







一、导言
MobileNetV3是Google研究团队推出的下一代MobileNet系列模型,专为移动设备设计的高效卷积神经网络。它结合了互补的搜索技术和新颖的架构设计,旨在为移动CPU优化,并在准确率、延迟和模型大小之间取得更好的平衡。以下是关于MobileNetV3的关键特性与改进点的概述:
-
硬件感知的网络架构搜索 (NAS) 与NetAdapt结合: MobileNetV3的开发利用了硬件感知的网络架构搜索方法,这种方法考虑了具体硬件限制,比如CPU性能,以减少推理延迟。此外,它还结合了NetAdapt算法来进一步优化模型,确保模型在特定延迟约束下保持高准确性。
-
新颖的架构设计: 在NAS和NetAdapt的基础上,研究人员还手动进行了一系列架构上的改进,比如调整瓶颈结构、非线性激活函数等,以提升模型效率和准确性。
-
h-Swish激活函数: 为了提高效率并减少内存访问成本,MobileNetV3引入了h-Swish,这是基于swish函数的一种硬版本,它通过分段函数实现,减少了计算成本,同时在模型的较深层次中使用,以充分利用其优势。
-
大型Squeeze-and-Excite (SE)模块: 相比于之前根据瓶颈结构大小来决定SE模块尺寸的做法,MobileNetV3固定将SE模块设置为扩张层通道数的1/4,这在增加少量参数的同时提高了模型准确性,且没有显著增加延迟。
-
模型定义: MobileNetV3分为两个模型:MobileNetV3-Large和MobileNetV3-Small,分别针对高性能和低资源使用场景。这些模型都是通过平台感知的NAS和NetAdapt搜索,以及本节定义的网络改进共同创建的。
-
性能提升:
- MobileNetV3-Large在ImageNet分类任务上比MobileNetV2的准确率提高了3.2%,同时延迟降低了20%。
- MobileNetV3-Small在与MobileNetV2具有相似延迟的情况下,准确率提高了6.6%。
- 对于对象检测,MobileNetV3-Large在COCO数据集上的检测速度比MobileNetV2快25%左右,且准确率相近。
- 语义分割方面,MobileNetV3-Large的LR-ASPP比MobileNetV2的R-ASPP快34%,在Cityscapes数据集上保持了类似的准确率。
-
应用扩展: MobileNetV3不仅在图像分类任务上表现出色,还被成功应用于对象检测和语义分割等任务,通过适应如SSDLite等轻量化检测框架,以及提出新的高效分割解码器LR-ASPP,展现了广泛的实用性。
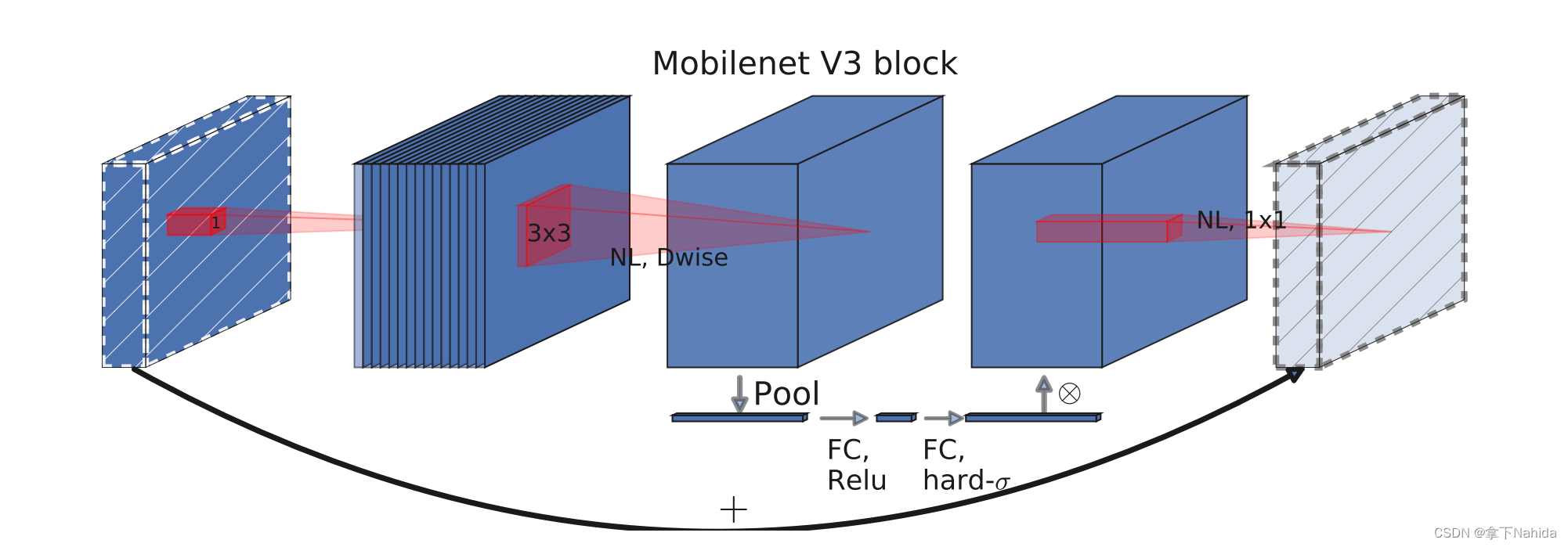
二、准备工作
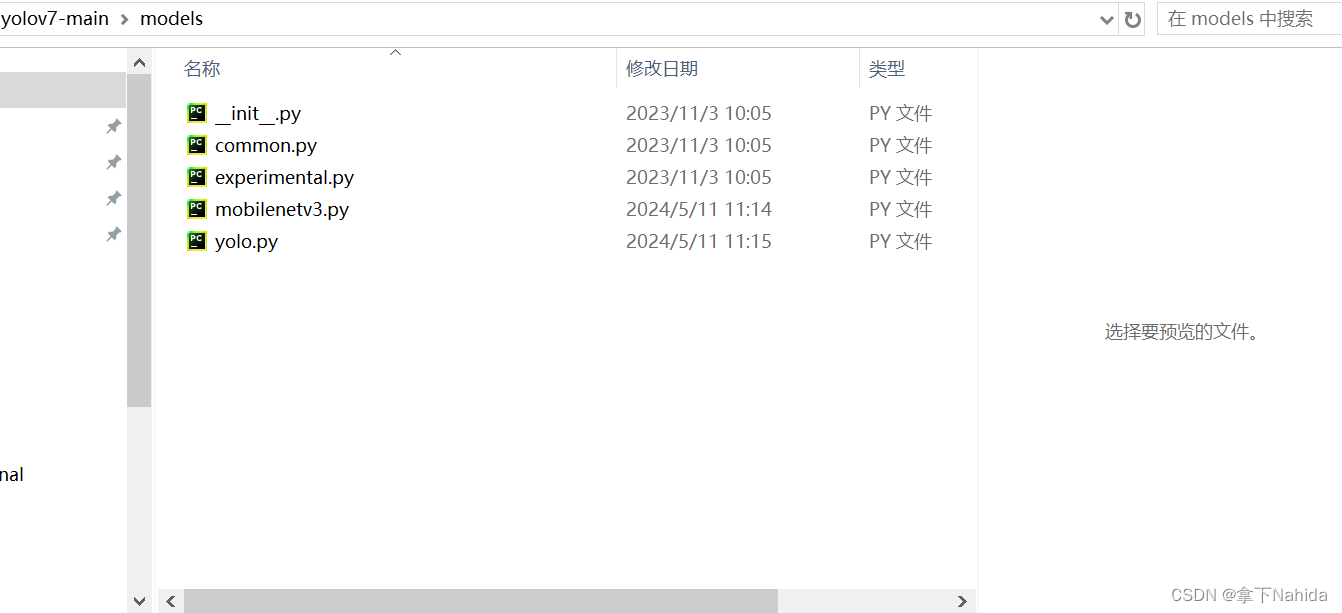
首先在YOLOv5/v7项目文件下的models文件夹下创建新的文件mobilenetv3.py
导入如下代码
from models.common import *
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class conv_bn_hswish(nn.Module):
def __init__(self, c1, c2, stride):
super(conv_bn_hswish, self).__init__()
self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = h_swish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MobileNetv3_block(nn.Module):
def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):
super(MobileNetv3_block, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
h_swish() if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
y = self.conv(x)
if self.identity:
return x + y
else:
return y
其次在在YOLOv5/v7项目文件下的models/yolo.py中在文件首部添加代码
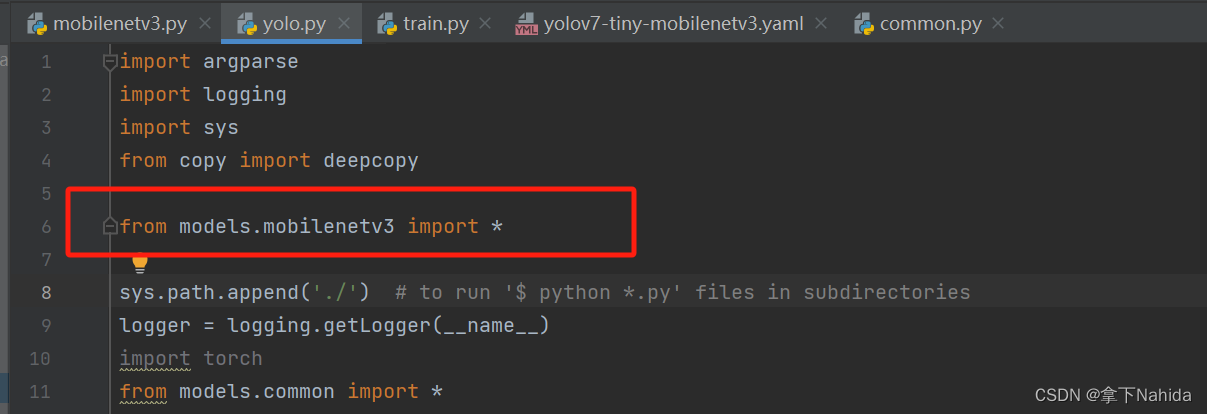
from models.mobilenetv3 import *并搜索def parse_model(d, ch)
定位到如下行添加以下代码
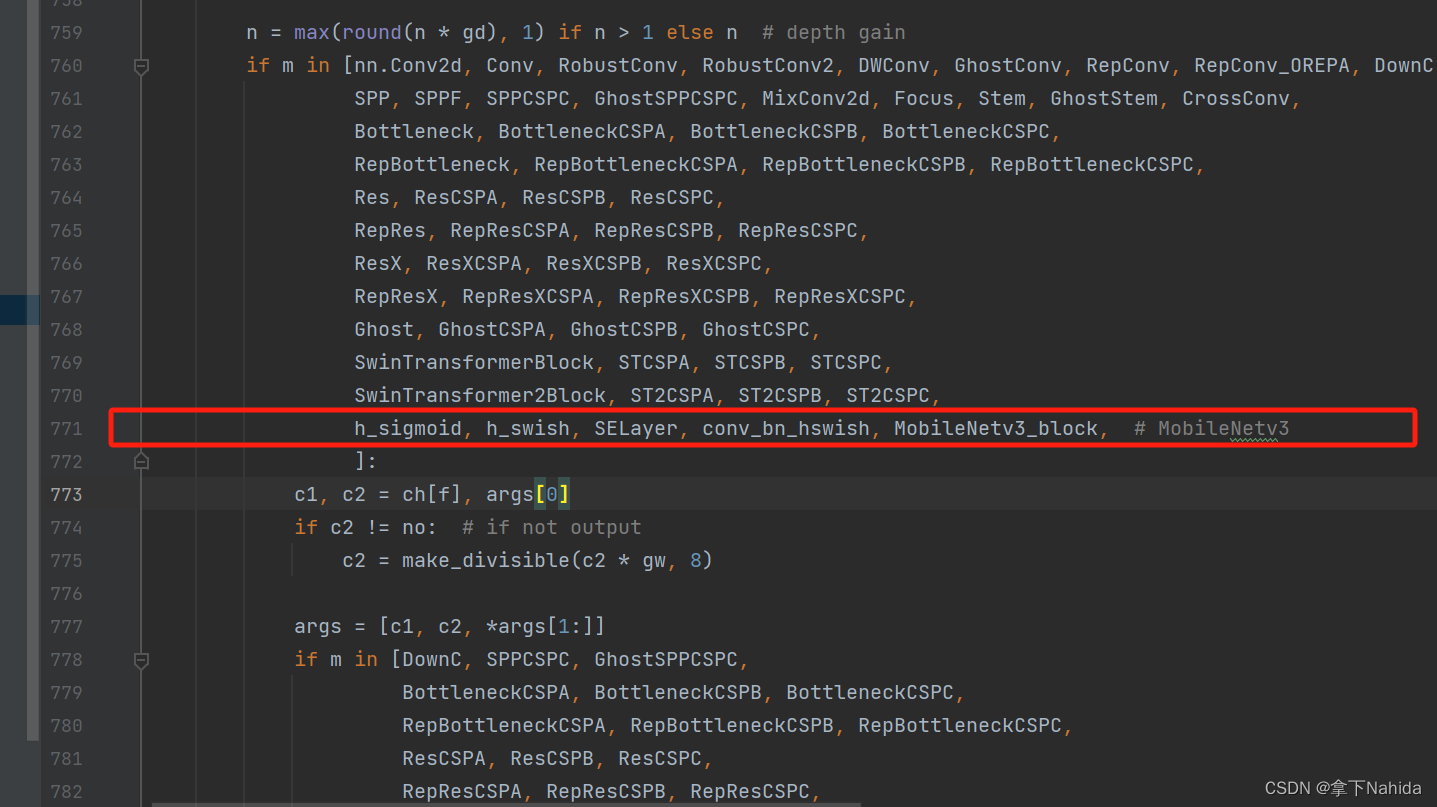
h_sigmoid, h_swish, SELayer, conv_bn_hswish, MobileNetv3_block,三、YOLOv7-tiny改进工作
完成二后,在YOLOv7项目文件下的cfg/training文件夹下创建新的文件yolov7-tiny-mobilenetv3.yaml,导入如下代码。
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[ [ -1, 1, conv_bn_hswish, [ 16, 2 ] ], # 0 p1/2
[ -1, 1, MobileNetv3_block, [ 16, 16, 3, 2, 1, 0 ] ], # 1 p2/4
