







Magpie:开创性的大语言模型对齐数据生成方法
在人工智能快速发展的今天,大语言模型(LLM)的对齐问题越来越受到关注。高质量的指令数据对于对齐大语言模型至关重要,但目前大多数高质量对齐数据集都是非公开的,这在一定程度上阻碍了AI的民主化进程。为了解决这一问题,来自华盛顿大学的研究团队提出了一种名为Magpie的创新方法,可以从零开始合成大规模高质量的对齐数据。
Magpie方法的核心思想
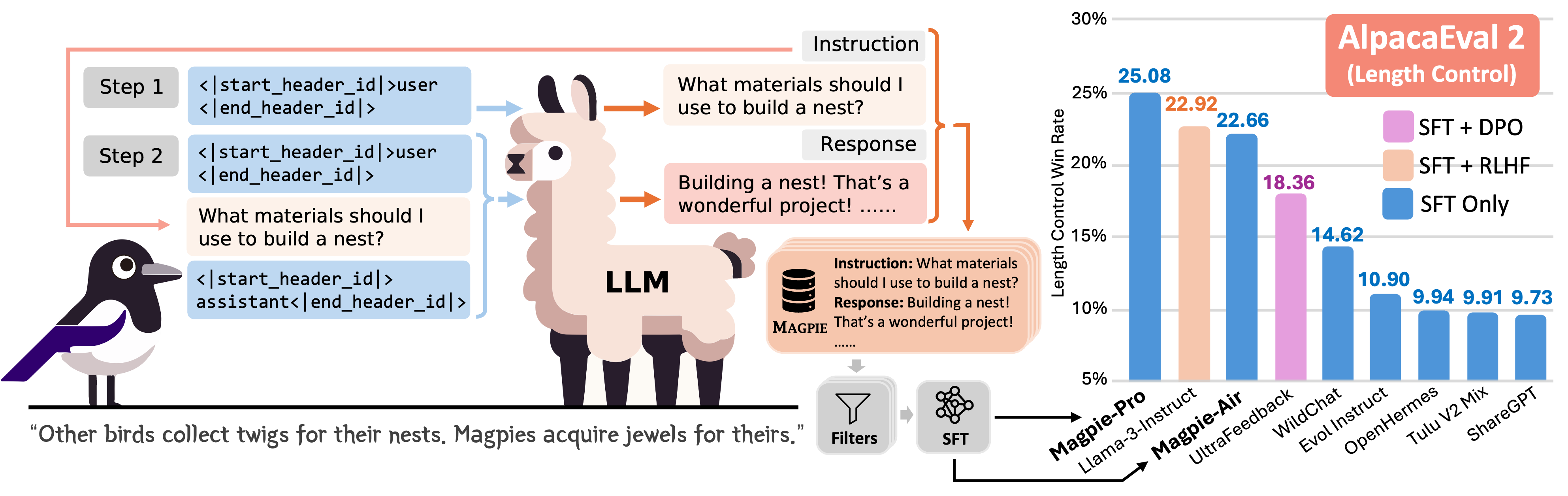
Magpie的核心思想非常简单而巧妙。研究人员发现,像Llama-3-Instruct这样已经对齐的大语言模型,当只输入左侧模板直到用户消息位置时,就可以自动生成一个用户查询。这是由于模型的自回归特性决定的。
基于这一发现,研究人员使用Llama-3-Instruct模型生成了400万条指令及其对应的回复。通过全面分析提取出的数据,他们最终筛选出了30万条高质量的样本。
Magpie数据的优势
为了比较Magpie数据与其他公开的指令数据集,研究人员使用不同的数据集对Llama-3-8B-Base模型进行了微调,并评估了微调后模型的性能。结果表明,在某些任务中,使用Magpie数据微调的模型性能可以与官方的Llama-3-8B-Instruct相媲美,尽管后者经过了1000万数据点的监督微调和后续的反馈学习。
更令人惊喜的是,仅使用Magpie进行监督微调就可以超越之前用于监督微调和偏好优化的公开数据集的表现,如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3738
3738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









