






简介
Qwen2.5-Math 是 Qwen2-Math 的升级版本,包括基础模型 Qwen2.5-Math-1.5B/7B/72B,指令微调模型Qwen2.5-Math-1.5B/7B/72B-Instruct 和数学奖励模型 Qwen2.5-Math-RM-72B。
相较于 Qwen2-Math 只支持使用思维链(CoT)解答英文数学题目,Qwen2.5 系列扩展为同时支持使用思维链和工具集成推理(TIR) 解决中英双语的数学题。Qwen2.5-Math 系列相比上一代 Qwen2.5-Math 在中文和英文的数学解题能力上均实现了显著提升。

图1:在MATH上的效果
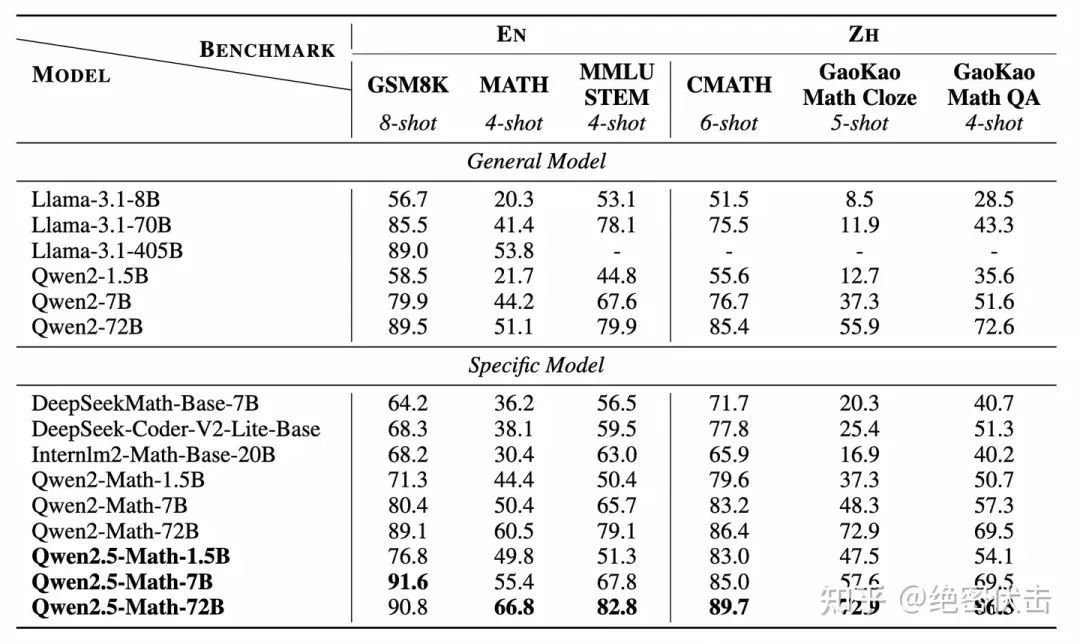
图2: 开源数据集评测
此外,使用 TIR 能进一步提升模型效果。
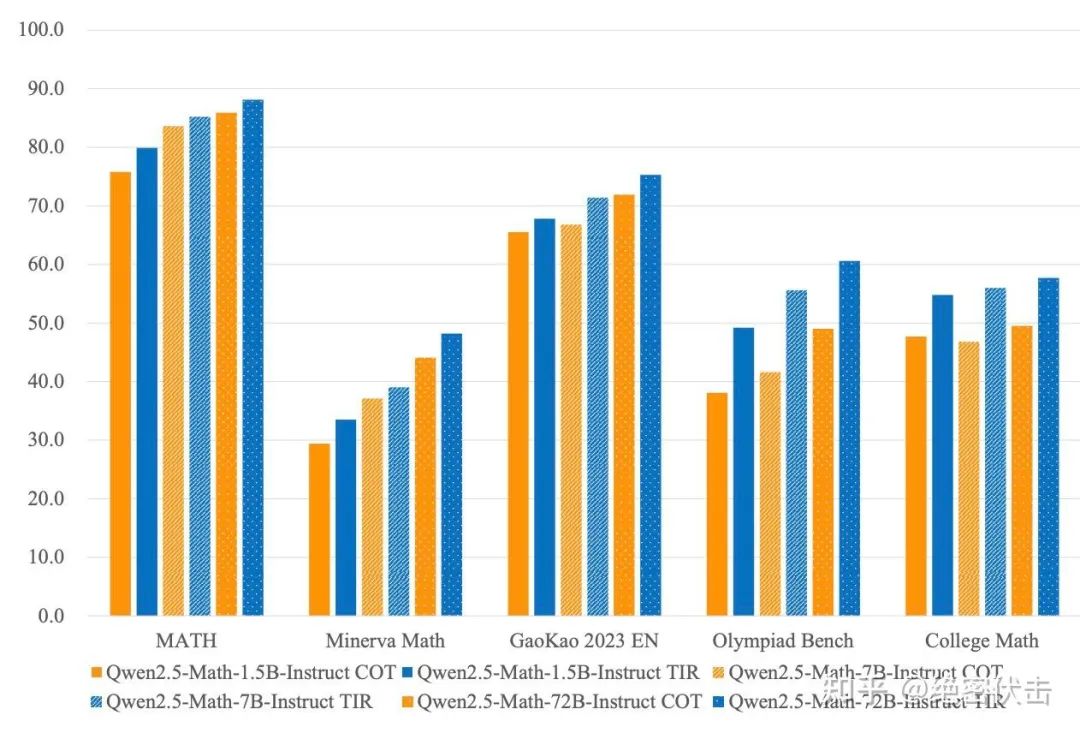
图3:使用TIR工具调用能进一步提升效果
下面是一个使用 TIR 的例子:
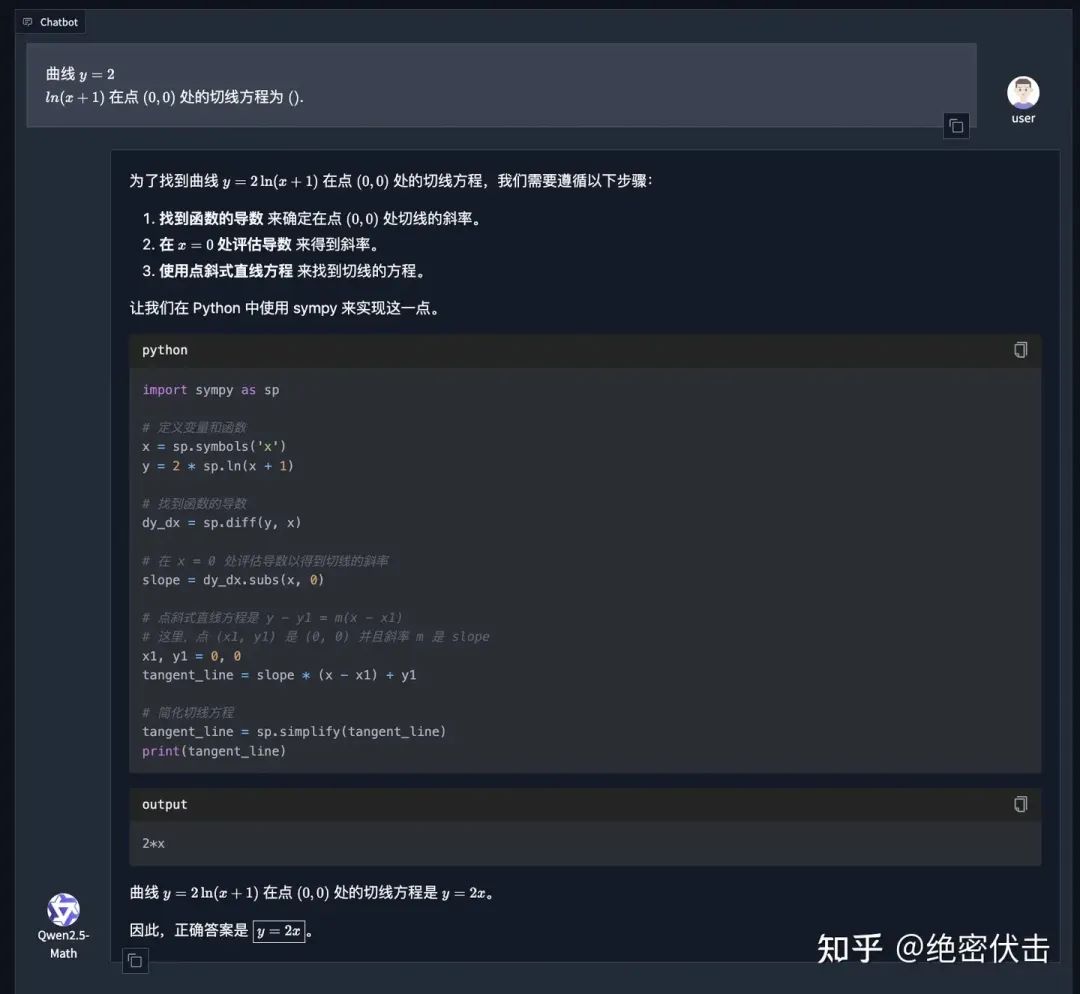
图4: 使用TIR
由于使用 TIR 需要调用 Agent,因此如果是直接推理,模型的输出会有问题。
下面的例子中,代码正确的结果应该是((159, 160, 161, 162), 642) ,如果不掉用 Agent,模型依然会生成代码结果,但是结果会有问题。

图5: 不掉用 Agent 结果
