






01引言
智能体架构是定义AI智能体各组件组织与交互方式的蓝图,使其能够感知环境、进行推理并采取行动。本质上,它就像智能体的数字大脑——通过整合"眼睛"(传感器)、“大脑”(决策逻辑)和"手"(执行器)来处理信息并执行动作。
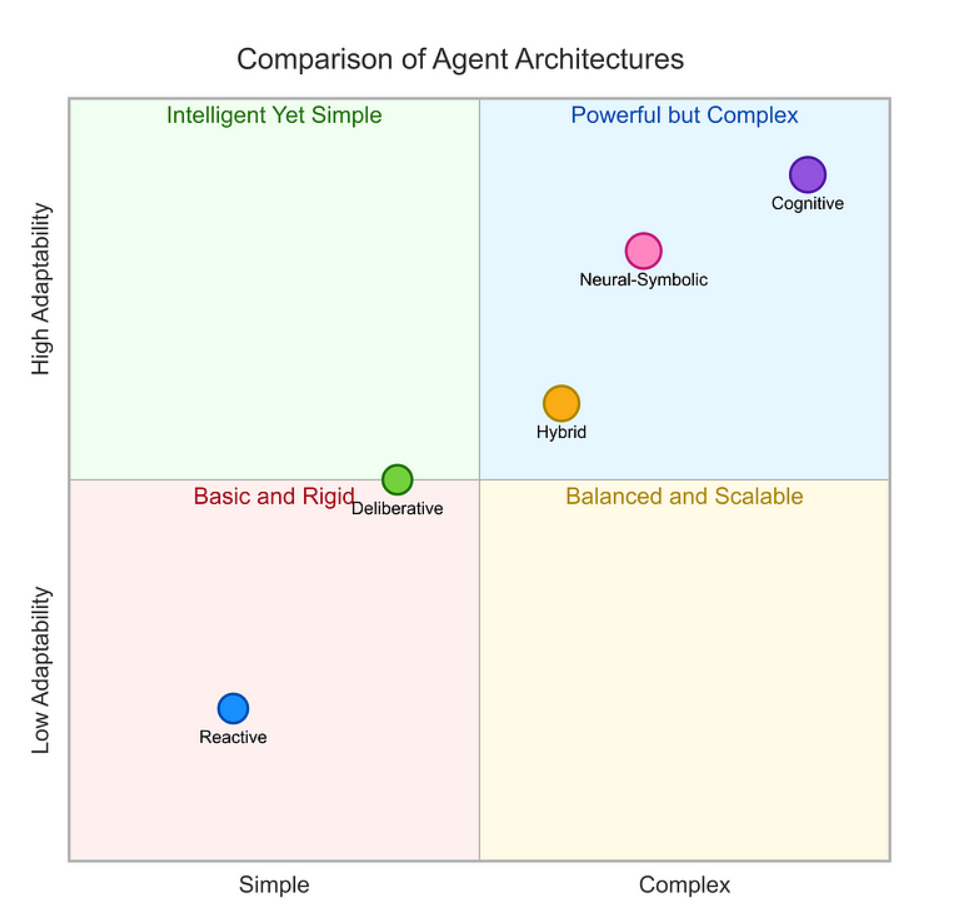
选择正确的架构对构建高效AI智能体至关重要。该架构决定了智能体的响应速度、处理复杂任务的能力、学习适应性及资源需求等核心能力。例如,基于简单反射的智能体可能擅长实时反应但缺乏长期规划能力,而慎思型智能体虽能处理复杂目标却需更高计算成本。理解这些权衡关系,工程师才能为特定应用领域匹配最佳架构,实现性能与可靠性的最优化。
02 Agents 架构
智能体架构主要分为以下几类:
- 反应式(Reactive)
- 慎思式(Deliberative)
- 混合式(Hybrid)
- 神经符号式(Neural-Symbolic)
- 认知式(Cognitive)
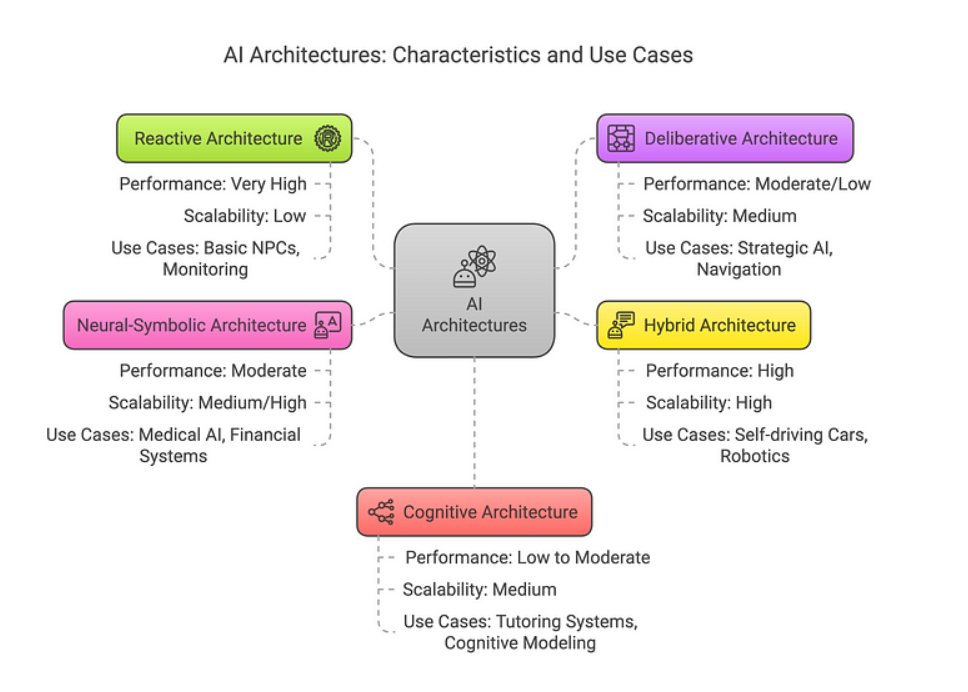
接着我们分章节来逐步介绍不同的架构。
03Reactive Architectures
最基础的AI智能体设计模式称为ReAct(推理-行动循环)。该模式下,大语言模型(LLM)首先分析当前状况并确定待执行动作,随后在环境中执行该动作并获取反馈观察结果。LLM处理观察信息后重新评估下一步行动,如此循环迭代直至判定任务完成。
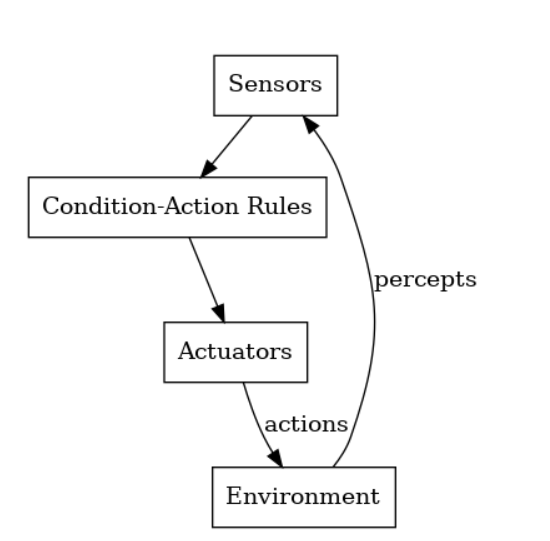
反应式架构非常适合需要瞬间决策且响应可预测、明确定义的领域。典型的例子包括机器人技术和游戏:如一台机器人吸尘器或无人机,在传感器检测到障碍物后立即反应避让;或者视频游戏中的非玩家角色(NPC),它们会根据预设脚本对玩家的动作做出即时反应(比如,敌方守卫在玩家进入视线时立即攻击)。
在工业环境中,简单的监控智能体可能会在传感器超出范围时触发报警或关闭设备。这类智能体在实时控制系统中表现出色,但由于缺乏全局规划,它们通常用于相对简单或受严格限制的任务中,在这些任务中可以预先定义所有情况的规则。
这类架构在实时控制系统中表现突出,但由于缺乏全局规划能力,仅适用于规则可预先明确定义的简单或强约束任务。
- 样例实现:
from dotenv import load_dotenvfrom openai import OpenAI_ = load_dotenv()client = OpenAI()
class Agent: def __init__(self, system=""): self.system = system self.messages = [] if self.system: self.messages.append({"role": "system", "content": system}) def __call__(self, message): self.messages.append({"role": "user", "content": message}) result = self.execute() self.messages.append({"role": "assistant", "content": result}) return result def execute(self): completion = client.chat.completions.create( model="gpt-4o", temperature=0, messages=self.messages) return completion.choices[0].message.content
接下来,我们需要一个系统提示,为我们的智能体提供指令,让它使用另外两个工具来完成任务:一个用于数学计算,另一个用于查找给定犬种的平均体重。
import openaiimport reimport httpximport osprompt = """You run in a loop of Thought, Action, PAUSE, Observation.At the end of the loop you output an AnswerUse Thought to describe your thoughts about the question you have been asked.Use Action to run one of the actions available to you - then return PAUSE.Observation will be the result of running those actions.Your available actions are:calculate:e.g. calculate: 4 * 7 / 3Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessaryaverage_dog_weight:e.g. average_dog_weight: Colliereturns average weight of a dog when given the breedExample session:Question: How much does a Bulldog weigh?Thought: I should look the dogs weight using average_dog_weightAction: average_dog_weight: BulldogPAUSEYou will be called again with this:Observation: A Bulldog weights 51 lbsYou then output:Answer: A bulldog weights 51 lbs""".strip()def calculate(what): return eval(what)def average_dog_weight(name): if name in "Scottish Terrier": return("Scottish Terriers average 20 lbs") elif name in "Border Collie": return("a Border Collies average weight is 37 lbs") elif name in "Toy Poodle": return("a toy poodles average weight is 7 lbs") else: return("An average dog weights 50 lbs")known_actions = { "calculate": calculate, "average_dog_weight": average_dog_weight}prompt = """You run in a loop of Thought, Action, PAUSE, Observation.At the end of the loop you output an AnswerUse Thought to describe your thoughts about the question you have been asked.Use Action to run one of the actions available to you - then return PAUSE.Observation will be the result of running those actions.
现在我们可以通过循环运行它来构建我们的智能体,使其分多个步骤工作:
abot = Agent(prompt)def query(question, max_turns=5): i = 0 bot = Agent(prompt) next_prompt = question while i < max_turns: i += 1 result = bot(next_prompt) print(result) actions = [ action_re.match(a) for a in result.split('\n') if action_re.match(a) ] if actions: # There is an action to run action, action_input = actions[0].groups() if action not in known_actions: raise Exception("Unknown action: {}: {}".format(action, action_input)) print(" -- running {} {}".format(action, action_input)) observation = known_actions[action](action_input) print("Observation:", observation) next_prompt = "Observation: {}".format(observation) else: returnquestion = """I have 2 dogs, a border collie and a