






引言
检索增强生成(RAG)主要目的是为了大模型引入外部知识,减少大模型幻觉,是目前大模型应用开发中必不可少的技术之一。但是传统RAG主要是通过语义相似度在向量空间中进行检索,无法捕获数据库中数据点之间的依赖关系。
为此,GraphRAG应运而生。本文将详细介绍传统RAG技术、GraphRAG技术、两者之间的优缺点以及如何将两者结合使用。本文结构安排:
传统RAG技术
RAG是 “检索增强生成(Retrieval Augmented Generation)” 的缩写。我们先聚焦于第一个词:检索。即首先检索相关上下文信息,是让大语言模型(LLM)基于特定上下文进行回答的第一步。
检索上下文有很多种方式,但目前最常见的方式是对给定数据集执行语义搜索(也称向量搜索)。这就引出了“朴素 RAG(Naive RAG)”这一术语,它是一种最基础的问题回答系统,其检索完全依赖向量搜索。
传统RAG技术介绍
在大多数 RAG 系统中,“R”(即 Retrieval,检索)指的就是向量搜索。通过使用Embedding模型将用户查询和数据进行向量化,然后通过语义相似度提取出最相关的信息。这通常需要借助向量数据库实现。
由于朴素RAG的非常适合为查询请求进行检索相关上下文,并将其作为LLM生成回答的依据。用于朴素RAG的数据集通常包括一系列“文本”字段,每条文本都生成一个嵌入向量,如下图所示: 需要注意的是,这里的每条数据都是独立的,每条都有其可以表示为向量的语义意义。因此,朴素RAG能访问的信息只是这些独立向量本身。这种方式只能表示出向量空间中的语义接近程度,并不能体现出数据之间的关系。
需要注意的是,这里的每条数据都是独立的,每条都有其可以表示为向量的语义意义。因此,朴素RAG能访问的信息只是这些独立向量本身。这种方式只能表示出向量空间中的语义接近程度,并不能体现出数据之间的关系。
举个例子:假设我们有一个包含多个(虚构)合同的数据集(如合作、雇佣等),每份合同都包含 contract_text、author 和 contract_type 字段。我们对每份合同进行向量化,让每份合同有一个代表其语义的向量。当我们就这些数据提出问题时,朴素RAG就能很好地检索出最相关的合同: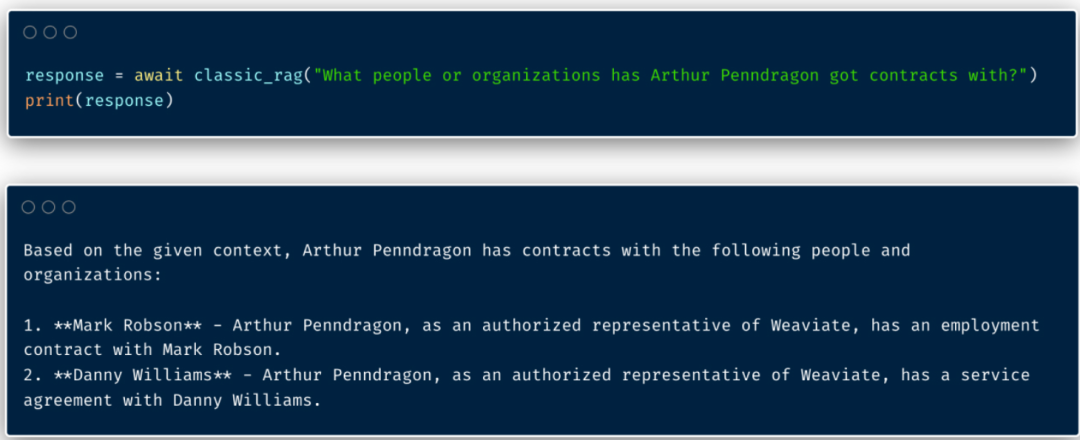
传统RAG的局限性
