






在机器学习和自然语言处理的快速发展中,大型语言模型是处理各种任务的非常有用的工具。其中一项引起人们极大兴趣的任务是对文档进行问答,其中 LLM 用于根据 PDF、网页或公司内部文件等文档的内容提供准确的回答。这篇博文将深入探讨使用 LLM 对文档进行问答的迷人世界,探索嵌入和向量存储等关键概念。我们还将逐步完成整个过程,并向您介绍LangChain库,该库简化了这些技术的实现。
一、文档问答
想象一下,你拥有一个虚拟助手,可以根据文档立即回答您的问题,这就是使用 LLM 对文档进行问答的实用性:
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain.chains.retrieval_qa.base import RetrievalQA
from langchain.vectorstores.docarray import DocArrayInMemorySearch
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_openai import ChatOpenAI
from IPython.display import display, Markdown
from langchain.indexes import VectorstoreIndexCreator
1.使用 LLM 根据文档回答问题
LLM 是在海量数据集上训练的,但如果你需要他们根据他们以前从未见过的文档来回答问题怎么办?这就是奇迹发生的地方。通过将 LLM 与外部数据源相结合,您可以使它们更加灵活并适应您的特定用例。
from langchain_openai import OpenAI
llm_replacement_model = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct")
path = "OutdoorClothingCatalog_1000.csv"
loader = CSVLoader(file_path=path)