scottish terrier. \What is their combined weight"""query(question)Thought: I need to find the average weight of a Border Collie and a Scottish Terrier, then add them together to get the combined weight.Action: average_dog_weight: Border ColliePAUSE -- running average_dog_weight Border CollieObservation: a Border Collies average weight is 37 lbsAction: average_dog_weight: Scottish TerrierPAUSE -- running average_dog_weight Scottish TerrierObservation: Scottish Terriers average 20 lbsThought: Now that I have the average weights of both dogs, I can calculate their combined weight by adding them together.Action: calculate: 37 + 20PAUSE -- running calculate 37 + 20Observation: 57Answer: The combined weight of a Border Collie and a Scottish Terrier is 57 lbst
如示例所示,该智能体成功调用两种工具分别获取了边境牧羊犬和苏格兰梗的平均体重数据,并最终完成求和计算。
-
*核心优势*
-
极速响应:反应式架构决策耗时恒定,没有复杂推理开销,特别适合实时机器人控制、高频交易等毫秒级应用场景
-
设计透明:行为完全由预定义规则驱动,系统可验证性强
-
*固有局限*
-
适应性缺陷:缺乏学习与规划能力,既无法应对意外场景,也不能执行需要多步骤协同的目标型任务
-
短视行为:可能陷入局部优化(例如未配置战略逻辑的机器人会持续在小范围内循环移动)
这些局限性推动了具有内部状态存储与推理能力的进阶架构发展。研究表明,不同设计模式适用于不同任务场景。开发者无需从零构建,可直接采用针对特定问题验证过的成熟方案——例如LangGraph文档就提供了多种经过验证的多智能体架构方案。

04Deliberative Architecture
慎思型智能体是基于模型、目标驱动的智能体,其核心特征在于先推理后行动。与即时响应的反应式智能体不同,这类智能体具备前瞻能力:它们会通过内部模型评估多种可能行动方案,最终选择最优执行策略以实现目标。
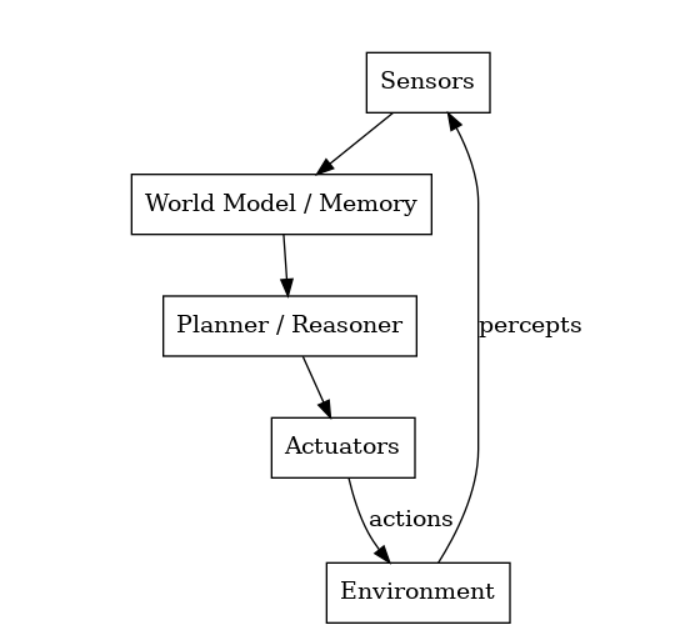
Sense → Model → Plan → Act
- 感知(Perceive):从环境中接收新的输入信息。
