






前言
随着人工智能技术的飞速发展,大语言模型(Large Language Models, LLMs)正在医疗健康领域掀起一场革命。近日,来自加州大学河滨分校和斯坦福大学的研究人员发表了一篇题为《Large Language Models in Healthcare and Medical Domain: A Review》的综述论文,全面梳理了大语言模型在医疗领域的应用现状、发展趋势以及面临的挑战。本文将深入解读这篇重要综述,为读者呈现大语言模型在改变医疗实践、推动医学研究方面的巨大潜力。
1. 大语言模型简介
大语言模型是一类基于深度学习的自然语言处理模型,通过在海量文本数据上进行预训练,习得了丰富的语言知识和世界知识。代表性的大语言模型包括GPT系列、BERT、T5等。这些模型具有强大的自然语言理解和生成能力,可以执行各种复杂的语言任务。
论文指出,大语言模型的核心优势在于:
-
具备丰富的领域知识,可以理解专业的医学术语和概念
-
具有强大的上下文理解能力,能够捕捉长距离依赖
-
可以进行多轮对话,实现人机交互
-
具有推理能力,可以回答开放性问题
-
可以生成连贯、流畅的自然语言
这些特点使得大语言模型在医疗领域具有广阔的应用前景。
2. 医疗大语言模型的发展历程
论文回顾了医疗大语言模型的发展历程。如图2所示,从2019年到2023年,医疗大语言模型的规模呈现指数级增长。
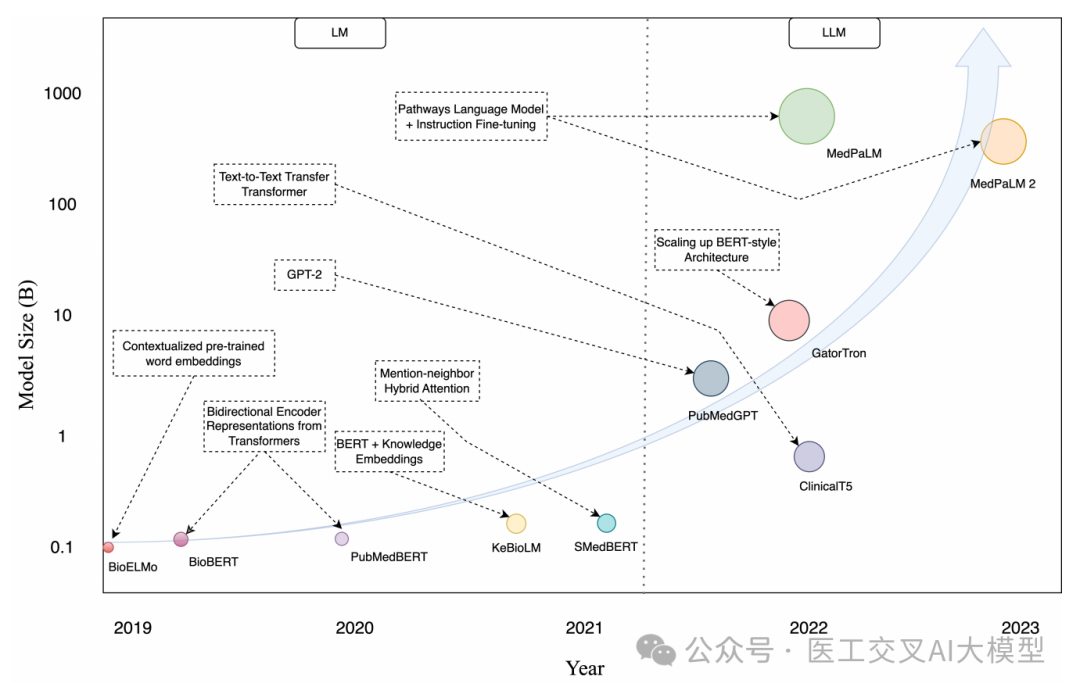
早期的医疗语言模型如BioBERT、ClinicalBERT等,主要是在通用预训练语言模型的基础上,使用医学文献或临床文本进行领域适应。这些模型的参数规模在几亿到几十亿不等。
随着模型架构和训练方法的进步,医疗大语言模型的规模迅速增长。2022年,规模达到百亿参数的BioMedLM和GatorTron相继问世。2023年,谷歌推出的Med-PaLM 2更是达到了数千亿参数的规模。
表1总结了近年来代表性的医疗大语言模型。
| 模型名称 | 年份 | 任务 | 机构 | 开源情况 |
|---|---|---|---|---|
| BioMistral | 2024 | 医学问答 | Avignon Université, Nantes Université | 模型已开源 model(https://huggingface.co/BioMistral/BioMistral-7B,accessed on 8 July 2024) |
| Med-PaLM 2 | 2023 | 医学问答 | Google Research, DeepMind | - |
| Radiology-Llama2 | 2023 | 放射学 | University of Georgia | - |
| DeID-GPT | 2023 | 去识别化 | University of Georgia | 代码已开源 code (https://github.com/yhydhx/ChatGPT-API,accessed on 8 July 2024) |