虽然 Qwen2.5-Math-72B 在开源数据集上,评测效果会明显好于 Qwen2.5-72B-Instruct,但是在 superclue 8 月的计算和逻辑推理上,效果并没有比 Qwen2.5-72B-Instruct 好,反而不如 Qwen2.5-72B-Instruct。这可能是因为 Qwen2.5-Math-72B 更擅长处理纯数学问题,而 superclue 的题目偏向应用,比如找规律、规划问题、逻辑推理等。
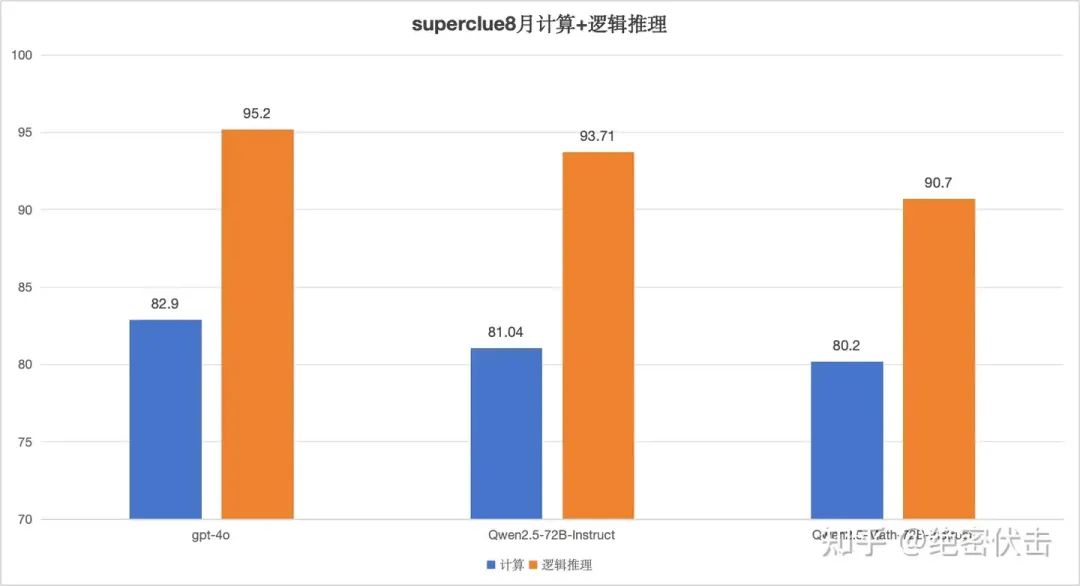
图6: 在 superclue 上的评测结果
关键技术
-
• Pre-training:在预训练阶段大量使用来自 Qwen2-Math 的合成数学数据。
-
• Post-training:SFT 模型和奖励模型之间的交互迭代。在后训练阶段迭代生成微调数据并在奖励模型的指导下进行强化训练。
-
• nference:支持双语(英语和中文)解题,以及思维链(COT)和工具集成推理能力(TIR)。
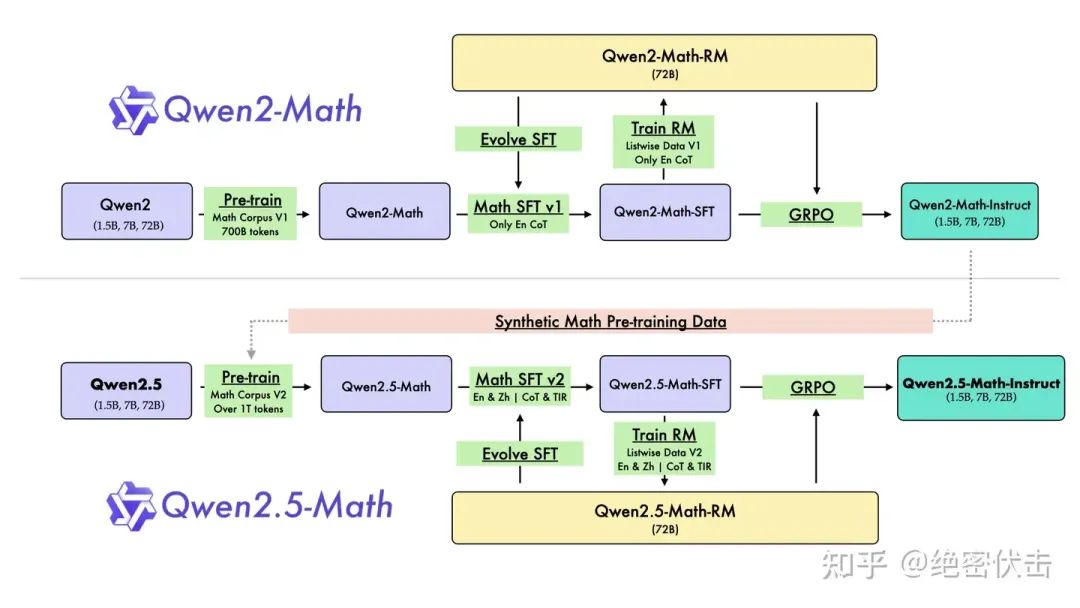
图7: Qwen2.5-Math 训练流程
和 Qwen2-Math 相比:
-
• Pre-training:使用了 Qwen2-Math 生成的合成数据,数据量从 700B tokens 增加到 1T tokens
-
• Post-training:SFT 数据包含 2000K 条英文数据和 500K 条中文数据,除了 COT 数据,同时使用了 TIR 数据
推理时使用 COT
messages = [
