







SwanLab介绍
SwanLab是一款开源、轻量级的AI实验跟踪工具,提供了一个跟踪、比较、和协作实验的平台,旨在加速AI研发团队100倍的研发效率。其提供了友好的API和漂亮的界面,结合了超参数跟踪、指标记录、在线协作、实验链接分享、实时消息通知等功能,让您可以快速跟踪ML实验、可视化过程、分享给同伴。借助SwanLab,科研人员可以沉淀自己的每一次训练经验,与合作者无缝地交流和协作,机器学习工程师可以更快地开发可用于生产的模型。
本教程将介绍如何使用SwanLab来可视化跟踪魔乐社区上的模型微调,帮助大家了解SwanLab的能力。感兴趣的朋友也可以亲自上手感受一下。
友情链接:
-
魔乐社区:https://modelers.cn/docs/zh/openmind-library/0.9.1/overview.html
-
SwanLab项目官网:https://swanlab.cn
-
SwanLab离线版GitHub开源仓库:https://github.com/SwanHubX/SwanLab
2 微调代码
如果了解了上述的对应机制,那么就可以跑一个简单的微调代码了,该代码参考了魔乐社区的教程文档,稍作调整,可以对比NVIDIA显卡的结果。
2.1 概述
魔乐社区(Modelers.cn)是一个为人工智能开发者及爱好者打造的社区,提供工具链、数据集、模型和应用等AI领域生产要素的托管及展示服务和支撑系统。目前,魔乐社区已支持openMind Library。该工具通过简单的API接口,帮助开发者完成模型预训练、微调、推理等流程。同时,openMind Library原生兼容PyTorch 和 MindSpore 等主流框架,原生支持昇腾NPU处理器。openMind Library可以和PEFT、DeepSpeed等三方库配合使用,来提升模型微调效率。
2.2 环境配置
2.2.1 直接安装环境
如果是昇腾AI卡系列的话,配置环境前需要先安装驱动等设备,具体可以参考软件安装-CANN商用版8.0.RC3开发文档-昇腾社区。
驱动安装&验证
首先得确定有NPU卡和NPU相关驱动,驱动是8.0.RC3.beta1,如果没安装可以参考上面软件安装的链接查看。
安装好后的验证方法是运行下面的命令,该命令作用与nvidia-smi类似,这里是查看NPU的状态和性能
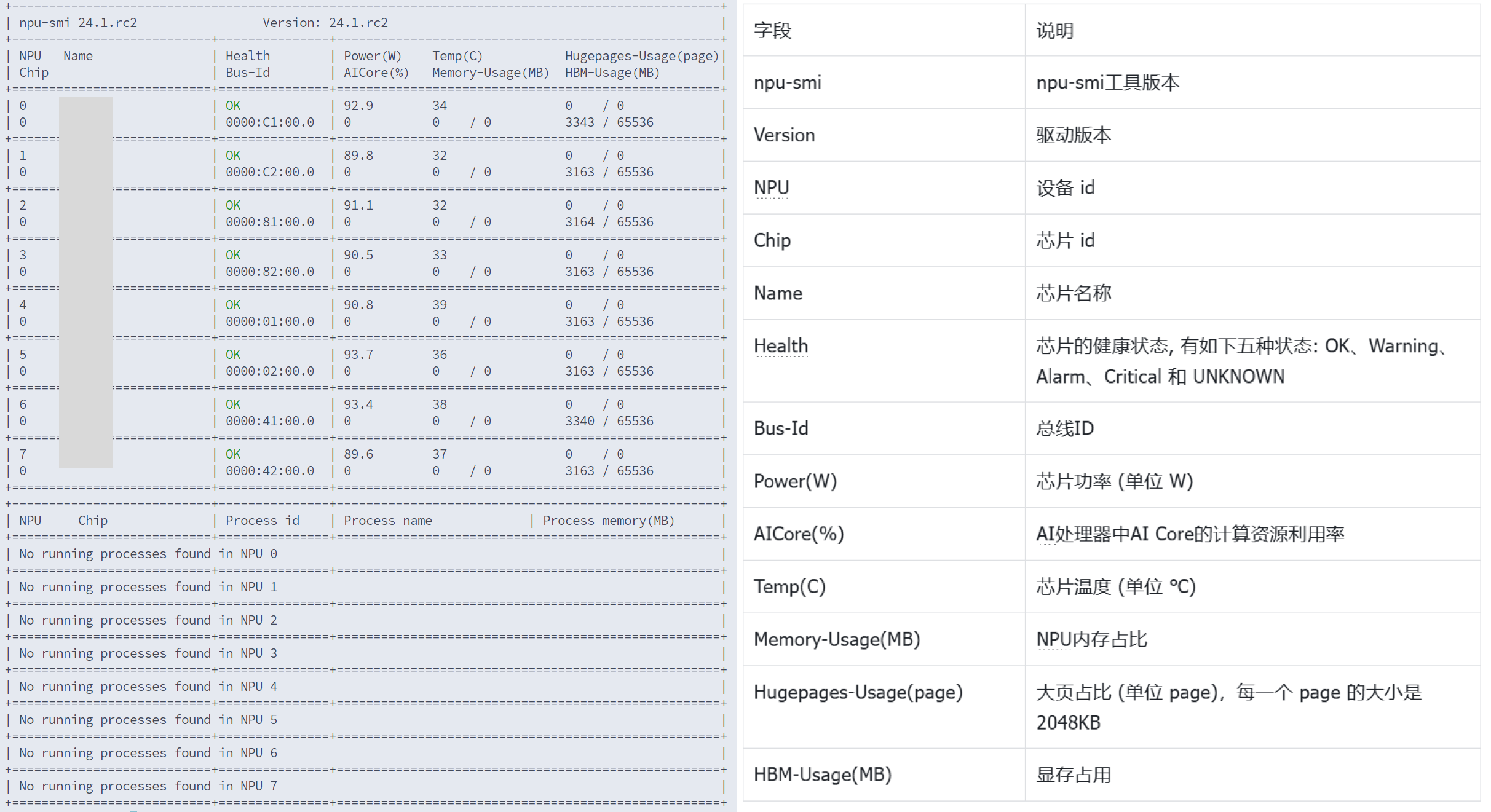
npu-smi info
可以看到如下信息的话就表示驱动已经安装完成了,左侧是安装成功后运行代码后的结果,右侧是每一部分的含义
安装好驱动之后就可以配置环境了,本次微调代码使用PyTorch框架,昇腾AI应用使能套件中自带了基于PyTorch框架的各类函数,因此正常安装就行。
安装命令如下:
# 下载PyTorch安装包
wget https://download.pytorch.org/whl/cpu/torch-2.4.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 下载torch_npu插件包
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc3-pytorch2.4.0/torch_npu-2.4.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 安装命令
pip3 install torch-2.4.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