- 建模(Model):更新内部的世界模型(例如符号状态、语义地图)。
- 深思(Deliberate):生成可能的计划并模拟/评估它们的结果。
- 行动(Act):执行最优计划或朝着目标的下一步行动。
- 这种方式类似于国际象棋AI提前策划几步,而不是逐步反应。
伪代码实现:
# Pseudocode for a deliberative agent with goal-oriented planninginitialize_state()while True: perceive_environment(state) options = generate_options(state) # possible plans or actions best_option = evaluate_options(options) # deliberation: select best plan commit_to_plan(best_option, state) # update intentions execute_next_action(best_option) if goal_achieved(state): break
在这个循环中,generate_options 会根据当前状态和目标生成可能的行动或计划,evaluate_options 会应用推理或规划(例如模拟结果或使用启发式方法选择最佳方案),而智能体则逐步执行这些行动,并在必要时进行重新评估。这反映了一个深思熟虑的智能体考虑未来后果并为长期目标进行优化的过程。例如,在路径规划智能体中,generate_options 可能会创建多条路线,evaluate_options 则会选择最短且安全的路径。
05 Hybrid Architecture
混合智能体架构通过结合反应式与慎思式系统,在动态环境中同时实现快速响应与智能决策。
反应层:对感知输入即时响应(如避障行为)
慎思层:基于内部模型进行目标驱动规划(如路径规划)
各层级通常并行运作,在快速反应与长期策略间实现动态平衡。
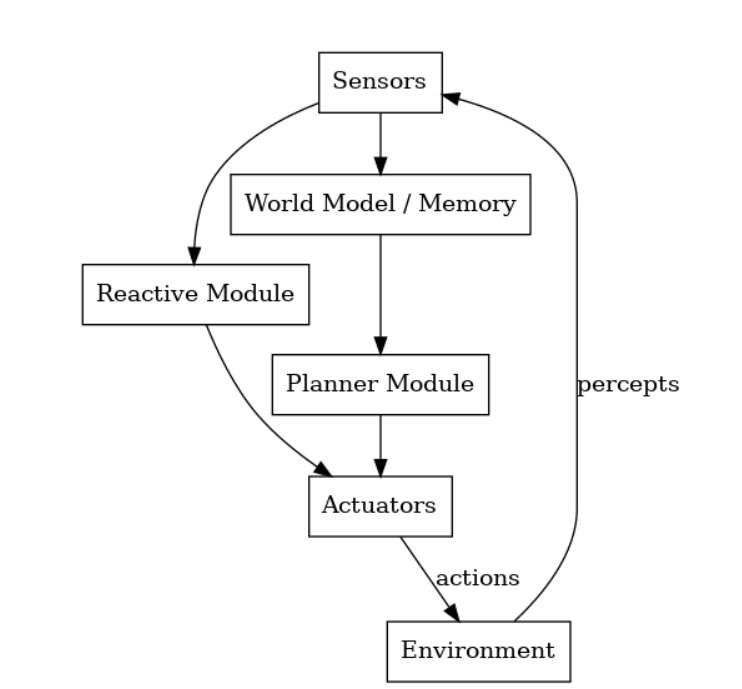
混合型智能体架构结合了反应式和深思熟虑式系统,以在动态环境中实现速度和智能的兼顾。
反应层:即时响应感知输入(例如,避障)。
深思熟虑层:利用内部模型进行目标驱动的规划(例如,路径规划)。
这些层通常协同运行,甚至同时作用,以在快速反应和长远策略之间取得平衡。
样例实现:
percept = sense_environment()if is_urgent(percept): action = reactive_module(percept) # Quick reflexelse: update(world_model, percept) action = deliberative_planner(world_model, current_goal)execute(action)
这种逻辑确保了安全和效率,能够适应瞬时威胁和长期目标。**
**
06Neural-Symbolic Architecture