{"role": "system", "content": "Please reason step by step, and put your final answer within \\boxed{}."},
{"role": "user", "content": prompt}
]
推理时使用 TIR
messages = [
{"role": "system", "content": "Please integrate natural language reasoning with programs to solve the problem above, and put your final answer within \\boxed{}."},
{"role": "user", "content": prompt}
]
Pre-Training
Qwen Math Corpus v1
Qwen Math Corpus v1 是从 Qwen2 训练 Qwen2-Math 时候用的数据集,总共有 700B tokens,上下文长度 4K。
-
• 数据来源:Web 数据,例如 common crawl
-
• 数据召回和去重:使用 FastText 分类器标注数据,召回更多的 Math 数据。使用 MinHash 去重。
-
• 数据过滤:使用 Qwen2-0.5B-Instruct 评估数据质量,选取高得分数据。(论文并没有给出评分的 prompt)。
-
• 数据配比(数据混合):使用小模型 Qwen2-Math-1.5B 对数据混合进行消融实验。
Qwen Math Corpus v2
数据由原来的 700B tokens 扩充到 1T tokens,上下文长度仍然是 4k。
-
• 合成数据:使用 Qwen2-72B-Instruct 模型来合成大量数学预训练语料。在这个阶段,已经收集到的高质量数学数据被用作种子数据。利用 Qwen2-72B-Instruct 模型,(1) 从这些种子数据中提取和精炼现有的 query-answer 数据,(2) 直接生成新的 query-answer。
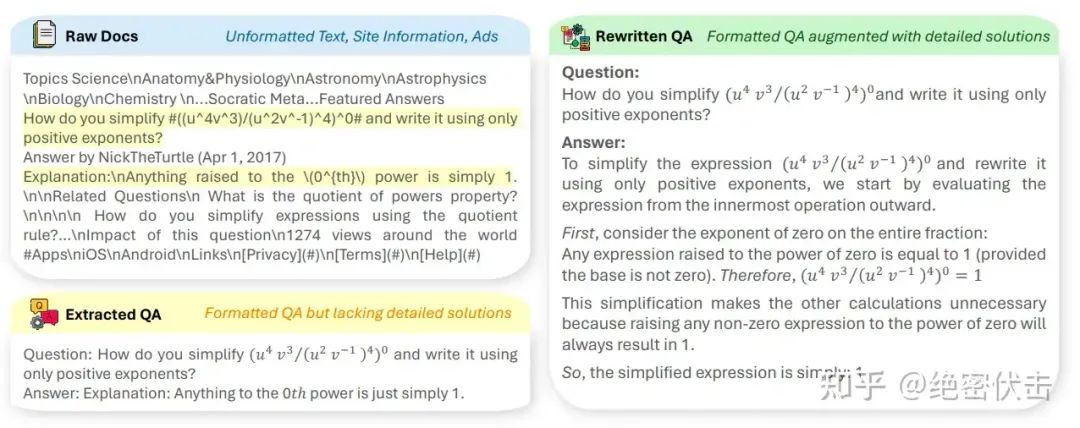
图8:重新生成新的 query-answer
-
• 收集更多中文 Math 数据
Post-Training
后训练用于进一步提升 Qwen2.5-Math 的数学能力,特别是专注于思维链(CoT)和工具集成推理(TIR)。
后训练主要关注两个挑战:
-
• 如何自动生成大量高质量且可靠的 CoT 和 TIR 数据
-
• 如何有效利用这些数据进行 SFT 和强化
SFT
包含 2500K COT 数据(2000K 英文+500K 中文),395K TIR 数据(190K 带标注数据,其中 75K 是由 Qwen2-72B 翻译为中文的数据,205K 合成数据)。
训练参数:
3 个 epoch,上下文长度 4096,72B 模型的 batch size 256、学习率5e-6,1.5B 和 7B 模型的 batch size 128、学习率 2e-5。学习率最小衰减到 7e-7。
COT数据
数据总量:英文 2000K,中文 500k
query 构建
-
• query 数据量:580K 英文,500K 中文
