






摘要
ChatGPT的成功引发了一场人工智能竞赛,研究人员努力开发新的大型语言模型(LLMs),以匹敌或超越商业模型的语言理解和生成能力。近来,一些模型已经涌现,通过各种指导调整方法声称性能接近GPT-3.5或GPT-4。作为Text-to-SQL解析的实践者,我们对他们在开源研究中的宝贵贡献表示感谢。然而,审慎对待这些声明并确切评估这些模型的实际有效性是重要的。因此,我们将六个流行的大型语言模型相互比较,系统评估它们在九个基准数据集上的Text-to-SQL解析能力,采用五种不同的提示策略,覆盖零-shot和few-shot场景。遗憾的是,这些开源模型在性能上明显不及GPT-3.5等闭源模型,突显了弥合这些模型之间性能差距的进一步研究的必要性。
1 引言
Text-to-SQL解析自动将用户输入的问题转换成SQL语句,实现从数据库中检索相关信息。通过让用户用自然语言表达他们的目标,Text-to-SQL系统可以降低非专业用户与关系型数据库交互的技术障碍,提高生产力。
引入像BERT和T5这样的大型预训练语言模型进一步改善了Text-to-SQL系统的性能。研究人员正在利用这些模型卓越的理解能力,推动Text-to-SQL能力的边界。
最近,在基于解码器的大型语言模型方面取得的突破进一步革新了自然语言处理领域。一种显著的趋势是追求训练规模逐渐扩大的语言模型,包括数十亿个参数,并利用大量文本数据。随后,使用基于指令的技术对这些模型进行微调,使它们更好地符合人类生成的文本提示。
ChatGPT是解码器LLMs的显著应用之一,它构建在OpenAI的GPT-3.5和GPT-4模型之上。ChatGPT在零-shot和few-shot场景中表现出色,如各种Text-to-SQL评估研究所证实的那样。遗憾的是,ChatGPT的成功引发了一场人工智能竞赛,导致工业研究实验室停止公开披露其模型参数和训练方法。
因此,研究人员一直在积极追求开发新的语言模型,以潜在地与ChatGPT的能力相媲美。这些模型包括Dolly,它构建在Pythia模型之上,以及Vicuna和Guanaco,基于LLaMA模型。其中一些通过声称通过微调技术实现超过90%的GPT-4性能水平而受到关注。
作为Text-to-SQL的实践者,我们感谢这些模型的贡献。然而,我们对这些开源模型是否真正达到它们所声称的质量水平感到不确定。为了解决这个问题,本文对六种语言模型(Dolly、LLaMA、Vicuna、Guanaco、Bard和ChatGPT)进行了全面评估,直接比较它们在九个基准数据集上的性能,采用了五种不同的提示策略。
我们的主要发现有:
-
在大多数Text-to-SQL数据集上,开源模型的性能明显不如闭源模型。
-
虽然LLMs在生成语法有效的SQL语句方面表现出色,但它们经常难以产生语义准确的查询。
-
LLMs在利用few-shot学习的示例时表现出高度敏感性。
为促进Text-to-SQL解析领域的进一步研究,我们将所有大型语言模型的原始和后处理输出公开在匿名URL上。
2 实验设置
2.1 大型语言模型竞争者
我们从五个大型语言模型家族中精选了竞争者,以全面展示当前领域的格局:
-