index = VectorstoreIndexCreator(vectorstore_cls=DocArrayInMemorySearch).from_loaders([loader])
query = "Please list all your shirts with sun protection in a table in markdown and summarize each one."
response = index.query(query, llm=llm_replacement_model)
display(Markdown(response))
# Output
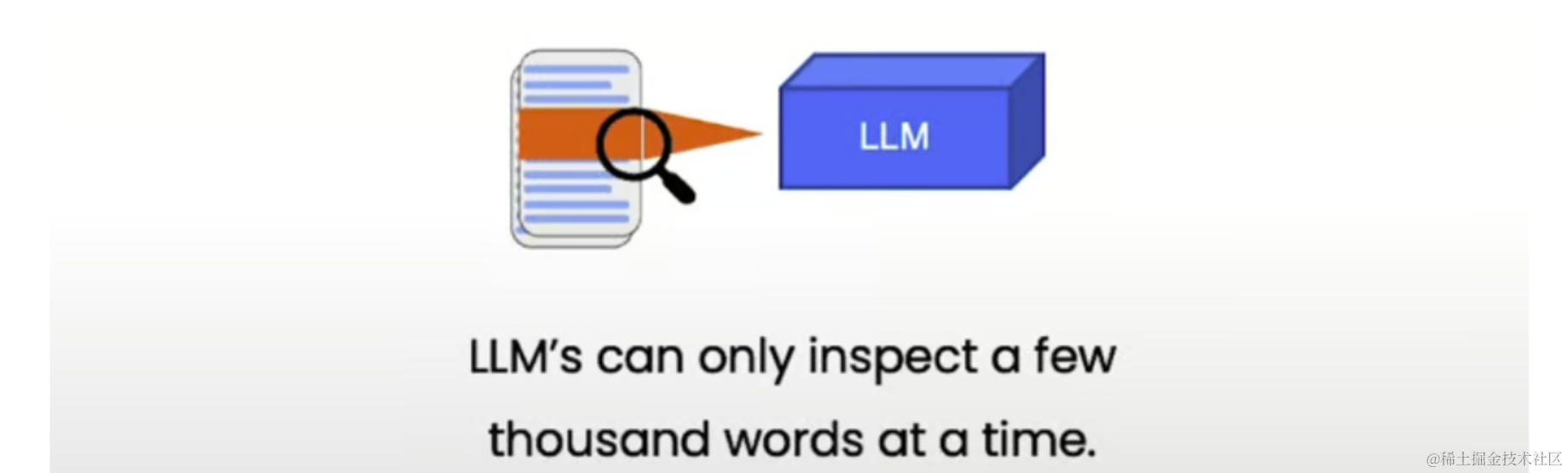
2.嵌入
嵌入是文本的数字表示形式,用于捕获其语义含义。相似的文本将具有相似的嵌入,使我们能够在向量空间中比较和查找相关文档。
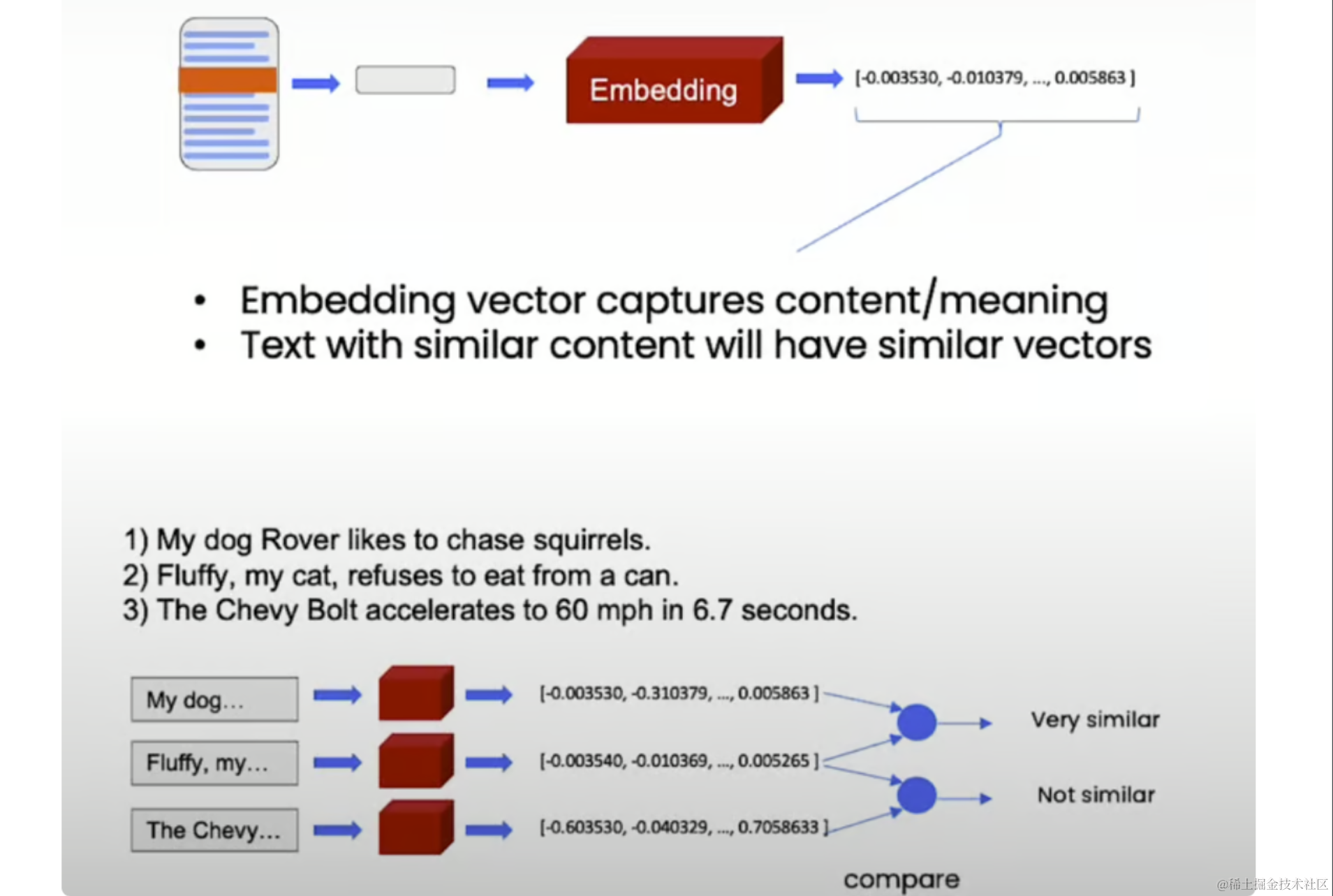
from langchain.document_loaders import CSVLoader
loader = CSVLoader(file_path=path)
docs = loader.load()
print(docs[0])
# Output
# Document(page_content=": 0\nname: Women's Campside Oxfords\ndescription: This ultracomfortable lace-to-toe Oxford boasts a super-soft canvas, thick cushioning, and quality construction for a broken-in feel from the first time you put them on. \n\nSize & Fit: Order regular shoe size. For half sizes not offered, order up to