-
• 来源:
-
• 标注数据来自 GSM8K、MATH、NuminaMath、自家的 K-12 中文数学
-
• 合成 query 是使用 MuggleMath 方法从标注 query 演变而来的(换数、改写、增加复杂度等手段)
-
• 难度分类:难度评分模型对 query 分类,控制不同难度的分布
补充:MuggleMath 合成方法
针对 GSM8K query
我希望你能扮演一位数学老师。
我会提供一个小学数学问题,你需要通过给定的方法来创建更具挑战性的数学问题。
给定的问题是:“詹姆斯每周 2 次给 2 个不同的朋友写一封 3 页的信。他 1 年写多少页?”
你可以通过以下思路进行修改:
1. 改变具体的数字:詹姆斯每周 3 次给 2 个不同的朋友写一封 2 页的信。他 4 年写多少页?
2. 引入分数或百分比:詹姆斯每周 2 次给 2 个不同的朋友写一封 3 页的信。每周他在每封信上增加 50% 的页数。他一个月写多少页?
3. 结合多个概念:詹姆斯每周 2 次给 2 个不同的朋友写一封 3 页的信。他使用纸的两面,每面可以写 250 个字。如果詹姆斯每分钟写 100 个字,他一周写完所有信需要多长时间?
4. 包含条件语句:詹姆斯每周 2 次给 2 个不同的朋友写一封 3 页的信。如果是节假日,他会给每个朋友额外写一封 5 页的信。考虑到一年有 10 个节假日,他一年写多少页?
5. 增加问题的复杂性:詹姆斯每周 2 次给两个不同的朋友写一封 3 页的信。此外,他每周给另外 2 个朋友写一封5页的信。假设一个月有 4 周,他一个月写多少页?
