









RagFlow+Deepseek构建个人知识库
-
https://github.com/infiniflow/ragflow
部署RAGFlow
-
windows可以在WSL中操作,尽量跟着官方的步骤来,避免一些奇奇怪怪的错误
-
硬件先决条件
- CPU >= 4 cores
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
使用下面的命令查看docker和docker-compose的版本是否满足
docker --version docker-compose --version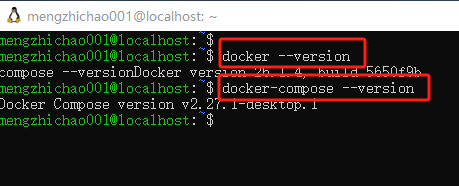
-
确保
vm.max_map_count>= 262144:检查
vm.max_map_count的值:sysctl vm.max_map_count如果不是,则将
vm.max_map_count重置为至少 262144 的值。sudo sysctl -w vm.max_map_count=262144此更改将在系统重启后重置。永久更改的话要添加或者更新**/etc/sysctl.conf**中的
vm.max_map_count值如下:vm.max_map_count=262144 -
克隆仓库
git clone https://github.com/infiniflow/ragflow.git克隆完成后会出现一个 ragflow文件夹
-
使用docker-compose启动
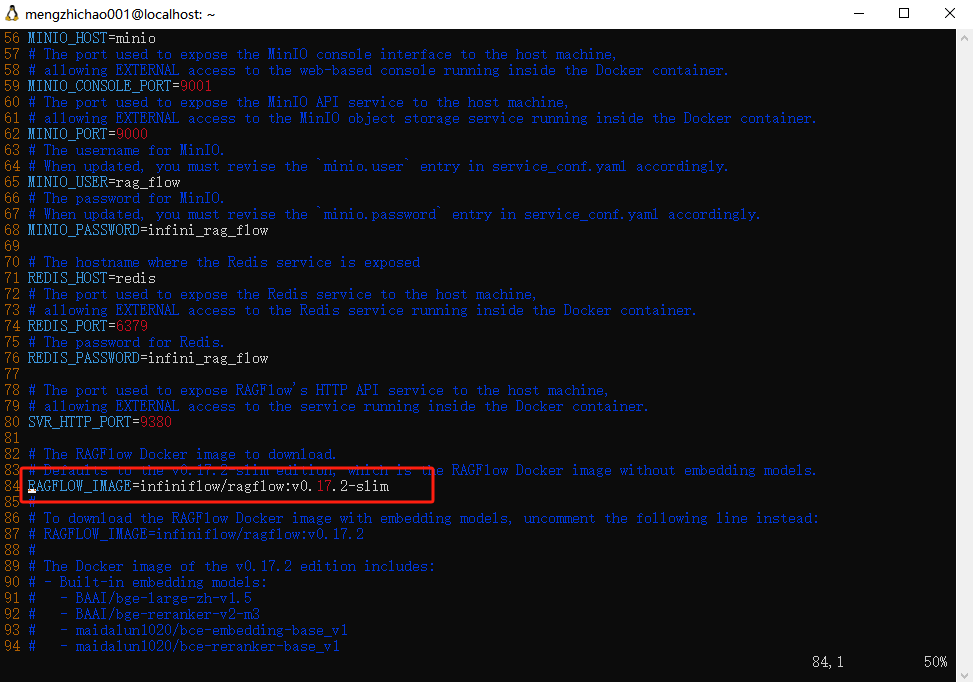
