






前言
提到 Transformer,大家就会联想到位置编码、注意力机制、编码器-解码器结构,本系列教程将探索 Transformer 的不同模块在故障诊断等信号分类任务中扮演什么样角色,到底哪些模块起作用?
前言
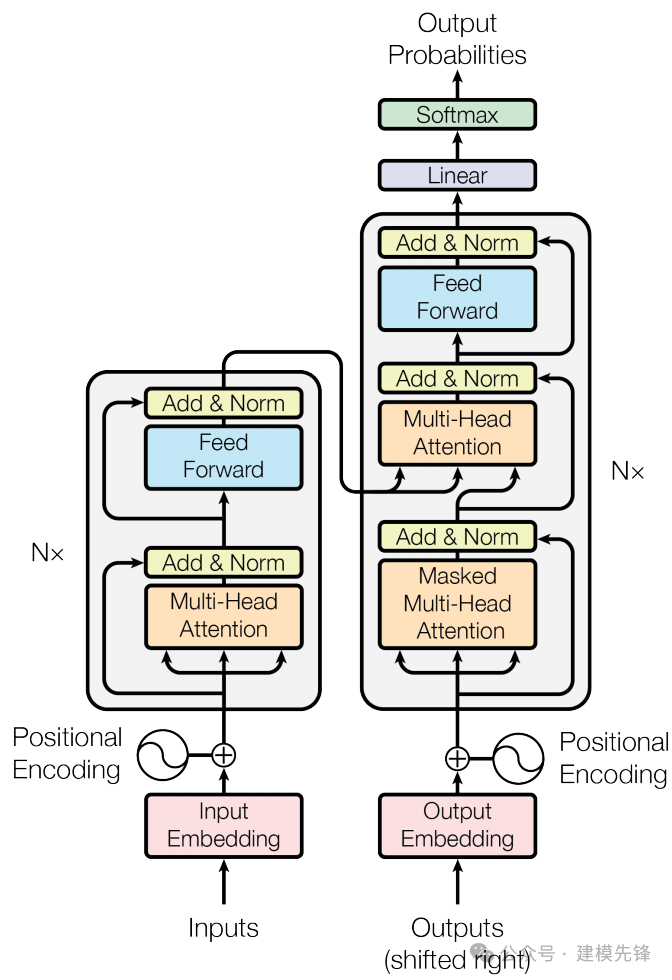
本期基于凯斯西储大学(CWRU)轴承数据,进行 Transformer 中**位置编码 (**Positional Encoding) 的详细介绍,同时探索位置编码对故障分类任务的影响力。
1 位置编码相关介绍
1.1 数据中的顺序信息
在任何一门语言中,词语的位置和顺序对句子意思表达都是至关重要的。传统的循环神经网络(RNN)中,模型是逐词处理输入序列的,每个时刻的输出依赖于前一个时刻的输出。这种逐序处理的方式使得RNN天生适合处理序列数据,因为它能够隐式地保留序列中词语的顺序信息。

由于Transformer模型没有RNN(循环神经网络)或CNN(卷积神经网络)结构,句子中的词语都是同时进入网络进行处理,所以没有明确的关于单词在源句子中位置的相对或绝对的信息。