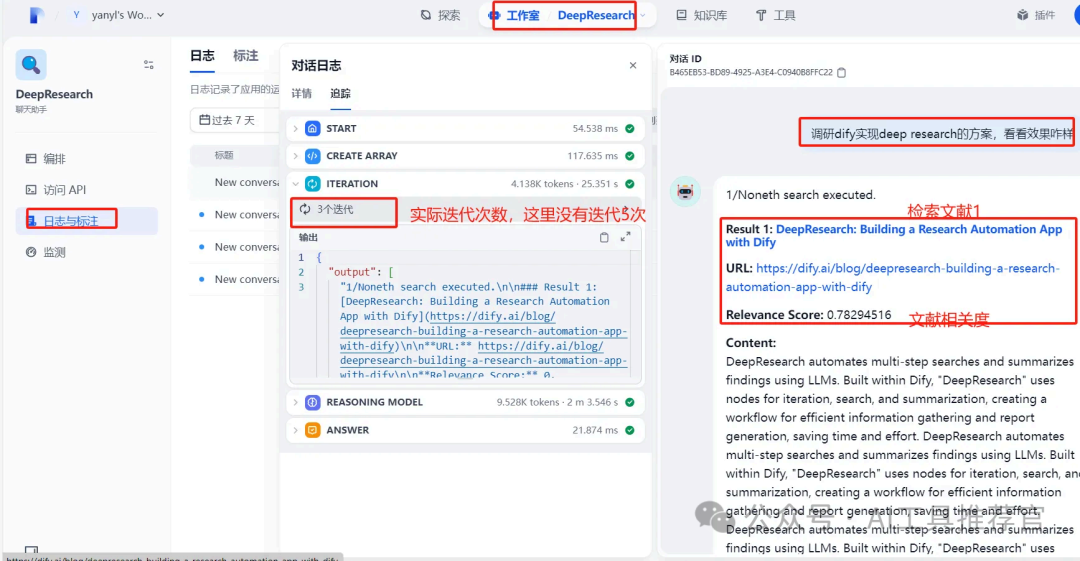
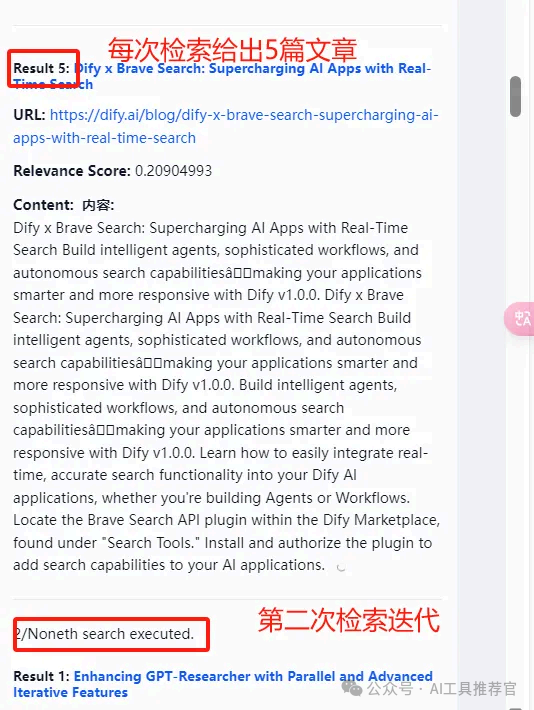
可以看到,这个任务,迭代节点整个只迭代了3次,llm就判停了,另外,右侧输出了检索到的结果,为1篇英文文章,并给出了相关分数。每次迭代,Tavily会检索5篇文章,3次迭代总共检索了15篇,都是英文文章。
看下最后结果
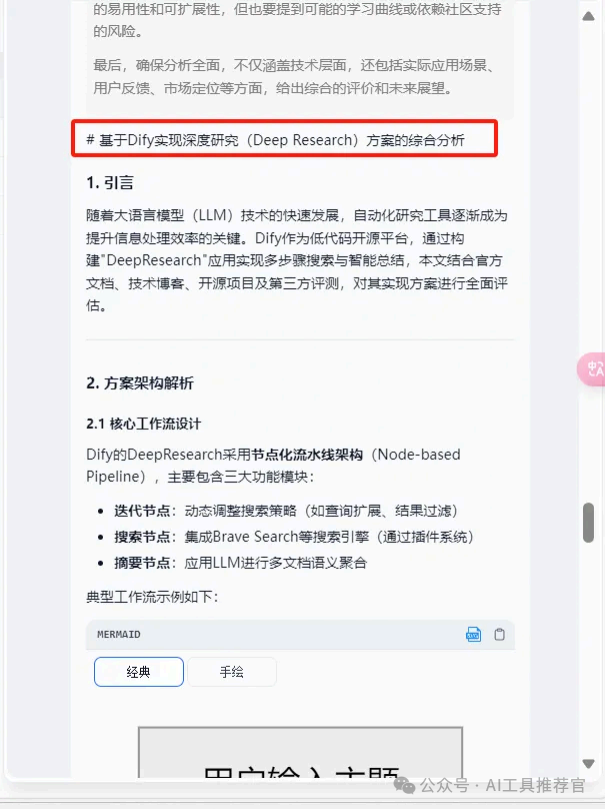
结果只能说是中规中矩吧,个人感觉并比腾讯元宝要差。这也是可以预期的,毕竟这个工作流还是太简单了一些,要应用到生产,还有很多很多优化要做,比如,LLM主题分析和终止搜索节点的设置,信源组成,报告生成节点的设置等等。
但是,它也给我带来惊喜,帮我们揭开了DeepResearch的神秘面纱,让我们可以从这里出发,进入DeepResearch
四、从OpenManus架构和新版Dify推出的Agent节点再看否可以搭建Manus
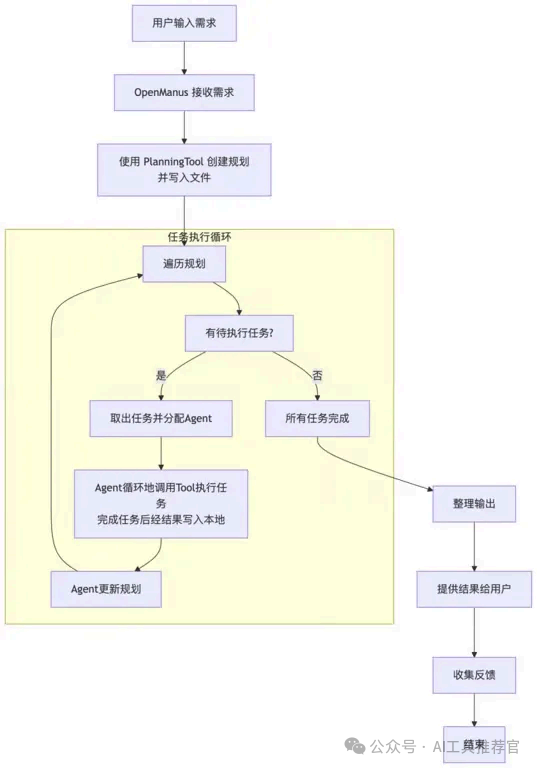
我们知道从3月5日晚Manus发布以来,国内掀起了一股Manus宣传风暴,MetaGPT团队和CAMEL AI团队在3月7日同一天分别开源了OpenManus和OWL这两个仿Manus框架,并在开源社区爆发式传播开来。我们拿OpenManus来分析一下这种多智能体的架构和原理,OpenManus 的技术架构主要依托于模块化、多智能体协同的设计理念,其核心思路可以总结为以下几个方面:
-
1. 多智能体协同
-
• 系统将一个复杂任务拆分为多个子任务,并由不同的智能体(Agent)分别负责。例如,一个 Agent 负责理解用户需求、另一个负责工具调用(如浏览器自动化、文件操作等),各智能体之间通过消息传递协同工作,从而实现整体任务的自动化执行。
-
2. 任务调度与反馈机制
-
• 通过一个任务调度层,将用户输入转换为具体的操作指令,并根据每个子任务的执行情况实时反馈。这种机制保证了系统能动态调整执行策略,确保各步骤之间的协调与高效运行。
-
3. 工具调用层
-
• OpenManus 集成了多种工具接口,如代码执行、网络搜索、浏览器自动化等,这些工具都通过统一的接口被各个 Agent 调用,形成一个灵活可扩展的工具链,支持不同任务场景下的操作需求。
我在3月12发的文章中《深度解析:Dify能否复刻Deep Research与Manus?三大工具深度对比》提到,Dify Agent的配置手段非常简单,无法利用Dify平台预置的节点或工具,构建Manus这种具备“规划——执行——反馈”的复杂多智能体系统。好巧不巧的是,Dify.AI也在这天发布了《Dify Agent 节点 - 当工作流学会「自主思考」》,指出在Dify v1.0.0版本中,Agent的构建方式迎来了重大更新,在工作流中新增了Agent节点,Agent 节点被定义为工作流中的“智能决策中心”,允许通过插件化的 Agent 策略(如 ReAct、Function Calling)实现自主推理与工具调用。
看到了吗,这是不是有Manus的影子了?