next whole size. \n\nSpecs: Approx. weight: 1 lb.1 oz. per pair. \n\nConstruction: Soft canvas material for a broken-in feel and look. Comfortable EVA innersole with Cleansport NXT® antimicrobial odor control. Vintage hunt, fish and camping motif on innersole. Moderate arch contour of innersole. EVA foam midsole for cushioning and support. Chain-tread-inspired molded rubber outsole with modified chain-tread pattern. Imported. \n\nQuestions? Please contact us for any inquiries.",
# metadata={'source': '/home/voldemort/Downloads/Code/Langchain_Harrison_Chase/Course_1/OutdoorClothingCatalog_1000.csv', 'row': 0})
from langchain_openai import OpenAIEmbeddings
import os
openai_api_key = os.environ.get("OPENAI_API_KEY")
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
embed = embeddings.embed_query("Hi, my name is Rutam")
print(embed[:5])
# Output
# [-0.007099587601852241, -0.01262648147645342, -0.016163436995450566, -0.0208622593573264, -0.013261977828921556]
①人工智能/大模型学习路线
②AI产品经理入门指南
③大模型方向必读书籍PDF版
④超详细海量大模型实战项目
⑤LLM大模型系统学习教程
⑥640套-AI大模型报告合集
⑦从0-1入门大模型教程视频
⑧AGI大模型技术公开课名额
3.矢量数据库
向量数据库存储这些嵌入,允许我们通过测量向量相似性来查找给定查询的相关文本块。
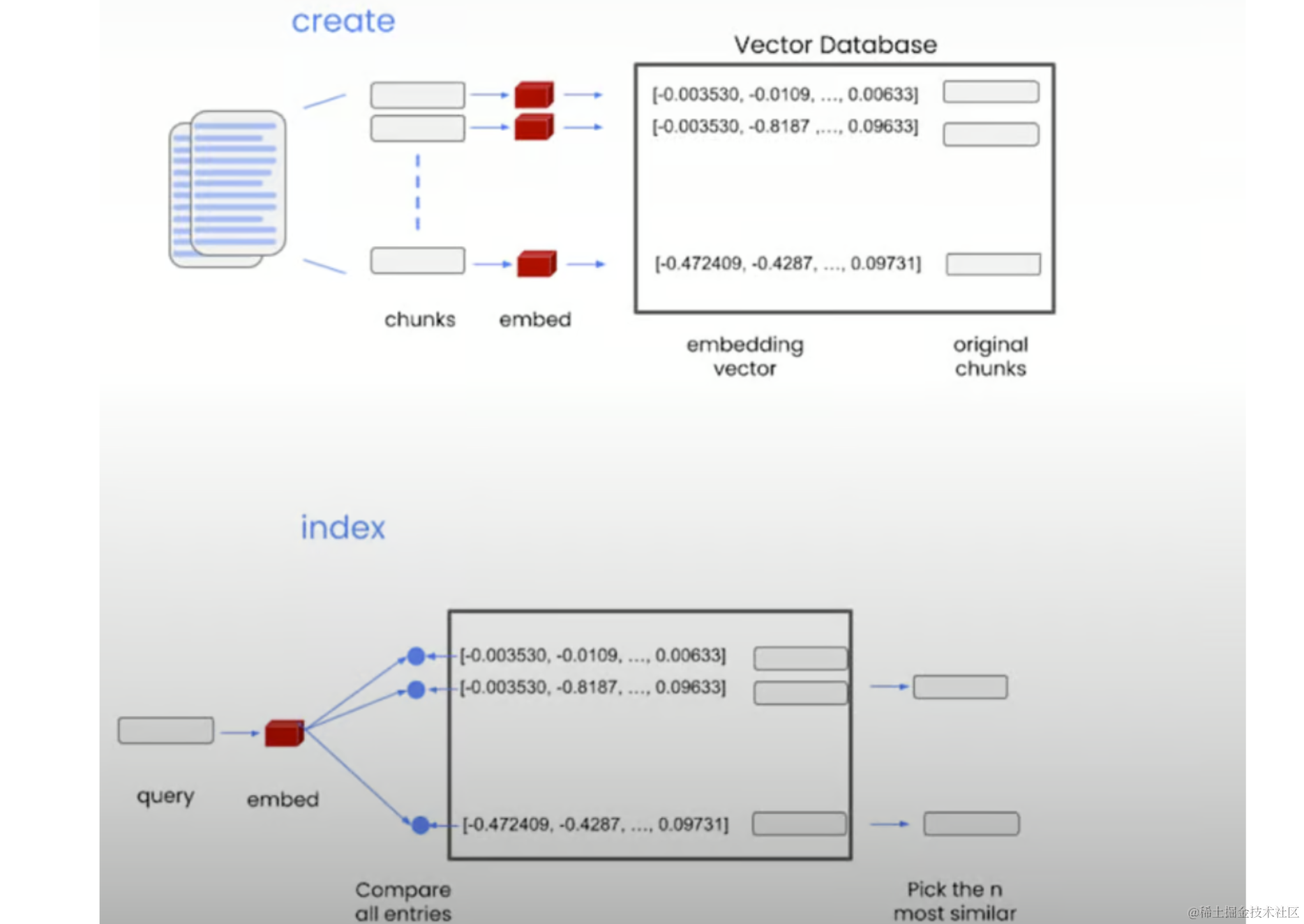
from langchain.indexes import VectorstoreIndexCreator
db = DocArrayInMemorySearch.from_documents(docs, embedding=embeddings)
query = "Please suggest a shirt with sunblocking"
docs = db.similarity_search(query)
3.检索问答
我们将从矢量存储创建一个检索器,并使用像 ChatOpenAI 这样的语言模型来生成文本。
from langchain_openai import ChatOpenAI
retriever = db.as_retriever()
llm = ChatOpenAI(temperature=0.0, model="gpt-3.5-turbo")
然后,我们将检索到的文档和查询结合起来,将它们传递给语言模型,并得到最终答案。
qdocs = "\n".join([docs[i].page_content for i in range(len(docs))])
response = llm.call_as_llm(
f"{qdocs} Question: Please list shirts with sun protection in a table in markdown and summarize each one."
