






一、Grounding DINO:开词汇的精确目标定位
1. 目标和特性
Grounding DINO 是一种将自然语言与图像理解深度融合的模型,专注于开放词汇的目标检测和语言引导的目标定位。它的独特之处在于能够根据任意的文本描述,在图像中准确地定位和检测对应的目标,即使这些目标在训练集中未曾出现过。
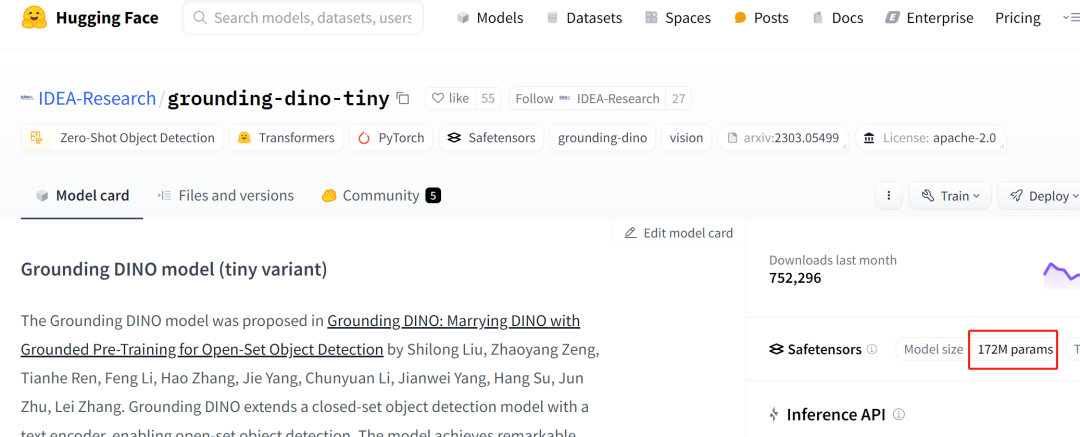
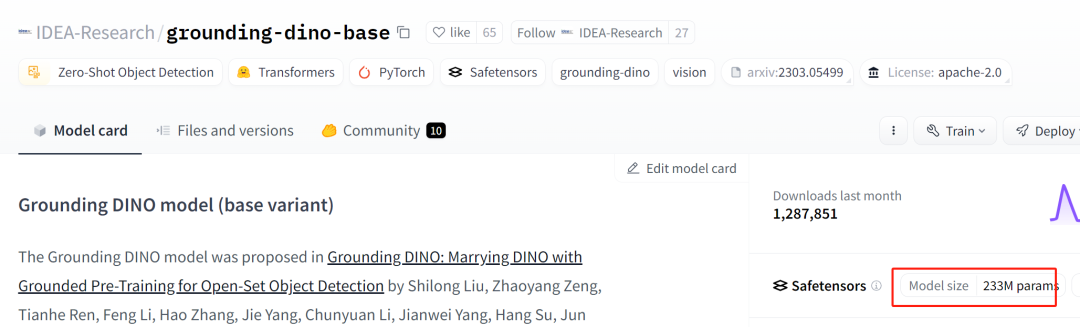
2. 技术架构
Grounding DINO 基于 DINO(DETR with Improved DeNoising Anchor Boxes)的架构,融合了 Transformer 的优势。通过在模型中引入文本编码器,将视觉特征和语言特征在统一的框架中融合。模型采用跨模态的注意力机制,使得视觉和语言信息可以相互关联,实现精确的目标定位。
具体来说,Grounding DINO 构建在 DINO(DETR with Improved DeNoising Anchor Boxes)的基础之上,而 DINO 又是对 DETR(DEtection TRansformer)模型的改进和增强。DETR 是首个将 Transformer 应用于目标检测任务的模型,通过将卷积神经网络(CNN)与 Transformer 相结合,实现了端到端的目标检测。
Grounding DINO 的核心架构包含以下关键部分:
- 视觉编码器(Backbone):
-
通常使用预训练的 CNN(如 ResNet)来提取图像特征。
-
提取的特征被传递给 Transformer 编码器。
- Transformer 编码器和解码器:
-
编码器负责处理视觉特征,捕获图像中的全局和局部信息。
-
解码器接收来自编码器的视觉特征和文本编码器提供的语言特征,进行跨模态融合。
-
自注意力机制使模型能够在视觉和语言特征之间建立关联,实现精确的目标定位。
- 文本编码器:
-
使用预训练的语言模型(如 BERT)将输入的自然语言描述编码为特征向量。
-
这些语言特征与视觉特征在 Transformer 解码器中进行融合。
- 跨模态注意力机制:
- 在解码器中,采用跨模态的注意力机制,使得模型能够根据文本描述,在图像特征中关注相关的区域。
- 预测头(Prediction Head):
-
解码器的输出经过线性层,生成目标的边界框和分类结果。
Grounding DINO 通过利用 Transformer 的强大建模能力,成功地将视觉和语言信息融合在一起,实现了开放词汇的目标检测。Transformer 架构的应用,使得模型在处理序列数据、全局依赖性和跨模态交互方面具有显著优势。