[ -1, 1, MobileNetv3_block, [ 24, 72, 3, 2, 0, 0 ] ], # 2 p3/8
[ -1, 1, MobileNetv3_block, [ 24, 88, 3, 1, 0, 0 ] ],
[ -1, 1, MobileNetv3_block, [ 40, 96, 5, 2, 1, 1 ] ], # 4 p4/16
[ -1, 1, MobileNetv3_block, [ 40, 240, 5, 1, 1, 1 ] ],
[ -1, 1, MobileNetv3_block, [ 40, 240, 5, 1, 1, 1 ] ],
[ -1, 1, MobileNetv3_block, [ 48, 120, 5, 1, 1, 1 ] ],
[ -1, 1, MobileNetv3_block, [ 48, 144, 5, 1, 1, 1 ] ],
[ -1, 1, MobileNetv3_block, [ 96, 288, 5, 2, 1, 1 ] ], # 9 p5/32
[ -1, 1, MobileNetv3_block, [ 96, 576, 5, 1, 1, 1 ] ],
[ -1, 1, MobileNetv3_block, [ 96, 576, 5, 1, 1, 1 ] ], # 11
]
# yolov7-tiny head
head:
[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, SP, [5]],
[-2, 1, SP, [9]],
[-3, 1, SP, [13]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -7], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 20
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[8, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 30
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[3, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 40
[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 30], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 48
[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 20], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 56
[40, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[48, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[56, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[57,58,59], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]最后,修改train.py的cfg参数为刚刚创建的yolov7-tiny-mobilenetv3.yaml,运行。
from n params module arguments
0 -1 1 464 models.mobilenetv3.conv_bn_hswish [3, 16, 2]
1 -1 1 612 models.mobilenetv3.MobileNetv3_block [16, 16, 16, 3, 2, 1, 0]
2 -1 1 3864 models.mobilenetv3.MobileNetv3_block [16, 24, 72, 3, 2, 0, 0]
3 -1 1 5416 models.mobilenetv3.MobileNetv3_block [24, 24, 88, 3, 1, 0, 0]
4 -1 1 13736 models.mobilenetv3.MobileNetv3_block [24, 40, 96, 5, 2, 1, 1]
5 -1 1 55340 models.mobilenetv3.MobileNetv3_block [40, 40, 240, 5, 1, 1, 1]
6 -1 1 55340 models.mobilenetv3.MobileNetv3_block [40, 40, 240, 5, 1, 1, 1]
7 -1 1 21486 models.mobilenetv3.MobileNetv3_block [40, 48, 120, 5, 1, 1, 1]
8 -1 1 28644 models.mobilenetv3.MobileNetv3_block [48, 48, 144, 5, 1, 1, 1]
9 -1 1 91848 models.mobilenetv3.MobileNetv3_block [48, 96, 288, 5, 2, 1, 1]