| Med-HALT | 2023 | 幻觉测试 | Saama AI Research | 代码已开源 code (https://github.com/medhalt/medhalt,accessed on 8 July 2024) |
| ChatCAD | 2023 | 计算机辅助诊断 | ShanghaiTech University | 代码已开源 code (https://github.com/zhaozh10/ChatCAD,accessed on 8 July 2024) |
| BioGPT | 2023 | 分类、关系抽取、问答等 | Microsoft Research | 代码已开源 code (https://github.com/microsoft/BioGPT,accessed on 8 July 2024) |
| GatorTron | 2022 | 语义相似度、自然语言推理、医学问答 | University of Florida | 代码已开源 code (https://github.com/uf-hobi-informatics-lab/GatorTron,accessed on 8 July 2024) |
| BioMedLM | 2022 | 生物医学问答 | Stanford CRFM, MosaicML | 代码已开源 code (https://github.com/stanford-crfm/BioMedLM,accessed on 8 July 2024) |
| BioBART | 2022 | 对话、摘要、实体链接、命名实体识别 | Tsinghua University, International Digital Economy Academy | 代码已开源 code (https://github.com/GanjinZero/BioBART,accessed on 8 July 2024) |
| ClinicalT5 | 2022 | 分类、命名实体识别 | University of Oregon, Baidu Research | 模型已开源 model(https://huggingface.co/xyla/Clinical-T5-Large,accessed on 8 July 2024) |
| KeBioLM | 2021 | 生物医学预训练、命名实体识别、关系抽取 | Tsinghua University, Alibaba Group | 代码已开源 code (https://github.com/GanjinZero/KeBioLM,accessed on 8 July 2024) |
从表中可以看出,近年来医疗大语言模型的研究非常活跃,涉及的任务类型也越来越丰富。值得注意的是,许多模型都选择开源代码或模型,这大大促进了该领域的发展。

