






前言
在人工智能和深度学习领域,自注意力机制(Self-Attention)无疑是近年来最引人注目的技术之一。它彻底改变了我们处理序列数据的方式,为自然语言处理、计算机视觉等多个领域带来了突破性进展。它是一种创新性的技术,能够让模型更好地理解序列中的信息,并做出更准确的预测和决策。本篇我将用通俗易懂的方式为各位同学介绍一下Self-Attention。
01、什么是Self-Attention
在你阅读一本书的时候,当你读到某个句子时,你的大脑会自动关注句子中的关键词,并将这些关键词与前面提到的信息联系起来,从而理解整个句子的含义。自注意力机制就是模仿这种人类阅读理解过程的一种算法。
简单来说,自注意力机制允许模型在处理序列数据(如句子)时,自动找出序列中各个元素之间的关联。它能够让模型在处理某个位置的信息时,同时考虑到整个序列中的其他相关信息,而不仅仅是附近的信息。
02、作用
自注意力机制的主要作用是让模型能够聚焦于序列中的重要信息,并忽略无关的噪声。它通过计算序列中每个元素与其他元素之间的相似度,来分配不同的权重,从而实现对序列的精细化处理。这种机制使得模型能够捕捉长距离依赖关系,并理解序列中的语义和上下文。
在自然语言处理中,自注意力机制可以帮助模型更好地理解句子中的词语之间的关系,从而提高文本分析和生成任务的性能。在计算机视觉中,它可以用于捕捉图像中的对象之间的关联,从而增强目标检测和图像分类的准确性。
Self-Attention的作用主要有仨:
1. 捕捉长距离依赖关系
在处理长序列时,自注意力机制可以直接计算任意两个位置之间的关联,轻松处理长距离依赖。
2. 并行计算
自注意力可以并行计算整个序列,大大提高了计算效率。
3. 提供可解释性
自注意力机制可以生成注意力权重,显示模型在做决策时关注的是哪些部分,增加了模型的可解释性。
03、原理
让我们通过一个简单的例子来理解自注意力的工作原理。
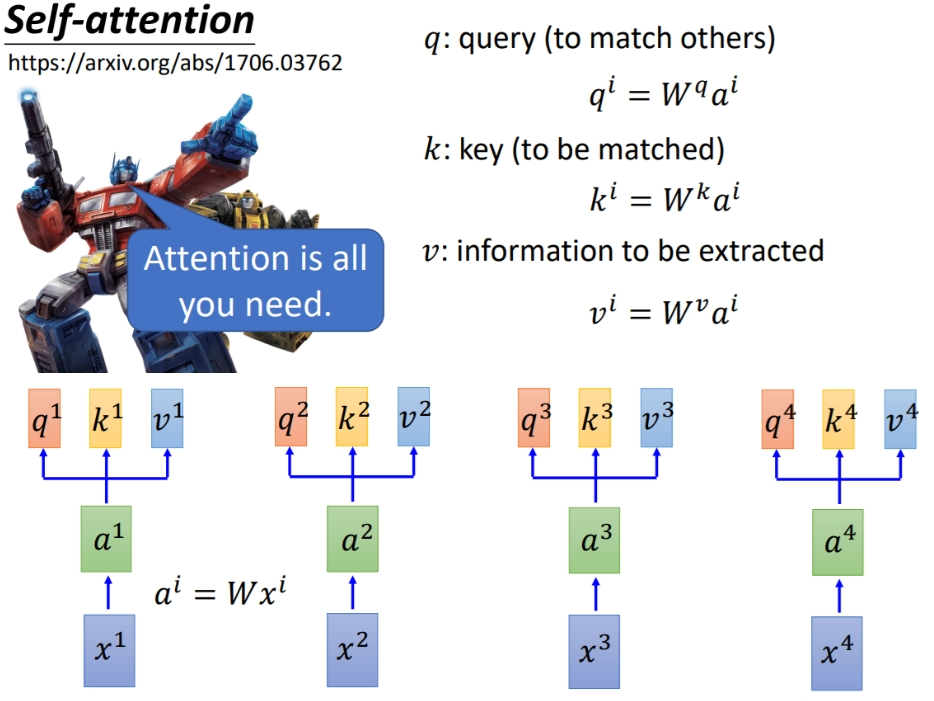
- 用一个句子:“小明喜欢吃苹果”,通过以下过程进行换算:
1:生成查询(Query)、键(Key)和值(Value)向量
对句子中的每个词,我们都会生成三个向量:查询向量(Q)、键向量(K)和值向量(V)。这些向量是通过对输入进行线性变换得到的。
2:计算注意力分数
对于句子中的每个词,我们用它的查询向量与所有词(包括它自己)的键向量做点积,得到注意力分数。例如,对于"小明"这个词:
-
"小明"对"小明"的注意力分数 = Q小明 · K小明
-
"小明"对"喜欢"的注意力分数 = Q小明 · K喜欢
