






神经网络语言模型
神经网络语言模型(Neural Network Language Model, NNLM)是一种利用神经网络架构来预测文本序列中下一个词的语言模型。NNLM通过学习大量文本数据中的词汇之间的概率关系,能够捕捉到语言的结构和语境,从而生成连贯且符合上下文的文本。
本文旨在结合经典论文 《A Neural Probabilistic Language Model》 的内容,详细解析NNLM的基本原理、网络架构及模型训练。

一种神经概率语言模型
一、NNLM的基本原理
Yoshua Bengio及其团队在2003年的论文《A Neural Probabilistic Language Model》中首次展示了如何使用神经网络(特别是多层感知器MLP)来构建语言模型,这一工作不仅为后续的深度学习在NLP中的应用奠定了基石,还意外地催生了词嵌入(word embedding)这一重要概念。
NNLM的核心思想:利用神经网络来建模自然语言中的词语序列,从而预测给定上下文条件下下一个词出现的概率。与传统的n-gram模型相比,NNLM能够捕捉更长的上下文依赖关系,并且通过词嵌入技术将词语映射到连续的向量空间中,使得相似的词语在向量空间中具有相近的表示。
NNLM开山之作
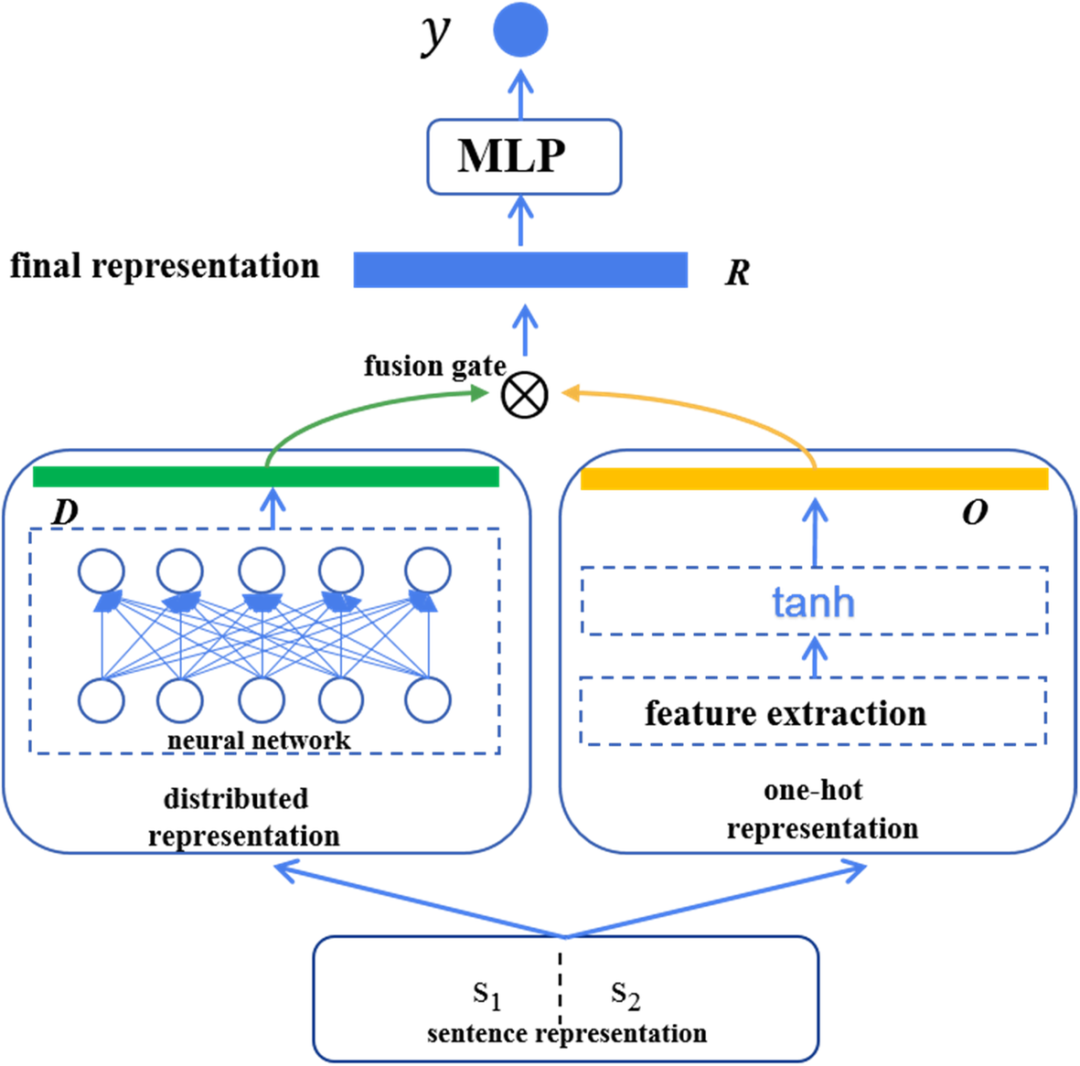
NNLM中的Distributed Representation(分布式表示) 是Embedding(嵌入)最早的理论支撑之一,它代表了一种将单词或文本表示为连续向量空间的技术。 这种表示方法相比传统的独热编码(One-Hot Encoding)具有显著的优势, 能够捕捉到单词之间的语义关系。