在大多数检索任务中,数据之间的“关系”可能并不那么重要。但以合同为例,如果能编码合同之间的关系,将会非常有价值。例如,对于检索到的某份合同,我们可以知道它的作者,但并不知道作者是否还签署过其它合同。这时,我们就该进入Graph RAG的世界了。
GraphRAG技术
GraphRAG是一个总称,泛指所有在检索阶段利用知识图谱的RAG方法。不同的方法各有不同的实现方式,核心思想是通过图结构来提升 LLM 的检索效果。其中,微软提出的GraphRAG 实现是目前最受欢迎的方法之一,其流程图如下所示: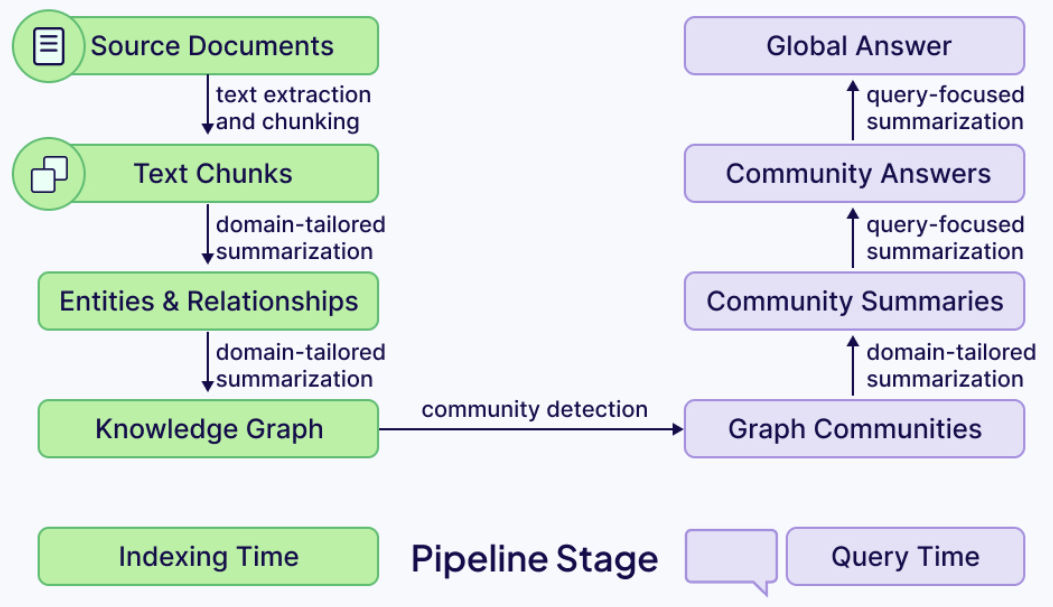 微软的GraphRAG的实现采用两阶段流程,通过LLM构建知识图谱。其中在第一阶段,从原始文档中提取实体和关系,形成图谱的基础结构。
微软的GraphRAG的实现采用两阶段流程,通过LLM构建知识图谱。其中在第一阶段,从原始文档中提取实体和关系,形成图谱的基础结构。
GraphRAG增强RAG能力
微软 GraphRAG 的亮点在于,构建完知识图谱后,它能识别图中的cluster,并为相互关联的实体群生成特定领域的摘要。这种分层方法将原始文本中的零散信息整合为结构化的实体、关系,从而形成更加有机、全面的知识表达。
这些实体、关系级别的摘要可以在用户查询时作为参考信息提供给LLM。结构化的图谱也支持多种检索方式,例如将图搜索和向量搜索结合,从而大幅增强信息检索体验。
GraphRAG代码实现
为展示这一概念,我们开发了一个简化的python代码程序:https://github.com/neo4j-contrib/ms-graphrag-neo4j/tree/main/src/ms_graphrag_neo4j,它封装了所有提示语,避免代码过于复杂。虽然它只是一个概念验证(PoC),但足以演示GraphRAG核心机制。
实体、关系提取
使用与朴素RAG相同的模拟数据:https://huggingface.co/datasets/weaviate/agents/viewer/query-agent-financial-contracts,该数据包含 100 份合同。GraphRAG 的关键配置之一是指定要提取和摘要的实体类型,它将直接影响后续图谱的构建。由于关注的是合同,所以这里选择提取 人名(Person)、组织(Organization) 和 地点(Location)。