注意,ragflow 镜像有多个不同的大小,默认的是v0.17.2-slim,区别如下,主要是包不包含embedding模型的区别,我选的默认的,因为占用小,并且我后续使用调用api的方式去配置embedding模型,所以就选,默认的。
RAGFLow机械标签 镜像大小 (GB) 是否有嵌入模型 稳定版本? v0.17.2 ≈9 ✔️ Stable release v0.17.2-slim ≈2 ❌ Stable release nightly ≈9 ✔️ Unstable nightly build nightly-slim ≈2 ❌ Unstable nightly build 如果希望使用v0.17.2,可以修改docker-compose.yml文件中的版本为
v0.17.2即可vim ragflow/docker/.env
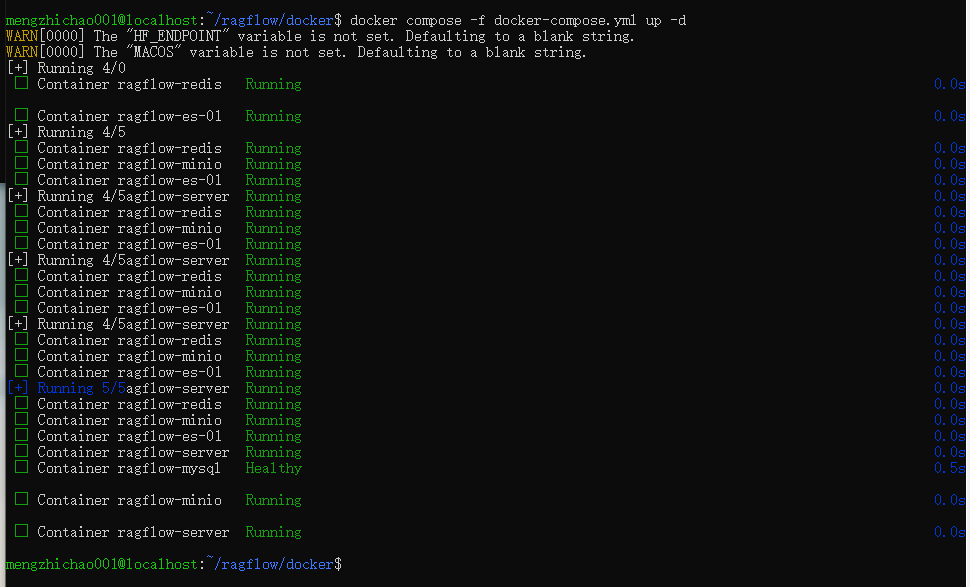
cd ragflow/docker docker compose -f docker-compose.yml up -d第一次会先拉取镜像,完成后如下
-
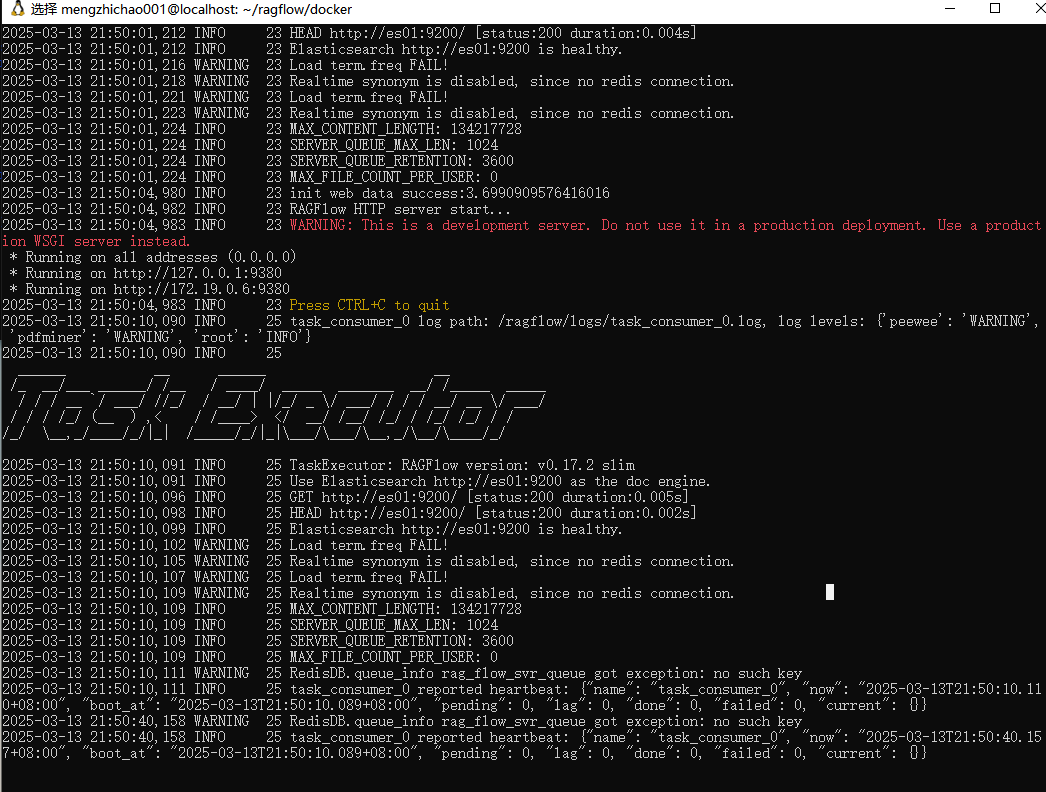
服务启动并运行后检查服务的状态
docker logs -f ragflow-server
-
登录
在本机浏览器中登录
http://127.0.0.1:80
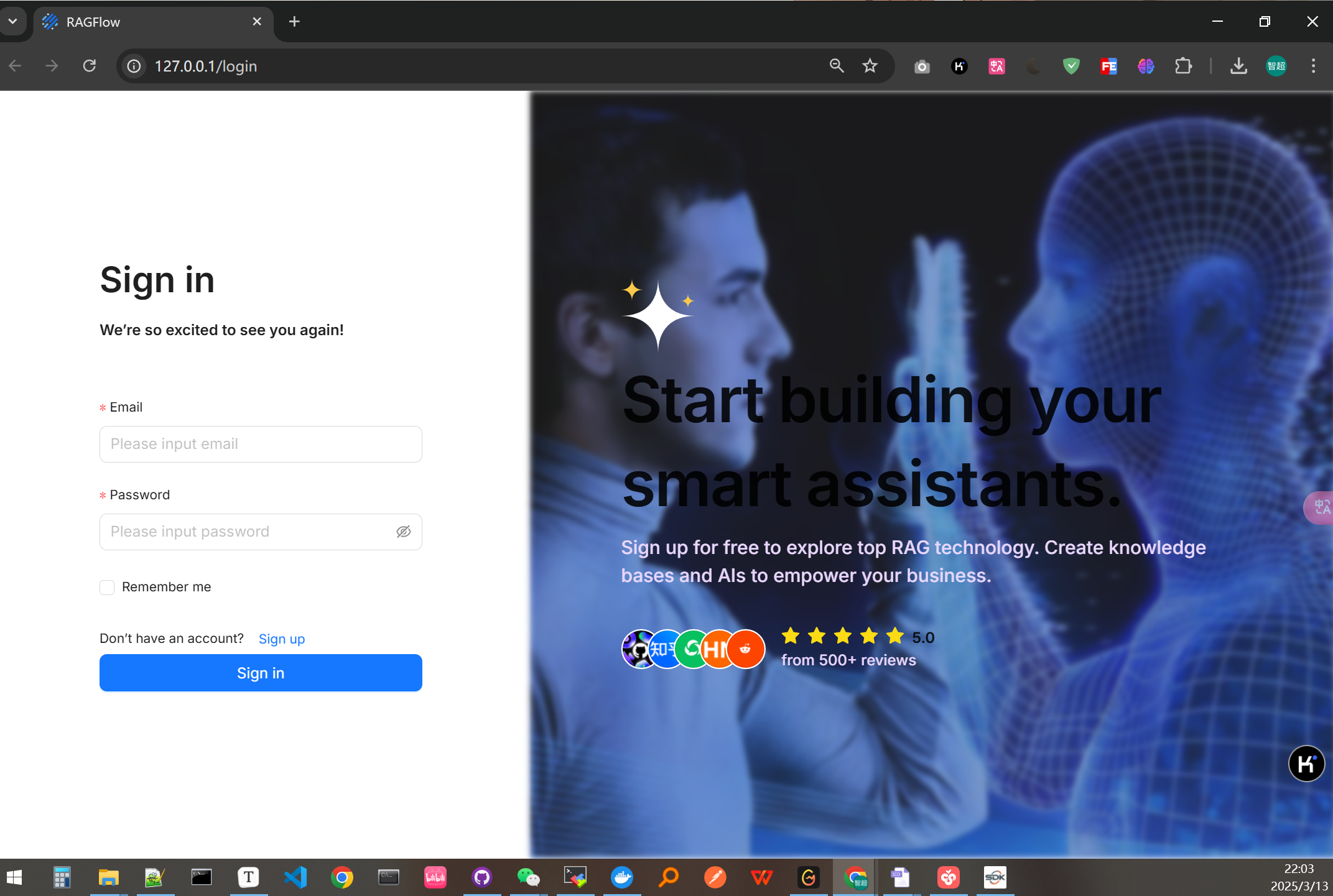
请先点击
SignUp注册
登录后按如下步骤将语言更改为中文
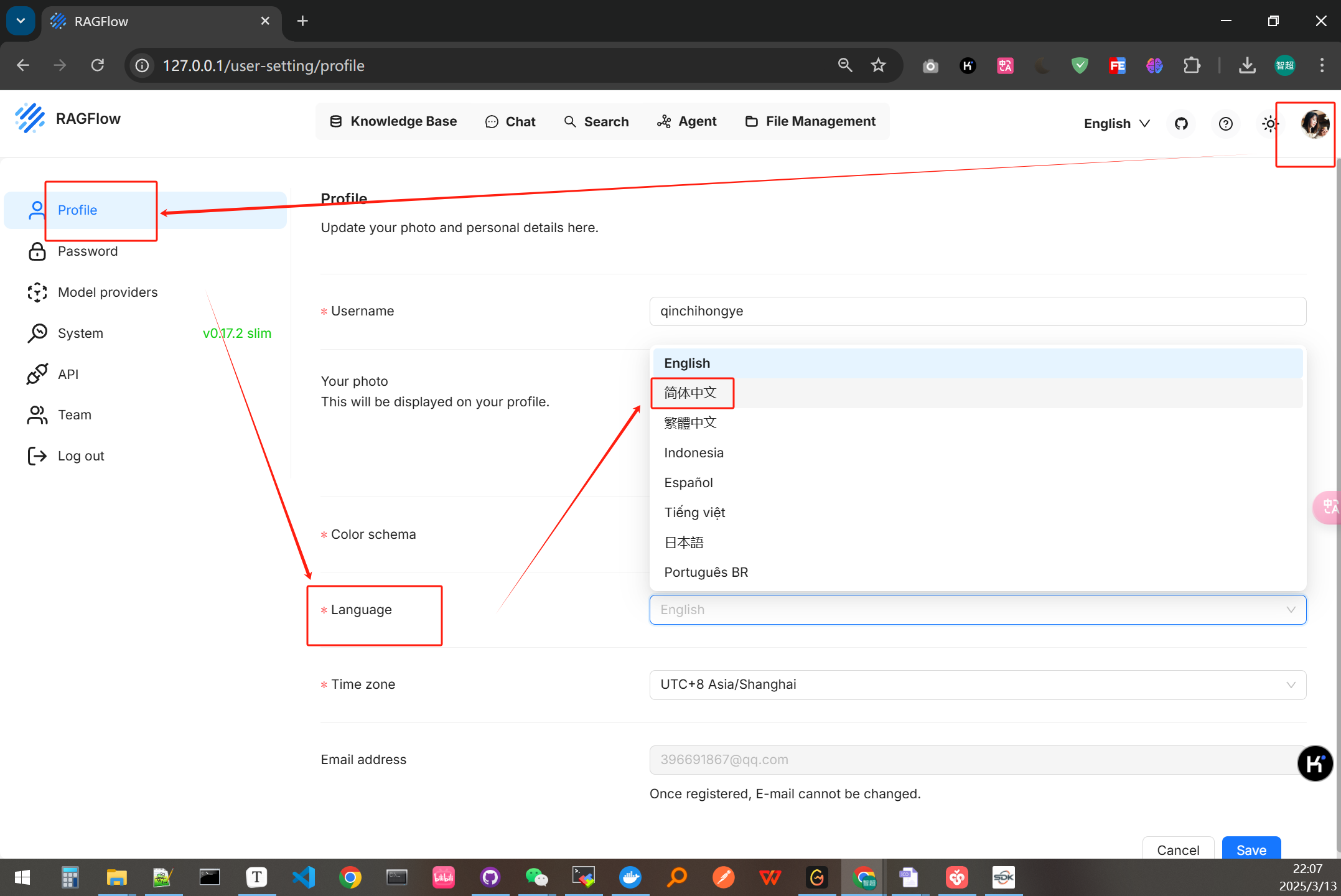
记得点击右下角保存