-
"小明"对"吃"的注意力分数 = Q小明 · K吃
-
"小明"对"苹果"的注意力分数 = Q小明 · K苹果
3:softmax归一化
将上述得到的分数通过softmax函数进行归一化,得到注意力权重。这样确保了所有权重之和为1。

4:加权求和
用上述求出的注意力权重与对应的值向量相乘,然后求和,得到该位置的输出。
对于"小明",输出为:
Output小明 = (权重小明 * V小明) + (权重喜欢 * V喜欢) + (权重吃 * V吃) + (权重苹果 * V苹果)
这个过程对句子中的每个词都重复一遍之后,就会形成一个算术矩阵,为大模型使用这些数据提供了支持。
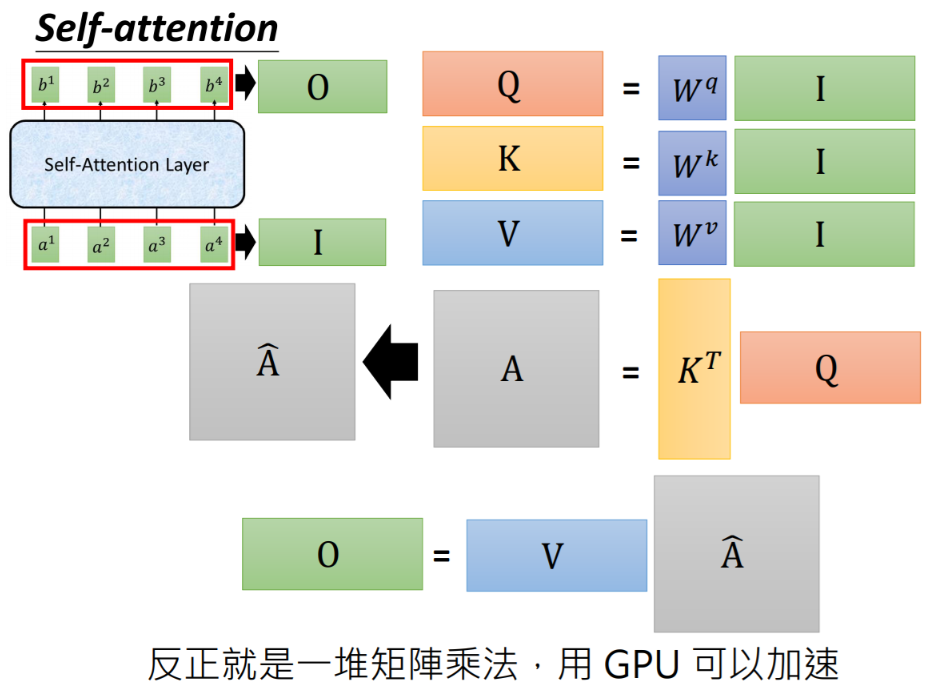
04、更直观地理解
让我们用更直观的方式来理解这个过程:
1. 相关性计算
查询向量(Q)就像是一个问题,键向量(K)像是可能的答案。当我们用Q点乘K时,我们实际上是在问:“这个词与当前词有多相关?”
2. 信息提取
值向量(V)包含了词的实际信息。通过对V进行加权平均,我们就是在根据相关性提取有用的信息。
3. 全局视角
因为每个词都会和所有词计算注意力,所以模型能够获得全局视角,了解整个句子的上下文。
看到这里感觉如何?各位体会到自注意力的魅力了吗?它比起传统的循环神经网络(RNN)是不是有种脱胎换骨的感觉。
05、实际应用
1. 机器翻译
在翻译"The animal didn’t cross the street because it was too tired"这句话时,传统模型可能难以确定"it"指代的是什么。但使用自注意力,模型可以直接建立"it"和"animal"之间的联系,从而正确理解和翻译这个代词。
2. 情感分析
在分析"这部电影情节还行,但是演员的表演really糟糕"这句话的情感时,自注意力可以捕捉到"really"和"糟糕"之间的强关联,从而正确判断整体情感倾向。
3. 文本摘要
在生成文章摘要时,自注意力可以帮助模型关注文章中的关键信息,忽略次要细节,从而生成准确简洁的摘要。
06、总结
自注意力机制是一种强大的序列建模技术,它通过计算元素之间的相似度,让模型能够聚焦于重要的信息,并忽略无关的噪声。这种机制在自然语言处理、计算机视觉、语音处理等领域都有着广泛的应用和显著效果。它为序列数据的处理提供了新的思路和方法,使得模型能够更好地理解和利用序列中的信息,从而推动人工智能技术的进步和发展。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