3. 医疗大语言模型的应用场景
论文详细介绍了大语言模型在医疗领域的多种应用场景。如图3所示,主要包括以下几个方面:
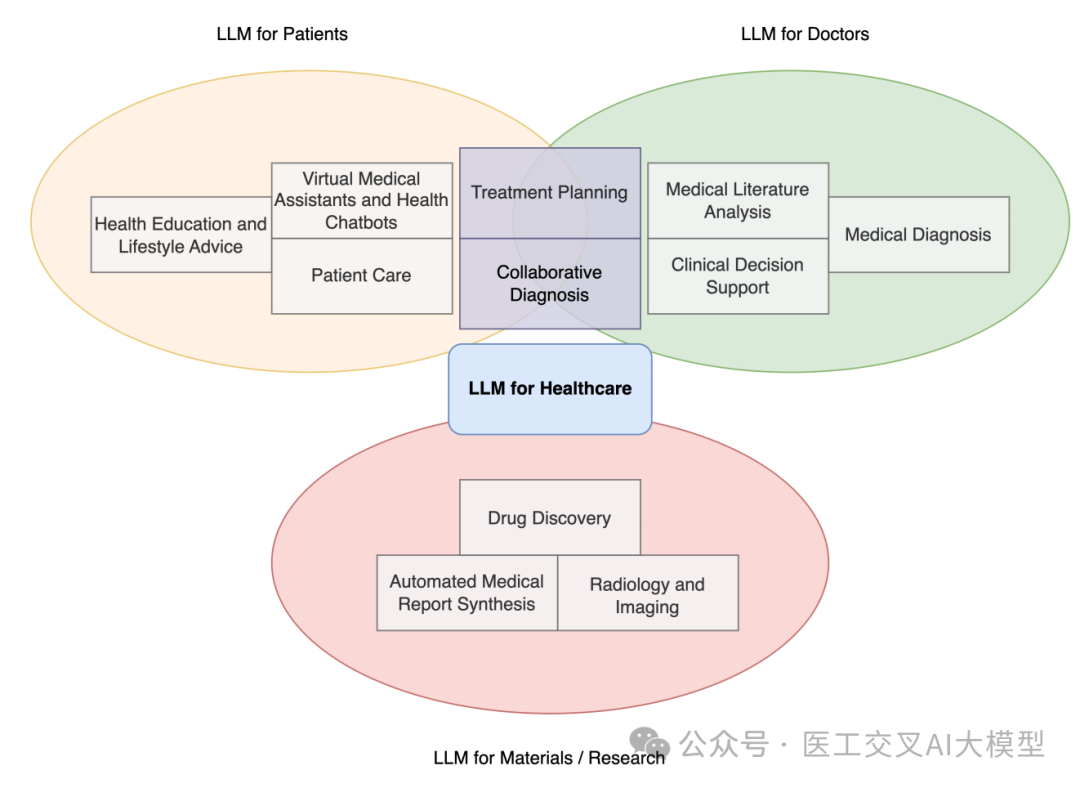
3.1 医疗诊断
大语言模型可以通过分析患者症状、病历和相关数据,协助医生进行疾病诊断。研究表明,基于Transformer的模型在COVID-19诊断、阿尔茨海默病诊断等任务上都取得了不错的效果。例如,一项研究利用BERT、RoBERTa等模型,基于患者对化学感觉变化的文本描述,预测COVID-19诊断,取得了接近人类水平的表现。
3.2 患者护理
大语言模型可以为患者提供个性化的建议、定制化的治疗方案,并持续监测患者的康复进展。这使得医疗服务更加以患者为中心,提高了护理质量。例如,一些研究探索了利用LLMs生成个性化的饮食建议和运动计划。
3.3 临床决策支持
通过分析大量医疗数据,大语言模型可以为医疗专业人员提供循证医学建议,提高诊断准确性和治疗选择的合理性。研究表明,在放射学、肿瘤学和皮肤科等领域,LLMs已经展现出作为决策支持工具的潜力。
3.4 医学文献分析
大语言模型能够高效地阅读和总结大量医学文献,帮助研究人员和临床医生及时了解最新的研究进展和循证医学实践。这在快速发展的医疗领域尤为重要,可以确保医疗实践始终保持在创新和循证护理的前沿。
3.5 药物发现
在药物发现领域,大语言模型可以分析复杂的分子结构,识别具有治疗潜力的化合物,并预测这些候选药物的功效和安全性。一项研究探索了使用预训练的生物化学语言模型来初始化目标分子生成模型,结果表明这种方法在化合物质量评估和基准指标方面表现优异。
3.6 虚拟医疗助手和健康聊天机器人
大语言模型可以作为健康聊天机器人的底层智能,提供持续的、个性化的健康相关支持。这些聊天机器人可以提供医疗建议、监测健康状况,甚至延伸到心理健康支持等领域。
3.7 放射学和影像学
多模态视觉语言模型在增强医学影像分析方面具有巨大潜力。这些模型可以帮助放射科医生更早地识别医学图像中的异常,并生成更准确、全面的诊断解释。
3.8 从影像数据自动生成医疗报告
自动从图像生成医疗报告对于简化病理学家和放射科医生的工作流程至关重要。最新的研究如ChatCAD利用大语言模型显著改进了报告生成质量。ChatCAD+通过引入模板检索系统,进一步解决了写作风格不匹配的问题,确保了生成报告在不同医疗领域的通用性和可靠性。
4. 医疗大语言模型的性能评估
论文详细讨论了评估医疗大语言模型性能的多种指标。表3总结了常用的评估指标。
| 评估指标 | 描述 | 关键亮点 |
|---|---|---|
| Perplexity | 困惑度,量化语言模型预测的不确定性。值越低表示预测准确性和连贯性越高。 | - 联邦学习模型在英语上达到了最佳困惑度3.41 |
