






前言
flux 刚出来的时候画个图是真的慢,经过社区一轮一轮的优化,现在 4090 不使用加速 Lora 的情况下,生成 30 步 1024 * 1024 的图片只需要 16 秒。
这两天社区又来给 flux 加速了,这个技术就是 TeaCache,一种免训练的缓存方法,可估计和利用跨时间步的模型输出之间的波动差异,从而加速推理。在不损失图像质量的前提下,可以在原来的基础上实现 1.4 到 2 倍的加速。
听雨试了下无损的参数配置基本只需要 10 秒就可以出图,如果可以接受损失一些质量,可以缩短到 8 秒出图。并且可以和 Lora 以及 ControlNet 一起使用。
好了,话不多说,我们直接开整!
上边的对于 TeaCache 的介绍,小伙伴们可能不是很理解,我们还是通俗一点再来简单介绍一下:
TeaCache 就好比一个聪明的“记事本”,它能够观察并记录下模型在不同时间点输出结果之间的变化情况。通过分析这些变化,TeaCache 可以预测出在某些时间点上,模型的输出结果可能与之前的结果非常相似,因此就可以直接使用之前的结果,而不需要再次进行复杂的计算。这样一来,模型在进行推理时就可以节省大量的计算资源和时间,从而提高整体的运行效率。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~
大致的原理就是这样,和编程里的缓存很像,可以帮我们加速获取结果。
我们来看下具体的效果,这个是基础的 flux 工作流, 30 步 1024 * 1024 分辨率,可以看到采样器上耗时是 16 秒。
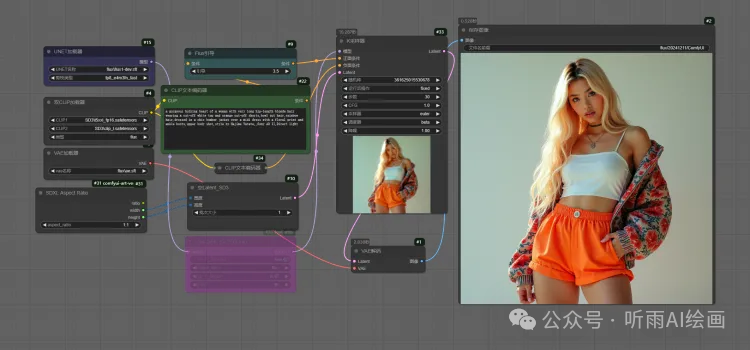
接下来我们加上 TeaCache 节点,可以看到生成的两张图完全一样,但是采样时间只需要 9 秒,差不多提速了一倍。
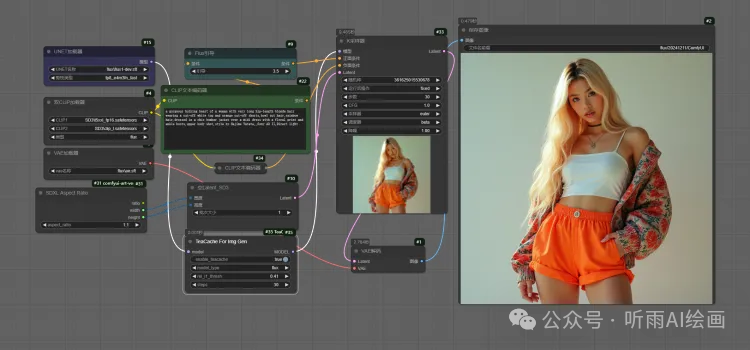
两张图片可以对比下,基本没有任何区别。

如果我们调大 TeaCache,这里把 TeaCache 节点中的「rel_l1_thresh」设置为 1,上边设置的是 0.4,出图速度可以达到惊人的 6 秒。
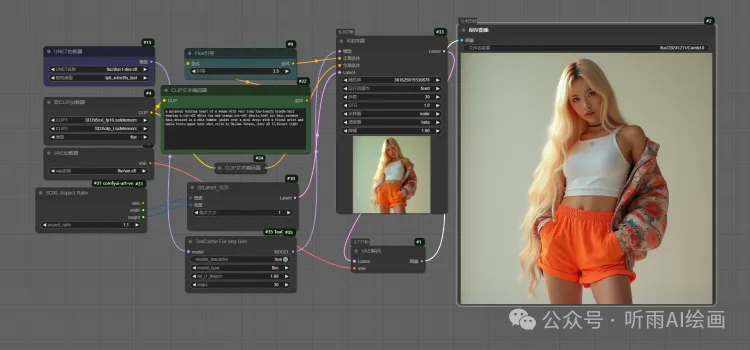
但是相应的也会丢失一些质量,左边的图可以看到是损失了一些精度的,看起来有些模糊,所以无损的话,我们设置 0.4 左右就可以了。