现在给你一个新的数学问题:
**一个新的数学问题在这里。**
针对 GSM8K answer
我希望你能作为一个优秀的数学解题者。
你将一步一步地解决给定的数学问题。
你需要用 Python dict 的格式回复,格式与给定的例子相同。保留小数点后三位。
过程中的公式需要使用以下格式:48/2 = «48/2=24»24 个夹子。回复的结尾需要是:#### {答案}。
例子:
{“query”: “娜塔莉亚在四月份卖给了她的48个朋友夹子,然后她在五月份卖了一半的夹子。娜塔莉亚在四月和五月一共卖了多少个夹子?”,
“response”: “娜塔莉亚在五月份卖了48/2 = «48/2=24»24个夹子。娜塔莉亚在四月和五月一共卖了48+24 = «48+24=72»72个夹子。#### 72”
}。
给定的问题:
**一个新的数学问题在这里。**
```json
{
"query": "一个新的数学问题在这里。",
"response": "解答步骤将在这里展示。#### {答案}"
}```
answer 构建
使用了拒绝采样,具体流程如下:
-
• 训练一个 SFT 模型 S1,训练一个奖励模型 R1
-
• 采样路径:
-
• 对于有标准答案的 query:选取答案正确的 top-k 个推理路径
-
• 对于没有标准答案的 query:首先通过加权多数投票机制得到最合理的推理路径,然后再使用 Reward Model 选取得分最高的 top-k 个路径
-
• 根据上面获取的新数据,SFT 新的模型 S2,基于 S2 训练新的 Reward Model R2
-
• 重复以上步骤
TIR 数据
使用 TIR 处理复杂数学计算(如求解二次方程的根或计算矩阵的特征值)。
开发 TIR 数据集,使用 Python 解释器执行代码。
query 构建
-
• 数据总量:190k 带标注的数据(其中75k Qwen2-72B 翻译为中文的数据),205k 合成数据
-
• 来源:
answer 构建
-
• 带标注的数据:公开数据集,GSM8K、MATH、CollegeMath 和 NuminaMath 等
-
• 合成 query:使用 MuggleMath 和 DotaMath 方法,其中 DotaMath 是阿里自己 7 月份的工作,大概就是子问题分解、代码解题、错误分析、迭代优化
-
• 带标注的问题:仍然是 RFT,不同的是,用了 DeepSeek-Math 中的 Online RFT,在每次 RFT 迭代中,使用当前最优模型在不同 Temperature 下进行多次采样,增加难问题的样本量
-
• 合成数据:从 Online RFT 中获得的最优模型来生成推理样本。采用多数投票选择最可能正确的推理路径
补充:DotaMath 合成方法
合成 query
我希望你能作为一名数学老师。你应该想出一些方法来帮助学生进行有挑战性的竞赛数学问题的变式训练。
以下是一些你可以参考的方法:
引入分数或百分比,结合多个概念,包含条件语句,增加问题的复杂性等等。回复需要使用特定格式,如:
引入分数或百分比:##1 新问题1 ##1
结合多个概念:##2 新问题2 ##2
...