10 -1 1 294096 models.mobilenetv3.MobileNetv3_block [96, 96, 576, 5, 1, 1, 1]
11 -1 1 294096 models.mobilenetv3.MobileNetv3_block [96, 96, 576, 5, 1, 1, 1]
12 -1 1 25088 models.common.Conv [96, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
13 -2 1 25088 models.common.Conv [96, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
14 -1 1 0 models.common.SP [5]
15 -2 1 0 models.common.SP [9]
16 -3 1 0 models.common.SP [13]
17 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
18 -1 1 262656 models.common.Conv [1024, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
19 [-1, -7] 1 0 models.common.Concat [1]
20 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
21 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
22 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
23 8 1 6400 models.common.Conv [48, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
24 [-1, -2] 1 0 models.common.Concat [1]
25 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
26 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
27 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
28 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
29 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
30 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
31 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
32 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
33 3 1 1664 models.common.Conv [24, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
34 [-1, -2] 1 0 models.common.Concat [1]
35 -1 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
36 -2 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
37 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
38 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
39 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
40 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
41 -1 1 73984 models.common.Conv [64, 128, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
42 [-1, 30] 1 0 models.common.Concat [1]
43 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
44 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
45 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
46 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
47 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
48 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
49 -1 1 295424 models.common.Conv [128, 256, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
50 [-1, 20] 1 0 models.common.Concat [1]
51 -1 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
52 -2 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
53 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
54 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
55 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
56 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
57 40 1 73984 models.common.Conv [64, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
58 48 1 295424 models.common.Conv [128, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
59 56 1 1180672 models.common.Conv [256, 512, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
60 [57, 58, 59] 1 17132 models.yolo.IDetect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 384 layers, 4169242 parameters, 4169242 gradients, 6.9 GFLOPS若打印出如上文本代表改进成功。
四、YOLOv5n改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5n-mobilenetv3.yaml,导入如下代码。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# MobileNetV3
[[-1, 1, conv_bn_hswish, [16, 2]], # 0-p1/2
[-1, 1, MobileNetv3_block, [16, 16, 3, 2, 1, 0]], # 1-p2/4
[-1, 1, MobileNetv3_block, [24, 72, 3, 2, 0, 0]], # 2-p3/8
[-1, 1, MobileNetv3_block, [24, 88, 3, 1, 0, 0]], # 3
[-1, 1, MobileNetv3_block, [40, 96, 5, 2, 1, 1]], # 4-p4/16
[-1, 1, MobileNetv3_block, [40, 240, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [40, 240, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [48, 120, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [48, 144, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [96, 288, 5, 2, 1, 1]], # 9-p5/32
[-1, 1, MobileNetv3_block, [96, 576, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [96, 576, 5, 1, 1, 1]], # 11
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 15
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 19 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 16], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 22 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 25 (P5/32-large)
[[19, 22, 25], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
最后,修改train.py的cfg参数为刚刚创建的yolov5n-mobilenetv3.yaml,运行。
from n params module arguments
0 -1 1 232 models.mobilenetv3.conv_bn_hswish [3, 8, 2]
1 -1 1 628 models.mobilenetv3.MobileNetv3_block [8, 8, 16, 3, 2, 1, 0]