-
减少维度灾难:传统的独热编码方式在词汇表很大时会导致向量维度极高,而分布式表示则通过低维向量表示单词,大大减少了计算复杂度。
-
捕捉语义信息:分布式表示能够捕捉到单词之间的语义相似性,使得在向量空间中相似的单词具有相近的表示,这对于处理NLP任务至关重要。
-
提高模型泛化能力:由于分布式表示能够捕捉到单词之间的语义关系,因此模型在处理未见过的单词或句子时具有更好的泛化能力。
distributed representation vs one-hot representation
二、NNLM的网络架构
NNLM的目标: NNLM是一个用于语言建模的神经模型, 该模型旨在学习一个函数f,该函数可以根据给定的前置词汇预测序列中的下一个词汇。
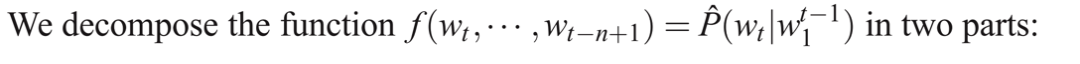
函数f
模型 f 分解为两个主要部分:词嵌入层(C)和概率函数(g)。 词嵌入层将词汇转换为向量表示,而概率函数则利用这些向量预测文本序列中下一个词汇的概率分布。
-
词嵌入层(C):将词汇表中的每个词汇转换成一个实值向量。 这些向量代表了词汇的分布式特征,即它们不仅仅表示词汇本身,还包含了词汇在不同上下文中的语义信息。
-
概率函数(g):
根据给定的上下文信息来预测下一个词汇出现的概率。 由多个词汇组成的上下文(比如前面的n-1个词汇),概率函数g会利用这些词汇的向量表示(即词嵌入层输出的向量)来估计下一个词汇出现的概率分布。
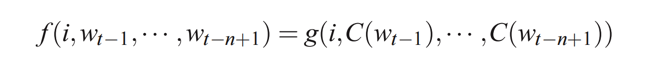
词嵌入层(C)和概率函数(g)