| BLEU | 评估机器翻译质量,通过与参考翻译比较。 | - ClinicalGPT模型达到最佳BLEU-1得分13.9 |
| GLEU | 计算各种n-gram的平均得分,评估文本生成质量。 | - Bloom-7B模型达到最佳GLEU得分2.2 |
| ROUGE | 通过测量与参考摘要的重叠来评估摘要和翻译。 | - ClinicalGPT模型达到最佳ROUGE-L得分21.3 |
| Distinct n-grams | 通过计算唯一n-gram来衡量生成响应的多样性。 | - 在Huatuo-26M数据集上,微调后的T5模型达到Distinct-1和Distinct-2分别为0.51和0.68 |
| F1 Score | 平衡精确度和召回率,衡量模型识别正例和最小化误报的准确性。 | - GatorTron-large模型在医学关系抽取任务上达到最佳F1得分0.9627 |
| BERTScore | 使用上下文嵌入计算候选句和参考句之间的token相似度得分。 | - Longformer-Encoder-Decoder (LED_large-PubMed)模型达到最佳BERTScore F1为70.7 |
| Human Evaluation | 由专家人类评估者对模型生成内容的质量进行评分,提供定性见解。 | - 所有人类SCORE用户的中位数表现为65%,而ChatGPT在SCORE多项选择题和Data-B问题上的正确率分别为71%和68% |
这些评估指标从不同角度衡量了模型的性能,包括语言建模能力、生成质量、多样性、准确性等方面。其中,人工评估虽然成本较高,但能提供最直观的质量评价。
5. 医疗大语言模型的性能比较
论文对多个医疗大语言模型在不同数据集上的性能进行了详细比较。图4展示了各模型在MedQA、MedNLI、Tox21和PubMedQA等数据集上的表现。
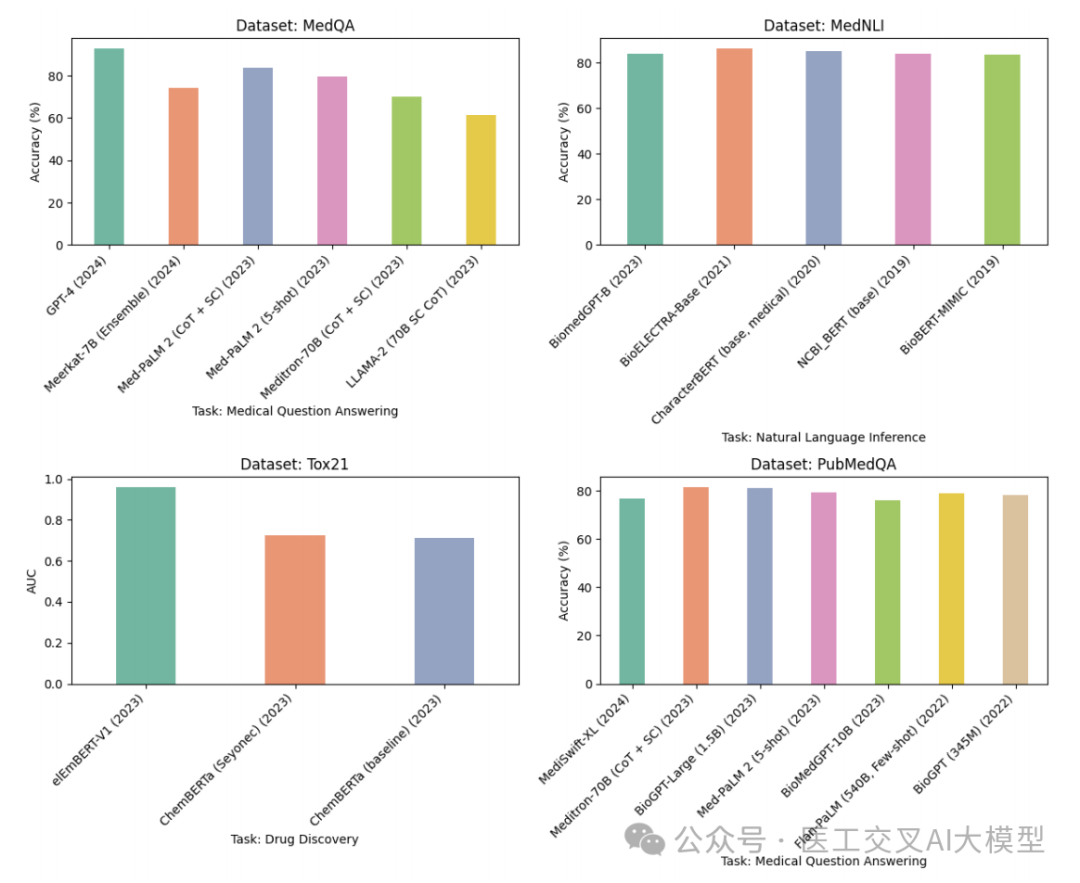
图4:多个医疗大语言模型在MedQA、MedNLI、Tox21和PubMedQA数据集上的性能比较。纵轴表示准确率或AUC值,横轴表示不同的模型。不同颜色的柱状图代表不同的数据集。
从图中可以看出:
-
在MedQA数据集上,GPT-4 (2024)以93.06%的准确率遥遥领先,远超Med-PaLM 2 (CoT + SC) (2023)的83.7%和Meerkat-7B (Ensemble) (2024)的74.3%。
-
在MedNLI数据集上,BioELECTRA-Base (2021)以86.34%的准确率位居榜首,紧随其后的是CharacterBERT (base, medical) (2020),达到84.95%。
-
在Tox21数据集上,elEmBERT-V1 (2023)以0.961的AUC值表现最为出色,在预测化学性质和毒性方面效果显著。
-
在PubMedQA数据集上,Meditron-70B (CoT + SC) (2023)和BioGPT-Large (1.5B) (2023)表现强劲,准确率分别达到81.6%和81.0%。