2 -1 1 2104 models.mobilenetv3.MobileNetv3_block [8, 8, 72, 3, 2, 0, 0]
3 -1 1 2568 models.mobilenetv3.MobileNetv3_block [8, 8, 88, 3, 1, 0, 0]
4 -1 1 9848 models.mobilenetv3.MobileNetv3_block [8, 16, 96, 5, 2, 1, 1]
5 -1 1 43772 models.mobilenetv3.MobileNetv3_block [16, 16, 240, 5, 1, 1, 1]
6 -1 1 43772 models.mobilenetv3.MobileNetv3_block [16, 16, 240, 5, 1, 1, 1]
7 -1 1 14702 models.mobilenetv3.MobileNetv3_block [16, 16, 120, 5, 1, 1, 1]
8 -1 1 19364 models.mobilenetv3.MobileNetv3_block [16, 16, 144, 5, 1, 1, 1]
9 -1 1 61752 models.mobilenetv3.MobileNetv3_block [16, 24, 288, 5, 2, 1, 1]
10 -1 1 211008 models.mobilenetv3.MobileNetv3_block [24, 24, 576, 5, 1, 1, 1]
11 -1 1 211008 models.mobilenetv3.MobileNetv3_block [24, 24, 576, 5, 1, 1, 1]
12 -1 1 1664 models.common.Conv [24, 64, 1, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 8] 1 0 models.common.Concat [1]
15 -1 1 19840 models.common.C3 [80, 64, 1, False]
16 -1 1 2112 models.common.Conv [64, 32, 1, 1]
17 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
18 [-1, 3] 1 0 models.common.Concat [1]
19 -1 1 5056 models.common.C3 [40, 32, 1, False]
20 -1 1 9280 models.common.Conv [32, 32, 3, 2]
21 [-1, 16] 1 0 models.common.Concat [1]
22 -1 1 18816 models.common.C3 [64, 64, 1, False]
23 -1 1 36992 models.common.Conv [64, 64, 3, 2]
24 [-1, 12] 1 0 models.common.Concat [1]
25 -1 1 74496 models.common.C3 [128, 128, 1, False]
26 [19, 22, 25] 1 4086 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [32, 64, 128]]
Model Summary: 343 layers, 793100 parameters, 793100 gradients, 1.2 GFLOPs若打印出如上文本代表改进成功。
五、YOLOv5s改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-mobilenetv3.yaml,导入如下代码。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# MobileNetV3
[[-1, 1, conv_bn_hswish, [16, 2]], # 0-p1/2
[-1, 1, MobileNetv3_block, [16, 16, 3, 2, 1, 0]], # 1-p2/4
[-1, 1, MobileNetv3_block, [24, 72, 3, 2, 0, 0]], # 2-p3/8
[-1, 1, MobileNetv3_block, [24, 88, 3, 1, 0, 0]], # 3
[-1, 1, MobileNetv3_block, [40, 96, 5, 2, 1, 1]], # 4-p4/16
[-1, 1, MobileNetv3_block, [40, 240, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [40, 240, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [48, 120, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [48, 144, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [96, 288, 5, 2, 1, 1]], # 9-p5/32
[-1, 1, MobileNetv3_block, [96, 576, 5, 1, 1, 1]],