插件的安装也很简单,直接在 ComfyUI 管理器中搜索:ComfyUI-TeaCache,进行安装就可以了。
使用上也很简单,只需要链接在模型加载节点和采样器节点之间就可以了。
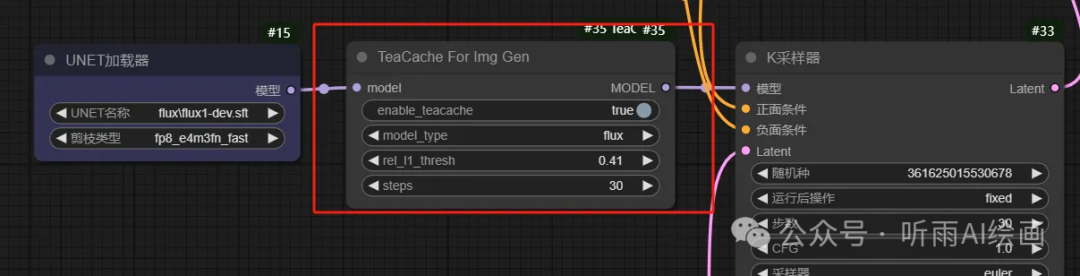
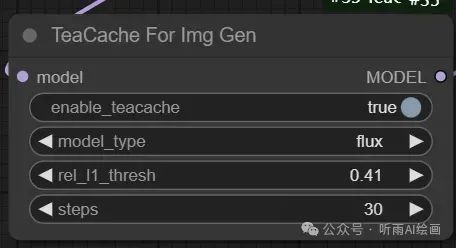
节点就一个,我们简单来讲下这些参数:
enable_teacache:是否开启缓存,关闭就相当于没有这个节点。
model_type:现在只有 flux,后续作者会支持混元以及 LTX-Video 视频模型。
rel_l1_thresh:这个参数值越大,生图速度越快,图片质量会下降,不同的模式和步数,rel_l1_thresh 的最优值都会有细微变化,可以在 0.4 左右调整。
steps:这个和采样节点里的步数保持一致即可。
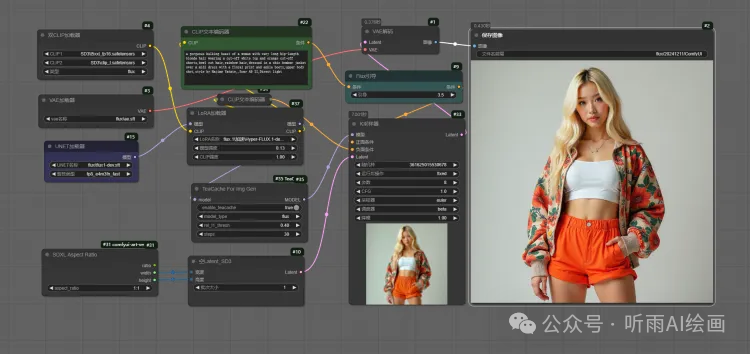
基础的工作流讲完了,我们开头说它是支持 Lora 的,那我们还可以再加上字节的 8 步加速 Lora 模型,速度还可以继续提升,可以提升到 7 秒内,这速度相比于 flux 刚出来的时候,不知道快了多少倍了。
开源社区就是牛逼。
ControlNet 也是一样的操作,并且听雨也试过了,flux 的量化模型以及微调模型都是可以使用这个节点加速的哦!
而且 TeaCache 不仅可以加速 flux 这类生图大模型,还可以加速混元之类的视频大模型,雨露均沾,一起进入加速时代!
好了,今天的分享就到这里了,感兴趣的小伙伴快去试试吧!
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …

二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …

三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …

四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …

五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取


















 2667
2667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