这些结果表明,不同模型在不同任务上各有优势,选择合适的模型需要根据具体应用场景来决定。值得注意的是,GPT-4在医学问答任务上的出色表现令人瞩目,展现了大规模通用语言模型在医疗领域的强大潜力。
6. 医疗大语言模型面临的挑战与局限性
尽管医疗大语言模型展现出巨大潜力,但在实际应用中仍面临诸多挑战。论文详细讨论了这些挑战,如图5所示。
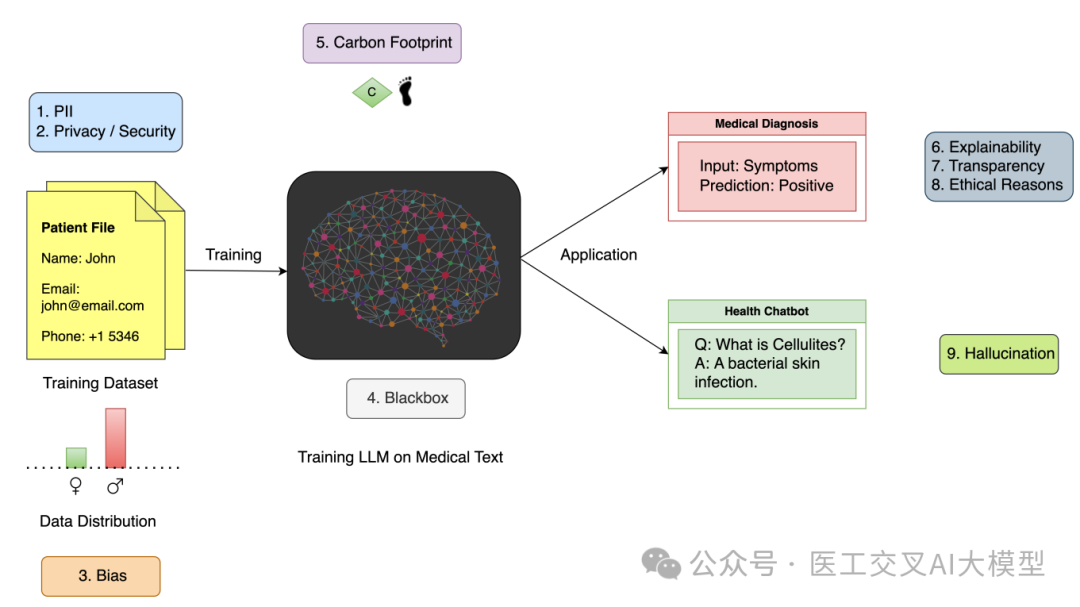
图5:该图总结了大语言模型在医疗领域应用面临的主要挑战,包括模型可解释性和透明度、安全性和隐私考虑、偏见和公平性、幻觉和虚构信息、法律和伦理问题等。
6.1 模型可解释性和透明度
医疗大语言模型的决策过程往往是不透明的,这被称为"黑箱"问题。在医疗领域,决策的后果可能关乎生命,因此理解AI生成输出背后的逻辑至关重要。论文指出,提高模型的可解释性和透明度是医疗AI领域持续面临的挑战。
为了应对这一挑战,研究人员提出了多种可解释AI(eXplainable and Interpretable Artificial Intelligence, XIAI)方法。表2总结了一些代表性的XIAI方法及其在医疗大语言模型中的应用。
| 方法 | 年份 | 任务 | XIAI属性 | XIAI评估指标 |
|---|---|---|---|---|
| MentaLLaMA | 2024 | 心理健康分析 | 基于提示(ChatGPT与任务特定指令) | BART-score, 人工评估 |
| ArgMed-Agents | 2024 | 临床决策推理 | 基于提示(自我论证迭代+符号求解器) | LLM评估器预测准确率 |
| Diagnostic reasoning prompts | 2024 | 医学问答(MedQA) | 基于提示(贝叶斯、鉴别诊断、分析和直觉推理) | 专家评估,评分者间一致性 |
| SkinGEN | 2024 | 皮肤病诊断 | 视觉解释(Stable Diffusion),交互式框架 | 感知可解释性评分 |
| DR. KNOWS | 2023 | 自动诊断生成 | 知识图谱(可解释的诊断路径) | - |
| Human-AI Collaboration | 2023 | 临床决策制定 | 显著特征,反事实解释 | 一致性水平,可用性问卷 |
| ChatGPT | 2023 | 心理健康分析 | 基于提示(情感线索和专家编写的少样本示例) | BART-score, 人工评估 |
| CHiLL | 2023 | 临床预测任务,胸部X光报告分类 | 可解释特征,线性模型 | 专家评估,临床判断一致性 |
| Trap-VQA | 2022 | 病理学视觉问答(PathVQA) | Grad-CAM, SHapley Additive exPlanations | 定性评估 |