在这里也要跟各位读者道个歉,在发上篇文章时由于思维惯性,没有注意到这个重大的更新点,因为自己使用一年多Dify以来,确确实实Agent这块,一直就没咋大变化过。这无疑说明Manus出现后,Dify也在快速跟进。
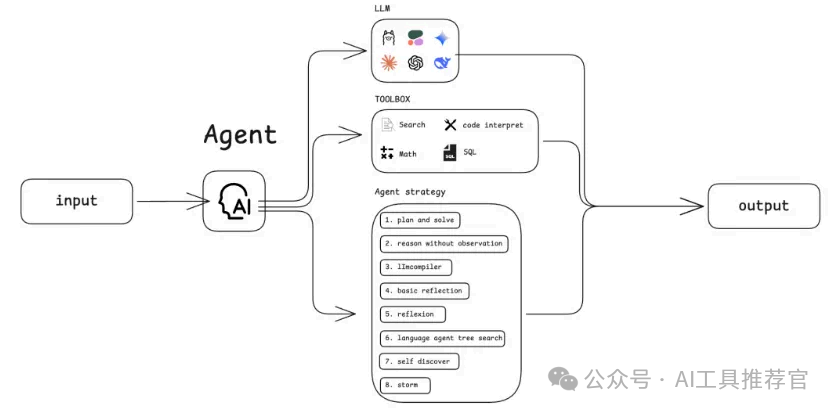
引用一下《Dify Agent 节点 - 当工作流学会「自主思考」》中的原话来说明Agent的执行一般流程:
代理的执行流程分为三个主要阶段:初始化、迭代循环和回答。在初始化阶段,系统会设置好所需的参数、工具和上下文。接着进入迭代循环,在这个阶段,系统会准备包含当前上下文的提示,并使用工具信息调用大型语言模型(LLM)。然后,系统解析 LLM 的响应,以确定是调用工具还是获得最终答案。如果需要调用工具,系统会执行相应的工具,并用工具的输出结果更新上下文。这个循环会持续进行,直到任务完成或达到预设的最大迭代次数为止。最后,在最终阶段,系统会返回最终的答案或结果。不得不说,上面这个流程和OpenManus的流程图是非常像的。
回到核心问题,最新版的Dify到底能不能搭建出一个完整的Manus或者是OpenManus呢,个人判断,暂时还是不能的,因为目前缺失记忆、browser-use等辅助模块,但是目前核心模块Agent节点出来了,照着OpenManus的流程图,通过拖拉拽,分分钟就能用工作流把一个简易版的OpenManus的流程给拼凑出来。
所以,最终Dify会不会推出一个工作流版的完整版的Manus,让我们普通开发者通过简单拖拉拽就能完成这种高大上的应用构建,这个答案还需要一点时间,让子弹飞再一会吧。
后记
就在我准备发出这篇文章时,发现Dify竟然又上新版了—— v1.1.0,这是什么速度!