pip3 install torch_npu-2.4.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 安装openMind Library
pip install openmind[pt]
# 安装SwanLab
pip install swanlab
注意以下几点:
- 可以使用镜像源来安装环境,不然会很浪费时间,可以使用清华源:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple name
- 魔乐社区的模型支持PyTorch和MindSpore两种不同框架。配置环境时,可根据需要选择其中一个框架进行配置。
2.2.2 docker环境安装(推荐)
魔乐社区官方库也提供了模型的docker环境。
推荐通过点击模型测试部分(下图红框)找到docker的链接,通过docker来拉起拉起环境。下面介绍docker环境的搭建教程。
首先得确定有NPU卡和NPU相关驱动,驱动是8.0.RC3.beta1,如果没安装可以参考CANN官方安装教程
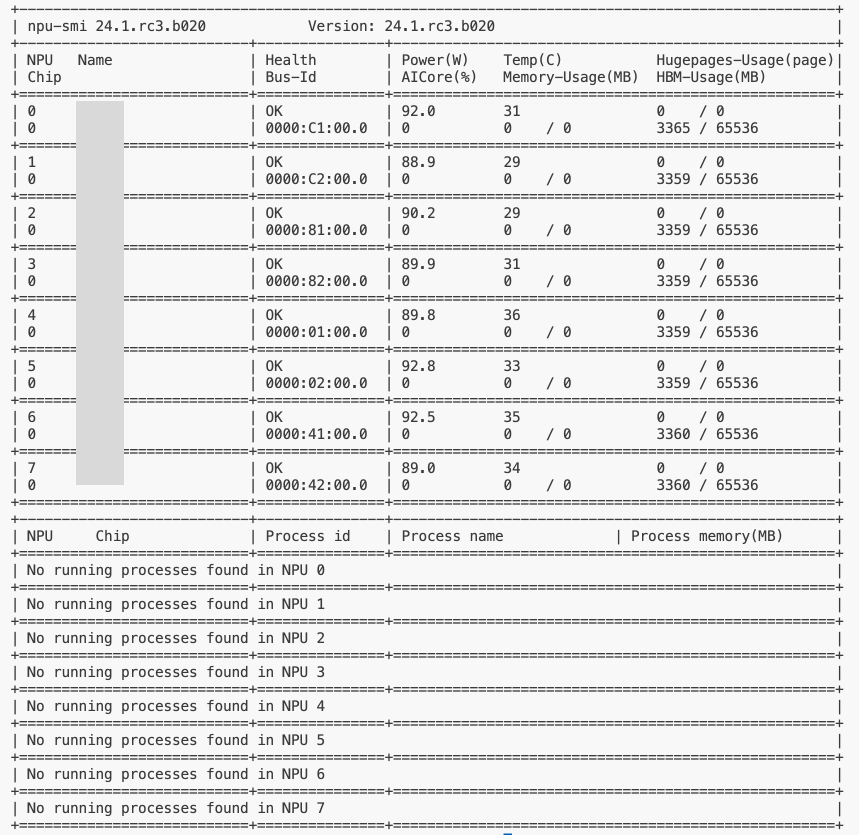
完成安装后检测方法是运行
npu-smi info
可以看到如下信息的话就表示驱动已经安装完成了。
接下来使用如下命令创建一个装好openmind环境的容器,这样可以省去大量安装环境的时间:
docker run \
--name openmind \
--device /dev/davinci0 \ # 指定NPU 0号设备
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-tid registry.modelers.cn/base_image/openmind:openeuler-python3.10-cann8.0.rc3.beta1-pytorch2.1.0-openmind0.9.1 bash
这将在后台开启一个名为openmind容器。使用如下命令可进入到容器当中
docker exec -it openmind bash
出现如下界面即表示进入到容器当中
最后在docker中运行如下命令安装SwanLab即可完成环境安装。
# 安装swanlab命令
pip install swanlab
2.3 数据集处理
OmDataset.load_dataset()方法目前支持下载的数据集格式如下:
- parquet
- json或者jsonl
- tar.gz
- csv
- 下载python脚本加载魔乐社区数据集
- 下载python脚本加载三方站点数据集
from openmind import OmDataset
from openmind import AutoTokenizer
### 准备数据集
dataset = OmDataset.load_dataset("AI_Connect/glue", "cola")
### 结果
"""
DatasetDict({
train: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 8551
})
validation: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 1043
})
test: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 1063
})
})
"""
### 加载分词器
tokenizer = AutoTokenizer.from_pretrained("PyTorch-NPU/bert_base_cased")