| Vision Transformer | 2021 | Covid-19诊断 | 显著性图 | 可视化 |
| ClinicalBERT | 2019 | 预测住院再入院 | 注意力权重 | 可视化 |
这些方法从不同角度提高了模型的可解释性,包括:
-
基于提示的方法:通过设计特定的提示来引导模型生成可解释的输出。
-
可视化方法:如Grad-CAM和显著性图,可以直观地展示模型关注的图像区域。
-
特征重要性分析:如SHAP(SHapley Additive exPlanations),可以量化不同特征对模型决策的贡献。
-
知识图谱:通过构建知识图谱,展示模型推理的路径。
-
反事实解释:通过改变输入来观察模型决策的变化,从而理解决策边界。
尽管这些方法在提高模型可解释性方面取得了进展,但仍存在一些挑战。例如,如何量化可解释性、如何在可解释性和模型性能之间取得平衡等问题仍需进一步研究。
6.2 安全性和隐私考虑
医疗大语言模型的训练和应用涉及大量敏感的患者数据,因此数据安全和隐私保护至关重要。论文指出,主要的安全和隐私挑战包括:
-
训练数据中可能包含个人身份信息(PII),可能导致患者隐私泄露。
-
模型可能通过看似无害的数据推断出敏感的个人属性,侵犯个人隐私。
-
即使在数据匿名化的情况下,LLMs仍可能从大量健康数据中发现潜在的识别模式。
为应对这些挑战,论文建议采取以下措施:
-
实施强大的数据匿名化技术
-
建立安全的数据存储程序
-
严格遵守伦理标准
-
设计能够检测和防止个人重新识别的算法
-
持续监控LLMs的输出,确保不会意外泄露隐私
-
制定前瞻性政策,预anticipate挑战
-
让专家验证LLMs是否符合伦理指南
-
在开发过程中让患者和医疗服务提供者参与,提高透明度并维护对健康数据使用的信任
6.3 偏见和公平性
医疗大语言模型可能会放大训练数据中已存在的偏见,特别是与人口统计、疾病流行率和治疗结果相关的偏见。这可能导致不公平和不平等的医疗结果。
论文强调,解决偏见问题应该是优先事项。具体建议包括:
-
仔细策划和预处理训练数据,减少固有偏见并解决不平等的来源。
-
定期进行审计和评估,识别和纠正模型训练和部署中的偏见。
-
领域专家、伦理学家和数据科学家应该合作制定指南和最佳实践,以确保LLM开发的无偏见性。
6.4 幻觉和虚构信息
"幻觉"是指语言模型生成看似合理但实际上不准确的内容。在医疗场景中,这可能导致严重的后果。论文指出,随着LLMs的不断进步,它们生成越来越令人信服的"幻觉"的能力也在增强。
为了解决这个问题,研究人员提出了Med-HALT基准数据集,专门用于评估医疗LLMs的幻觉现象。Med-HALT包括基于推理和基于记忆的幻觉评估,旨在测试LLMs在医疗领域的问题解决和信息检索能力。
6.5 法律和伦理问题
医疗大语言模型的应用涉及复杂的法律和伦理问题。论文讨论了几个主要的监管框架:
-