目前主要新增了一个知识库元数据过滤功能,和一些比较小的增强功能,Agent方面暂时没有重大更新。
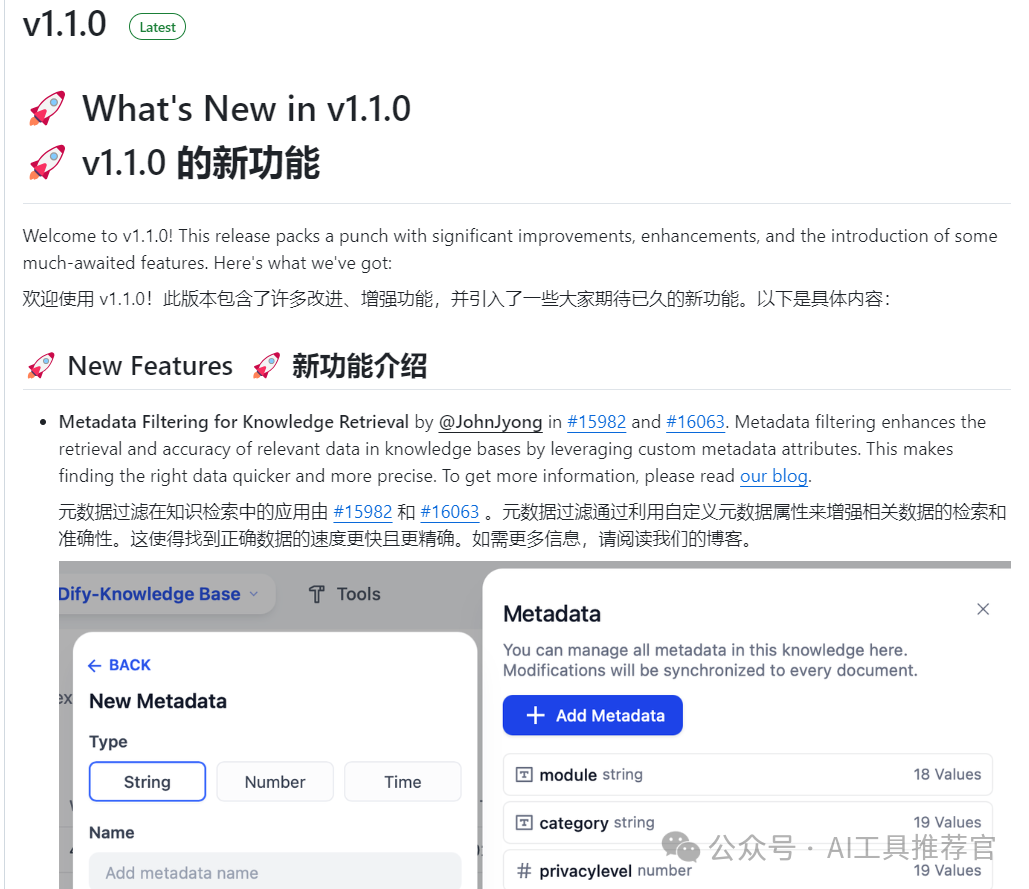
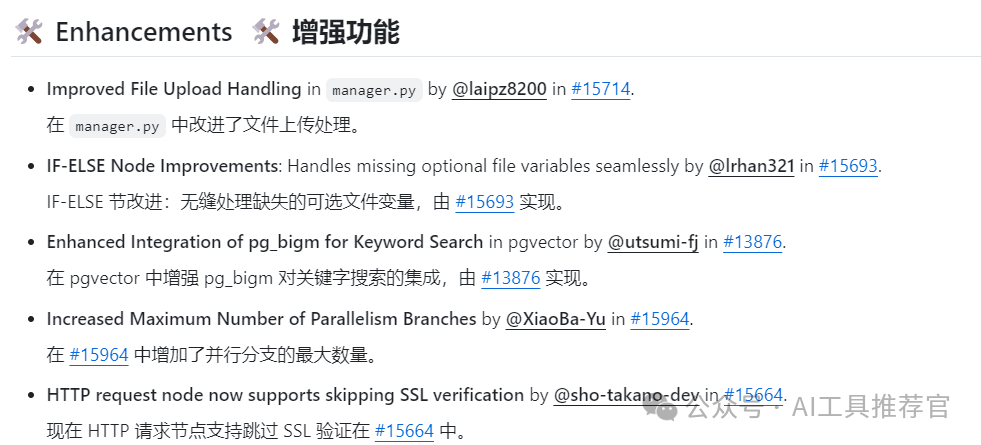
后面我们会推出继续深入探索对Dify内置DeepResearch的完善和补充,包括扩充信源(本地文献、开源Firecrawl、百度和bing等搜索引集成)、工作流优化,以及深入探索Dify Agent 相关功能,欢迎持续关注。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