神经符号架构(Neural-Symbolic)将神经网络(数据学习)与符号化人工智能(规则推理)相结合,使智能体既能感知复杂环境,又能进行逻辑推演。
-
神经网络:擅长模式识别(如图像、语音)
-
符号系统:精于逻辑推理与可解释性
-
融合目标:通过神经感知与符号理解的协同,实现兼具智能性与可解释性的决策
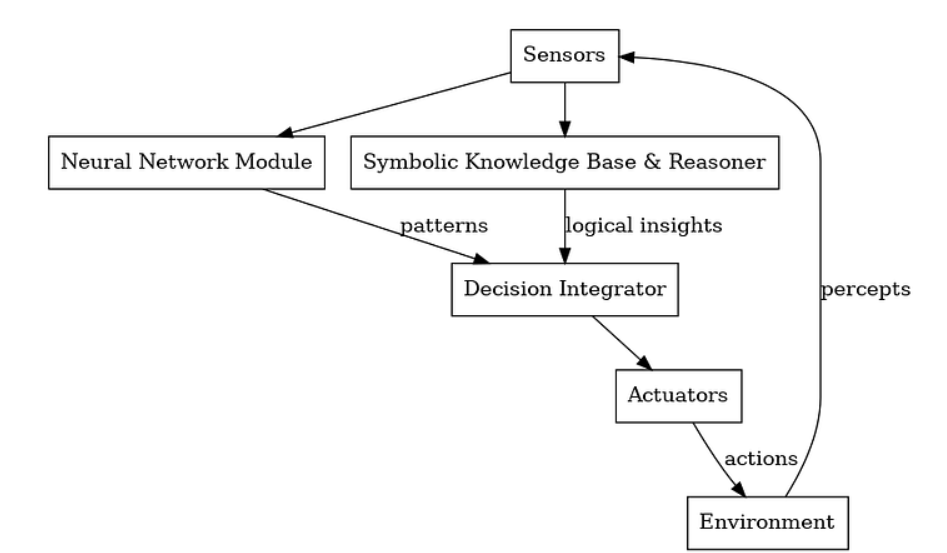
神经符号架构主要有两种集成策略:
- 串行式:神经网络模块处理原始输入(如目标检测),符号模块对解析后的输出进行推理。
- 并行式:神经模块与符号模块同步工作,由决策模块融合双方输出。
伪代码实现:
percept = get_sensor_data()nn_insights = neural_module.predict(percept) # Perception (e.g., detect anomaly)sym_facts = symbolic_module.update(percept) # Translate data to logical factssym_conclusions = symbolic_module.infer(sym_facts) # Apply domain knowledgedecision = policy_module.decide(nn_insights, sym_conclusions)execute(decision)
这实现了学习的见解与明确规则的结合,以指导行动。
07 Cognitive Architecture
认知架构是一种综合性框架,旨在通过将感知、记忆、推理和学习整合为统一的智能体系统,来模拟类人的通用智能。
其设计特点包括:
- 受人类认知机制启发
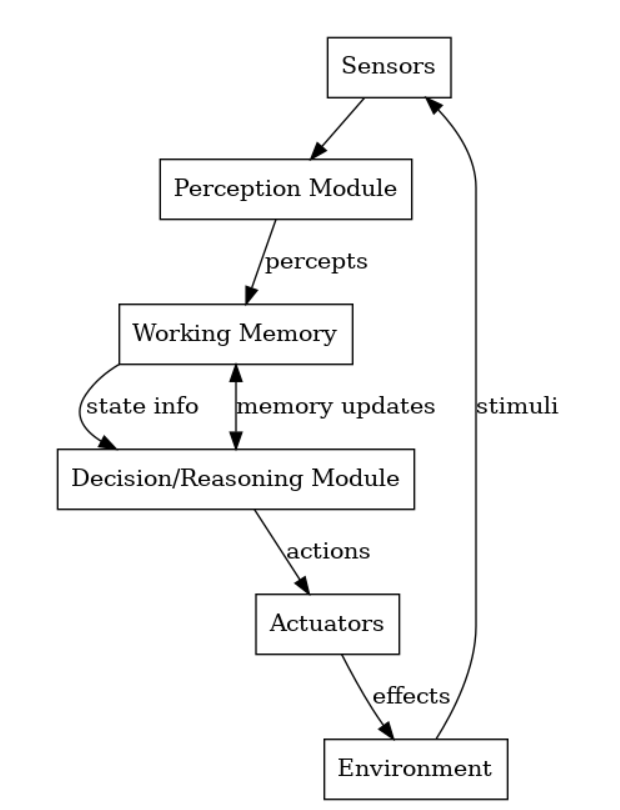
- 遵循"感知-思考-行动"循环:
- 感知环境信息
- 更新工作记忆
- 运用产生式规则进行推理决策
- 通过执行器输出动作
- 旨在打造能够学习、规划、解决问题和适应的智能体,就像人类一样。
-
SOAR 架构
1980年代为实现通用智能行为而开发
• 工作记忆:存储当前状态信息
• 产生式记忆:保存"条件-动作"规则集
• 采用通用子目标机制——遇阻时自动分解子目标
• 学习机制:运用"组块化"技术——将经验转化为新规则
• 典型应用:AI飞行员、人形机器人、决策智能体 -
ACT-R 架构
植根于认知心理学理论
• 模块化设计:包含视觉、运动、记忆等专用模块
• 各模块配备独立缓冲区处理临时工作记忆
• 通过产生式规则管理模块间数据流
• 混合架构:符号推理与亚符号机制(如记忆激活)相结合 -
*共同特征*
- 模块化设计(感知/记忆/行动模块)
- 多记忆系统:
- 陈述性记忆(事实存储)
- 程序性记忆(技能/规则)
- 情景记忆(可选,存储过往事件)
- 内置学习机制(SOAR的组块化/ACT-R的参数调优)
- 样例实现:
percept = perceive_environment()update_working_memory(percept)action = cognitive_reasoner.decide(working_memory)execute(action)