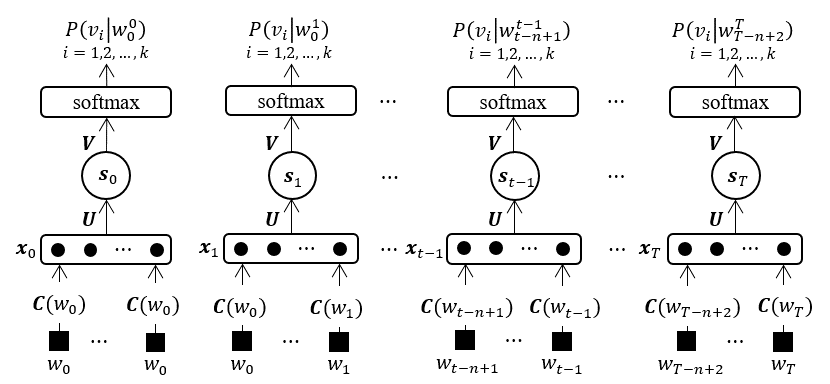
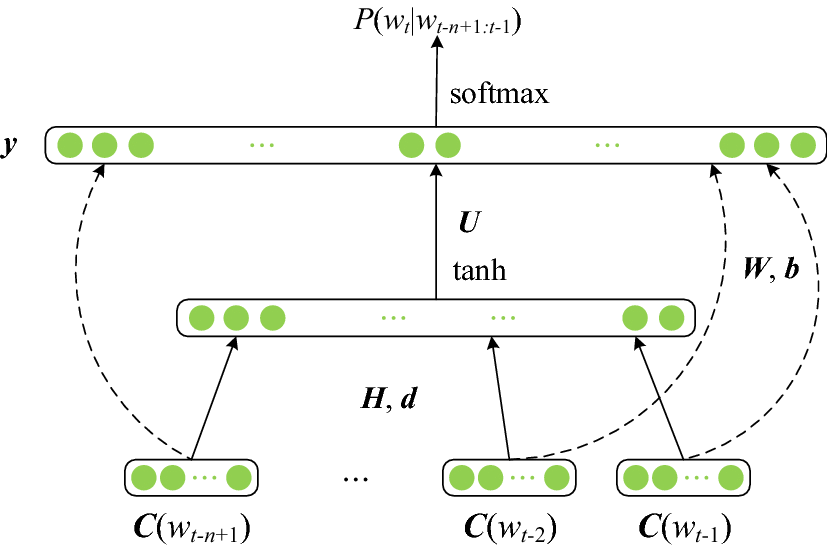
NNLM的网络架构:根据《A Neural Probabilistic Language Model》中的描述,NNLM主要由输入层、隐藏层及输出层三部分组成。 通过输入层接收前文单词序列的向量表示,在隐藏层中捕捉复杂的语言结构,最后在输出层输出每个单词作为下一个词出现的概率分布。

NNLM的网络架构
一、输入层
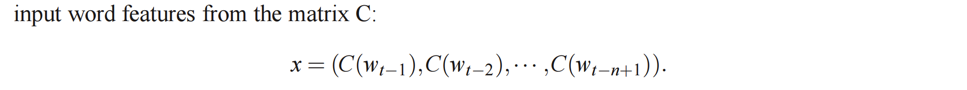
输入层
-
作用:输入层负责接收原始数据,并将其转换为神经网络可以处理的格式。在自然语言处理中,输入层通常接收的是词汇的向量表示,即词嵌入(word embedding)。
-
上下文词汇向量:如上文所述,输入层连接的是上下文词汇向量
x = (C(wt-1), C(wt-2), …, C(wt-n+1)),其中C(wt-i)表示在时间步t-i时词汇wt-i的词嵌入向量。这些向量共同构成了神经网络的输入。
二、隐藏层
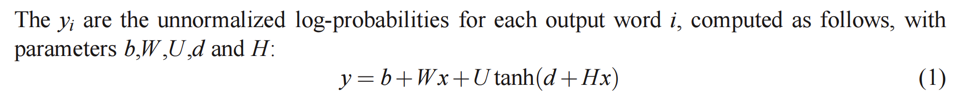
隐藏层
-
作用:隐藏层是神经网络中的核心部分,负责学习数据的复杂特征表示。在自然语言处理中,隐藏层通常包含多个神经元,并且这些神经元之间以及与前一层和下一层之间都有连接。
-
非线性激活函数:为了引入非线性,隐藏层中的神经元通常使用非线性激活函数,如双曲正切函数(tanh)。激活函数使得神经网络能够学习非线性关系,从而捕捉数据的复杂模式。
-