为了让模型理解序列中每个单词的位置(顺序),Transformer论文中提出了使用一种叫做 Positional Encoding(位置编码) 的技术。这种技术通过为每个单词添加一个额外的编码来表示它在序列中的位置,这样模型就能够理解单词在序列中的相对位置。
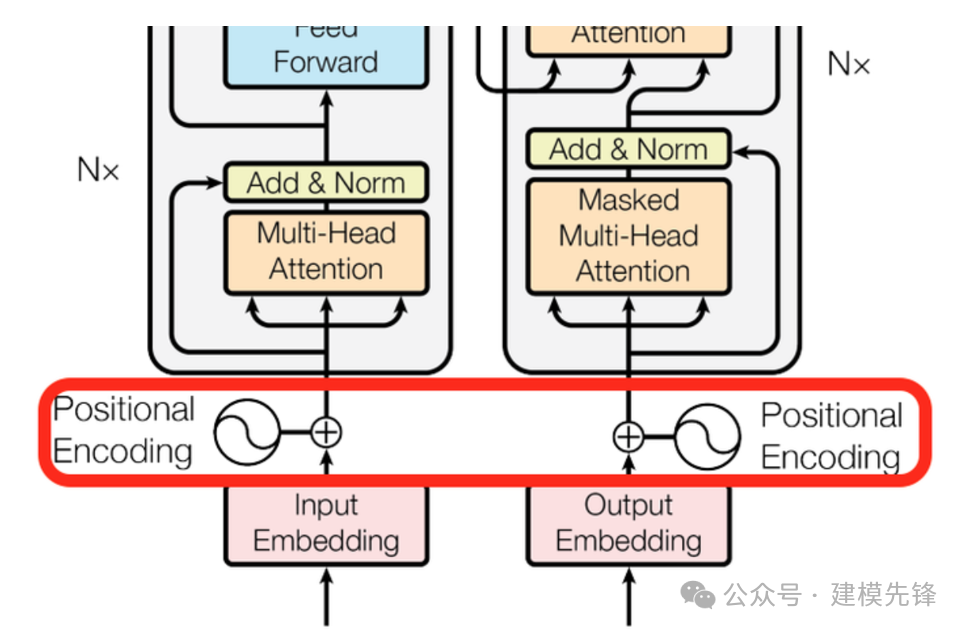
1.2 位置编码的概念
RNN作为特征提取器,是自带词的前后顺序信息的;而Attention机制并没有考虑先后顺序信息,但前后顺序信息对语义影响很大,因此需要通过Positional Embedding这种方式把前后位置信息加在输入的Embedding上。
一句话概括,Positional Encoding就是将位置信息添加(嵌入)到Embedding词向量中,让Transformer保留词向量的位置信息,可以提高模型对序列的理解能力。
1.3 位置编码分类
对于transformer模型的positional encoding有两种主流方式:
(1)绝对位置编码:
Learned Positional Embedding方法是最普遍的绝对位置编码方法,该方法直接对不同的位置随机初始化一个 postion embedding,加到 word embedding 上输入模型,作为参数进行训练。