Dolly是一个拥有120亿参数的语言模型,声称是首个公开可用的针对学术和商业应用进行许可的指导调整LLM。它基于Pythia,并经过由Databricks员工创建的指令数据集进行了微调。此外,我们还尝试了Dolly的较小变体,包括3B和7B版本。
-
LLaMA是一个包含70亿到650亿参数的大型语言模型集合。这些模型仅在公开可用的文本语料库上进行训练。与其他模型不同,LLaMA模型没有经过指令微调。为了确保提示的自然延续,与LLaMA模型互动时,我们在提示的末尾附加关键字“SELECT”。
-
Vicuna是一个拥有130亿参数的LLaMA模型,通过对从ShareGPT2收集的用户共享对话进行微调,它声称在使用GPT-4进行自动评估时达到90%的ChatGPT质量。我们还尝试了7B版本。
-
Guanaco是一系列大型语言模型,声称在一台GPU上仅经过24小时的微调就能实现99.3%的ChatGPT性能。与Vicuna类似,Guanaco模型在LLaMA模型上进行了指导调整。我们在33B版本上进行评估。
-
Bard是由谷歌发布的对抗OpenAI的ChatGPT的会话式聊天机器人。它最初由LaMDA驱动,后来过渡到PaLM 2。由于Bard的技术细节未公开,我们将其作为黑盒模型在Text-to-SQL数据集上评估其性能。我们将由LaMDA驱动的版本称为Bard-L,由PaLM 2驱动的版本称为Bard-P2。
-
GPT-3.5是OpenAI目前为止为基于聊天的应用优化的最具成本效益的大型语言模型。在写本文时,它具有1750亿参数,驱动着广受欢迎的ChatGPT聊天机器人。我们通过openAI的API在“GPT-3.5-turbo-0301”变体上进行所有评估。
2.2 提示策略
我们探索了五种常用的提示策略:**非正式模式(IS)**策略提供了关于表及其相关列的自然语言描述。在这种方法中,模式信息以较不正式的方式表达。相反,**API文档(AD)策略,正如Rajkumar等的评估中所概述的,遵循OpenAI文档提供的默认SQL翻译提示。这个提示遵循数据库模式的稍微更正式的定义。Select 3策略包括数据库中每个表的三个示例行。这个额外的信息旨在提供每个表中包含的数据的具体示例,补充模式描述。我们还研究了一次学习(1SL)和五次学习(5SL)**策略的有效性,在这些策略中,我们分别在提示中提供了一个和五个黄金示例。各种提示策略的示例可以在附录中找到。
2.3 基准数据集
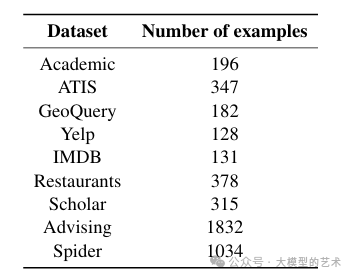
表1:用于评估各种Text-to-SQL数据集的示例数量。
我们在九个Text-to-SQL数据集上评估了提示策略:Academic、ATIS、GeoQuery、Yelp和IMDB、Restaurants、Scholar、Advising和Spider。值得注意的是,对于前八个数据集,我们使用了Finegan-Dollak等人发布的标准化和改进版本。
按照Zhong等人的方法,我们在数据集的测试集上评估大型语言模型的性能,如果定义了这样的集合。在没有提供测试集的情况下,我们对整个数据集进行评估。对于Spider数据集,由于在写作本文时测试集尚不公开,我们在开发集上评估模型。为了保持与Zhong等人的一致性,我们将前八个数据集统称为“经典数据集”。