诸如SOAR和ACT-R等认知架构提供了对智能的整体建模,将感知、记忆、决策与学习有机整合。这些架构不仅用于构建智能体——更帮助我们理解人类思维的运作机制。这类系统特别适合需要持续学习、处理多样化任务,并能进行类人推理的智能体。
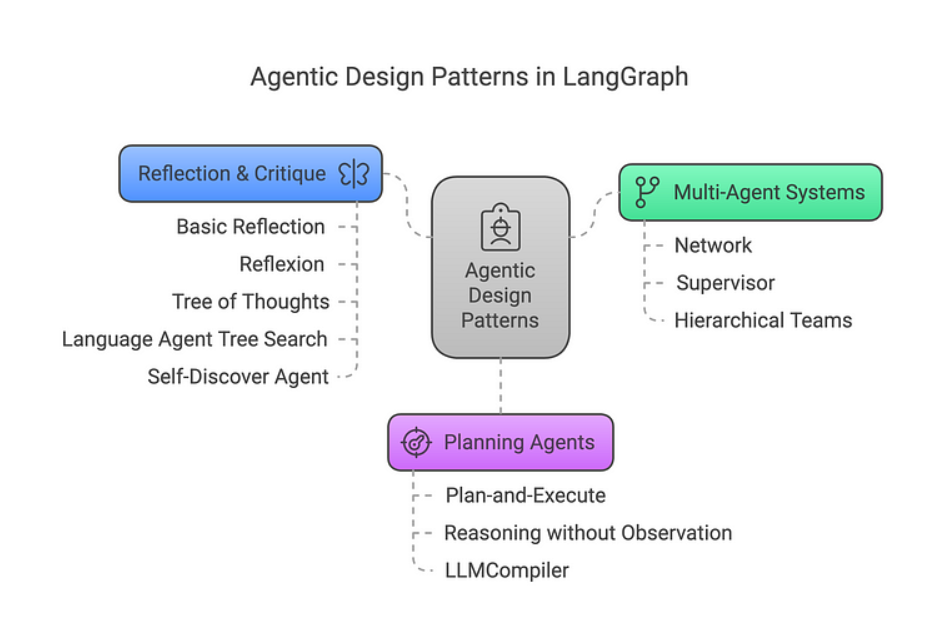
08 LangGraph中的智能体设计模式
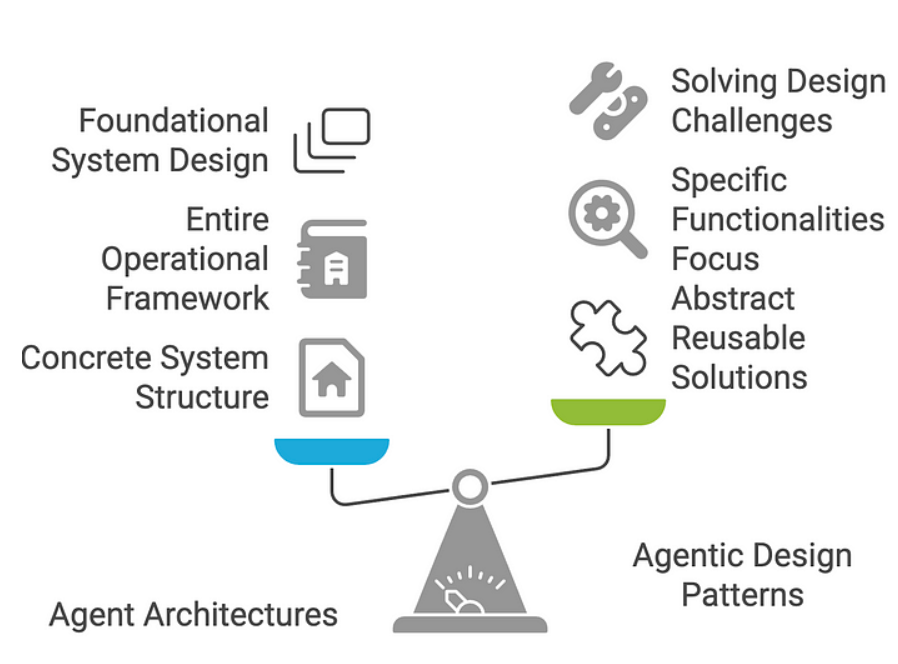
智能体架构与智能体设计模式密切相关,但两者在人工智能体开发中处于不同的抽象层级。智能体架构指的是定义智能体构建与运行方式的结构性框架或蓝图,聚焦核心组件及其组织关系——可视为智能体的"骨骼系统"。它具体规范了智能体如何感知环境、处理信息、做出决策并执行行动,本质上解决系统构建的"方法论"问题,涉及底层机制及数据/控制流。智能体设计模式则是更高层面的可复用策略模板,用于解决基于智能体系统中的特定问题。其关注点不在于智能体内部的具体实现,而在于指导跨场景适用的行为范式与交互方式——可类比为达成特定目标的"配方"。设计模式主要回答"需求定位"与"价值论证":即智能体应展现何种行为/能力,以及该设计为何适用于目标场景。****
LangGraph将这些智能体架构归纳为三大类别:
-
多智能体系统
• 协作网络:实现两个及以上智能体的任务协同
• 监督调度:利用大语言模型进行任务编排与个体调度
• 层级团队:通过嵌套式智能体团队解决问题 -
规划型智能体
• 计划执行:基础型规划与执行智能体实现
• 无观察推理:将观测存储为变量以减少重复规划
• LLM编译器:流式处理并动态执行规划器生成的任务有向无环图 -
反思与批判
• 基础反思:触发智能体对输出进行自省与修正
• 反射式改进:通过缺失/冗余细节批判引导后续步骤
• 思维树搜索:基于评分树结构对候选解决方案进行搜索
• 语言智能体树搜索:结合反思与奖励机制驱动蒙特卡洛树搜索
• 自我发现智能体:分析具备能力自认知的智能体架构
让我们深入了解下面的 Agentic 设计模式。
09Multi-agent systems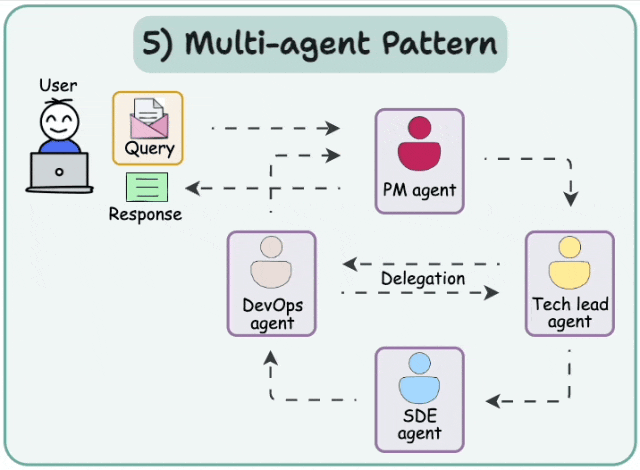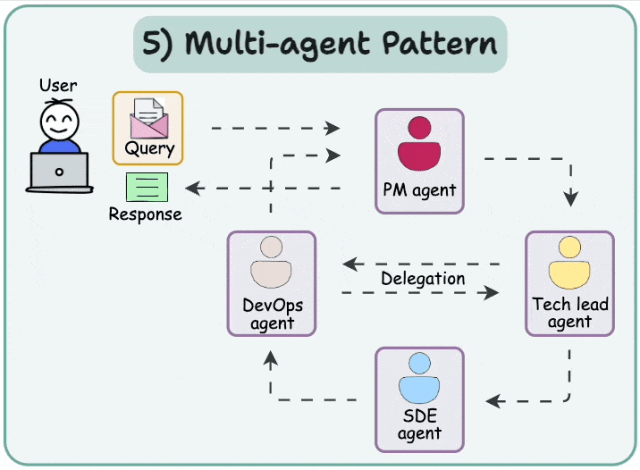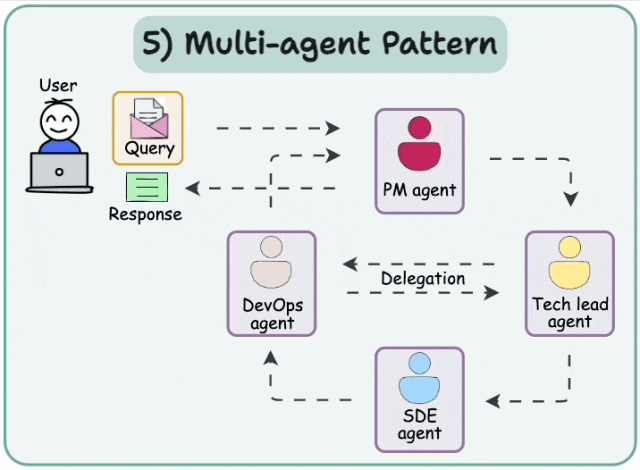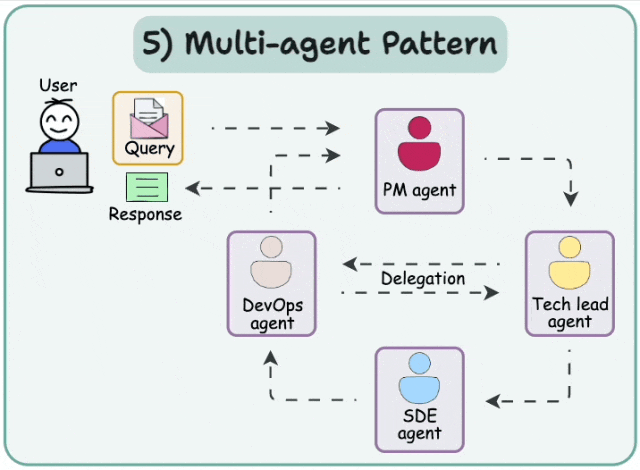
多智能体网络架构
解决复杂任务的有效方式之一是采用"分而治之"策略。通过路由机制,任务可被分配至擅长特定领域的智能体进行处理。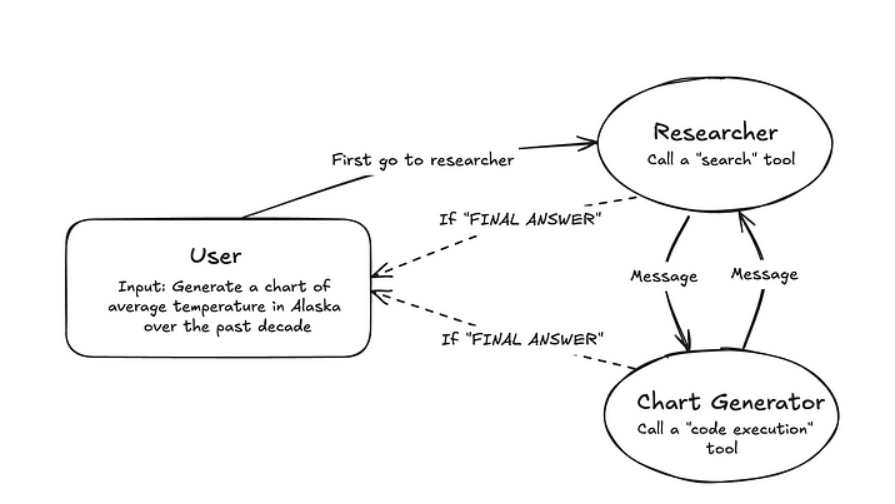 这种架构即称为多智能体网络架构。
这种架构即称为多智能体网络架构。
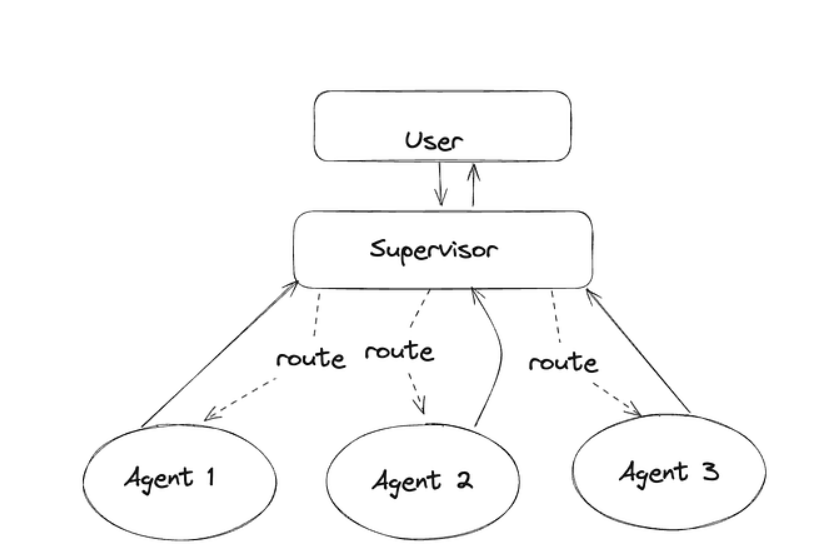
多智能体监督架构
该架构与网络架构高度相似,其核心区别在于:采用监督型智能体(而非路由机制)来协调各智能体的运作。