(2)相对位置编码
使用绝对位置编码,不同位置对应的 positional embedding 固然不同,但是位置1和位置2的距离比位置3和位置10的距离更近,位置1和位置2、位置3和位置4都只相差1,这些体现了相对位置编码。
常用的相对位置编码方法有Sinusoidal Positional Encoding 和 Learned Positional Encoding。其中,Sinusoidal Positional Encoding 是通过将正弦和余弦函数的不同频率应用于输入序列的位置来计算位置编码;Learned Positional Encoding 是通过学习一组可学习参数来计算位置编码。
(3)复杂编码-Complex embedding
在《Attention is all you need》里提到,Learned Positional Embedding和Sinusoidal Position Encoding两种方式的效果没有明显的差别。在论文 《Encoding Word Oder In Complex Embeddings》,实验结果表明使用Complex embedding相较前两种方法有较明显的提升。
1.4 位置向量与词向量
一般来说,可以使用向量拼接或者相加的方式,将位置向量和词向量相结合。相当于做了输入数据和位置信息数据的矩阵叠加!
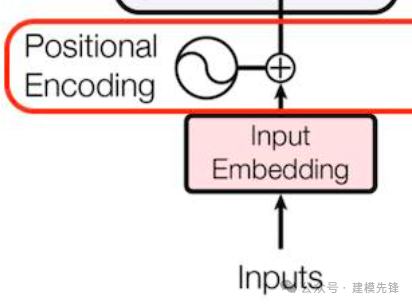
这里,input_embedding 是通过常规Embedding层,将每一个token的向量维度,也就是输入维度,从数据本身的维度映射到 d_model。由于是相加关系,则 positional_encoding 也是一个 d_model 维度的向量。(原论文中,d_model=512)
关于这个 d_model:
在深度学习和Transformer模型的上下文中,d_model中的“d”通常代表“dimension”,即“维度”的简写。因此,d_model指的是模型中向量的维度大小,这是一个关键的参数,d_model 定义了每层的大小、嵌入层的大小、自注意力机制的大小、前馈网络的输入和输出大小。
选择合适的d_model对模型的性能有重大影响。如果d_model太小,模型可能无法捕捉到足够的信息;而如果d_model太大,则会增加计算成本和过拟合的风险。因此,在设计模型时需要仔细考量d_model的大小。

