






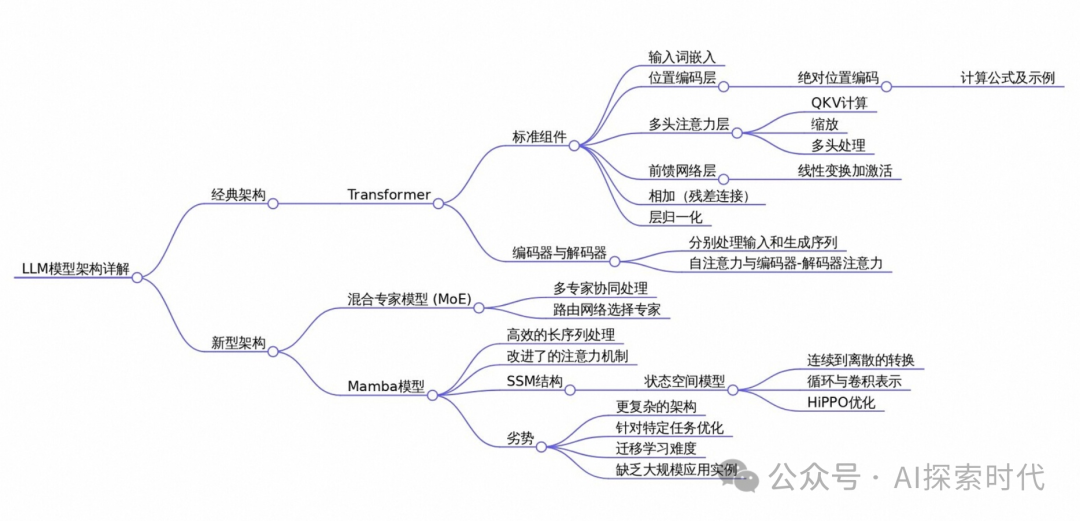
“ 不同的架构,适合不同的任务 ”
很多人对人工智能以及大模型都有一定的误解,那就是弄不明白其中各种专业名词,以及关系。甚至很多人认为大模型就是人工智能,人工智能就是大模型。
也有人认为只有transformer架构的才是大模型,因此,今天就来了解一下模型的架构。
大模型的架构及优缺点
首先,人工智能(AI)有多种实现方式,而机器学习是其中的一种;而基于机器学习又延伸出了深度学习,深度学习的思想就是分层,通过多个层的叠加实现对数据的分级表达。
而神经网络又是深度学习的一种表现形式,是由模仿人脑神经元的机制而得名,又由于多层的神经网络具有庞大的参数,因此叫做大模型(庞大参数量的机器学习(神经网络)模型)。
所以,大模型的核心是层次堆叠;因此,为了实现这种效果就有了多种神经网络的大模型架构。
大模型的常用架构主要包括Transformer,BERT,GPT,T5等;每种架构都有其独特的设计理念和应用场景;以下是对这些架构的详细介绍以及它们的优缺点分析。
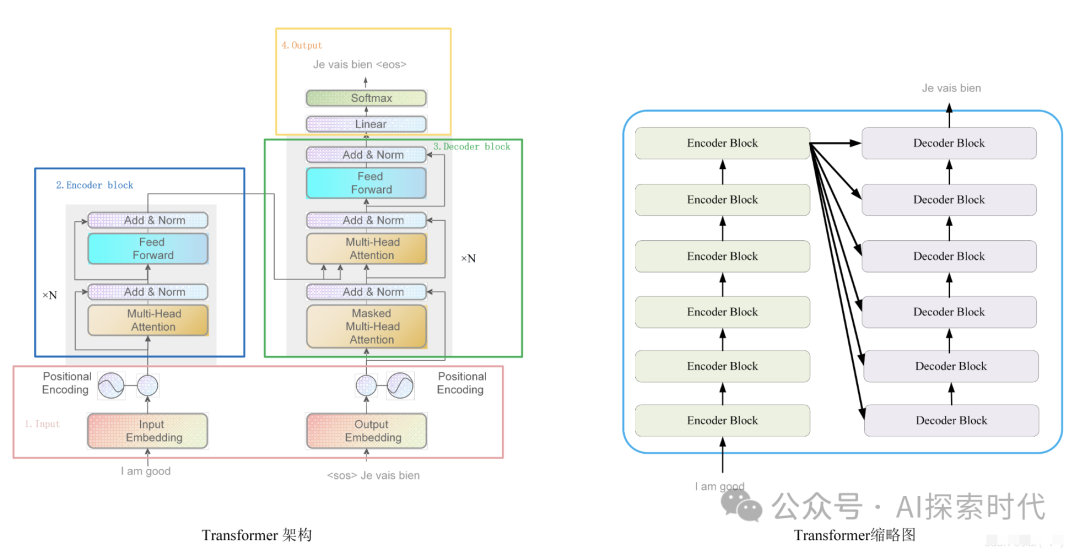
_Transformer架构_
简介
Transformer是目前大模型的主流架构,由Vaswani等人于2017年提出。它使用了注意力机制替代了传统的RNN和LSTM,能够更好的捕捉长距离依赖关系。
关键组件
自注意力机制:计算序列中各元素之间的相关性,生成每个元素的加权表示。
多头注意力机制:将注意力机制并行化处理,提高模型的表示能力
位置编码:由于模型本身不具备顺序信息,位置编码用于为序列添加位置信息
应用
Transformer本身用于各种自然语言处理认为,如机器翻译,文本分类等。
优点:模型可以并行处理序列,训练效率高,能够很好的捕捉长距离依赖。
缺点:在处理长序列时,计算复杂度高,内存占用大
BERT(Bidirectional Encoder Representations from Transformers)
简介
BERT是一种双向Transformer架构,擅长处理自然语言理解认为。它通过遮盖语言模型,和下一句预测进行训练。
特点
双向性允许BERT同时考虑左侧和右侧的上下文,增强了理解能力。
应用
情感分析,问答系统,文本分类,命名体识别等
优缺点
优点:双向编码器能够更好的理解上下文,尤其适合理解复杂的语言现象
缺点:生成能力较弱,主要适用于理解认为;模型计算成本较高
GPT(Generative Pretrained Transformer)
简介
GPT是一种基于Transformer的自回归模型,专注于文本生成任务,与BERT不同,GPT是单向的,即只使用过去的上下文来预测当前的单词。
关键特点
自回归生成:依次预测下一个单词,适合文本生成任务
Transformer解码器:采用Transformer架构中的解码器部分
应用
对话系统,文本生成,文章撰写,翻译等
优缺点
优点:生成文本时能保持一致性和流畅性,适用于多种生成任务
缺点:由于单向性,在理解复杂等上下文时效果不如BERT
T5(Text-To-Text Transfer Transformer)
简介
T5是一种统一的文本到文本的模型架构,可以将所有任务都转换为文本生成任务;例如翻译任务中的输入是原文,输出是译文;文本分类任务中的输入是句子,输出是类别标签
关键特点
统一框架:所有任务都表示为文本转换任务,简化了模型设计和训练流程
预训练目标:使用多任务预训练,包括翻译,摘要生成等