- 分层智能体团队架构
该架构源于一个核心思考:"当单个智能体不足以解决特定任务时,该如何应对?"其解决方案是:监督智能体不再直接协调多个独立智能体,而是统筹由多个智能体组成的协作团队。
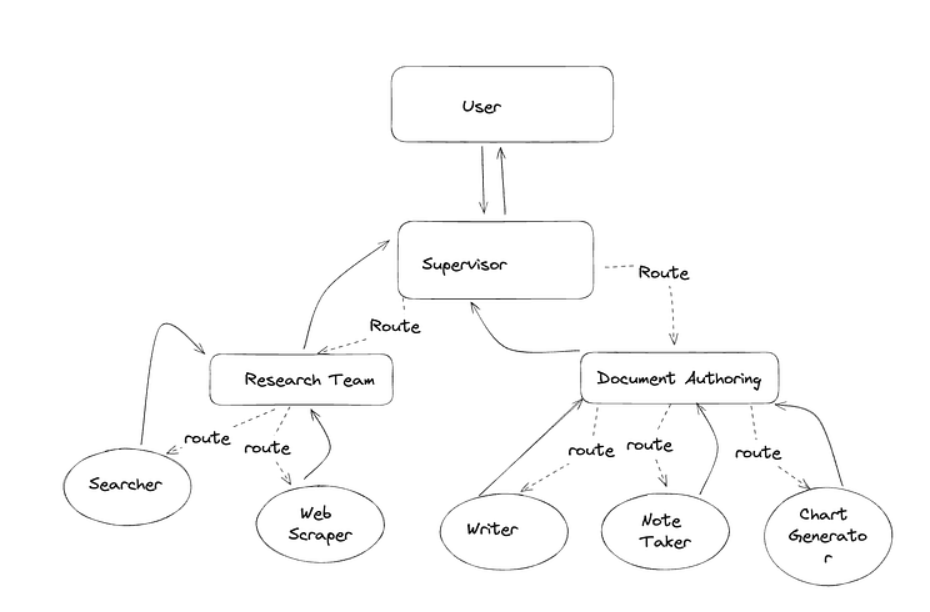
10Planning Agents
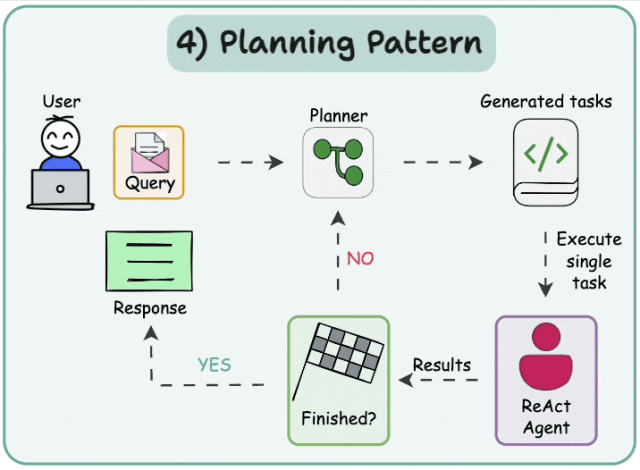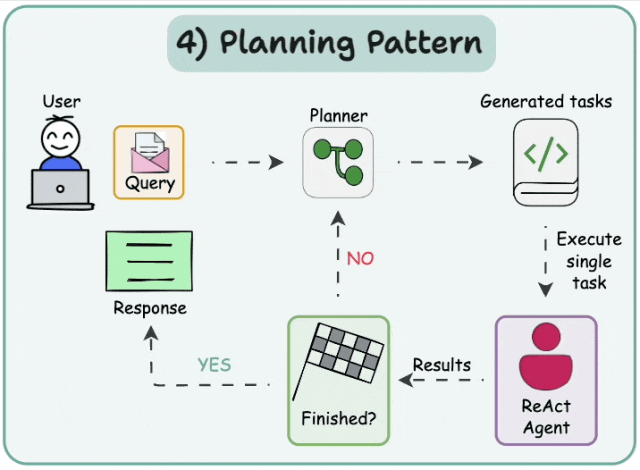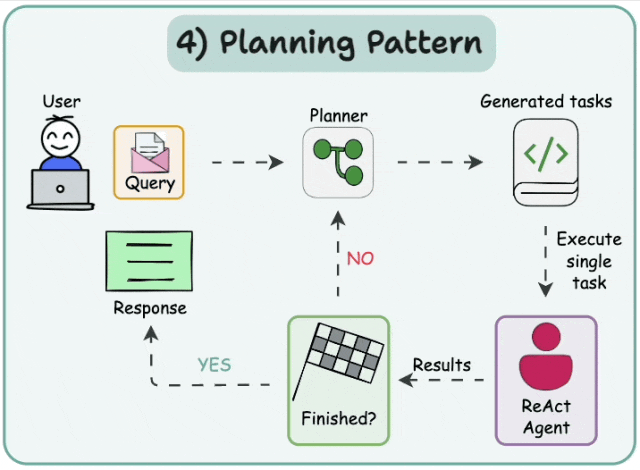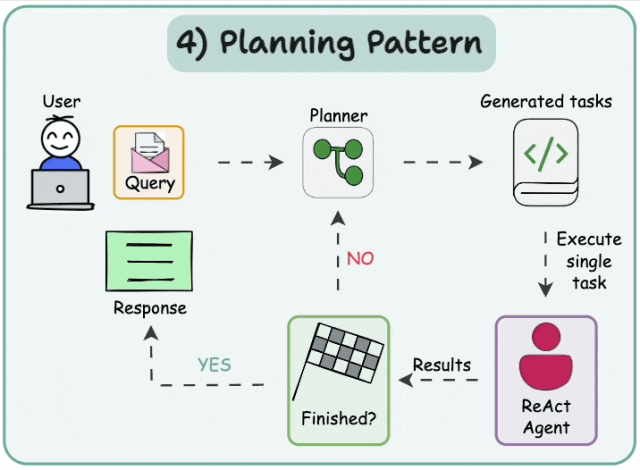
- *计划与执行*
在这种架构中,首先智能体(agent)会根据给定的任务依次生成子任务。然后,单任务(专业化的)智能体解决这些子任务,如果子任务完成,结果将被发送回规划智能体(planner agent)。规划智能体会根据结果制定不同的计划。如果任务完成,规划智能体将对用户做出响应。
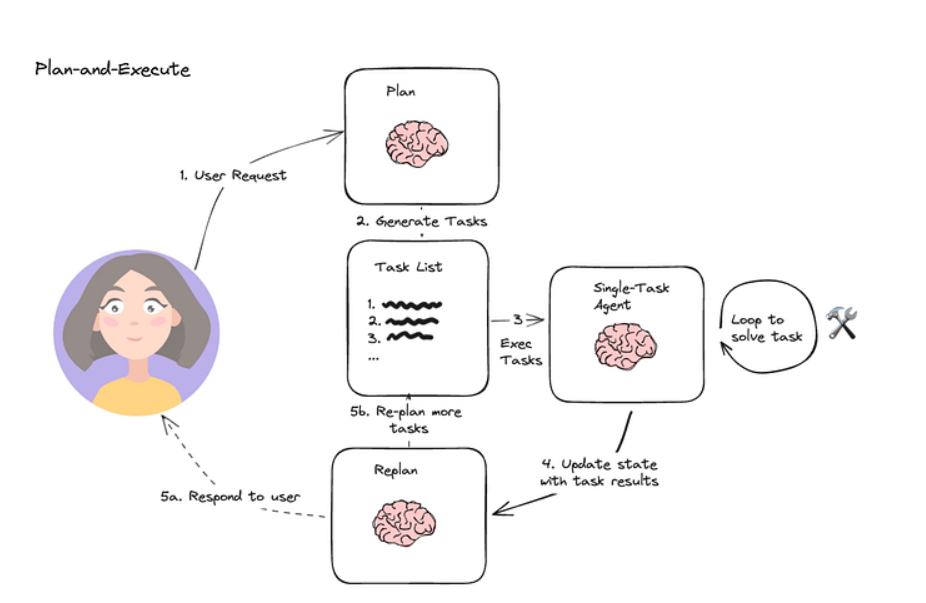
- *无观察下的推理*
在ReWOO中研究者引入了一种智能体,它将一个多步骤规划器与变量替换相结合,以优化工具的使用。这种方法与计划与执行架构非常相似。然而,与传统模型不同的是,ReWOO架构在每次行动之后没有包含观察步骤。相反,整个计划是预先制定好的,并且保持固定,不受任何后续观察的影响。
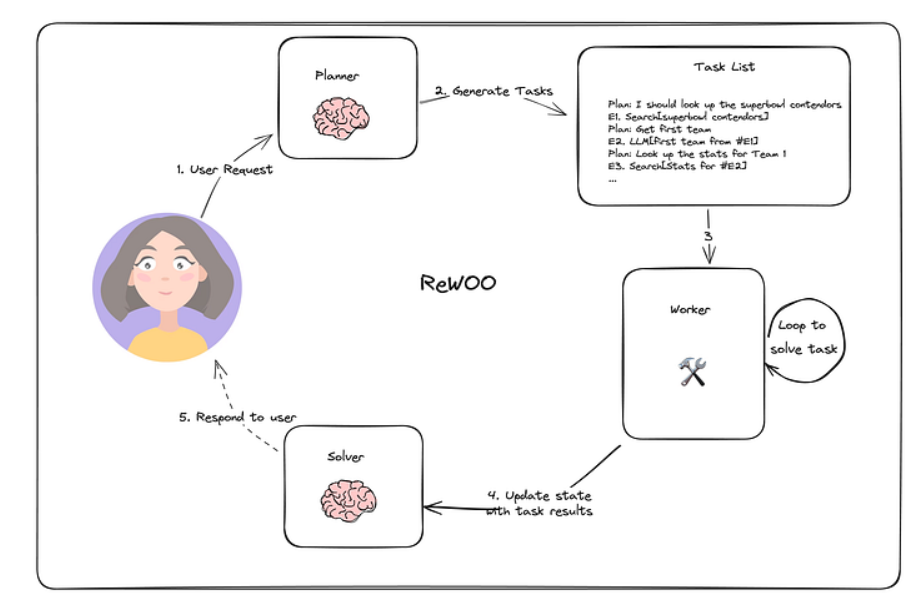
规划智能体构建了一个包含子任务的计划来解决任务,而工作智能体只需完成子任务,然后对用户做出响应。
- *LLMCompiler*
LLMCompiler是一种智能体架构,旨在通过在有向无环图(DAG)中积极执行任务来加速智能体任务的执行。它还通过减少对LLM(大型语言模型)的调用次数,节省了因冗余标记使用而产生的成本。以下是其计算图的概述:
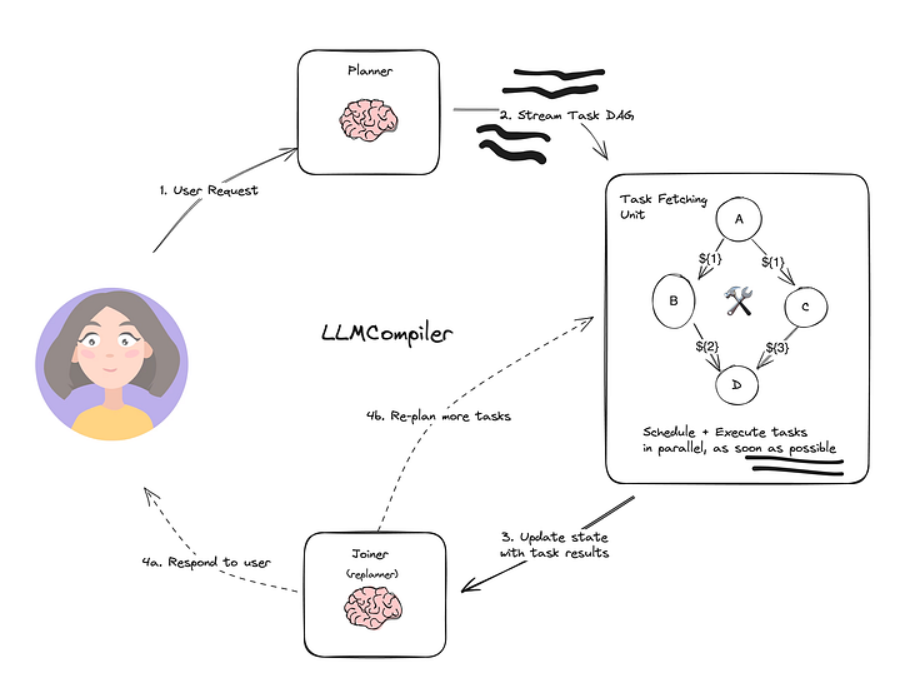
它包含3个主要组件:
- 规划器(Planner):流式传输任务的有向无环图(DAG)
- 任务获取单元(Task Fetching Unit):在任务可执行时立即调度并执行任务
- 合并器(Joiner):对用户做出响应或触发第二个计划。
11总结
在这篇博客中,我们探讨了智能体架构的演变历程,从传统的反应式和深思熟虑式模型,到更先进的混合式、神经符号化以及认知系统。随后,我们将这些基础概念与使用LangGraph的现代实现联系起来,展示了诸如规划、协作、反思和批判等强大的智能体设计模式。随着我们不断构建越来越智能和自主的系统,理解和应用这些架构原则将是解锁可扩展、模块化和目标驱动的人工智能解决方案的关键。人工智能的未来不在于孤立的智能,而在于协同工作、具有反思能力且目标明确的智能体共同解决复杂任务。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