2 位置编码原理
2.1 原理解析
Transformer论文中,使用正余弦函数表示绝对位置,通过两者乘积得到相对位置。因为正余弦函数具有周期性,可以很好地表示序列中单词的相对位置。我们以Sinusoidal Positional Encoding为例,进行讲解。
首先解释下论文中的公式,并给出对应代码,Positional Encoding 的公式如下:

对应代码实现如下:
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
从公式中可以看出,一个词语的位置编码是由不同频率的余弦函数组成的,这样设计的好处是:pos+k 位置的 positional encoding 可以被 pos 线性表示,体现其相对位置关系。虽然 Sinusoidal Position Encoding 看起来很复杂,但是证明 pos+k 可以被 pos 线性表示,只需要用到高中的正弦余弦公式:
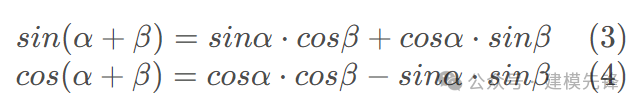
对于 pos+k 的 positional encoding:
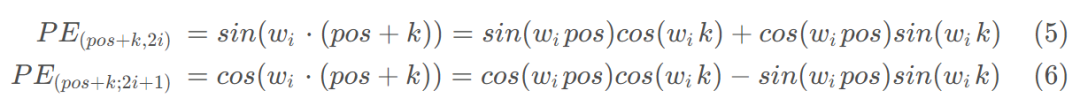
可以看出,对于 pos+k 位置的位置向量某一维 2𝑖 或 2𝑖+1 而言,可以表示为,pos 位置与 k 位置的位置向量的2𝑖 与 2𝑖+1维的线性组合,这样的线性组合意味着位置向量中蕴含了相对位置信息。
2.2 通俗理解
最简单直观的加入位置信息的方式就是使用1,2,3,4,…直接对句子进行位置编码(one-hot)。用二进制转化举个例子:
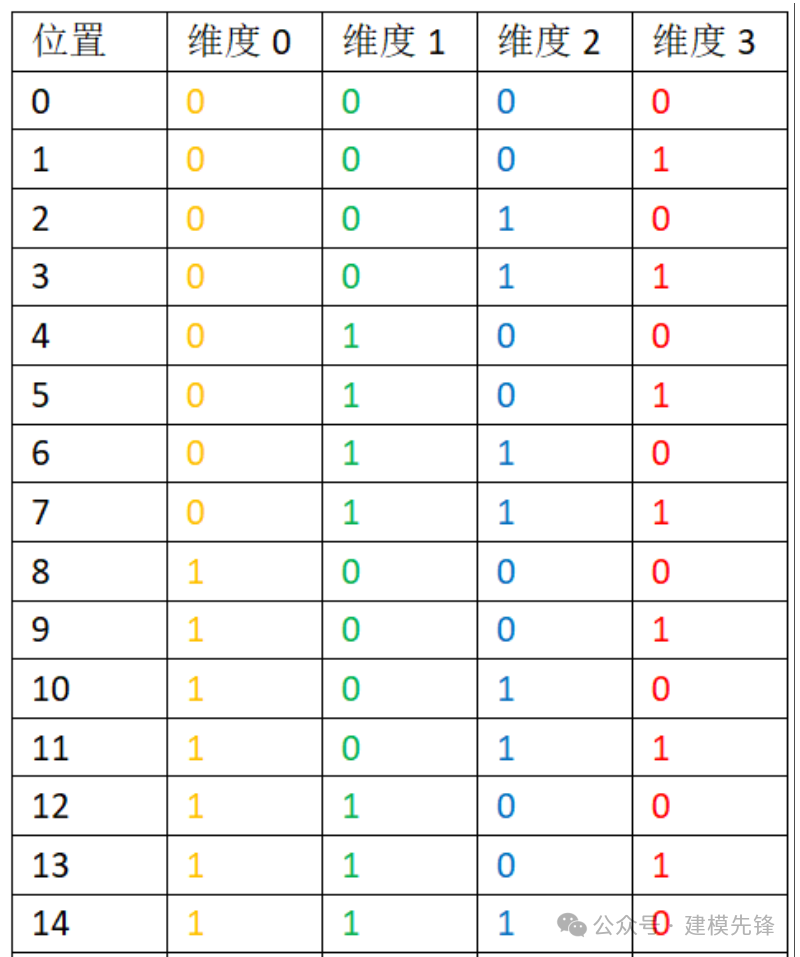
图中维度0,维度1,维度2,维度3拼成的数字就是该位置对应的二进制表示。可以看到每个维度(每一列)其实都是有周期的,并且周期是不同的。具体来说,每个比特位的变化率都是不一样的,越低位的变化越快(越往右边走,变化频率越快),红色位置0和1每个数字会变化一次,而黄色位,每8个数字才会变化一次。这样就能够说明使用多个周期不同的周期函数组成的多维度编码和递增序列编码其实是可以等价的。这也回答了为什么周期函数能够引入位置信息。
最后,我们需要将位置向量与词向量相结合。一般来说,可以使用向量拼接或直接相加的方式将二者结合起来。下面我们结合轴承故障数据进行实验讲解:

3 轴承故障数据的预处理