)
二、LangChain链
虽然我们可以手动实现上述过程,但LangChain提供了一个强大的抽象,称为RetrievalQA,可以简化该过程。
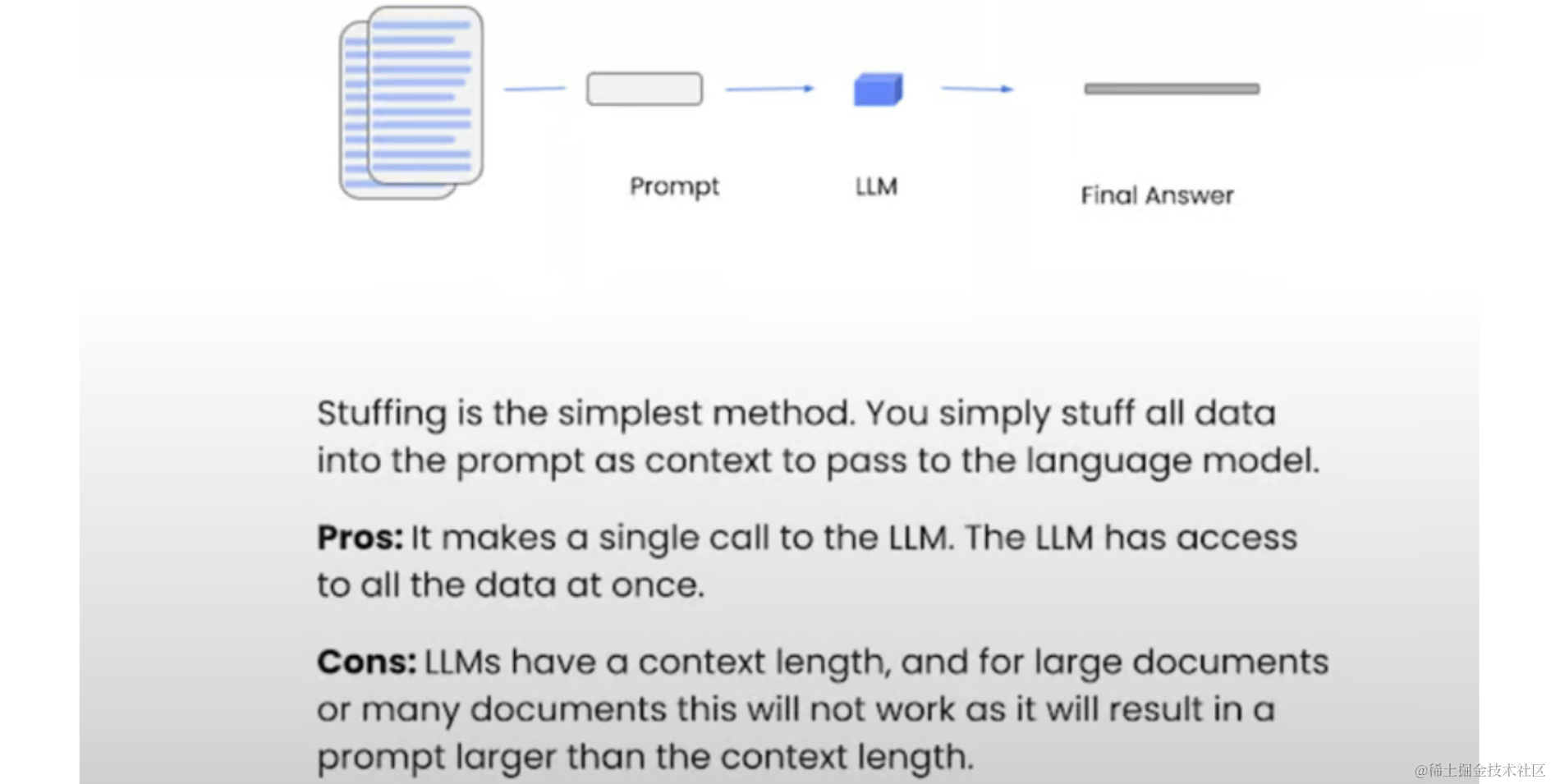
qa_stuff = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, verbose=True)
response = qa_stuff.invoke(query)
response = index.query(query, llm=llm)
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=embeddings,
).from_loaders([loader])
1.检索QA链
RetrievalQA 链封装了检索和问答过程,可以轻松自定义嵌入、向量存储和链类型等组件。