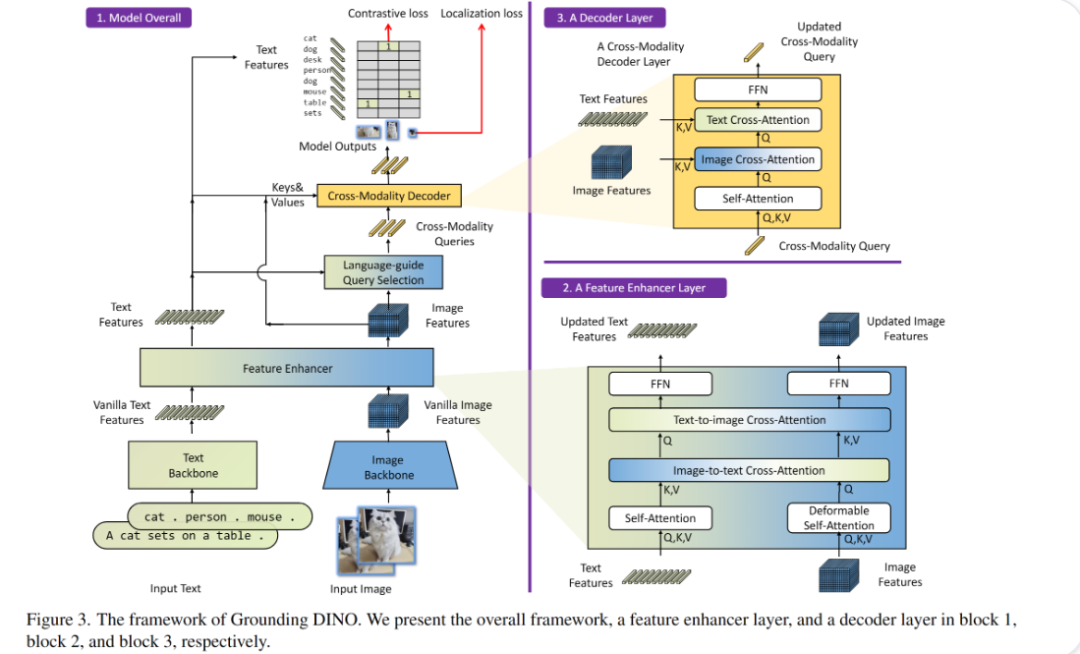
整体模型流程:
-
输入:给模型输入一段文本和一张图像。
-
特征提取:
-
文本特征提取:Text Backbone从文本中提取出初步的特征。
-
图像特征提取:Image Backbone从图像中提取出初步的特征。
-
特征增强:Feature Enhancer对提取到的文本和图像特征进行进一步增强。
-
跨模态查询生成:通过Language-guide Query Selection模块生成结合文本和图像信息的查询。
-
跨模态解码:Cross-Modality Decoder处理这些查询,结合文本和图像特征,输出最终结果。
-
输出:模型预测的结果,包括物体的类别和在图像中的位置。
特征增强层(Feature Enhancer Layer):
-
作用:进一步增强文本和图像特征,使得特征更加丰富。
-
方法:
-
使用Text-to-image Cross-Attention和Image-to-text Cross-Attention将文本和图像特征互相结合。
-
使用Self-Attention在同一模态内进一步处理特征。
-
输出:更新后的文本特征和图像特征。
解码层(Decoder Layer):
-
作用:根据增强后的特征进行解码,生成最终的预测结果。
-
方法:
-
使用Text Cross-Attention和Image Cross-Attention将文本和图像特征结合起来。
-
使用Self-Attention在同一模态内进一步处理特征。
-
输出:更新后的跨模态查询,用于最终的预测。
损失函数:
-
对比损失:确保模型能够正确地匹配文本和图像。
-
定位损失:确保模型能够准确地定位图像中的目标对象。
这个图展示的是一个结合了文本和图像信息的模型框架,通过多层次的特征处理和解码,最终实现精确的目标检测和定位。
3. 应用场景与具体案例
案例一:图像编辑中的智能选取
在照片编辑软件中,用户希望通过文字描述来选择特定的对象。例如,输入“选中画面中穿红色连衣裙的女孩”,Grounding DINO 能够根据描述,在图像中精确地框选出穿红色连衣裙的女孩,方便用户进行剪切、复制或应用滤镜等操作。
案例二:机器人视觉中的指令执行
家用服务机器人需要根据语音指令完成任务。用户说:“请把桌子上最大的绿色苹果拿给我。”Grounding DINO 可以帮助机器人在视觉输入中定位到“最大的绿色苹果”,然后进行抓取操作,提高了人机交互的自然性和效率。
案例三:安防监控中的异常事件检测
安防系统需要检测特定的异常行为或物体,例如“有人在禁区内放置包裹”。Grounding DINO 能够根据这种任意的文本描述,实时地在监控画面中检测并定位相关事件,提高安全性。