应用
翻译,摘要生成,文本分类,多任务学习等
优缺点
优点:统一框架便于跨任务的知识迁移,模型更具有通用性
缺点:对生成任务过于依赖,可能不适合一些特定的理解任务
基于Transformer架构的文本处理模型开发的人工智能机器人:
DistilBERT
简介
DistilBERT是BERT的精简版,通过蒸馏技术减小模型规模,同时保留了大部分性能
关键特点
模型蒸馏:通过从大模型中学习,精简模型参数,减少计算需求
应用
与BERT类似的任务,但适用于计算资源有限的场景
优缺点
优点:计算成本低,适合移动设备或实时应用
缺点:精度略低于完整的BERT模型
给大家推荐一本书,以下是一本学习大模型架构的书,里面详细介绍了大模型的核心架构以及实现原理,感兴趣的朋友可以点击购买:
不同架构的优缺点对比
-
BERT vs. GPT:BERT 适合理解任务,如文本分类、问答系统;GPT 适合生成任务,如文本生成、对话系统。BERT 的双向编码使其在理解上下文时更强,而 GPT 在生成流畅自然的文本时更有优势。
-
Transformer vs. RNN/LSTM:Transformer 可以并行处理,提高了训练效率,且更好地捕捉长距离依赖,但在处理超长序列时计算复杂度较高。RNN/LSTM 则天然适合处理序列数据,但容易出现梯度消失问题。
-
T5 vs. BERT/GPT:T5 的统一框架使其在多任务学习中表现出色,但在专门的理解或生成任务中,可能不如专门设计的 BERT 或 GPT。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
⑤AI+零售:智能推荐系统和库存管理优化了用户体验和运营成本。AI可以分析用户行为,提供个性化商品推荐,同时优化库存,减少浪费。
⑥AI+交通:自动驾驶和智能交通管理提升了交通安全和效率。AI技术可以实现车辆自动驾驶,并优化交通信号控制,减少拥堵。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题

如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