欧盟的AI法案:引入了全面的规定,包括人工智能责任指令(AILD),该指令解决了AI相关损害的赔偿问题。
-
美国的健康保险可携带性和责任法案(HIPAA):为患者数据保护设定了严格的标准。
-
欧盟的通用数据保护条例(GDPR):强调数据保护和隐私。
-
医疗器械条例(MDR):确保AI驱动的医疗设备的安全性和有效性。
这些规定对医疗AI的部署产生了重大影响,包括:
-
要求详细记录AI模型
-
需要先进的数据加密
-
严格的访问控制
-
严格的临床测试
虽然这些规定增加了开发成本和时间,但它们也促进了AI技术在医疗领域的可靠性、法律责任和道德标准,从而增强了用户和利益相关者的信任。
7. 未来展望
论文对医疗大语言模型的未来发展做出了展望:
-
增强对生物分子数据的解释和生成能力,这将显著推进基因组学和个性化医疗的发展。
-
引入实时自适应学习能力,使LLMs能够在手术或紧急情况中实时分析医疗设备数据,提供关键的决策支持。
-
开发联邦学习系统,实现医疗机构间安全、隐私保护的知识传播,提高模型的鲁棒性和适用性。
-
进一步推进可解释医疗AI的研究,特别是在结合传感器数据的多模态模型方面。
-
将LLMs与可穿戴技术结合,开发非临床环境下的连续健康监测系统。
-
通过分析和解释多模态数据,深入理解患者健康状况,为精准靶向治疗提供支持。
-
优化LLMs在电子健康记录系统中的应用,提高诊断准确性和个性化治疗方案的生成。
-
在临床试验、药物发现等领域推广生成式AI技术的应用。
-
改进自然语言处理和理解能力,提升医学影像分析水平,支持患者护理中的虚拟助手。
-
加强LLMs在疾病检测和筛查、医疗对话任务、语音生成、视频生成以及医疗环境中的图像合成和操作等方面的应用。
8. 结论
本文深入解读了《Large Language Models in Healthcare and Medical Domain: A Review》这篇重要综述,全面介绍了大语言模型在医疗领域的应用现状、发展趋势以及面临的挑战。
大语言模型在医疗诊断、患者护理、临床决策支持、医学文献分析、药物发现等多个方面展现出巨大潜力。它们可以提高诊断准确性、个性化治疗方案,优化医疗流程效率。然而,这些模型在实际应用中仍面临可解释性、数据安全、偏见、幻觉以及法律伦理等多方面的挑战。
未来,医疗大语言模型的发展将朝着多模态、实时自适应、联邦学习、可解释AI等方向不断推进。这些进展有望进一步提升医疗服务的效率、准确性和个性化水平。
尽管挑战重重,但大语言模型在医疗领域的应用前景依然广阔。通过跨学科合作,不断完善技术,加强伦理和监管,相信大语言模型将为医疗健康事业的发展做出重要贡献,最终造福广大患者。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1977
1977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









