






趁着心情不错的三分钟热血读一读llama3.1 report的3.2.1章节。llama3.1的report目前发现3处数值错误或逻辑错误的描述,读的时候需要仔细一点。错误的地方写到再说。
省流
最大参数量由GPU集群的计算能力(GPU的型号选择H100,则计算能力只取决于GPU的数量。计算能力在文章中使用Compute budgets表示)、可使用tokens的数量和Scaling law三者共同决定。
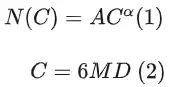

Meta这次拿出了3.8x10^25FLOPS 的Compute budgets和15-17T 的高质量清洗tokens,根据Scaling law 则模型的最佳参数量在400B左右。
不省流版
1、确定目标:想要得到参数量值,需要先拿到最佳tokens数
在启动一个训练任务之前,GPU的数量肯定是确定的,那么根据公式(2)想要得到最佳参数量 𝑀 ,我们还差一个𝐷 也就是可供使用的tokens的数量。
2、寻找Compute budgets、tokens数量、loss值、模型参数量之间的关系
既然目前能确定的参数是Compute budgets,而且从主观判断上Compute budgets和tokens数量肯定也是存在某种关联的,有更大的Compute budgets就能训练更多的数据。
那么力大砖飞,将Compute budgets、tokens数量、loss值、模型参数量这4个参数在一个设定的范围内全部实验一遍,自然就能看出一些规律了。
这项实验在report的Figure2和Figure3中呈现。meta真是豪气啊,这得花多少电费。
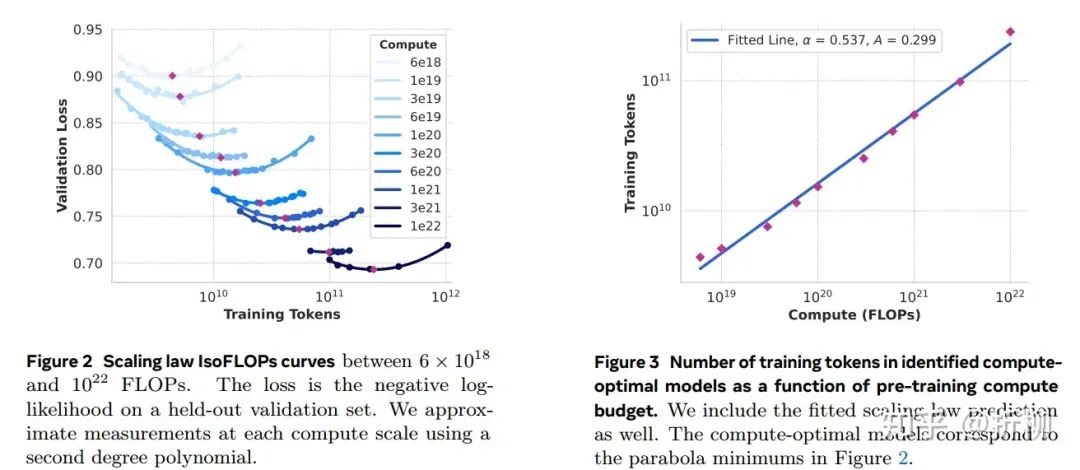
原文Figure2和Figure3
左侧Figure 2:Scaling law IsoFLOPs curves是一个工作量很大、成本很高的实验的结果展示。不同曲线的颜色代表不同的Compute budgets,范围从6x1018到1x1022 FLOPs,横坐标为tokens的数量,纵坐标是在validation set上计算的negative loglikelihood loss值。
注意,除了上述提到的三个维度的数据,Figure2还有一个维度的隐藏数据,针对每条Compute budgets随tokens变化的曲线,是由公式(2)Scaling law产生的,即固定Compute budgets,模型参数在40M到16B的范围内配合对应的tokens计算loss值。
接下来缩减数据的维度,提炼出想要的数据。
3、归纳tokens数量与Compute budgets之间的确定性换算
别忘了,这个实验最终想要的数据是Compute budgets和tokens之间的关系。那么就需要逐渐缩减数据的维度,首先缩减Compute budgets维度,就用每条Compute budgets曲线中loss最低值处代表此条Compute budgets对应的最佳tokens位置。
老实说,上面这段思维的转换才是最牛的,其余的最终结果、公式系数归纳什么的一点都不难。
好了,loss和参数量两个数据维度已经被剔除,把剩下的Compute budgets和tokens数拿出来做成Figure3,可以看到是一个大致的线性关系(与主观上的感受是相同的)。
这里有一个数学上的经验,虽然大体上是线性关系,但线性关系表达规律的能力较弱,这里使用了幂律分布,即假定了公式(1)然后带入数个Compute budgets和tokens数据对,最终得到待定的两个系数 𝐴 和 α 分别等于0.29和0.53。
有个坑啊,有个坑,0.29和0.53是个四舍五入值,直接使用这两个数带入计算是得不到具体值的。你看Figure3中这两个值是0.299和0.537。但0.299和0.537也不是最终的准确值,使用它们计算出来的结果是16.29T tokens,而文章中给出的是16.55T tokens。
4、最终确认参数量为405B
好了,要想尽可能的利用这3.8x10^25FLOPS的计算能力,需要16.55T tokens。
这里需要额外注意,Figure2中Compute budgets曲线从左上角到右下角的曲率是逐渐趋于平缓的,Compute budgets和tokens数之间的平衡中,Compute budgets可以相对较大些。主观上也是可以这样认同的,即算力大于tokens数,学习能力大一些,多学几遍数据,hhhh,话糙理不糙。
最终meta清洗得到了15.6T的tokens,带入公式(2),则最终得到最佳参数量为405B。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