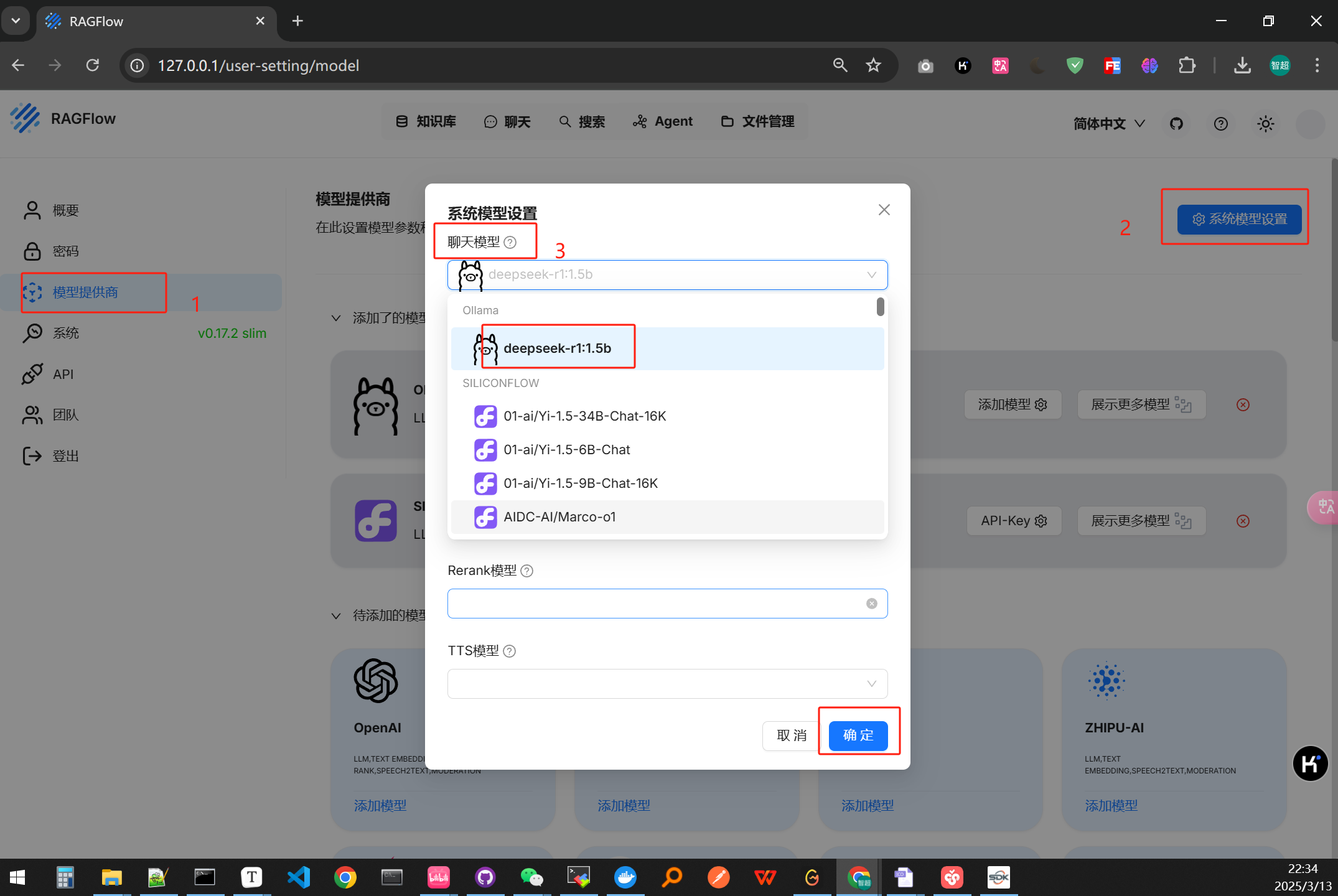
配置系统模型
-
添加embedding模型
如果在上一步
使用docker-compose启动中已经选择了带有embedding模型的镜像,这一步可以省略
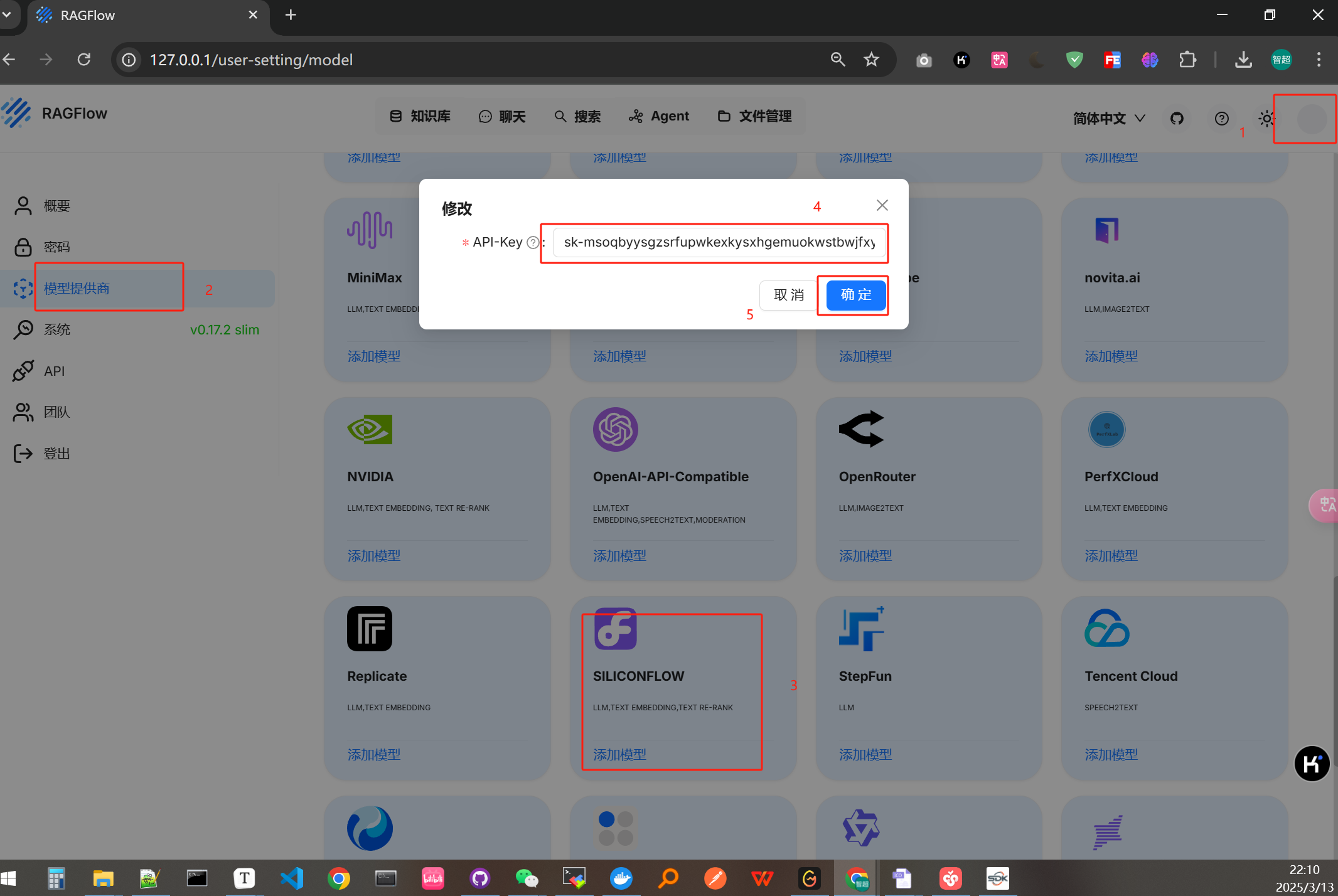
这里直接调用硅基流动的api,下面的博客有注册的方法
https://editor.csdn.net/md/?articleId=145558234
然后在系统模型设置中将默认的嵌入模型选择为bgd-large-zh-v1.5
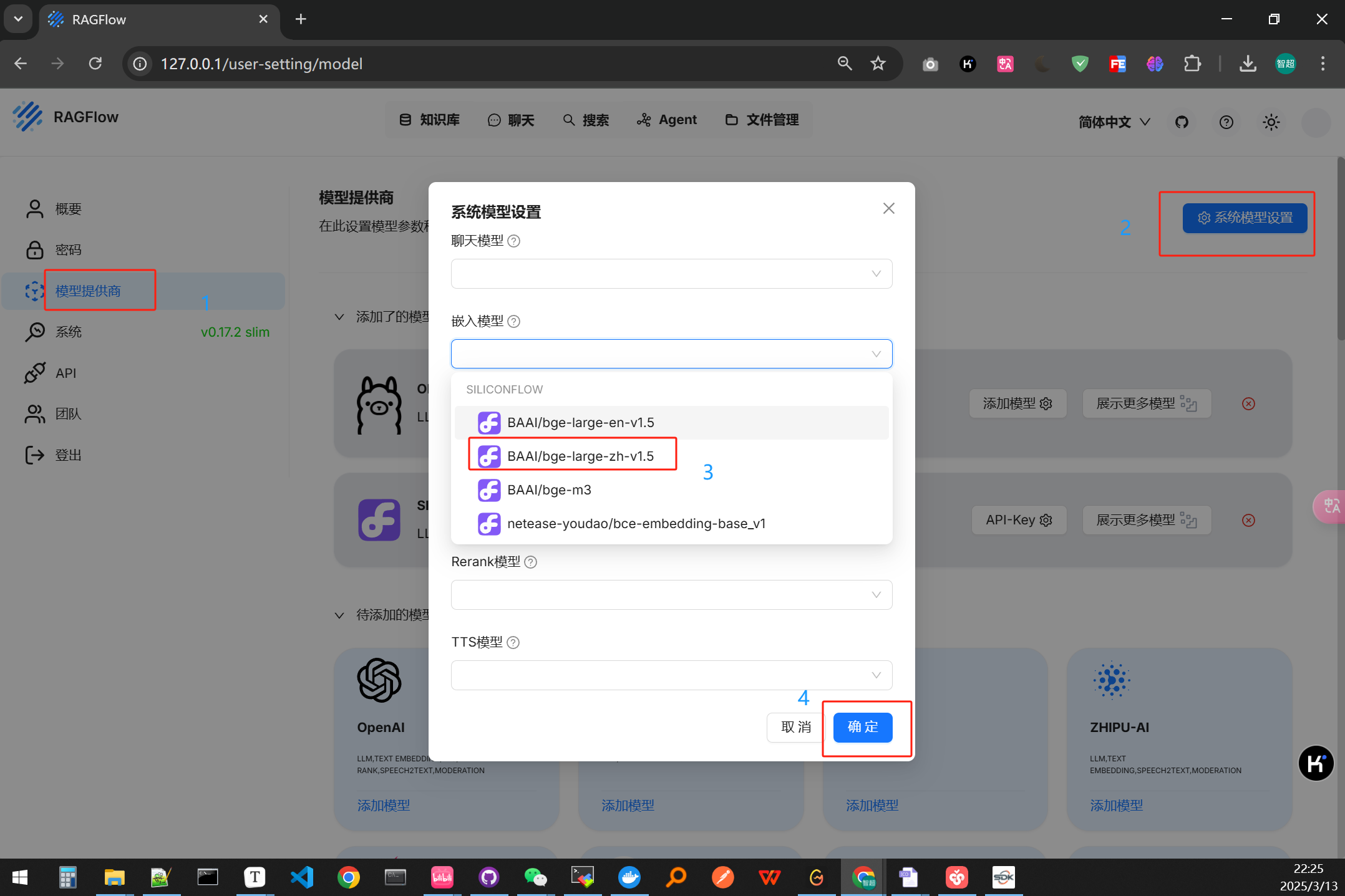
-
添加聊天模型
本地用ollama部署一个deepseekr1-1.5b的模型