二、Florence-2:通用的视觉语言基础模型
1. 目标和特性
Florence-2 是微软推出的多模态大模型,是 Florence 模型的升级版本。它旨在建立一个通用的视觉语言基础模型,能够在广泛的下游任务中取得优秀的表现。Florence-2 具备处理多种视觉和视觉语言任务的能力,包括图像分类、对象检测、语义分割、图文检索、图像描述生成等。
2. 技术架构
Florence-2 采用了大规模的预训练方法,利用海量的图文数据进行训练。其架构可能包括了自监督学习、对比学习等先进技术,以提升模型的通用性和泛化能力。通过融合多模态数据,Florence-2 在多个任务上都展现出卓越的性能。
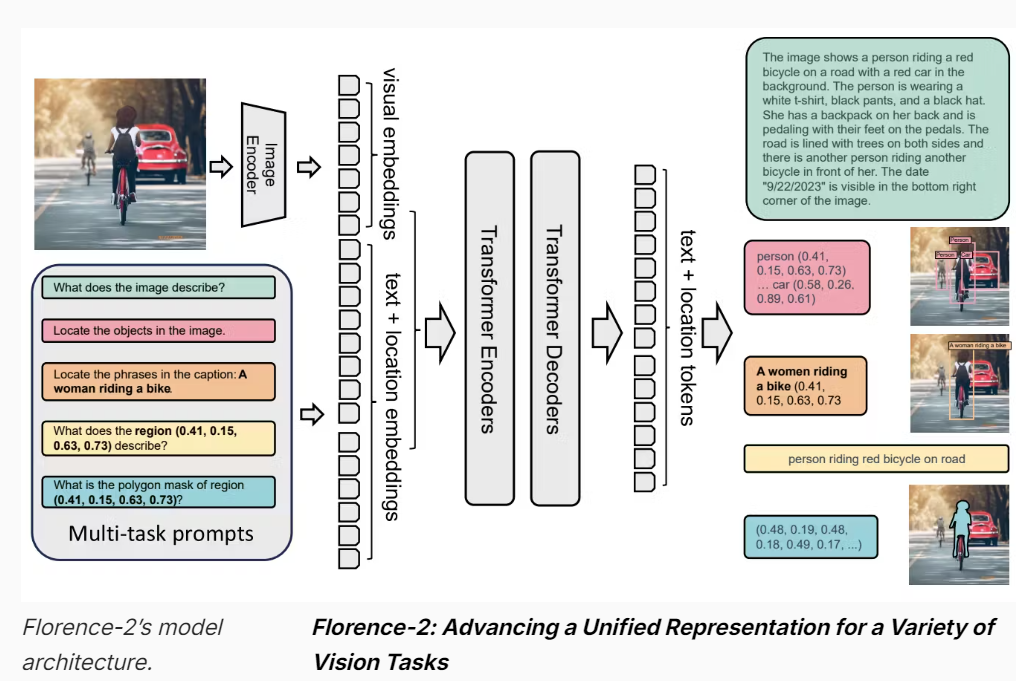
这张图展示的是Florence-2模型的架构,它用于处理多种视觉任务。以下是对这张图的详细解释,并与Grounding DINO进行对比:
Florence-2 模型架构:
- 输入:
-
图像输入:通过Image Encoder处理图像,生成视觉特征(visual embeddings)。
-
多任务提示(Multi-task prompts):包括问题、目标定位、短语定位、区域描述等任务提示。
- 特征编码:
-
视觉特征编码:从Image Encoder提取的视觉特征。
-
文本 + 位置特征编码(text + location embeddings):将文本和位置信息编码为特征向量。
-
Transformer Encoders:这些编码器处理视觉和文本特征,进行深度特征融合。
-
Transformer Decoders:解码器接收编码后的特征,生成文本和位置标记(text + location tokens)。
-
输出:
-
生成详细的图像描述(如右上角的绿色文本框)。
-
识别和定位图像中的对象(如右侧的红色和粉色标记框)。
-
生成多边形掩码(如右下角的蓝色掩码)。
与Grounding DINO的对比:
- 输入:
-
Grounding DINO:单独的文本和图像输入。
-
Florence-2:图像输入和多任务提示(包括文本和位置信息)。
- 特征提取:
-
Grounding DINO:使用Text Backbone和Image Backbone分别提取文本和图像特征。
-
Florence-2:使用Image Encoder提取图像特征,同时将文本和位置信息编码为特征。
- 特征融合:
-
Grounding DINO:通过Feature Enhancer和跨模态解码器(Cross-Modality Decoder)进行特征融合。
-