[-1, 1, MobileNetv3_block, [96, 576, 5, 1, 1, 1]], # 11
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 15
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 19 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 16], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 22 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 25 (P5/32-large)
[[19, 22, 25], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
最后,修改train.py的cfg参数为刚刚创建的yolov5s-mobilenetv3.yaml,运行。
from n params module arguments
0 -1 1 464 models.mobilenetv3.conv_bn_hswish [3, 16, 2]
1 -1 1 612 models.mobilenetv3.MobileNetv3_block [16, 16, 16, 3, 2, 1, 0]
2 -1 1 3864 models.mobilenetv3.MobileNetv3_block [16, 24, 72, 3, 2, 0, 0]
3 -1 1 5416 models.mobilenetv3.MobileNetv3_block [24, 24, 88, 3, 1, 0, 0]
4 -1 1 13736 models.mobilenetv3.MobileNetv3_block [24, 40, 96, 5, 2, 1, 1]
5 -1 1 55340 models.mobilenetv3.MobileNetv3_block [40, 40, 240, 5, 1, 1, 1]
6 -1 1 55340 models.mobilenetv3.MobileNetv3_block [40, 40, 240, 5, 1, 1, 1]
7 -1 1 21486 models.mobilenetv3.MobileNetv3_block [40, 48, 120, 5, 1, 1, 1]
8 -1 1 28644 models.mobilenetv3.MobileNetv3_block [48, 48, 144, 5, 1, 1, 1]
9 -1 1 91848 models.mobilenetv3.MobileNetv3_block [48, 96, 288, 5, 2, 1, 1]
10 -1 1 294096 models.mobilenetv3.MobileNetv3_block [96, 96, 576, 5, 1, 1, 1]
11 -1 1 294096 models.mobilenetv3.MobileNetv3_block [96, 96, 576, 5, 1, 1, 1]
12 -1 1 25088 models.common.Conv [96, 256, 1, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 8] 1 0 models.common.Concat [1]
15 -1 1 308736 models.common.C3 [304, 256, 1, False]
16 -1 1 33024 models.common.Conv [256, 128, 1, 1]
17 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
18 [-1, 3] 1 0 models.common.Concat [1]
19 -1 1 77568 models.common.C3 [152, 128, 1, False]
20 -1 1 147712 models.common.Conv [128, 128, 3, 2]
21 [-1, 16] 1 0 models.common.Concat [1]
22 -1 1 296448 models.common.C3 [256, 256, 1, False]
23 -1 1 590336 models.common.Conv [256, 256, 3, 2]
24 [-1, 12] 1 0 models.common.Concat [1]
25 -1 1 1182720 models.common.C3 [512, 512, 1, False]
26 [19, 22, 25] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 340 layers, 3542756 parameters, 3542756 gradients, 6.3 GFLOPs打印如上代码说明改进成功。
下一篇文章:【YOLOv5/v7改进系列】替换骨干网络为VanillaNet
将会进行手把手的改进教学。
更多文章产出中,主打简洁和准确,欢迎关注我,共同探讨!
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