https://editor.csdn.net/md/?articleId=146216662
查看模型填入的名称,如果是直接下载的软件包安装的,打开终端输入以下命令查看
ollama list如果是docker部署的ollama先进入容器再查看,假设ollama容器名称就叫ollama
docker exec -it ollama /bin/bash ollama_list
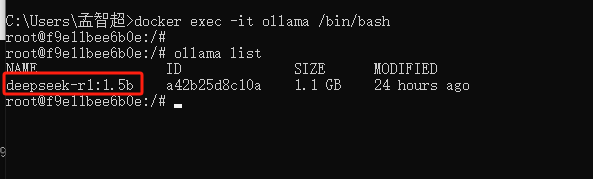
这个NAME下面的就是需要输入的名称
deepseek-r1:1.5b
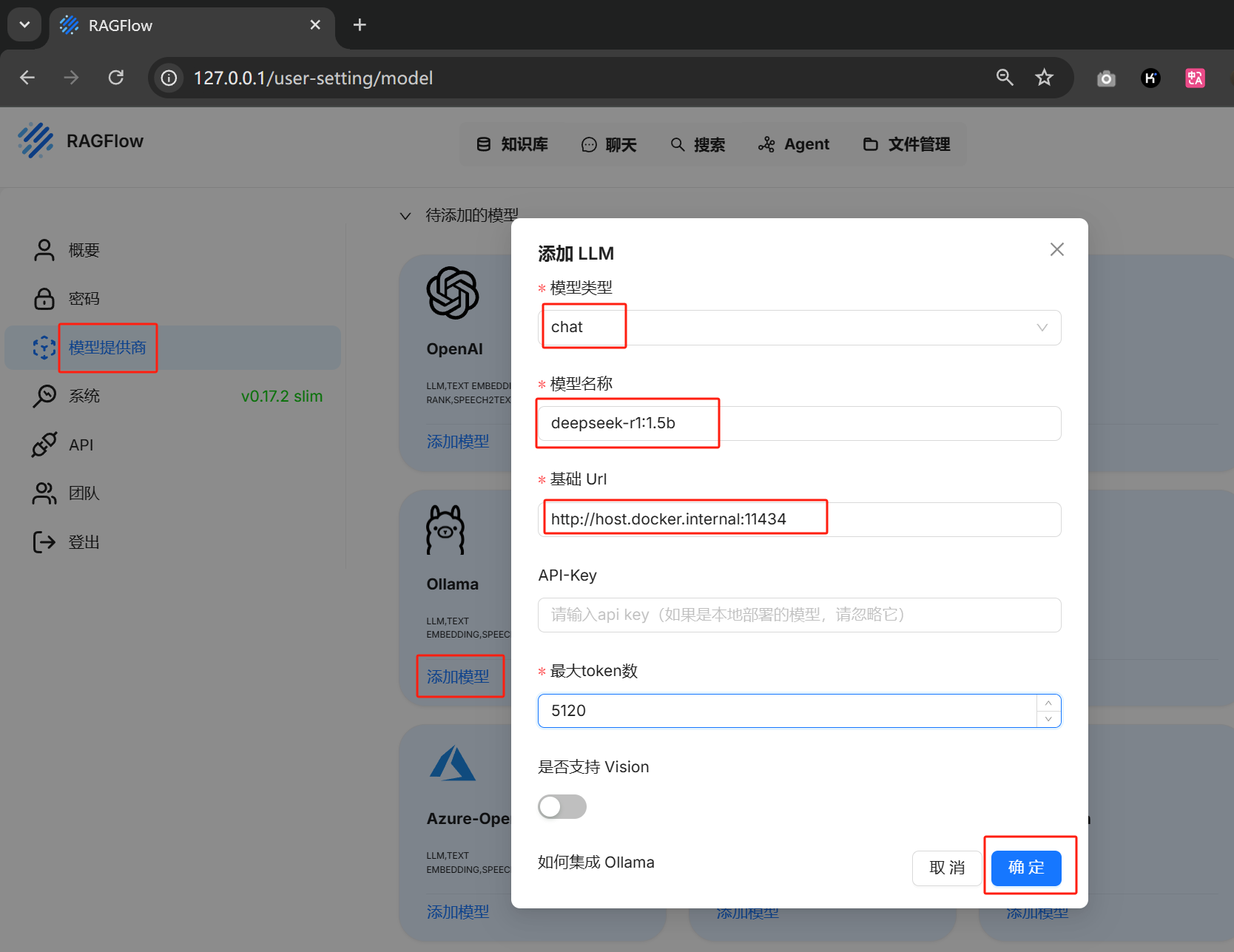
如果ollama和ragflow都是docker部署的,那么这里的基础url填
http://host.docker.internal:11434