3.1 导入数据
参考之前的文章,进行故障10分类的预处理,凯斯西储大学轴承数据10分类数据集:
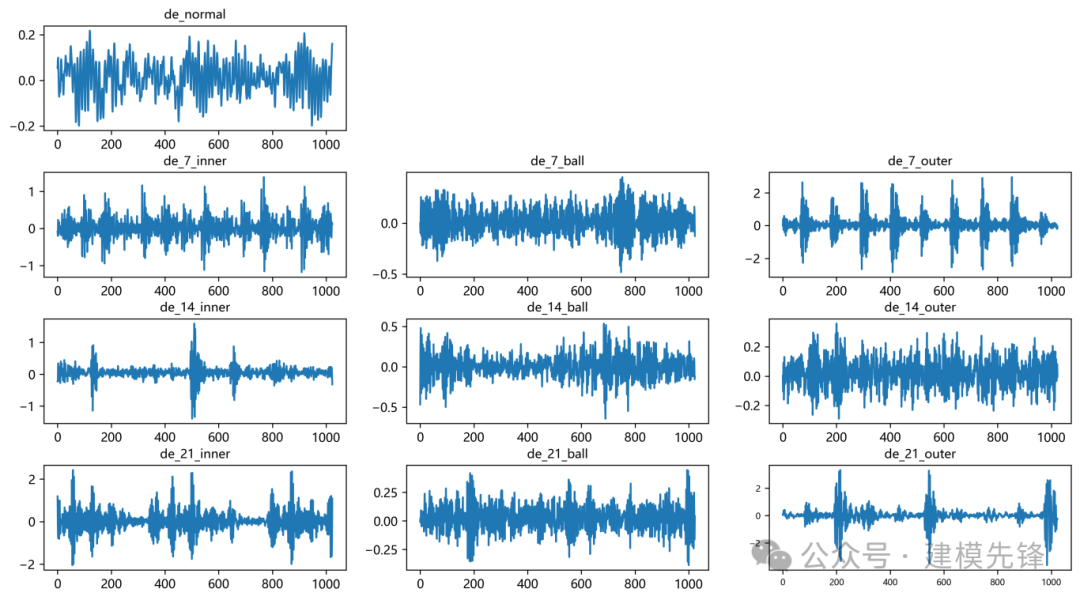
train_set、val_set、test_set 均为按照7:2:1划分训练集、验证集、测试集,最后保存数据
3.2 故障数据预处理与数据集制作

4 加入位置编码和 input_embedding 的实验对比
4.1 定义位置编码PositionalEncoding 和 input_embedding
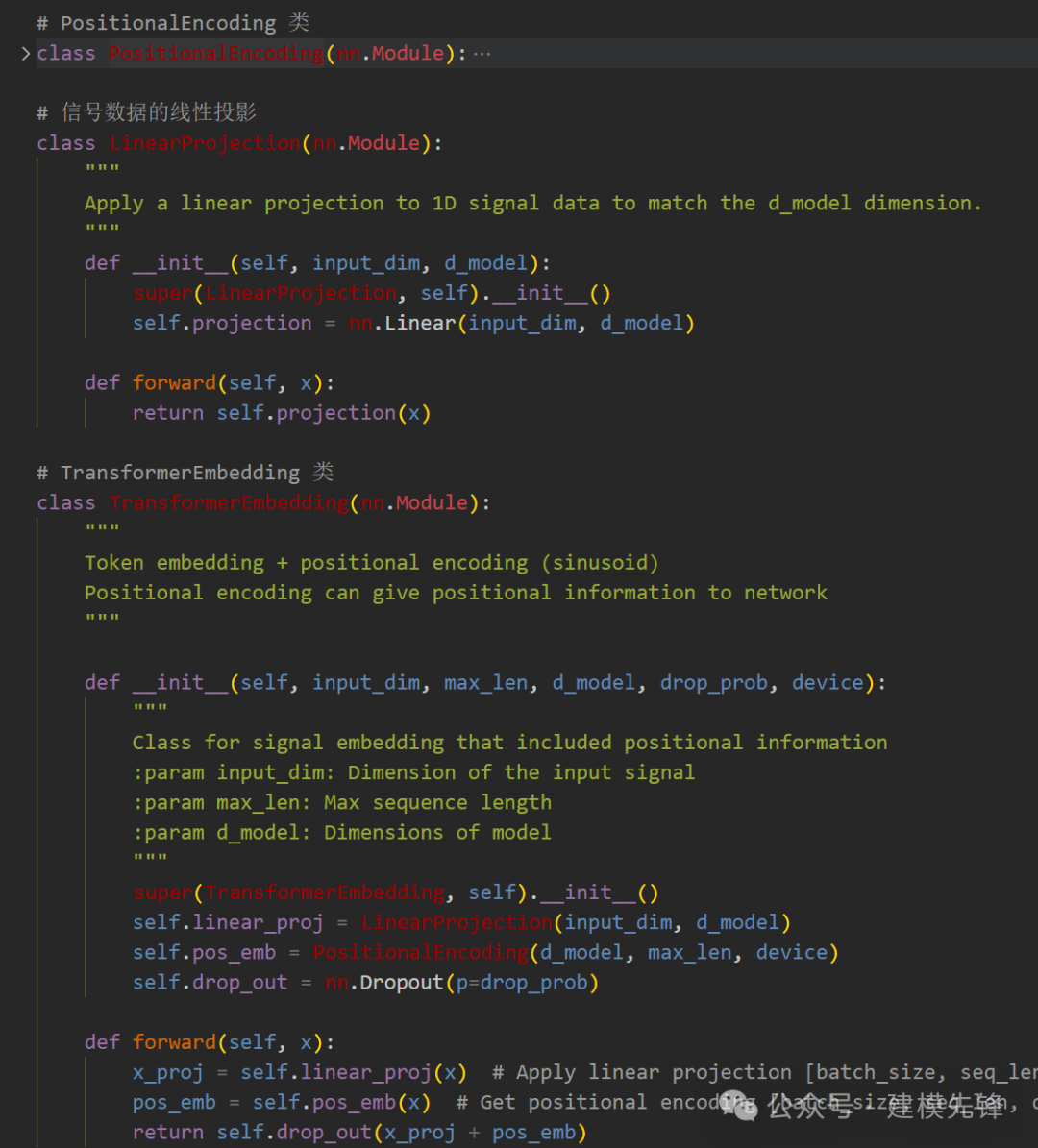
对比模型为:
-
模型 A :Transformer 编码器层
-
模型 B :Transformer 编码器层 + input_embedding -PositionalEncoding
4.2 西储大学十分类数据集实验对比
(1)模型 A:
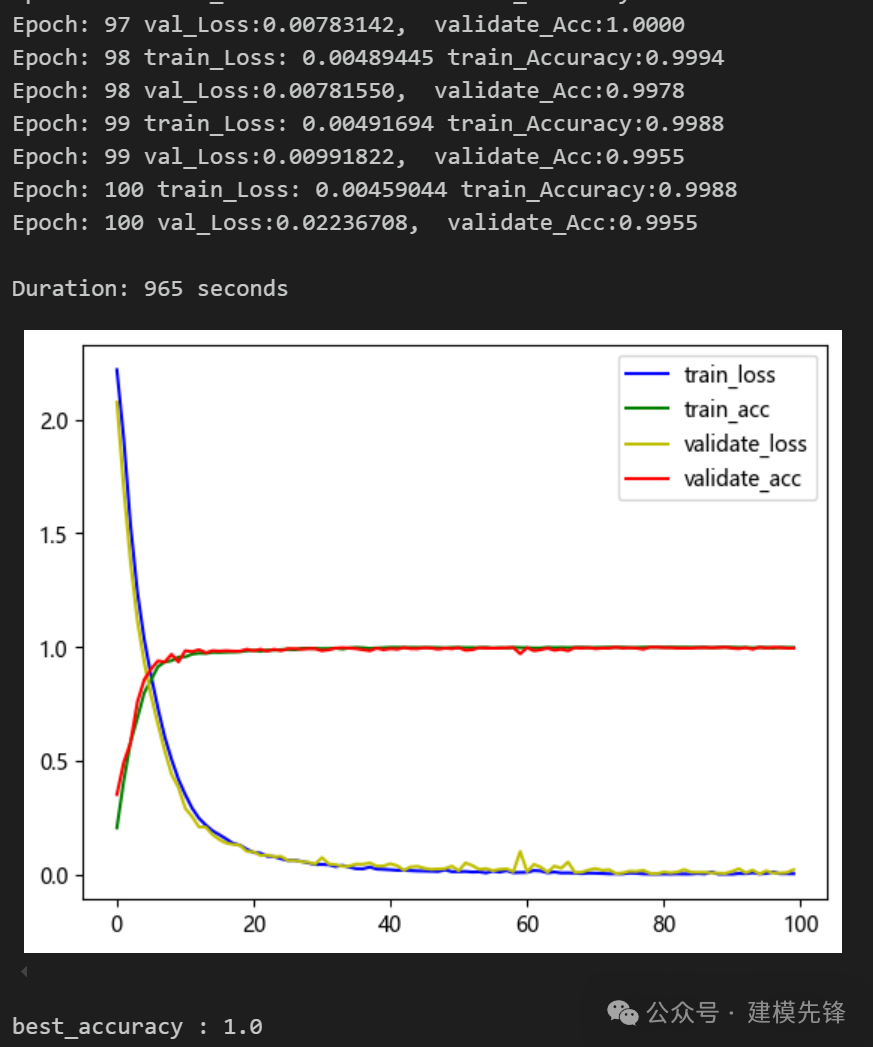
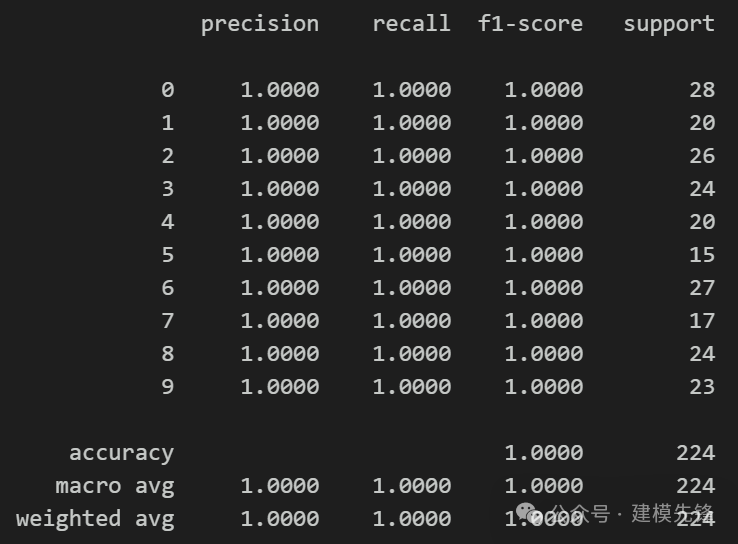
模型评估:
准确率、精确率、召回率、F1 Score