有关数据拆分的重要细节:经典的Text-to-SQL数据集,如GeoQuery、ATIS和Scholar,通常使用基于问题的数据拆分策略,其中匹配的(文本,SQL)对分配到相同的拆分。然而,这种拆分策略的一个潜在问题是相同的SQL查询可能出现在训练集和测试集中。在训练集和测试集之间重复使用相同的SQL查询可能引入偏差,并可能夸大模型的性能。模型可能无意中学会记住特定的SQL查询,而不是理解底层的语义解析。因此,我们采用Finegan-Dollak等人描述的基于查询的数据拆分,其中具有相似结构的SQL查询被分配到相同的拆分。因此,我们报告的一些结果比以前的研究中记录的结果低。
此外,我们还想强调,与Suhr等人;Lan等人使用GeoQuery、Scholar和Advising的经过过滤的训练和开发拆分的组合以及ATIS的经过过滤的开发拆分作为他们的评估集不同,我们坚持使用Finegan-Dollak等人的评估拆分。这个决定的原因是我们打算从训练集中采样示例,以进行一次学习和五次学习的提示实验。
2.4 评估指标
本文采用的主要评估指标是执行准确度(EX),它衡量生成的SQL查询与黄金SQL查询的输出完全一致的百分比。此外,对于Spider数据集,我们还计算测试套准确度(TS),这是该数据集的官方评估指标。TS通过评估在一组经过精简的随机生成的数据库上预测查询的执行准确度,提供了语义准确性的上界估计。与Liu等人一样,我们避免使用精确匹配准确度指标,因为SQL查询通常可以以多种等效的方式表达相同的目标。因此,精确匹配准确度可能会无意中惩罚那些生成的SQL查询与黄金数据在样式上不同的大型语言模型。
2.5 评估细节
我们在研究中使用了几种模型,包括Dolly的三个变体(v2-3b、v2-7b和v2-12b)、Vicuna的两个变体(7B和13B)、Guanaco的一个变体(33B)和LLaMA的四个变体(7B、13B、30B和65B)。为了保持一致性,我们致力于紧密遵循每个模型的默认超参数。我们设置了Dolly的top-p采样率为0.92和温度为0.8,Vicuna和Guanaco的温度为0.8,LLaMA的top-p采样率为0.95和温度为0.8。在评估过程中,我们在配备有八个NVIDIA RTXA6000 GPU的服务器上进行实验。对于Bard,我们开发了一个脚本,直接从其Web用户界面提取评估输出。对于GPT3.5,我们通过OpenAI的API利用“gpt-3.5-turbo-0301”版本,并遵循温度为1.0和top-p采样率为1.0的默认超参数。
3 评估结果
3.1 Spider 数据集
各种提示策略和模型在执行准确度(EX)和测试套准确度(TS)上的表现见表2。我们的主要发现如下:
闭源模型表现优于开源模型: GPT-3.5是领先的模型,在执行准确度(EX)上超过第二名的Bard模型17.8%,在测试套准确度(TS)上超过14.1%。然而,GPT-3.5仍然落后于最先进的Text-to-SQL模型,如Li等人提出的模型,绝对值至少相差13%。Bard-P2在使用IS、S3和5SL提示策略时表现出一些改进,但在使用AD和1SL提示策略时性能显著下降。
开源模型在Spider 数据集上表现不佳: 尽管模型性能与参数数量之间存在正相关关系,但开源模型在Spider 数据集上达到高准确度仍然面临挑战。例如,尽管Vicuna 7B和13B相对于原始预训练的LLaMA 7B和13B模型有所改善,但与Bard和GPT-3.5相比,性能仍存在显著差距。此外,Dolly 模型在不同提示策略下与LLaMA 13B版本相比也表现不佳。