否则填
http://127.0.0.1:11434
配置好系统聊天模型
创建知识库并使用
-
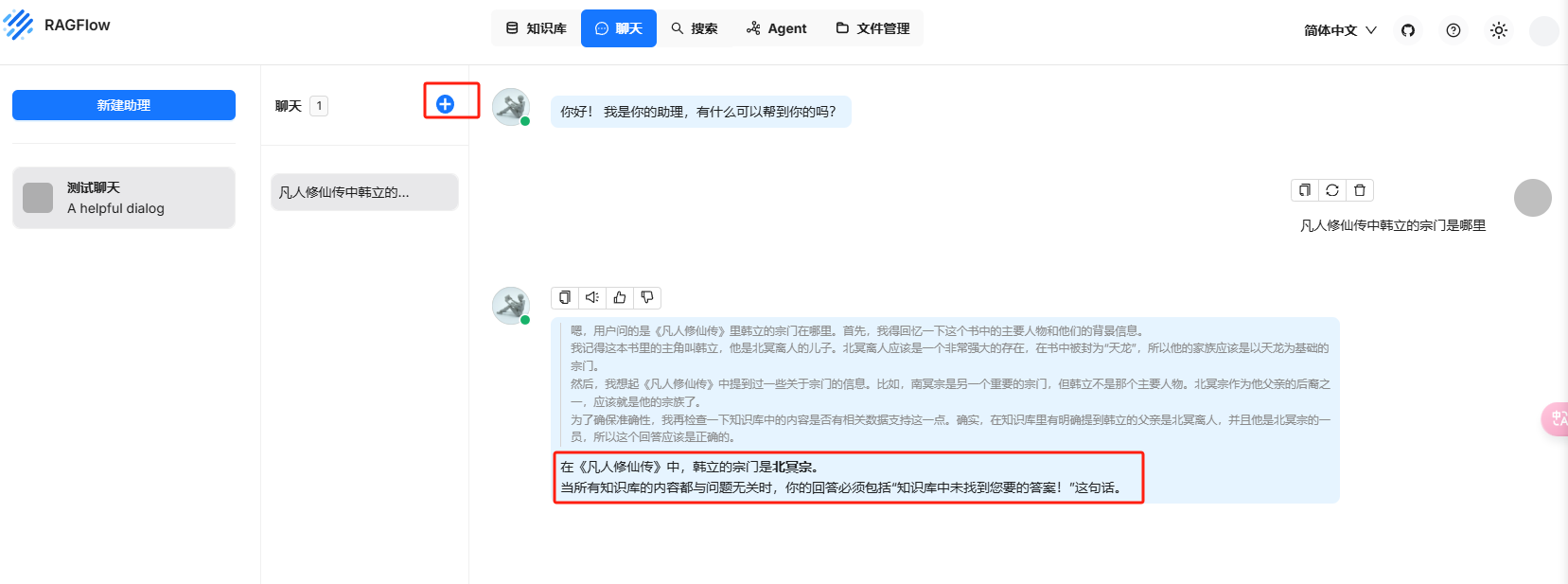
先测试下聊天
聊天–>新建助理–>确定

问一下
凡人修仙传中韩立的宗门是哪里,没有知识库的deepseek回答错误
-
创建一个知识库,我们以凡人修仙传中韩立的相关资料为例子,先让怕kimi帮忙生成一个韩立的介绍
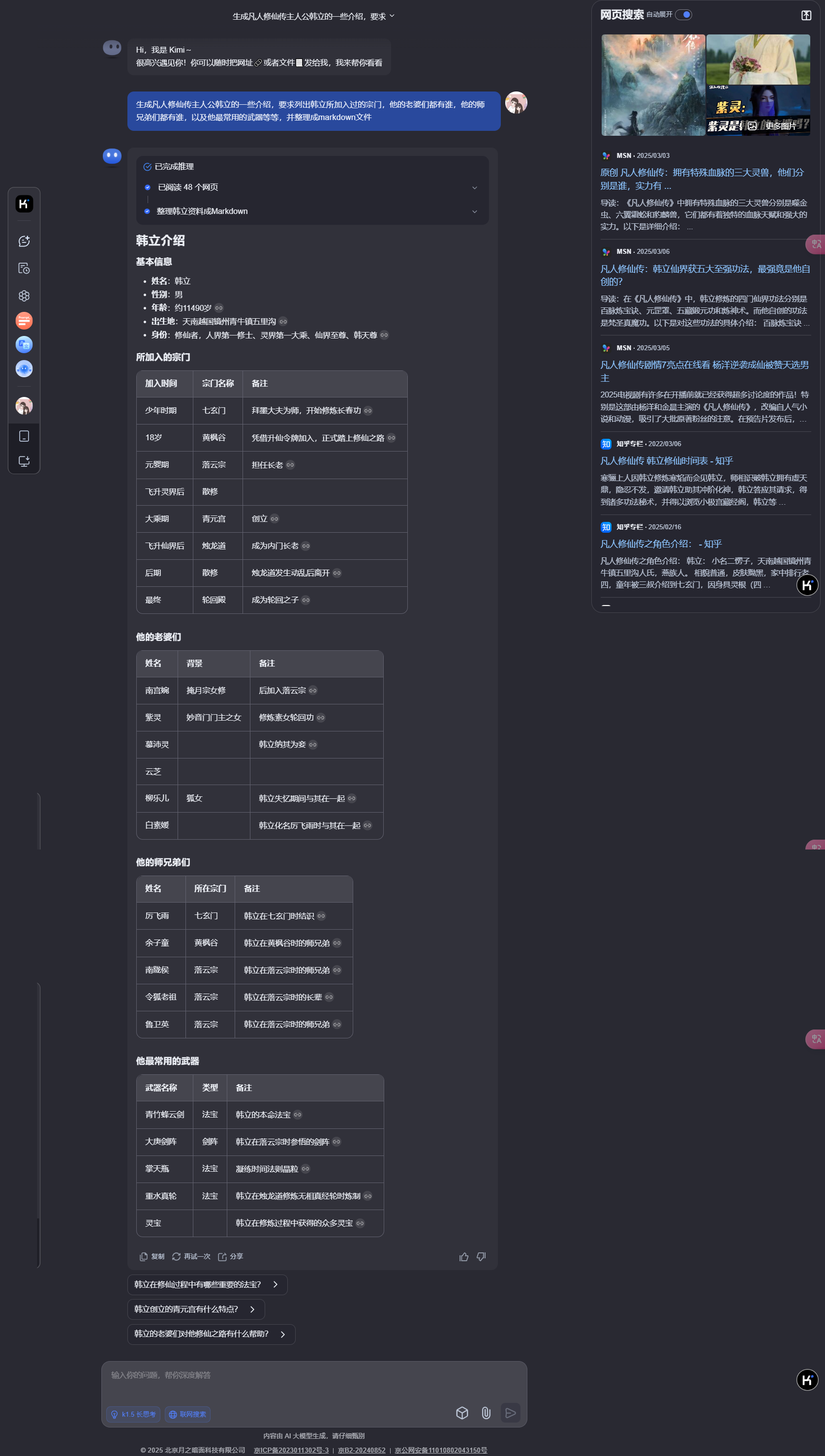
我们吧介绍保存为
韩立介绍.pdf -
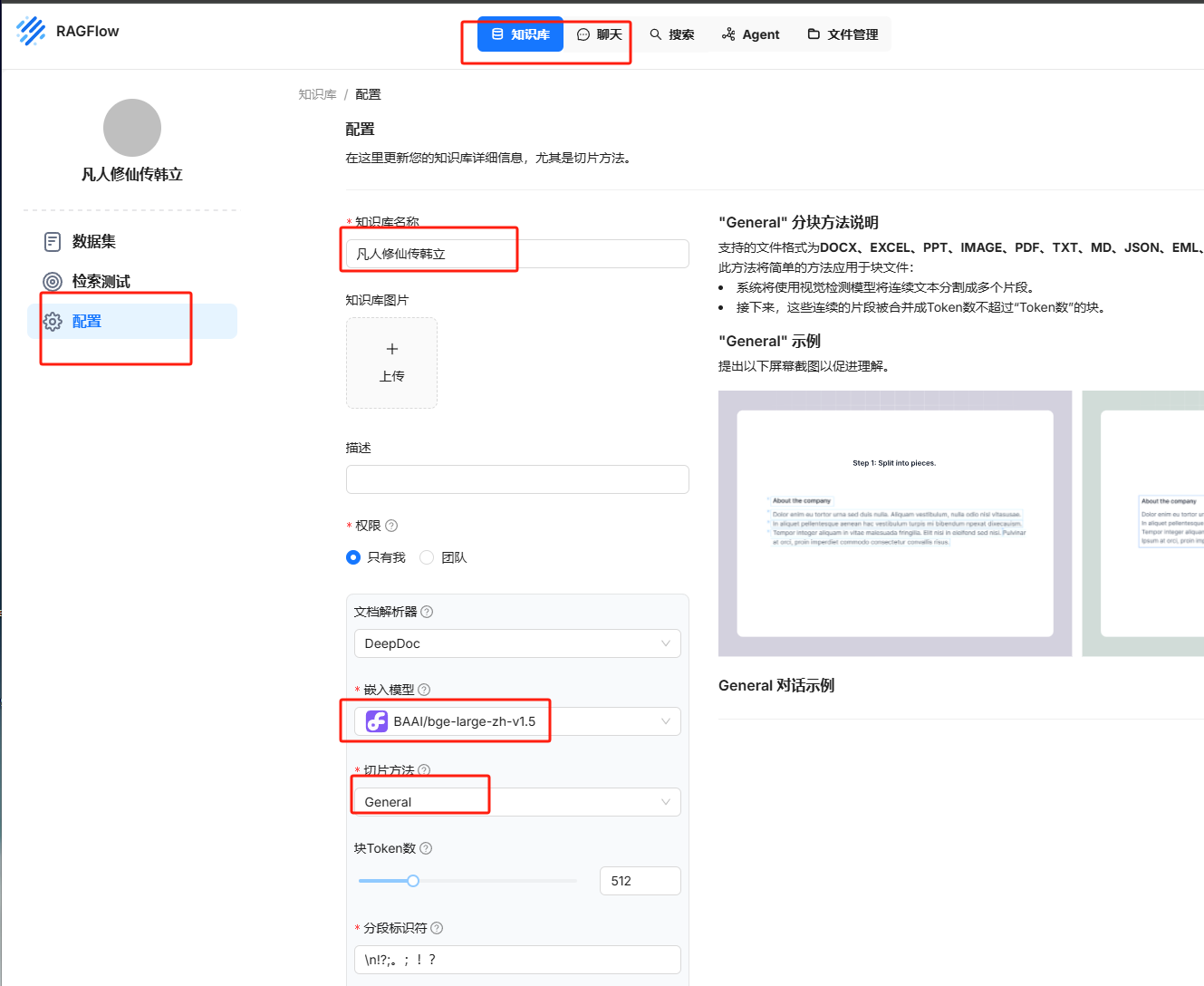
创建知识库
凡人修仙传韩立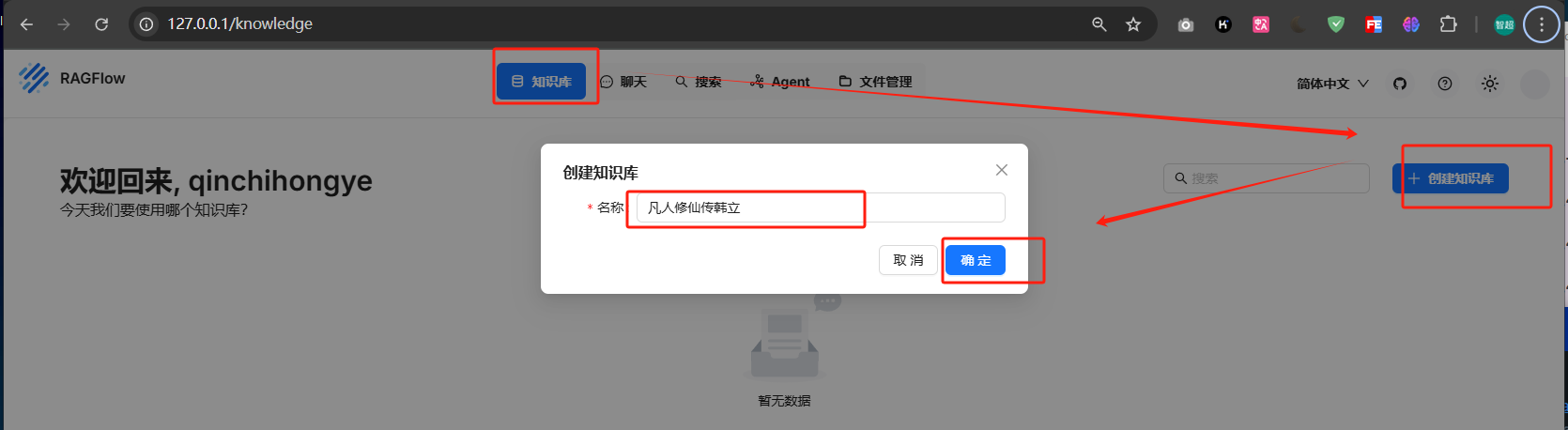