权重和偏置:隐藏层中的每个神经元都与其前一层的神经元通过权重矩阵U和H(以及偏置向量d)相连接。这些权重和偏置在训练过程中被学习,以最小化预测误差。
三、输出层

输出层
-
作用:输出层是神经网络的最后一层,负责产生最终的预测结果。在自然语言处理中,输出层通常使用softmax函数将隐藏层的输出转换为概率分布,以便在每个时间步预测下一个词汇。
-
softmax函数:softmax函数将隐藏层的输出转换为概率分布
P^(wt | wt-1, …, wt-n+1)。这个概率分布表示在给定上下文条件下,每个词汇作为下一个词汇的概率。 -
预测:最终,神经网络通过选择概率最高的词汇作为预测结果。
NNLM的网络架构
三、NNLM的模型训练
NNLM的模型训练:NNLM的训练过程旨在最大化训练数据中序列的联合概率,即最大化给定前文单词的条件下,下一个单词出现的概率。在训练过程中,分布式表示(即词嵌入)是作为模型的训练参数之一进行更新的。
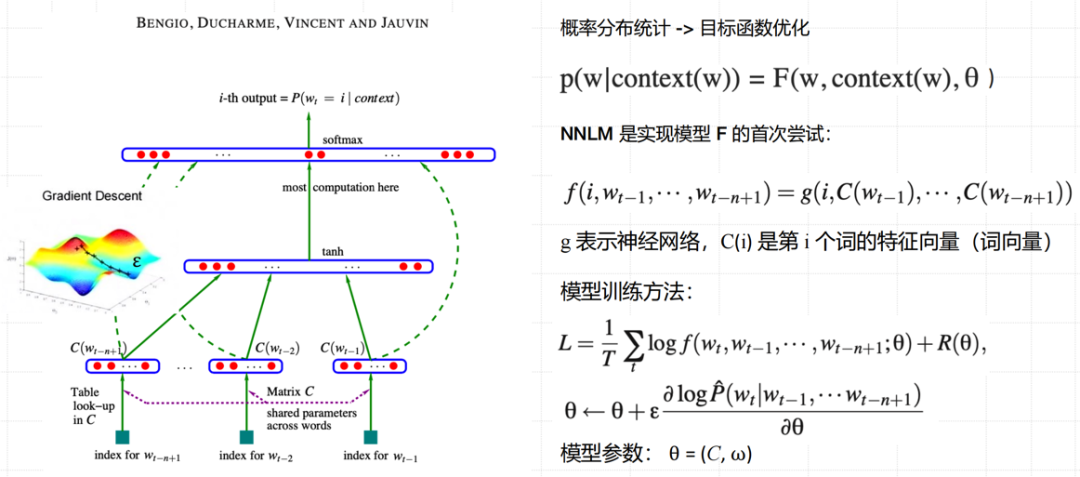
NNLM
NNLM训练过程: 通过前向传播计算输出,利用损失函数评估差异,然后反向传播更新权重,迭代优化直至收敛或达到预设迭代次数。 这通常通过 最小化负对数似然(negative log-likelihood)损失函数 来实现。
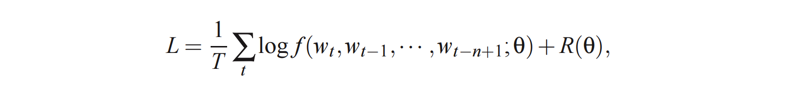
最小化负对数似然
其中 R( θ) 是正则化项(例如,权重衰减),使用随机梯度上升法更新参数 θ:

更新参数 θ
其中 ϵ 是学习率。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