LLMs的性能对提示样式非常敏感: 我们的实证发现证实,没有一种通用的提示策略能够在所有模型上都表现良好。虽然IS提示策略对GPT-3.5、Bard、Vicuna和Guanaco有效,但对Dolly和LLaMA的准确度较低。令人惊讶的是,LLaMA在使用S3提示时取得最佳效果,而相反,这显著降低了GPT-3.5的性能。
随机示例的少量学习提供有限的性能收益: 大多数从1SL和5SL获得的结果往往表现不佳,最多只能达到与其他提示策略相当的结果。然而,有两个例外。一个例外是Dolly模型,在12B变体中使用1SL提示策略时,其性能较其他提示策略更好。这一结果似乎是异常的,因为在其他1SL和5SL结果中没有观察到类似的性能提升。另一个例外是LLaMA模型,其中少量学习的提示策略优于一些零量学习的策略。例如,30B LLaMA模型仅提供5个示例,即可达到22.4%的EX和19.9%的TS准确度,接近Guanaco模型(24.4%的EX和19.0%的TS)的性能水平。
3.2 经典数据集
由于Academic、Restaurants、IMDB和Yelp没有训练集,我们从其他经典数据集的评估集中对1SL和5SL进行采样。根据表3中的结果,我们总结了一些关键发现:
大多数经典数据集上,LLMs 的性能较差: 特别是在与先前研究中报告的基准性能相比,Academic 和 Restaurants 数据集的结果存在明显差异。这些数据集上达到的最高准确度仅为2.9%和2.4%,相比之下,使用传统的seq2seq模型与LSTM或BERT实现的研究基准结果分别为34.0%和45.2%。此外,即使在使用指导调整的情况下,Vicuna、Guanaco和Dolly在经典数据集上仍面临巨大挑战,它们在不同提示策略和数据集组合中通常几乎产生零执行准确度。
少量学习的有效性在不同模型之间变化: 与Spider 数据集的发现相反,我们观察到在LLaMA 和 GPT-3.5 上使用1SL 和 5SL 时性能有所提高。例如,GPT-3.5 在 GeoQuery 数据集上的性能从15.4%提高到42.3%,而LLaMA 在相同数据集上的性能也从12.1%提高到15.4%。然而,我们在Dolly、Vicuna 和 Bard 上没有看到类似的性能改进。
附加数据库示例行是无效的: 与观察到的Spider数据集结果一样,将S3提示策略应用于经典数据集在不同模型上产生了次优结果。因此,可以明显看出,S3提示策略在Text-to-SQL的背景下可能不太有效。
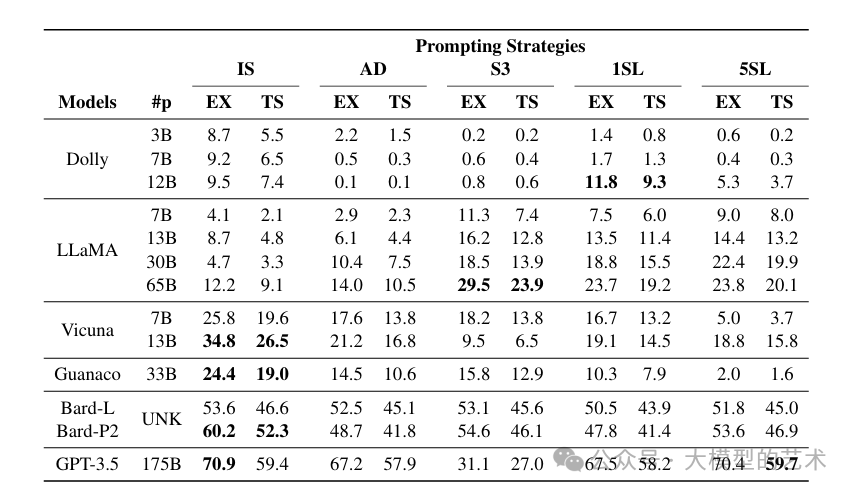
表2:各大语言模型及提示策略(Informal Schema(IS)、API Docs(AD)、Select 3(S3)、1-shot learning(1SL)和 5-shot learning(5SL))在 Spider 开发集上的执行准确度(EX)和测试套准确度(TS)结果。Bard的参数数量(#p)未知(UNK)。粗体标注的是每个大语言模型家族中的最佳结果。
4 讨论
4.1 大语言模型是否生成有效的SQL语句?
