






1. 引言
自然语言处理(NLP)领域正经历着一场由大规模语言模型(Large Language Models, LLMs)引发的革命。这些模型凭借其惊人的规模和复杂性,正在重新定义我们对机器理解和生成人类语言能力的认知。本文旨在深入探讨LLMs在NLP中的应用、面临的技术挑战,以及未来的发展趋势,为NLP从业者和研究人员提供一个全面的技术视角。
2. 大规模语言模型的概述
2.1 定义与基本原理
大规模语言模型是一类基于深度学习的模型,通常包含数十亿到数万亿个参数。这些模型通过对海量文本数据进行自监督学习,能够捕捉语言的复杂结构和语义信息。LLMs的核心思想是通过预训练和微调的范式,学习通用的语言表示,并在各种下游任务中展现出强大的性能。
2.2 代表性模型
- GPT(Generative Pre-trained Transformer)系列: 由OpenAI开发,最新的GPT-4模型展示了惊人的多任务能力和推理能力。GPT系列采用自回归语言模型结构,通过预测下一个词来学习语言表示。
- BERT(Bidirectional Encoder Representations from Transformers): 由Google提出,BERT通过双向上下文编码学习深层的语言表示。它在众多NLP任务中取得了突破性进展,尤其在文本分类、命名实体识别等任务中表现卓越。
- T5(Text-to-Text Transfer Transformer): Google的T5模型将所有NLP任务统一为文本到文本的转换问题,提供了一个通用的框架来处理各种NLP任务。
2.3 模型训练的资源需求
训练LLMs需要巨大的计算资源和数据集。以GPT-3为例,其训练过程使用了数千块GPU,消耗了数百PB的数据,训练成本估计超过400万美元。这种规模的训练不仅需要高性能的硬件设施,还需要专门的分布式训练框架和优化算法。
3. 应用场景
3.1 文本生成与写作辅助
LLMs在文本生成任务中表现出色,能够产生连贯、流畅且符合上下文的文本。这一能力可应用于:
- 自动文章生成
- 对话系统和聊天机器人
- 创意写作辅助
- 代码生成和补全
实现方法:通常采用条件文本生成技术,根据给定的提示或上下文,使用模型的自回归解码能力生成后续文本。
3.2 机器翻译
LLMs为机器翻译带来了新的可能性:
- 零样本翻译:无需针对特定语言对进行训练,模型就能执行翻译任务
- 上下文感知翻译:更好地处理长文本和复杂语境
- 多语言翻译:单一模型支持多种语言之间的互译
技术实现:利用模型的跨语言理解能力,将源语言文本编码后,通过目标语言的解码器生成翻译结果。
3.3 问答系统
LLMs在问答系统中的应用极大地提升了系统的性能:
- 开放域问答:能够回答广泛领域的问题
- 多跳推理:能够综合多个信息源进行推理和回答
- 上下文理解:更好地理解问题的背景和意图
实现方法:将问题和相关上下文作为输入,模型通过深层语义理解和推理生成答案。
3.4 情感分析
LLMs在情感分析任务中展现出优越性:
- 细粒度情感识别:不仅识别正面/负面,还能捕捉复杂的情感nuances
- 上下文相关的情感分析:考虑更广泛的上下文信息
- 多模态情感分析:结合文本、图像等多种模态进行分析
技术实现:通过微调预训练模型,使其能够在特定的情感分类任务上表现出色。
3.5 信息抽取
LLMs在信息抽取任务中的应用:
- 命名实体识别(NER)
- 关系抽取
- 事件抽取
- 开放域信息抽取