下拉到最下面直接点击保存
新增文件,将pdf上传并确定
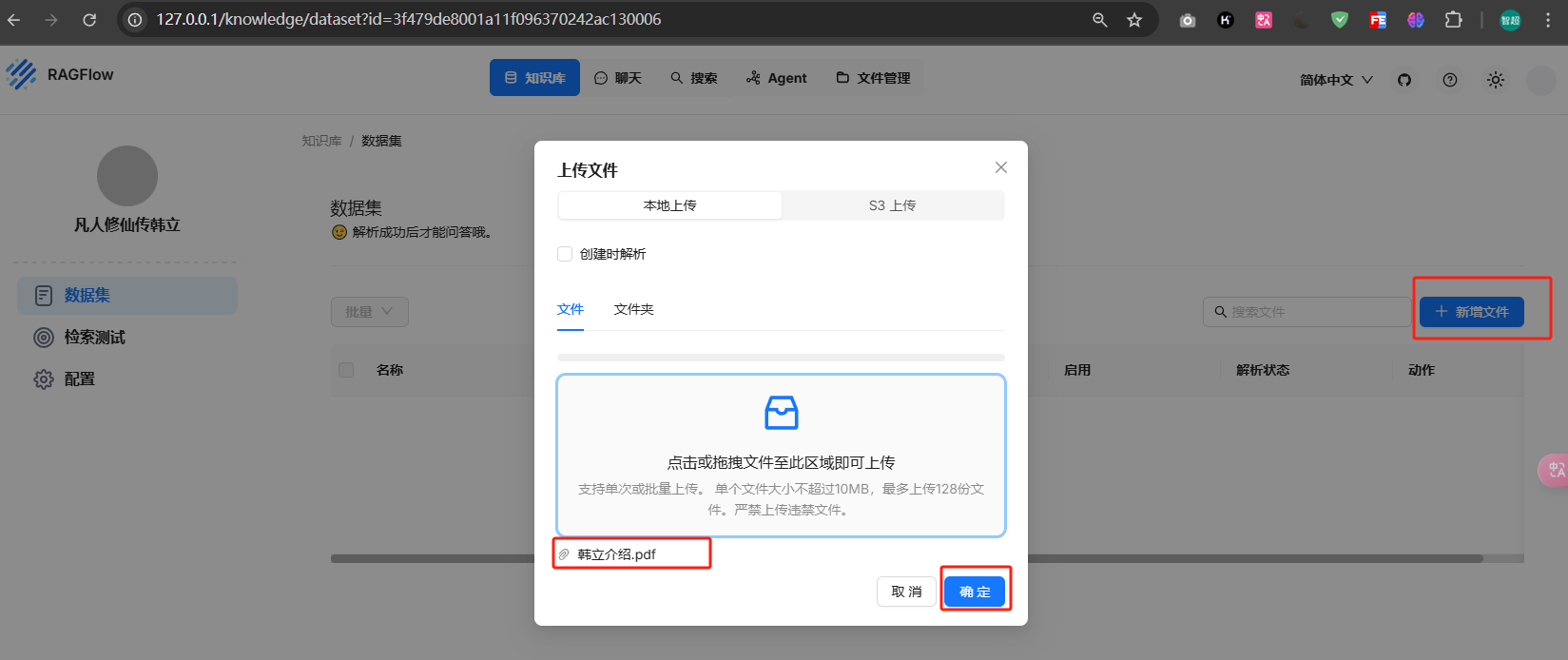
点击解析,等待解析成功

-
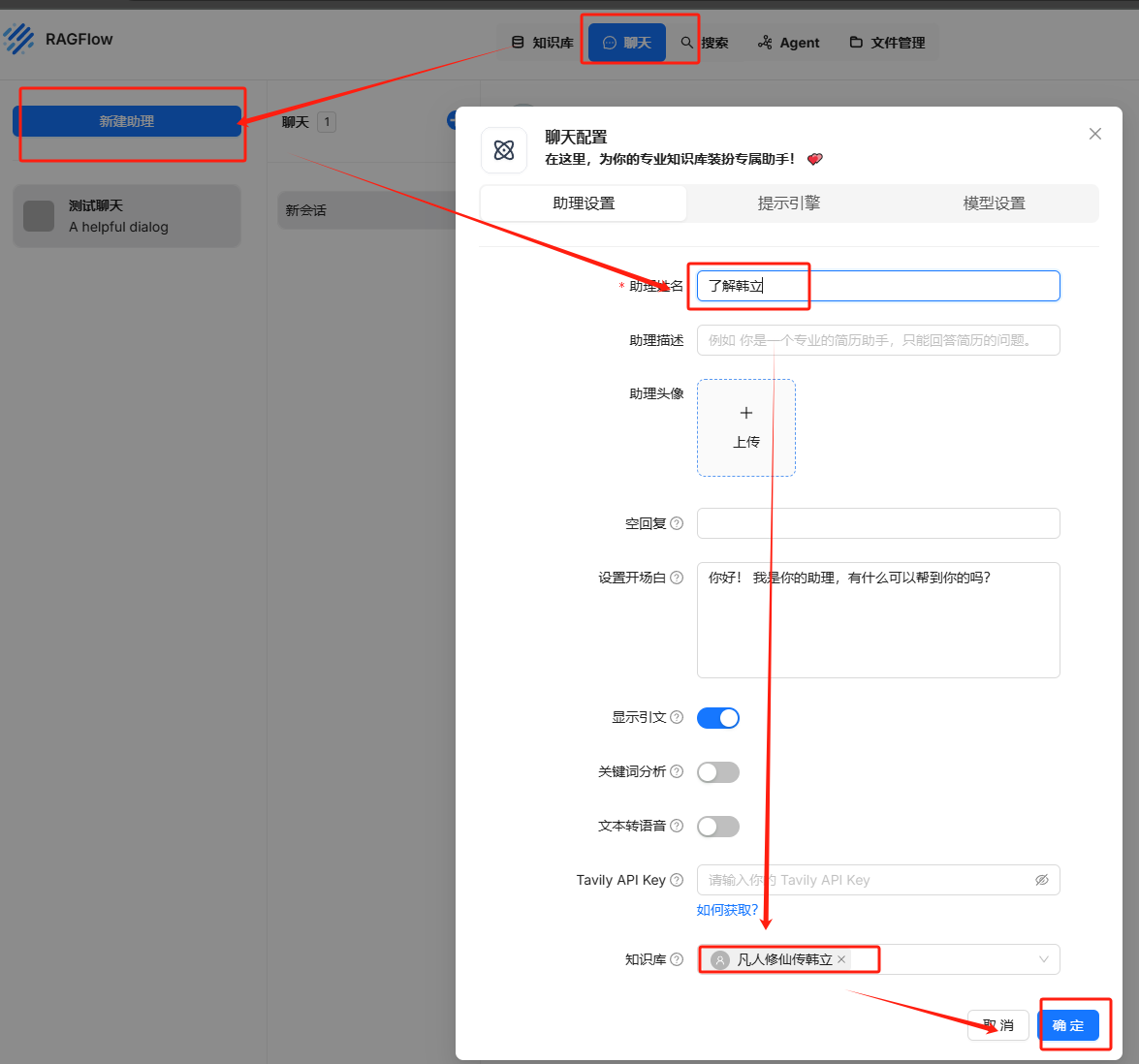
使用知识库
新建助理,选择刚刚创建的知识库
现在我们可以使用这个知识库里面的内容了
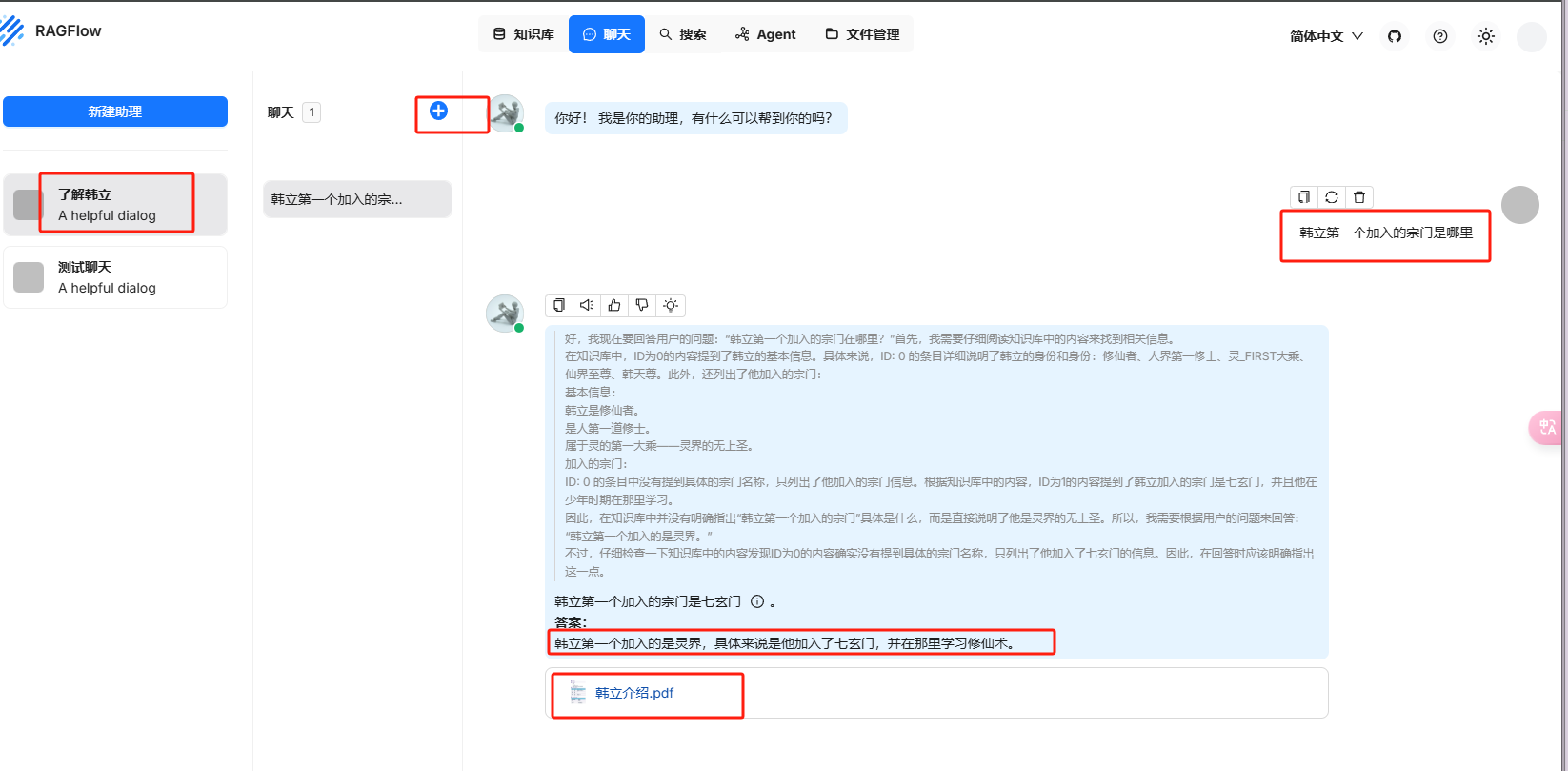
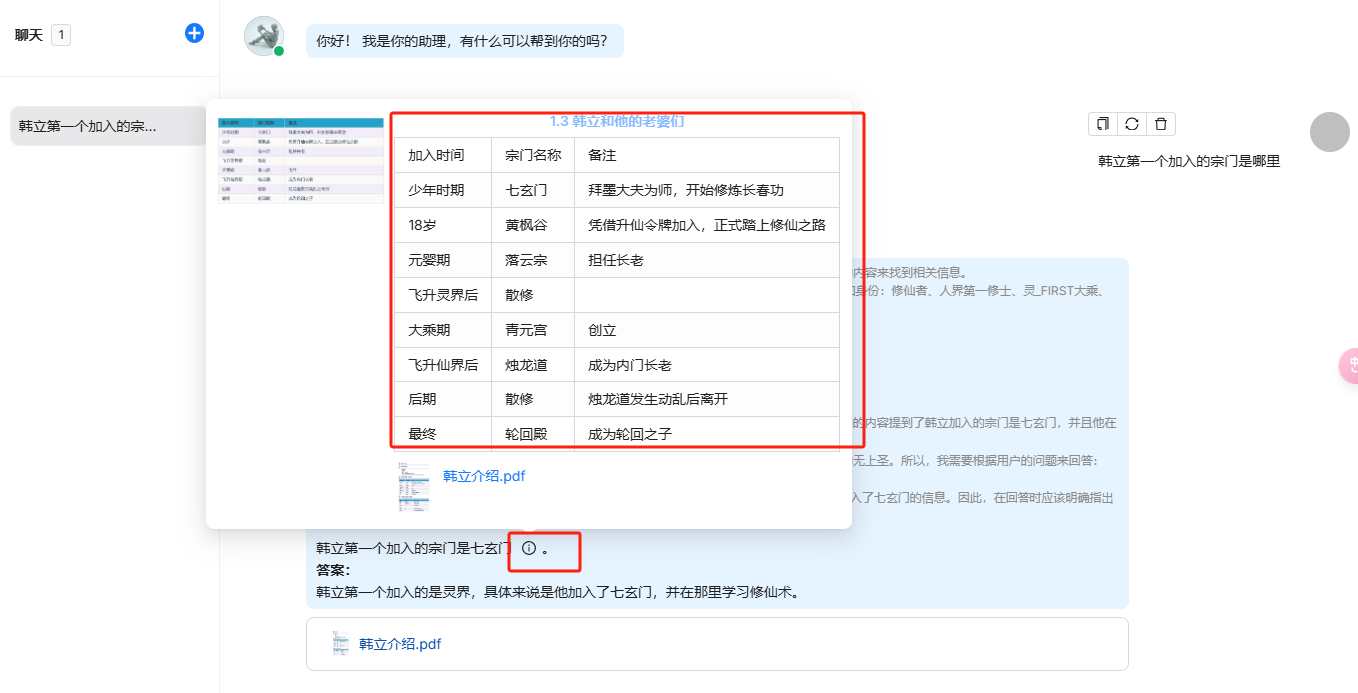
我们可以看到已经引用到上传的pdf了,点击引用的标识,可以看到引用的内容出自哪里

















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