(2)模型 B:
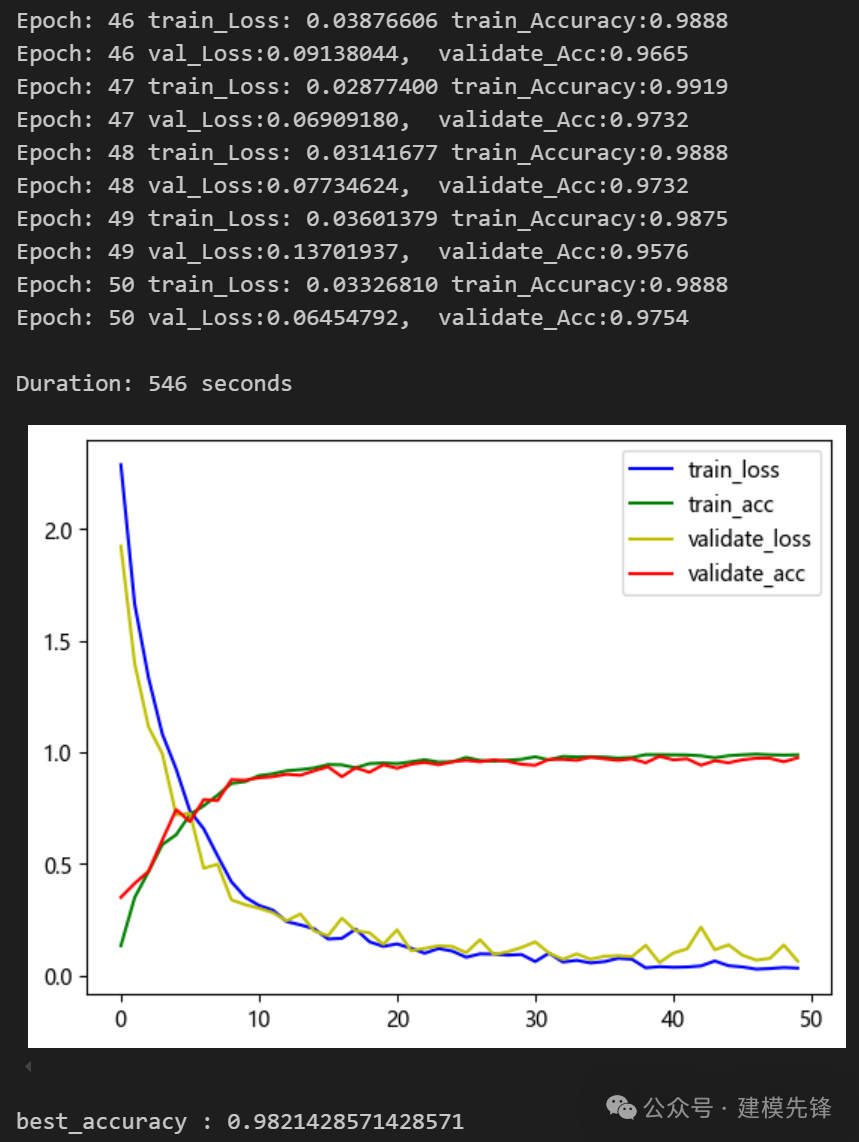
模型评估:
准确率、精确率、召回率、F1 Score
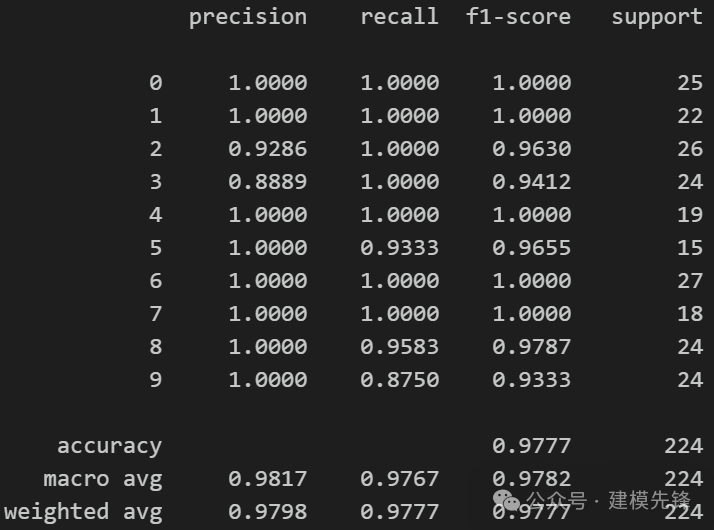
4.3 东南大学齿轮箱轴承故障-五分类数据集实验对比
(1)模型 A:
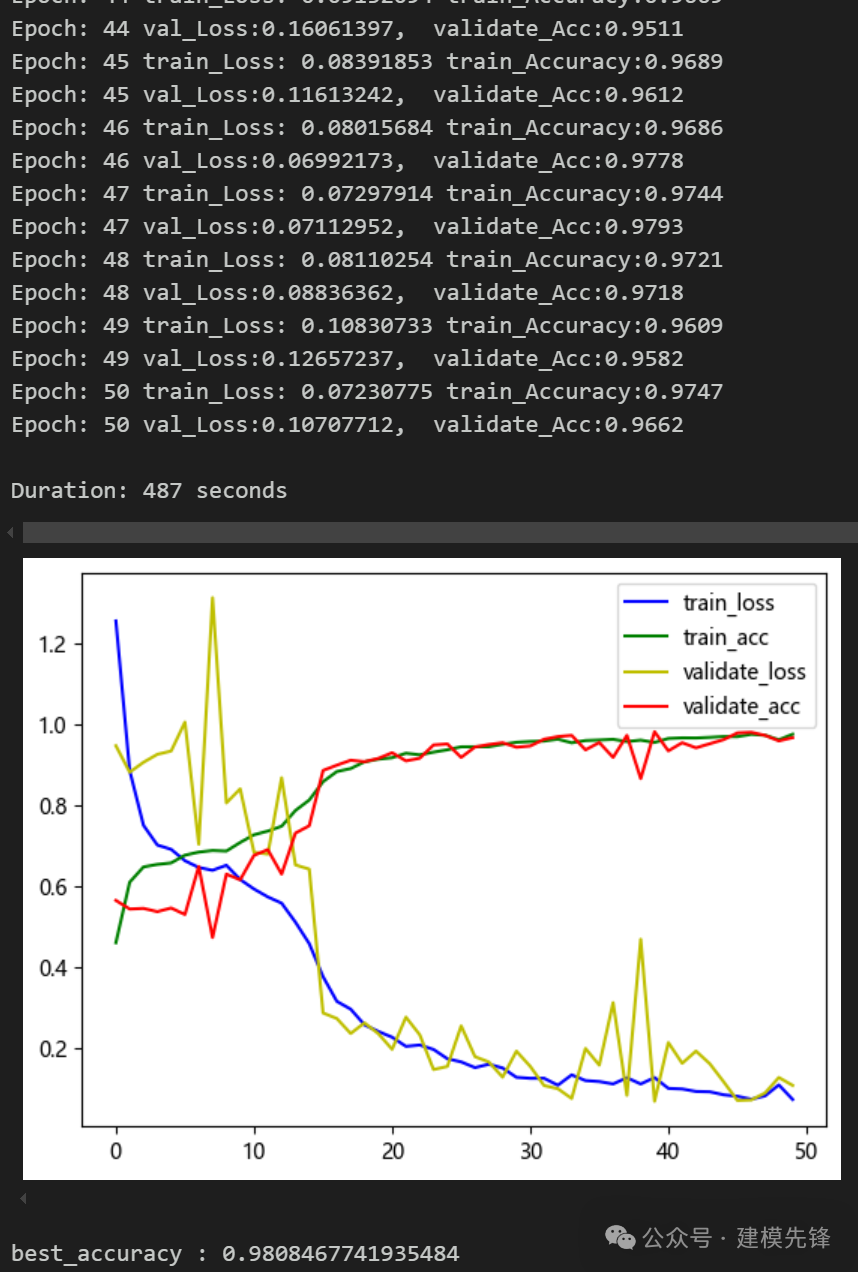
模型评估:
准确率、精确率、召回率、F1 Score
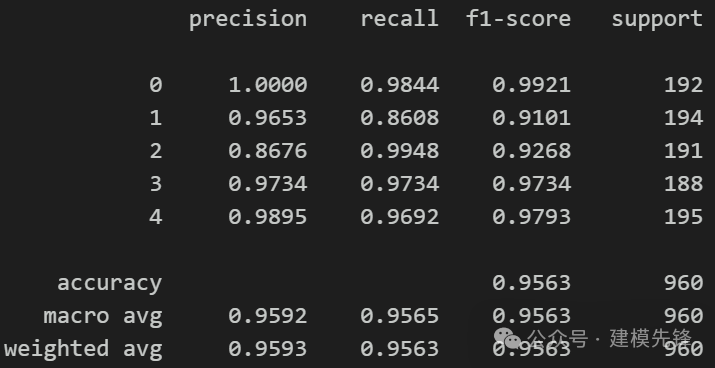
(2)模型 B:

模型评估:
准确率、精确率、召回率、F1 Score


5 实验对比结果分析
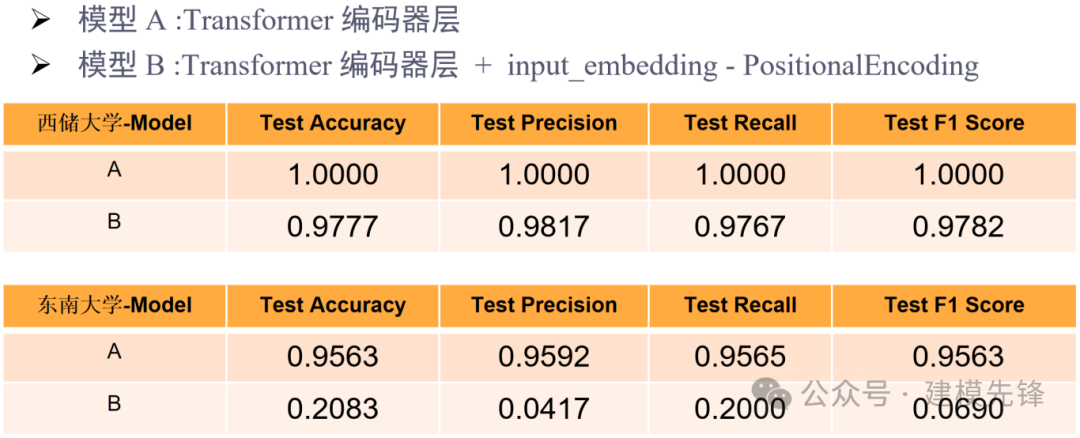
通过两个数据集的对比实验,我们可以发现,仅用Transformer 编码器层在故障信号分类任务上取得了不错的效果,但是加入输入编码和位置编码后,分类效果反而下降了,证明位置编码在故障信号分类任务上作用并不是特别明显!
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