Florence-2:通过Transformer Encoders进行视觉和文本特征的深度融合。
- 解码过程:
-
Grounding DINO:使用跨模态解码器层(Cross-Modality Decoder Layer)生成最终的预测结果。
-
Florence-2:使用Transformer Decoders生成文本描述和对象定位信息。
- 输出:
-
Grounding DINO:输出包括对象的类别和位置。
-
Florence-2:输出更加多样化,包括详细的图像描述、对象的类别和位置,以及多边形掩码。
总结:
-
Grounding DINO更注重结合文本和图像信息进行目标检测和定位,通过特征增强和跨模态解码实现这一点。
-
Florence-2则通过多任务提示和Transformer架构处理多种视觉任务,生成详细的图像描述和对象定位信息,适用于更广泛的任务场景。
两者的主要区别在于输入处理方式、特征融合方法和输出内容的多样性。Grounding DINO集中于目标检测和定位,而Florence-2则提供了更为全面的视觉任务解决方案。
3. 应用场景与具体案例
案例一:智能相册分类与搜索
手机相册应用希望自动对用户的照片进行分类,如人物、风景、美食等,并根据用户的搜索需求提供结果。Florence-2 可以执行图像分类、标注和检索等多项任务,提升用户体验。
案例二:视觉问答(VQA)和对话系统
在教育应用中,学生上传一张显微镜下的生物组织照片,提问:“这是什么组织的切片?”Florence-2 能够识别图像内容,回答相应的知识点,辅助教学。
案例三:跨模态检索与匹配
电商平台的“以图搜图”功能,用户拍摄一件衣服的照片,希望找到相似的商品。Florence-2 可以将图像和商品文本描述映射到统一的语义空间,实现高精度的跨模态检索,满足用户需求。
三、模型比较与选择
1. 专注领域
-
Grounding DINO 更加专注于开放词汇的目标检测和语言引导的精确目标定位。适用于需要根据任意自然语言描述,在图像中定位对象的任务。
-
Florence-2 作为一个通用的多模态模型,旨在在多种视觉和视觉语言任务中都有良好的表现。适用于需要处理多种视觉任务的应用。
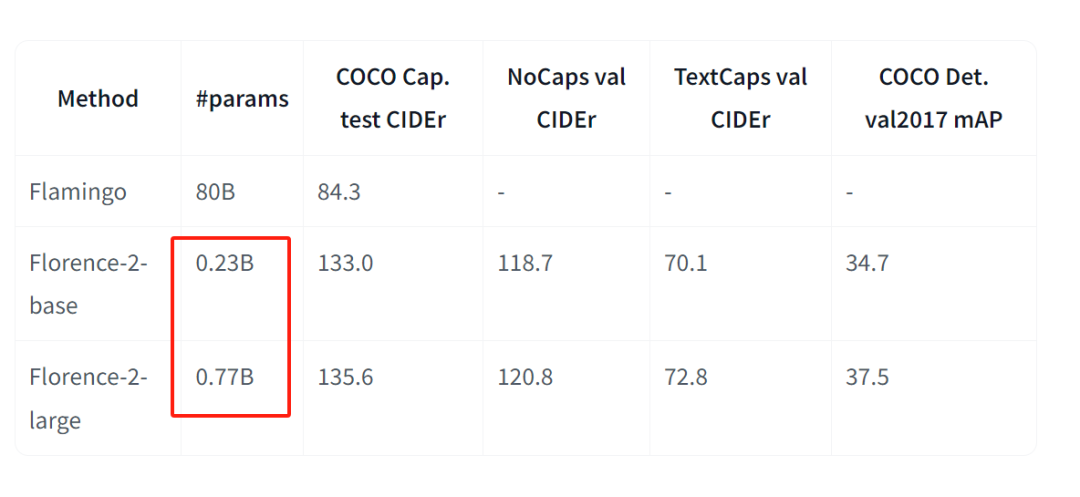
2. 模型规模和预训练数据
-
Florence-2 在模型参数规模和预训练数据量上更大,利用了更广泛的训练数据,以提升模型在各种任务上的性能。
-
Grounding DINO 则更注重在特定任务上的优化,通过精巧的架构设计,实现了在特定任务上的高性能。
3. 性能表现
-
如果关注文本引导的目标检测和定位任务,Grounding DINO 可能在精度和细粒度定位上具有优势。
-