大语言模型性能不佳的一个潜在解释在于它们无法理解旨在生成SQL语句的提示背后的意图。例如,在回答问题“返回PVLDB的主页”时,Guanaco直接提供了答案“该网站是https://www.vldb.org/pvldb。”面对许多S3提示,GPT-3.5未能生成有效的响应。为了评估这种情况的程度,我们绘制了在不同提示策略下生成的有效SQL语句的比例,如图1a和1b所示。对于Spider数据集,我们发现许多模型(除了Dolly)在使用IS、1SL和5SL提示策略时一贯生成90%以上的有效SQL响应。有趣的是,LLaMA也表现出生成有效SQL语句的能力,尽管它并没有专门在指导数据集上进行微调。对于经典数据集,Bard-P2和GPT-3.5仍能在80-100%的范围内生成有效的SQL。然而,像Vicuna和Dolly这样的开源模型在实现超过75%的有效SQL百分比方面遇到了挑战。LLaMA和Guanaco呈现出不同的趋势,尤其值得注意的是,LLaMA通过少量学习生成更多的有效SQL,而Guanaco的性能随着示例数量的增加而下降。
此外,我们注意到AD和S3提示策略通常不太理想,因为它们导致许多大型语言模型在所有数据集上生成的有效SQL响应数量显著减少。GPT-3.5特别容易受到S3提示策略的影响,在Spider和经典数据集中生成的有效SQL百分比大幅下降。
最后,值得强调的是,尽管这些语言模型可以生成有效的SQL响应,但这些SQL往往在语义上不准确,无法充分解答输入文本的问题。因此,在大多数数据集上的执行准确度明显较低。
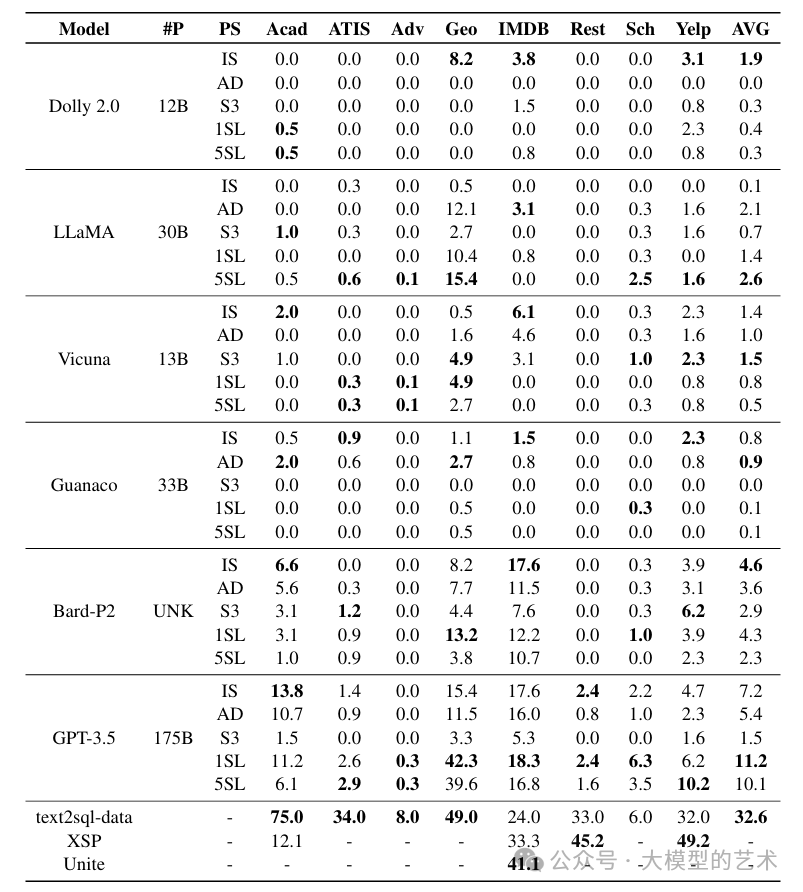
表3:在经典数据集(Academic、ATIS、Advising、GeoQuery、IMDB、Restaurant、Scholar和Yelp)上使用各种大语言模型和提示策略的EX和TS结果。我们还包括Finegan-Dollak等人(2018)(text2sql-data)、Suhr等人(2020)(XSP)和Lan等人(2023)(Unite)的基准结果,如果可能的话。在每个大语言模型家族中用粗体标出的是最佳结果。
4.2 样本选择如何影响1SL和5SL的性能?