### 处理数据集
def tokenize_function(examples):
return tokenizer(examples["sentence"],truncation=True,padding="max_length",max_length=512)
### 训练数据封装
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 训练数据+验证数据,验证发生在每个epoch之后
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42)
small_eval_dataset = tokenized_datasets["validation"].shuffle(seed=42)
2.4 加载模型
和transformers使用差不多,分别加载模型和分词器
from openmind import AutoTokenizer
from openmind import AutoModelForSequenceClassification ## 做分类任务
### 加载分词器
tokenizer = AutoTokenizer.from_pretrained("PyTorch-NPU/bert_base_cased")
### 加载模型
model = AutoModelForSequenceClassification.from_pretrained("PyTorch-NPU/bert_base_cased", num_labels=2) # 二分类任务
2.5 训练参数配置
创建一个TrainingArguments类,其中包含可以调整的所有超参数以及不同的训练选项。
from openmind import TrainingArguments
### 参数初始化
# 指定保存训练检查点的路径
training_args = TrainingArguments(logging_steps=1,
output_dir="test_trainer",
evaluation_strategy="epoch",
half_precision_backend="auto", # auto:自动选择合适的混合精度训练后端;apex:英伟达的 ;cpu_amp:在CPU上运行
per_device_train_batch_size=4,
optim="adamw_torch",
learning_rate=2e-5)
2.6 评估参数设置
Trainer在训练过程中不会自动评估模型性能,需要向Trainer传递一个函数来计算和展示指标。
import numpy as np
from openmind import metrics
### 配置评估参数
metric = metrics.Accuracy()
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=-1)
return metric.compute(preds=preds, labels=labels)
2.7 可视化工具配置
swanlab支持记录openMind Library。能够在线/离线查看训练日志。SwanLab支持openMind Library通过callback调用,调用代码可参考后文。

关于SwanLab的使用方法可以参考SwanLab官方文档-快速开始
如果提示登录swanlab,可以在官网完成注册后,使用获取API KEY找到对应的登陆密钥并粘贴,这样将能够使用云上看版随时查看训练过程与结果。
from openmind import Trainer