allowed_entities = ["Person", "Organization", "Location"]
await ms_graph.extract_nodes_and_rels(texts, allowed_entities)
提取完成后,相关实体关系展示如下图所示: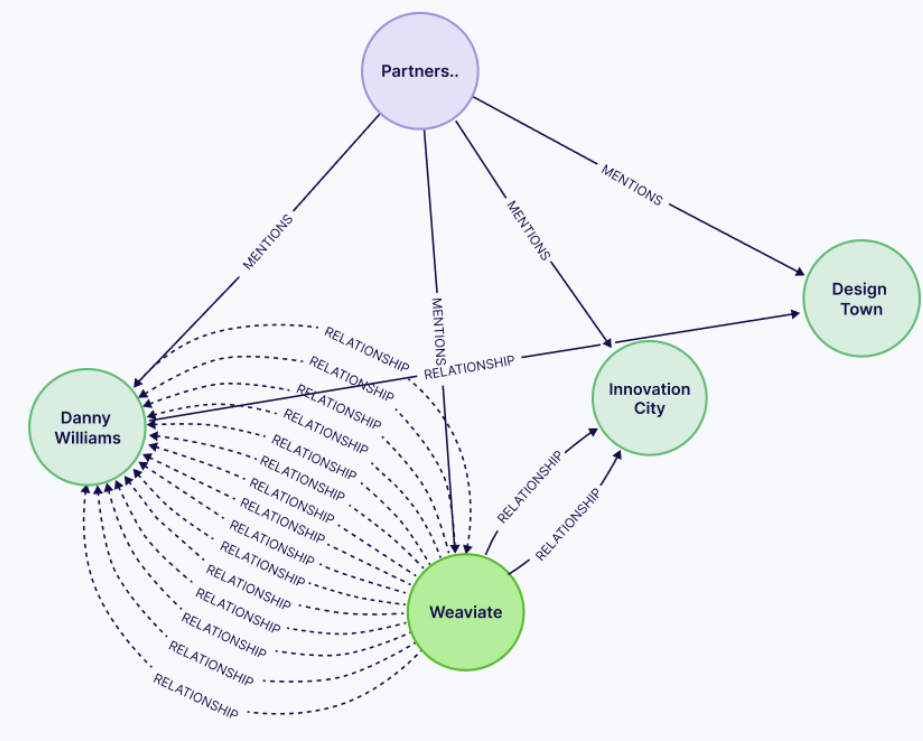 图中紫色节点是合同文本及元数据,绿色节点为提取出的实体。每个实体都有名称与描述,实体之间可以存在多重关系。
图中紫色节点是合同文本及元数据,绿色节点为提取出的实体。每个实体都有名称与描述,实体之间可以存在多重关系。
摘要生成
某个实体可能在多份合同中出现,因此会有多个描述。同理,实体之间若在多个段落中出现,也可能有多个关系。为了整合信息,使用 LLM 对实体和关系进行摘要,消除冗余与重复。
await ms_graph.summarize_nodes_and_rels()
得到的摘要结果如下: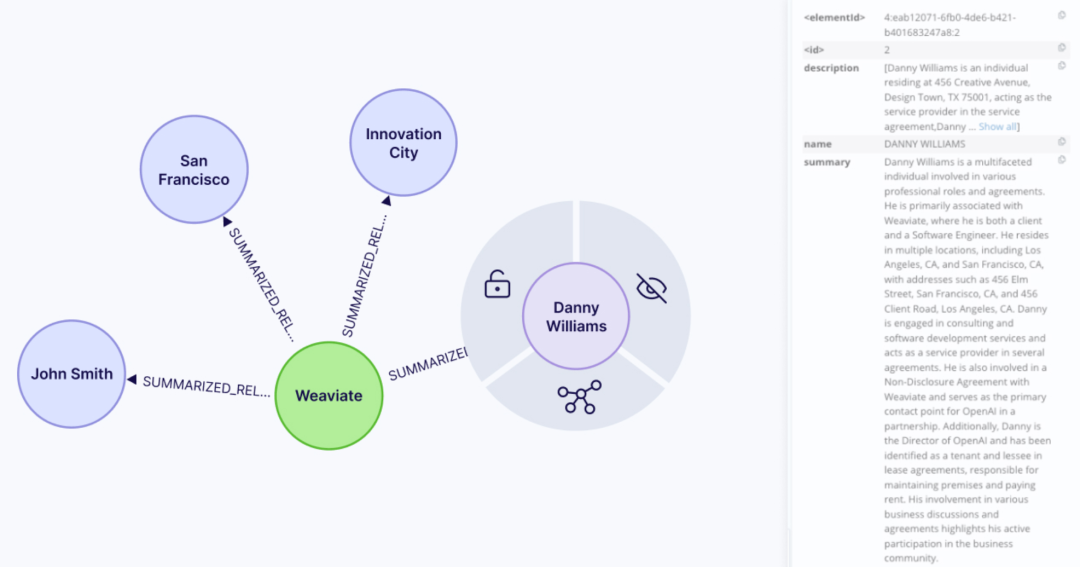 现在,每对实体之间只保留一条整合后的关系,内容是所有来源信息的摘要。同时,每个实体也拥有一个综合的描述,例如图中Danny Williams 的完整档案信息。
现在,每对实体之间只保留一条整合后的关系,内容是所有来源信息的摘要。同时,每个实体也拥有一个综合的描述,例如图中Danny Williams 的完整档案信息。
在索引流程的最后,使用如Leiden算法这样的图算法识别网络中的社区结构。这些社区由紧密互联的节点组成,彼此之间连接更密切。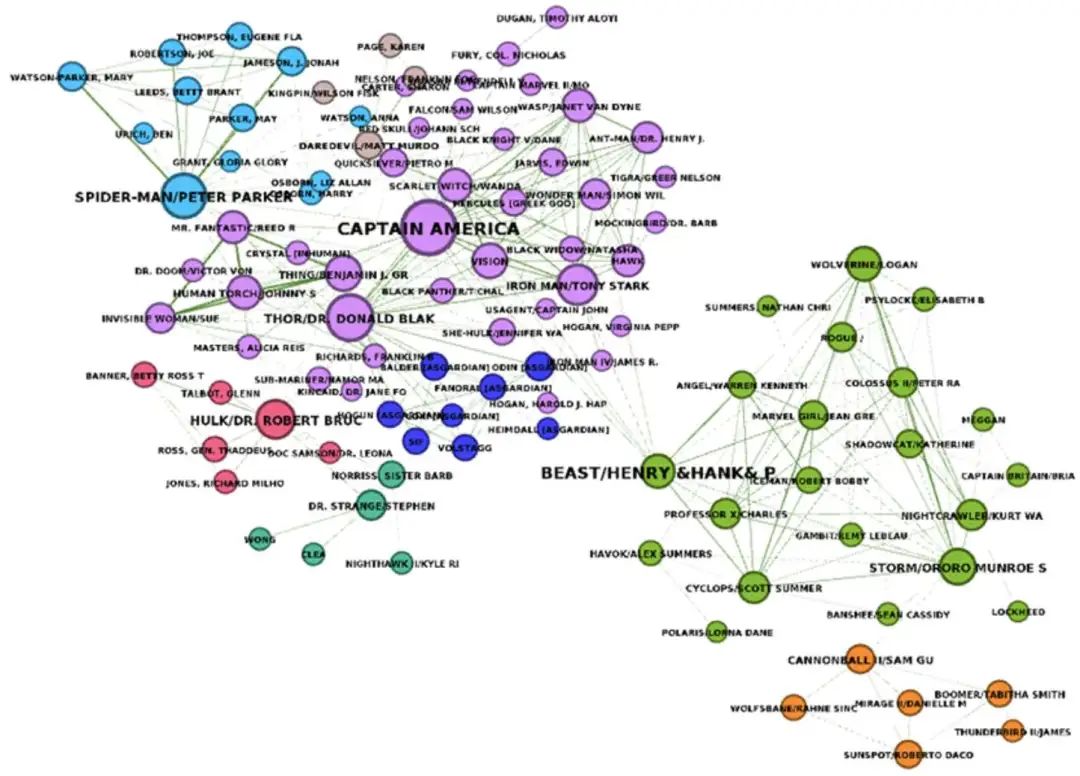 不同颜色表示不同的社区,从图中可以看出节点之间自然聚集形成群组。
不同颜色表示不同的社区,从图中可以看出节点之间自然聚集形成群组。
MS GraphRAG 的核心理念是:生成跨多个关系与实体的高层摘要,从而构建一个整体视图,将碎片化的信息整合为连贯、深入的洞察。
await ms_graph.summarize_communities()
知识图谱构建完毕后,接下来是检索阶段。
GraphRAG检索
从知识图谱中检索信息有多种方式。微软 GraphRAG 提供了三种检索策略:
- 全局搜索(Global Search)
- 局部搜索(Local Search)
- 漂移搜索(DRIFT Search)