根据表2和表3中呈现的结果,很明显,在提示中包含来自训练集的随机示例并未显著提高不同模型的性能。唯一的例外是LLaMA和GPT-3.5,它们在使用1SL和5SL提示策略时表现出明显的改善。LLaMA的性能提高可以部分归因于暴露LLaMA到更多示例显著增强其生成有效SQL的能力,如图1b所示。
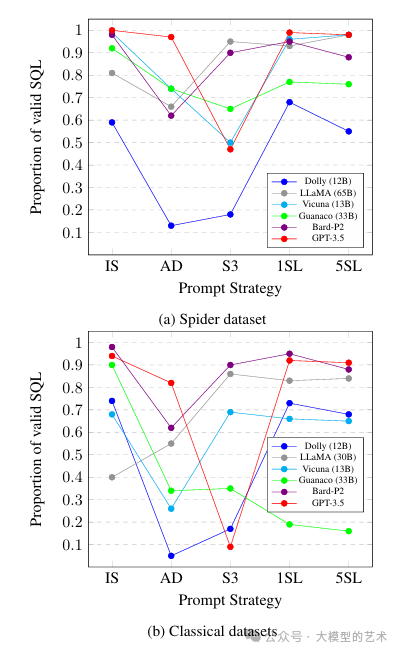
图1:不同提示策略下多个模型生成有效SQL的比例。图(a)呈现了Spider数据集的结果,而图(b)呈现了基于经典数据集的平均结果。
LLMa适应规范化的SQL风格: 另一个值得注意的观察是,当向大型语言模型提供来自经典数据集的示例时,它们开始以类似于Finegan-Dollak等人描述的规范化格式生成SQL,如图2所示,其中表别名遵循<TABLE_NAME>alias的标准约定。

图2:规范化SQL语句示例
LLMs对风格变化的敏感性: 为了评估语言模型(LLMs)在使用1SL和5SL生成SQL时遵循规范化SQL风格的程度,我们检查生成的SQL语句中包含术语“alias”的比例(见表4)。我们的研究发现,在使用1SL和5SL提示策略时,生成的SQL风格变化是唯一明显的。值得注意的是,LLaMA在所有模型中表现突出,因为它一致地在超过86%的生成SQL语句中附加术语“alias”。有趣的是,Bard对规范化的SQL风格不太敏感,只有16.0%的生成SQL中观察到风格变化。另一方面,GPT-3.5表现出较高的敏感性,超过50%的生成SQL受到影响。基于这一观察,我们假设这种敏感性差异可能是LLaMA和GPT-3.5采用1SL和5SL提示策略取得更大成功的原因之一。
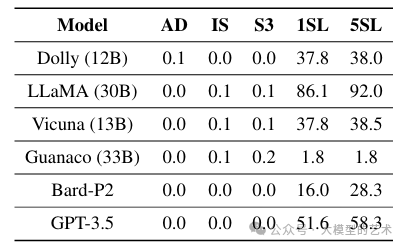
表4:包含术语“alias”的生成SQL在经典数据集中的百分比。
不同来源抽样对性能的影响
我们通过对来自不同来源的抽样性能进行实验,来结束本节。表5呈现了在从两个不同来源获取样本时得到的1SL和5SL结果。这两个来源分别是:1)Spider训练集和2)评估集。在第二种情况下,我们采取预防措施,通过过滤掉所有与感兴趣问题具有相同SQL答案的示例,以避免任何潜在的答案泄漏。我们发现使用来自Spider数据集的示例不仅未带来任何好处,而且还导致模型性能下降,表现不如零样本方法。另一方面,当我们包括来自评估集的示例时,我们观察到评估结果有所改善。在仔细检查提示时,我们发现少量示例在句法上与期望的SQL响应相似,主要在表、列和值方面有所不同。这一发现突显了LLMs对提示中提供的示例的敏感性。我们假设如果我们用在句法上与期望的SQL响应相似的示例供给LLMs,它们可能会生成更准确的SQL语句。
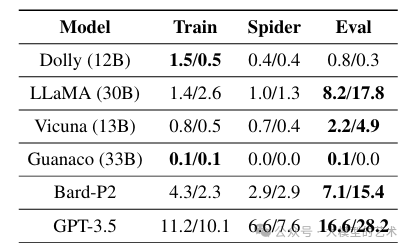
表5:从训练集、Spider训练集和评估集进行抽样时的平均1SL/5SL EX结果。
4.3 我们是否真正以零样本或少样本方式评估Text-to-SQL数据集?