对于需要处理多种任务的应用,尤其是在资源受限的情况下,Florence-2 的通用性可能提供更好的支持。
4. 具体使用建议
选择 Grounding DINO 的情况:
-
需要根据任意自然语言描述,在图像中精确定位对象。
-
如智能图像编辑、机器人视觉、人机交互等场景。
-
强调对新类别、新概念的实时检测和定位。
-
处理开放环境中的动态目标,或需要检测罕见事件时,Grounding DINO 的开放词汇能力非常有用。
选择 Florence-2 的情况:
-
需要处理多种视觉和视觉语言任务。
-
如图像分类、目标检测、语义分割、图像描述生成、视觉问答等多种任务。
-
强调模型的通用性和拓展性。
-
希望一个模型能够适应不同的应用场景,具备良好的泛化能力。
四、实战案例:Grounding DINO 的应用演示
为了更直观地理解 Grounding DINO,让我们来看一个具体的应用示例。
场景描述
假设我们有一张包含多种物体的图像,我们希望检测其中的“猫”和“遥控器”。
步骤一:环境准备
`pip install transformers pillow torch torchvision`
步骤二:加载模型和处理器
`import torch from PIL import Image from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model_name = "IDEA-Research/grounding-dino-tiny" processor = AutoProcessor.from_pretrained(model_name) model = AutoModelForZeroShotObjectDetection.from_pretrained(model_name).to(device)`
步骤三:准备图像和文本描述
`image = Image.open("path_to_your_image.jpg") # 请替换为实际的图像路径 text = "a cat. a remote control."`
步骤四:预处理输入
`inputs = processor(images=image, text=text, return_tensors="pt").to(device)`
步骤五:模型推理
`with torch.no_grad(): outputs = model(**inputs)`
步骤六:后处理结果
`results = processor.post_process_grounded_object_detection( outputs=outputs, input_ids=inputs.input_ids, box_threshold=0.3, text_threshold=0.25, target_sizes=[image.size[::-1]] )[0]`