其中局部搜索是将 AI 提取出的知识图谱与原始文档的相关文本段融合生成回答。它非常适合回答需要深入理解特定实体的问题(例如:“薰衣草精油的疗效有哪些?”)。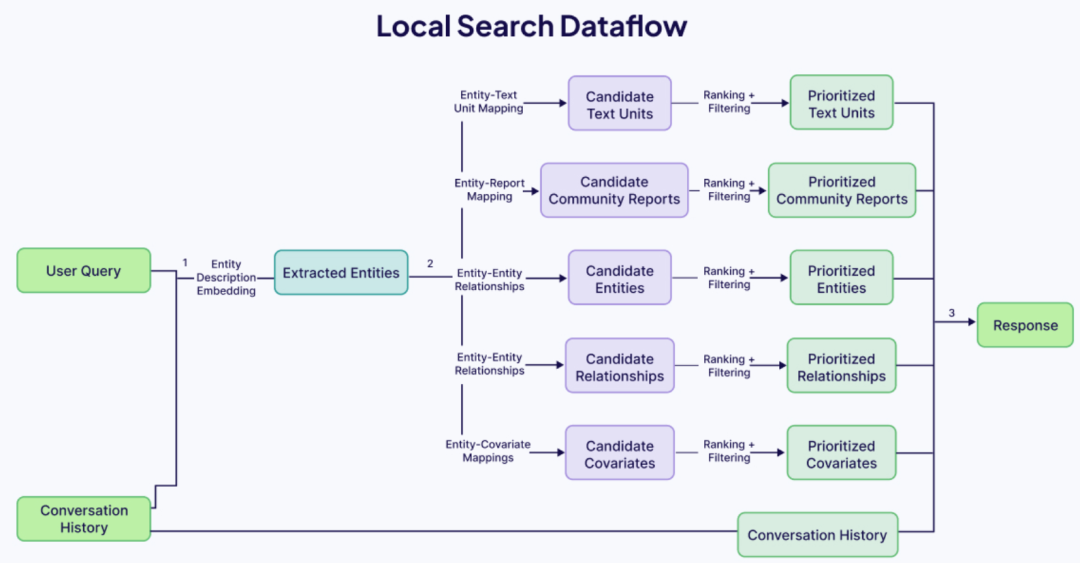 局部搜索通过以下步骤进行:
局部搜索通过以下步骤进行:
-
「实体识别」:识别出问题中涉及的关键实体。
-
「图谱导航」:这些实体成为图谱的切入点,系统可进一步:
-
- 查找关联实体;
- 提取属性和关系;
- 引入社区摘要等上下文信息。
将实体索引至向量数据库后,构建结合向量数据库和图数据库的检索流程。先通过向量数据库的语义搜索定位相关实体,再使用Neo4j遍历图谱,探索实体间关系与更广泛的上下文网络。此混合方法融合了语义理解与结构关系,实现更深层的信息检索。
retriever = WeaviateNeo4jRetriever(
driver=driver,
client=client,
collection="Entities",
id_property_external="entity_id",
id_property_neo4j="name",
retrieval_query=retrieval_query
)
首先从向量数据库查询出与用户问题最相关的实体,并将实体ID映射到Neo4j图谱中对应的节点。接下来,系统通过Cypher查询在图谱中遍历邻接关系,提取相关上下文。将向量语义搜索能力和Neo4j的关系导向结构相结合,那么就构建了一个既能理解数据内容又能理解数据连接的检索系统。
该查询整合了来自不同实体的文本、社区摘要、实体关系与实体自身的描述:
retrieval_query = """
WITH collect(node) as nodes
WITH collect {
UNWIND nodes as n
MATCH (n)<-[:MENTIONS]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT 3
} AS text_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY*]->(c:__Community__)
WHERE c.summary IS NOT NULL
WITH c, c.rating as rank
RETURN c.summary