from swanlab.integration.transformers import SwanLabCallback
### 使用swanlab监测
swanlab_config = {
"dataset": "glue",
"fp16_backend":"auto",
"datacollator":"transformer"
}
swanlab_callback = SwanLabCallback(
project="new_qwen2.5-7B-finetune",
experiment_name="跑的官方例子的微调",
description="这个是使用transformers的datacollator封装函数",
workspace=None,
config=swanlab_config,
)
### 创建训练器并且启动训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
callbacks=[swanlab_callback],
)
trainer.train()
### 保存模型
output_dir="./output"
final_save_path = join(output_dir)
trainer.save_model(final_save_path)
2.8 全过程代码
from openmind import OmDataset
from openmind import AutoTokenizer
from openmind import AutoModelForSequenceClassification
from openmind import TrainingArguments
from openmind import metrics
import numpy as np
from openmind import Trainer
from swanlab.integration.transformers import SwanLabCallback
from os.path import join
### 准备数据集
dataset = OmDataset.load_dataset("AI_Connect/glue", "cola")
### 加载分词器
tokenizer = AutoTokenizer.from_pretrained("PyTorch-NPU/bert_base_cased")
### 处理数据集
def tokenize_function(examples):
# 填充
return tokenizer(examples["sentence"],truncation=True,padding="max_length",max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 减少数据量
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42)
small_eval_dataset = tokenized_datasets["validation"].shuffle(seed=42)
### 加载模型
model = AutoModelForSequenceClassification.from_pretrained("PyTorch-NPU/bert_base_cased", num_labels=2)
### 参数初始化
# 指定保存训练检查点的路径
training_args = TrainingArguments(logging_steps=1,