我们已经确定了一些潜在的数据污染源,这些源引发了对Text-to-SQL数据集零样本或少样本评估真实性的关切。这些源包括Spider数据集和经典数据集都在GitHub存储库上可用,以及Spider数据集在Huggingface数据集等平台上的存在。此外,Text-to-SQL数据集还可能包含在FLAN等指导调整数据集收藏中。我们在文章结尾提出一个问题供研究人员思考:当大型语言模型已经接触过我们的评估数据时,我们是否真正进行了对它们进行零样本或少样本评估?
5 相关工作
最近,基于解码器的大型语言模型在代码生成任务中取得了巨大的贡献。这些模型利用大规模文本数据上的无监督自回归学习,使它们能够捕捉丰富的语义关系和单词的概率分布。尽管它们在上下文中只有一个或少量示例的表现非常出色,但最近的研究表明它们在涉及复杂推理的Text-to-SQL任务上仍然面临挑战。
有一些研究专注于通过增强提示设计来提高大型语言模型的文本到SQL解析能力。在Nan等人进行的一项研究中,作者强调了精心选择上下文学习示例的重要性。他们证明,将示例查询中的句法结构纳入可以极大增强大型语言模型的少样本能力。Chang和Fosler-Lussier进行了一项全面研究,探讨了提示长度对文本到SQL模型性能的影响。此外,他们还研究了跨不同领域的数据库知识表示的敏感性。Guo等人提出了一个基于案例推理的框架,通过自适应检索案例提示,在跨领域设置中调整GPT-3.5的输入。Rai等人通过边界为基础的技术,在模式和SQL的令牌级和序列级上预处理提示,以提高大型语言模型的泛化能力。
同时,一些研究也探讨了多步推理的复杂性对提高大型语言模型在文本到SQL解析上性能的潜在益处。Tai等人展示了最小到最多提示可能是不必要的,直接应用思维链(CoT)提示可能导致错误传播。Liu和Tan为Text-to-SQL任务引入了一种分隔和提示范式,该范式涉及将任务分为多个子任务,并对每个子任务应用CoT方法。在Pourreza和Rafiei的另一项研究中,在零样本设置中采用了一种自我校正模块,以在Spider排行榜上取得最新的最佳结果。该模块将每个子问题的解决方案反馈给大型语言模型,使其能够构建更好的整体解决方案。
6 结论和未来工作
本文系统评估了六个流行的大型语言模型在九个基准数据集上的Text-to-SQL解析能力,使用了五种不同的提示策略。我们的研究发现,与封闭源模型相比,开源模型在性能上存在显著不足。然而,值得注意的是,即使GPT-3.5在几个经典数据集上的表现也不如较小的基线模型。我们将我们的输出提供给进一步分析,并促进未来的研究工作。
在未来,我们有几个研究方向。首先,我们计划研究如何使用有限的GPU资源,采用低秩适应等技术,在Text-to-SQL数据集上对这些大型语言模型进行微调。其次,我们希望探索可以动态选择上下文学习示例的方法。最后,我们对研究在多轮Text-to-SQL数据集上(如SPARC)采用这些大型语言模型的可行性和局限性感兴趣。
限制
首先,我们承认这项研究的范围仅限于六个大型语言模型,而这些模型并未涵盖整个研究领域。近期还涌现出一些新颖的模型,如Falcon模型。其次,将五个示例附加到一些经典数据集的数据库模式可能会超出开源模型的2048令牌限制,在某些情况下导致截断,可能会对这些模型带来更短的上下文窗口。最后,一些模型生成的不仅是SQL语句,还包括附加信息,如解释。为确保准确性,我们已开发了正则表达式模式,旨在尽力提取仅为SQL语句的部分。然而,我们承认我们的规则可能并非完全防错,并且在某些情况下可能引入错误的SQL。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}