ORDER BY rank DESC
LIMIT 3
} AS report_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[r:SUMMARIZED_RELATIONSHIP]-(m)
WHERE m IN nodes
RETURN r.summary AS descriptionText
LIMIT 3
} as insideRels,
collect {
UNWIND nodes as n
RETURN n.summary AS descriptionText
} as entities
RETURN {Chunks: text_mapping, Reports: report_mapping,
Relationships: insideRels,
Entities: entities} AS output
"""
查询结果可能如下(为模拟数据):
Weaviate 是一家根据加利福尼亚州和特拉华州法律注册的公司,主要办公地点位于旧金山,在“创新大道 123”与“科技巷 123”等地设有分支。业务范围包括咨询、软件开发、数据分析、云存储、技术支持和项目管理服务。同时积极参与 AI 解决方案及数据处理技术的开发合作,为合作项目提供资源与专业支持。
...
GraphRAG局限性
与传统基于文本块的 RAG 不同,GraphRAG 提供了更丰富的实体与社区级描述。但它的摘要依赖静态的 LLM 生成,若新增数据则需重新索引,代价高昂。
相比之下,传统 RAG 新增数据时无需重新索引,更高效。此外,若某些实体关联过多节点,可能导致可扩展性问题。因此需要对高度连接的通用实体类型进行过滤,以避免结果失真。此外,「图谱构建和摘要过程虽然提高了细节质量,但维护实时性的难度也随之增加」。
总结
传统RAG技术是简单而有效的起点,尤其当数据结构良好、相对独立时表现出色。而 Graph RAG 进一步理解数据之间的关系和背景,在处理合同、科研文献、组织记录等信息关联密切的数据时具有更强表现。「结合这两种方法构建混合系统,可以兼顾语义相似度与结构洞察,为用户提供更准确、有深度的回答」。无论是初学者还是高级开发者,选择合适的策略首先要理解你手头的数据。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