2.链条类型
LangChain针对不同场景提供多种链式:
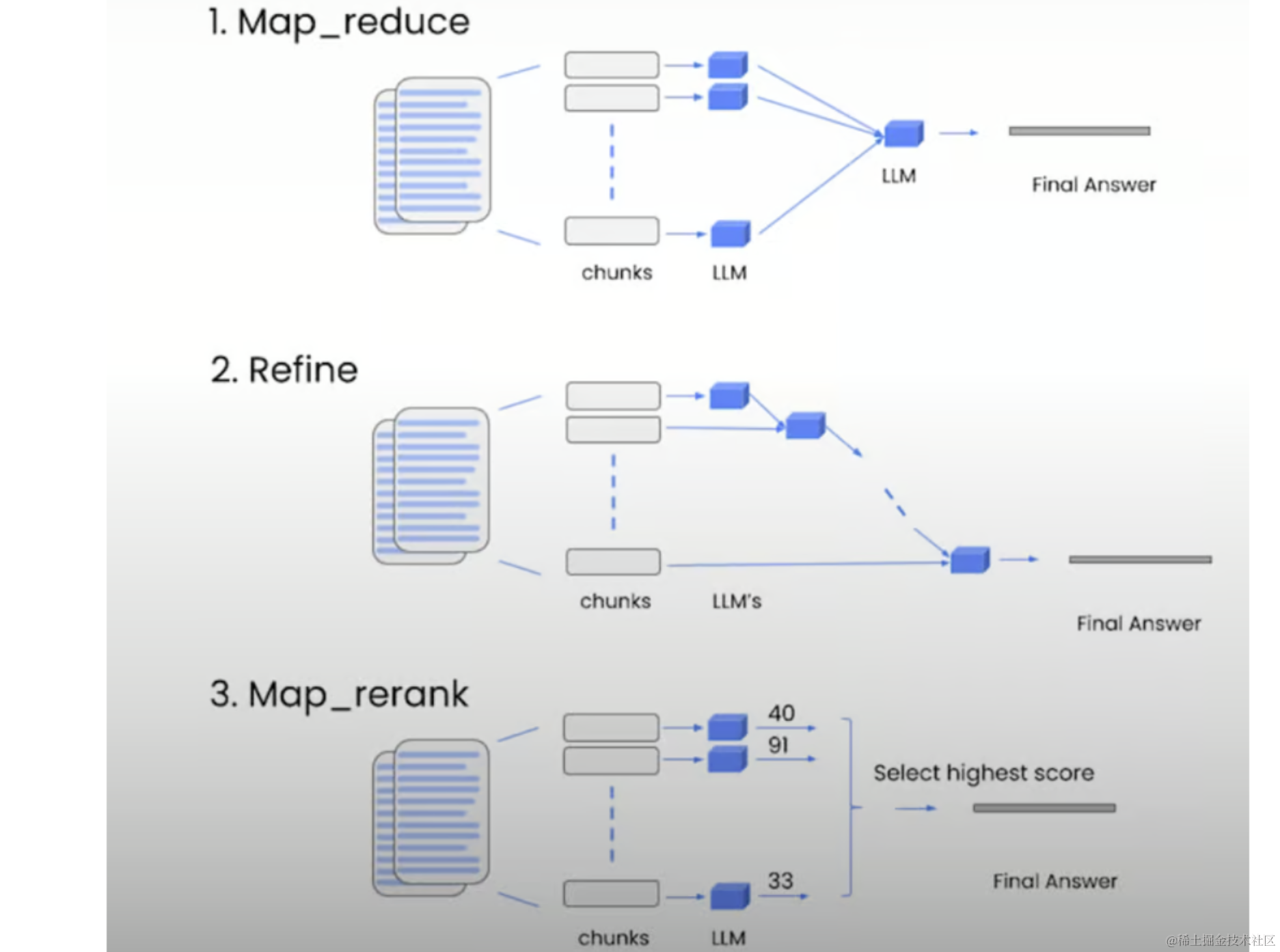
- Stuff:将所有文档合并到一个提示符中(在上面的示例中使用)。
- Map-reduce:独立处理文档块,然后进行汇总。
- Refine:以迭代方式构建以前的答案。
- Map-rerank:对每个文档进行评分,选择最高分。
小结
今天我们学习的是基于LangChain对文档进行问答,使用 LLM 对文档进行问答从未如此简单。使用 LangChain,您可以使用嵌入和向量存储等尖端技术来使您的 LLM 更加灵活和适应性强。无论您是在构建虚拟助手、增强产品搜索,还是探索自然语言处理的新领域,可能性都是无穷无尽的。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}