output_dir="test_trainer",
evaluation_strategy="epoch",
half_precision_backend="auto", # auto:自动选择合适的混合精度训练后端;apex:英伟达的 ;cpu_amp:在CPU上运行
per_device_train_batch_size=4,
optim="adamw_torch",
learning_rate=2e-5)
### 配置评估参数
metric = metrics.Accuracy()
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=-1)
return metric.compute(preds=preds, labels=labels)
### 使用swanlab监测
swanlab_config = {
"dataset": "glue",
"fp16_backend":"auto",
"datacollator":"transformer"
}
swanlab_callback = SwanLabCallback(
project="new_qwen2.5-7B-finetune",
experiment_name="跑的官方例子的微调",
description="这个是使用transformers的datacollator封装函数",
workspace=None,
config=swanlab_config,
)
### 创建训练器并且启动训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
callbacks=[swanlab_callback],
)
trainer.train()
### 保存模型
output_dir="./output"
final_save_path = join(output_dir)
trainer.save_model(final_save_path)
这里使用HF Transformers实现同样的训练过程,使用NVIDIA-A100卡来跑了一次做个对比,A100对应的代码如下:
from datasets import load_dataset
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from transformers import TrainingArguments
import evaluate
import numpy as np
from transformers import Trainer
from swanlab.integration.transformers import SwanLabCallback
from os.path import join
import os
# 设置只使用第一个GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 使用第一块 GPU
### 加载数据集
dataset = load_dataset("nyu-mll/glue","cola")
### 加载分词器
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
### 处理数据集
def tokenize_function(examples):
# 填充
return tokenizer(examples["sentence"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 减少数据量