步骤七:解析和展示结果
`for score, label, box in zip(results["scores"], results["labels"], results["boxes"]): print(f"检测到 {label},置信度:{score:.2f},位置:{[round(i, 2) for i in box.tolist()]}")`
结果示例
`检测到 a cat,置信度:0.48,位置:[344.7, 23.11, 637.18, 374.28] 检测到 a cat,置信度:0.44,位置:[12.27, 51.91, 316.86, 472.44] 检测到 a remote control,置信度:0.48,位置:[38.57, 70.0, 176.78, 118.18]`
五、重新训练模型 vs. 使用开放集模型
有人可能会问:如果需要检测新的类别,是否可以通过重新训练或微调模型来实现?
重新训练的挑战
-
数据收集与标注成本:获取并标注大量的新类别数据,耗时且昂贵。
-
训练资源与时间:重新训练深度模型需要大量的计算资源和时间。
-
模型更新频率:新类别频繁出现,频繁更新模型不现实。
-
泛化能力:在有限的数据上训练,可能导致过拟合,影响模型的泛化能力。
使用开放集模型的优势
-
无需重新训练:Grounding DINO 能够根据任意的自然语言描述,直接检测新类别。
-
即时性:适用于需要实时检测新类别的场景,提升灵活性。
-
节省资源:避免了频繁的训练过程,节省时间和计算资源。
建议
-
若新类别固定,资源充足:可以选择重新训练或微调模型,达到更高的精度。
-
若新类别未知或频繁变化:使用 Grounding DINO 等开放集模型更为合适。
结语
在计算机视觉与自然语言处理融合的道路上,Grounding DINO 和 Florence-2 都是里程碑式的模型。Grounding DINO 专注于开放词汇的精确目标检测,适用于需要实时响应自然语言描述的应用场景。而 Florence-2 则以通用性著称,适合处理多种视觉和语言任务。
选择哪一个模型,取决于您的具体需求:
-
如果您需要高精度的、基于自然语言的目标定位,尤其是在开放环境下,选择 Grounding DINO。
-
如果您的项目涉及多种视觉任务,且希望利用一个统一的模型,选择 Florence-2。
在未来,我们可以期待更多这样的创新模型出现,进一步推动人工智能的发展。

AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