增加问题的复杂性:##10 新问题10 ##10
第n个问题必须严格限制在##n和##n之间,以便我们后续的规则提取。
现在你有一个数学问题,请思考10种不同的方法。
给定的新问题:
{Query}
合成 answer
你是一名在数学和编程竞赛中都非常强大的竞争者,精通广泛的数学知识并擅长Python编程。
你在初等代数、代数、数论、计数与概率、几何、中级代数和预备微积分方面的造诣无与伦比。
你的思维缜密而深刻,你编写的代码总是运行得完美无误。
使用以下指南,结合逐步推理和Python代码来解决数学问题:
1. 将问题分解为子任务。
2. 编写函数来解决问题;函数不应接受任何参数。
3. 在Python代码中打印每个子任务的结果,使用Python程序中的中间变量来表示中间结果,参考下面的示例。
4. 编写Python程序时,避免使用小数。利用sympy和其他必要的Python库中的函数,并在不将其转换为小数值的情况下简化所有分数和平方根。
5. 在最后一行打印最终答案。
以下是一个你可以参考的示例:
给定一个数学问题,一个错误的解答,你需要纠正这个错误的解答。回复格式如下:(简短的错误解释)+(新解答)。
例子:求圆的半径

图9:DotaMath 合成 answer
DotaMath 使用分解和自我纠正来解决数学问题:
-
• 分解:对于问题 p,模型最初将其分解为三个子任务
-
• 编写代码:随后编写相应的代码
-
• 代码执行:Python 解释器执行这些代码,产生 3 个字结果
-
• 错误分析:发现错误,解释原因
-
• 迭代执行:重复以上步骤,直到找到最终正确结果
备注:DotaMath 并不是所有的 answer 都包含错误答案和纠错功能。
奖励模型训练
数据构建
-
• Qwen2-Math-RM:使用了 206K 英文数学问题,每个问题有 6 个从 Qwen2-Math 的中间版本中采样的候选回复
-
• Qwen2.5-Math-RM:增强了对中文和 TIR 的支持,使用更为多样化的 361K 英文和 257K 中文数学问题进行训练,每个问题有 6 个从 Qwen2.5-Math 中采样的回复
-
• 过滤掉所有回复完全正确或完全错误的情况
-
• 为了避免仅保留过于简单的数据的潜在缺点,通过各种中间版本和不同规模的模型的回复来丰富数据集。这一策略确保了 query 难度的更均衡分布,并保持正面和负面回复的均衡比例。
训练
一般的奖励模型通常是把训好的 SFT 模型最后的 lm_head 去掉,换成一个单输出线性层用于评分。
但 Qwen2.5-Math 做了两处改动:
-
• 把单线性层变为了双层, (hidden_state, hidden_state) 和 (hidden_state, 1)
-
• 对于每个问题的 6 个回答,如果有 k 个正面回复,那么剩下的 6 - k 个就是负面回复
强化学习
数据构建
-
• 数据量:66K,没有提到中英文占比
-
• query 来自奖励模型的训练集
-
• answer:利用不同规模的 SFT 为每个 query 重新采样8个回答,通过与标准答案比较,将每个回答分类为正确或错误,只保留 8 个回答中有 2 到 5 个正确答案的 query。少于 2 个正确答案的 query 被排除,因为这表明当前的数学模型无法处理这样的难问题。同样,超过 5 个正确答案的 query 也被忽略,因为模型在这些情况下已经表现出足够的能力,不需要进一步训练
训练
-
• 方法是 GRPO。
-
• 奖励函数的评分是结合了奖励模型的打分和规则的硬筛选:
-
最终奖励奖励模型的打分基于规则的打分
-
• 论文中设置的。
-
• 为什么要引入基于规则的打分,论文中提到:“这种塑造机制确保正确的回复始终比错误的回复获得更高的整体奖励。”
-
• 实现框架:ChatLearn。
-
• 实现细节:每个 query 采样 32 个回答。所有模型都使用 512 的 batch size。学习率分别为 1e-5(7B)和 5e-6(72B)。KL 系数为 1e-3。在 TIR 的强化学习中,屏蔽了 Python 解释器提供的所有输出 token。
去污染
-
• n-gram 过滤:非常常见的手段,Qwen2.5-Math 采用的是 13-gram 过滤
-
• LCS(最长子序列)过滤:过滤比例是 0.6,不同于 n-gram,LCS 是不要求连续的,对于数学这种表达式基本一样只是换个数的非常有效,例如:
| 训练 | 测试 |
|---|---|
| What is the remainder when 1+2+3+4+⋯+9+10 is divided by 8? | What is the remainder when 1+2+3+4+⋯+9+10 is divided by 9? |
| Krista put 2 cent into her new bank on a Sunday morning. On Monday she put 3 cents into her bank. On Tuesday she put 5 cents into her bank… | Krista put 1 cent into her new bank on a Sunday morning. On Monday she put 2 cents into her bank. On Tuesday she put 4 cents into her bank… |
可以看到,对于第一个例子,n-gram 过滤是有效的,毕竟只有最后一个数不一样。
但对于第二种这样常见的除了数字其他不变的题目,用 n-gram 可能过滤不掉,但用 LCS 就能有效过滤了。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1844
1844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