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42)
small_eval_dataset = tokenized_datasets["validation"].shuffle(seed=42)
### 加载模型
model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=2)
### 参数初始化
# 指定保存训练检查点的路径
training_args = TrainingArguments(logging_steps=1,
output_dir="test_trainer",
evaluation_strategy="epoch",
half_precision_backend="auto",
per_device_train_batch_size=4,
optim="adamw_torch",
learning_rate=2e-5)
### 配置评估参数
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=-1)
# 添加评估数据
metric.add_batch(predictions=preds, references=labels) # 使用add_batch方法添加批次数据
# 计算准确度
return metric.compute()
### 使用swanlab监测
swanlab_config = {
"dataset": "glue"
}
swanlab_callback = SwanLabCallback(
project="new_qwen2.5-7B-finetune",
experiment_name="跑的官方例子的微调",
description="用例子跑的,模型用的是bert,做文本分类任务",
workspace=None,
config=swanlab_config,
)
### 创建训练器并且启动训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
callbacks=[swanlab_callback],
)
trainer.train()
### 保存模型
output_dir="./output/A100"
final_save_path = join(output_dir)
trainer.save_model(final_save_path)
3 结果展示
下面是Ascend NPU与A100实验对比:
首先是实验时间,此次实验epoch=3,
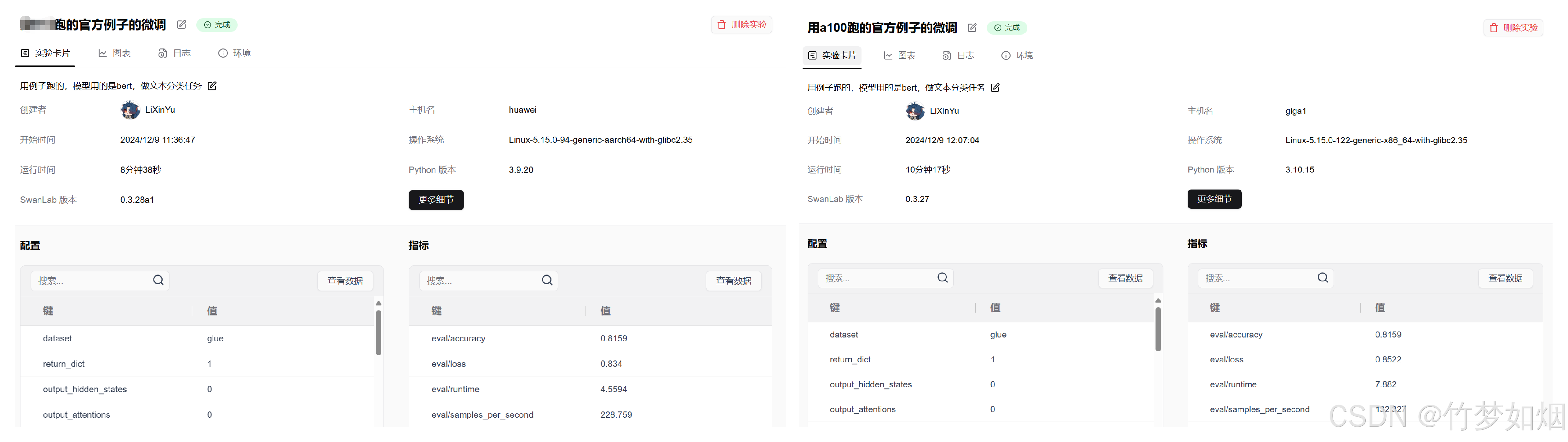
看样子昇腾卡比A100稍微快点
然后是显存消耗,其中两个监测NPU/GPU状态的代码如下:
# NPU:
watch -n 1 npu-smi info
# GPU:
nvtop
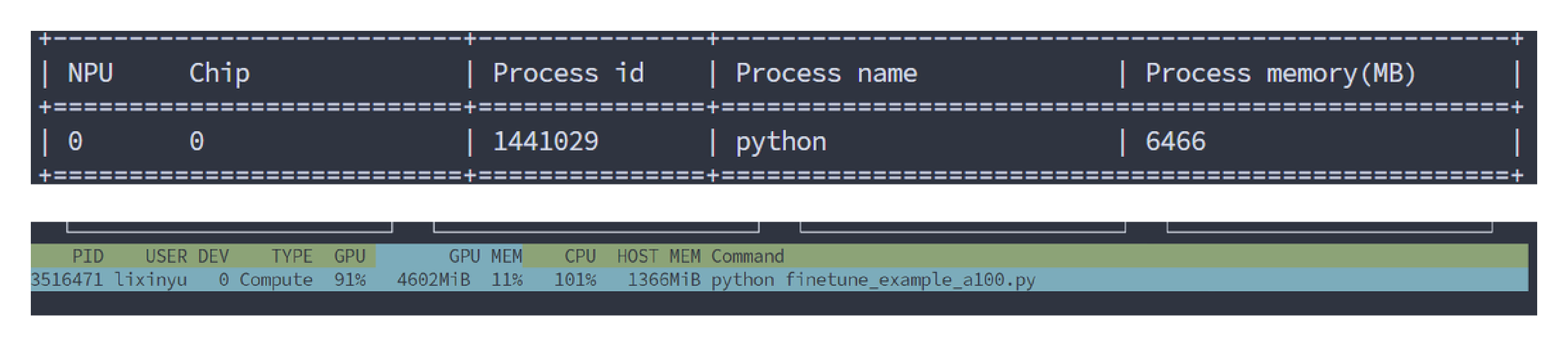
显存消耗差不多
最后是loss等参数的变化
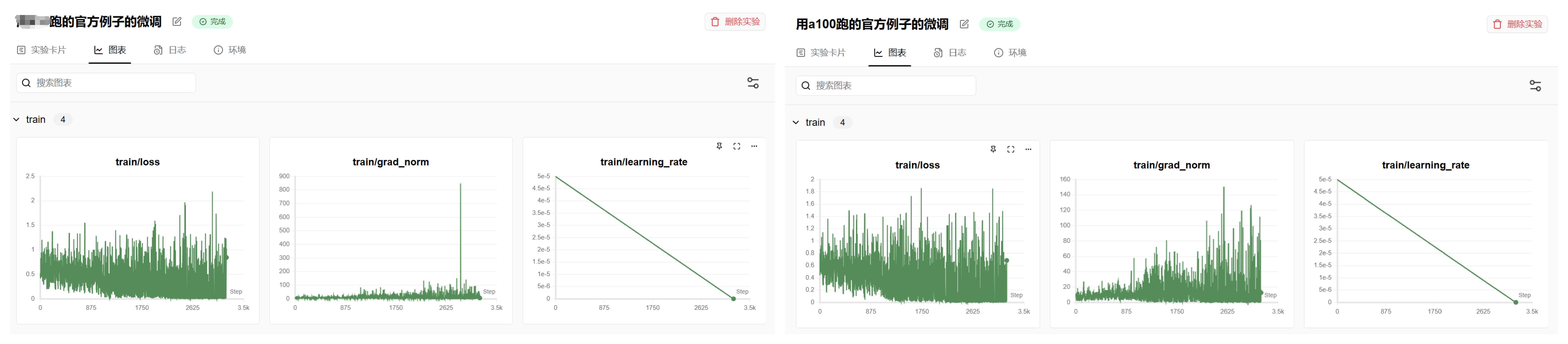
感觉A100上运行的结果震荡比较明显,昇腾卡震荡比较少。
以上便是使用SwanLab来可视化跟踪模型微调过程,欢迎大家尝试!
如您在尝试过程中遇到任何问题或建议,欢迎访问魔乐社区的帮助中心进行反馈(https://gitee.com/modelers/feedback)。

















 1738
1738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