实现方法:将信息抽取任务转化为生成任务或序列标注任务,利用模型的语言理解能力提取结构化信息。
4. 技术挑战
4.1 数据质量与多样性
挑战:
- 大规模数据收集的困难
- 数据清洗和质量控制的复杂性
- 确保数据多样性以避免模型偏见
解决方向:
- 开发更智能的数据收集和清洗工具
- 构建多样化的预训练语料库
- 引入主动学习等技术,提高数据效率
4.2 模型的可解释性
挑战:
- 模型决策过程的不透明性
- 难以解释模型的错误和偏见来源
解决方向:
- 开发新的可视化技术,展示模型内部状态
- 构建探测数据集,评估模型的行为模式
- 研究基于注意力机制的解释方法
4.3 计算资源与能耗
挑战:
- 训练和部署大规模模型的高昂成本
- 模型推理的实时性要求
- 能源消耗和环境影响
解决方向:
- 开发更高效的训练算法和架构
- 研究模型压缩和知识蒸馏技术
- 探索低能耗的神经网络硬件
4.4 数据隐私与安全
挑战:
- 训练数据中的隐私信息泄露风险
- 模型可能被用于生成有害内容
- 对抗性攻击的脆弱性
解决方向:
- 研究联邦学习等隐私保护训练方法
- 开发内容过滤和安全检查机制
- 增强模型对对抗性样本的鲁棒性
4.5 模型偏见与伦理问题
挑战:
- 模型继承和放大训练数据中的偏见
- 生成内容的公平性和中立性
- 模型使用的伦理边界定义
解决方向:
- 开发偏见检测和缓解技术
- 构建多样化和平衡的训练数据集
- 制定AI伦理准则和监管框架
5. 未来方向与趋势
5.1 更高效的训练方法
- 稀疏激活技术:如MoE(Mixture of Experts)
- 渐进式学习:逐步增加模型规模和数据复杂度
- 自适应预训练:根据任务动态调整预训练策略
5.2 增强的多模态学习
- 视觉-语言预训练:结合图像和文本信息
- 跨模态转换:如图像描述生成、文本到图像生成
- 多模态对话系统:整合语音、视觉和文本交互
5.3 更强的上下文理解能力
- 长文本建模:开发能处理更长序列的模型架构
- 知识增强:将结构化知识融入语言模型
- 推理能力增强:提升模型的逻辑推理和常识理解
5.4 模型在特定领域的专业化
- 领域适应技术:高效地将通用模型适应到特定领域
- 小规模高性能模型:为特定任务优化的轻量级模型
- 可组合的模型架构:根据任务动态组合模型组件
5.5 开放性与社区合作
- 开源模型和数据集:促进研究社区的合作与创新
- 模型评估基准:建立全面的评估框架
- 跨学科合作:结合语言学、认知科学等领域的见解
6. 结论
大规模语言模型已经成为NLP领域的核心驱动力,它们不仅改变了我们处理语言任务的方式,也为人工智能的发展开辟了新的可能性。尽管面临诸多挑战,但通过不断的技术创新和跨学科合作,我们有望解决这些问题,进一步推动LLMs的发展。
对于NLP从业者而言,深入理解LLMs的原理、掌握其应用技巧,并积极参与解决相关挑战,将是未来职业发展的关键。同时,我们也需要保持对伦理和社会影响的敏感,确保这一强大技术的负责任使用。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
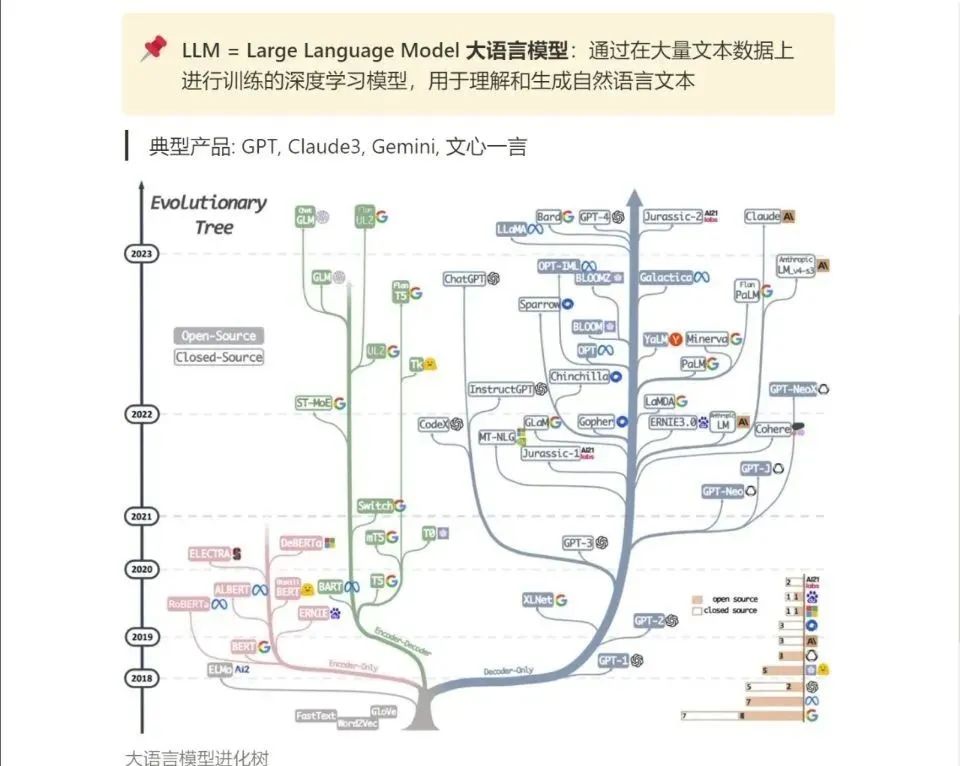
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!















 4876
4876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









