






LISA项目简介
LISA(Large Language Instructed Segmentation Assistant)是一个基于大语言模型的图像分割推理系统,由香港中文大学等机构的研究者开发。该系统能够根据自然语言指令生成图像分割结果,并提供解释性输出,实现了复杂推理、世界知识应用、多轮对话等能力。

主要特点
- 支持复杂推理:能够理解并执行需要推理能力的分割任务
- 应用世界知识:利用大语言模型的知识解答问题
- 提供解释性输出:不仅给出分割结果,还能解释原因
- 支持多轮对话:可以进行连续的问答交互
- 零样本能力强:仅用少量数据就能实现良好效果
相关资源
1. 项目主页
2. 论文
3. 模型
4. 数据集
5. 在线演示
使用指南
- 安装依赖:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
-
下载预训练模型
-
运行推理:
python chat.py --version='xinlai/LISA-13B-llama2-v1'
- 本地部署:
python app.py --version='xinlai/LISA-13B-llama2-v1 --load_in_4bit'
更多详细使用说明请参考GitHub README。
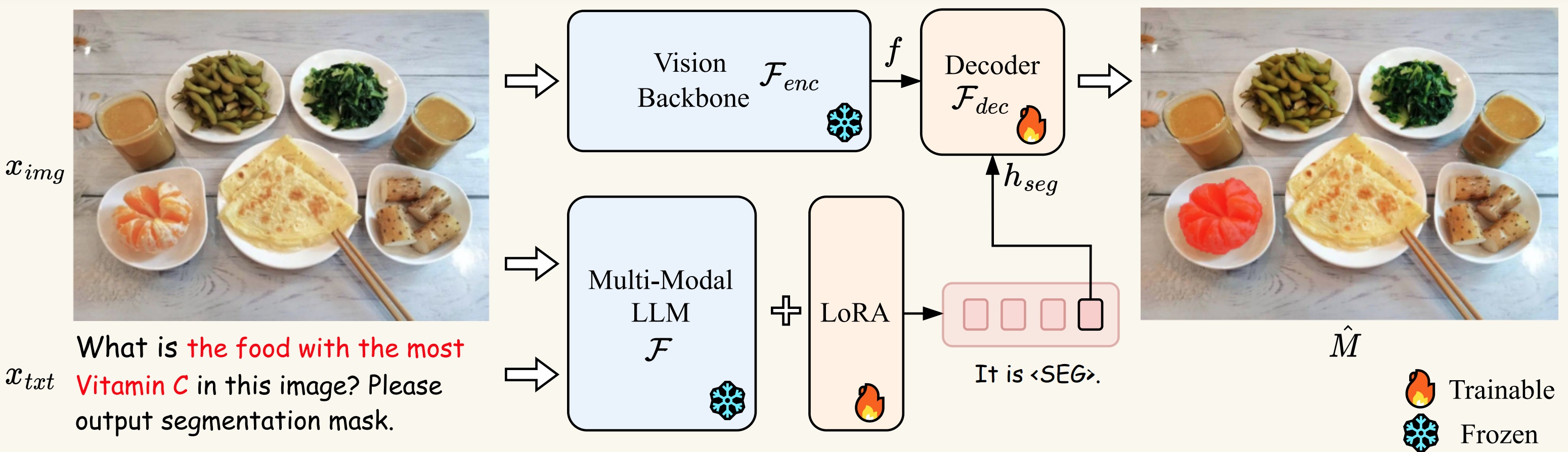
LISA项目为研究人员和开发者提供了一个强大的视觉-语言推理工具,欢迎大家尝试使用并为项目做出贡献!
文章链接;www.dongaigc.com/a/lisa-learning-resources-summary
https://www.dongaigc.com/a/lisa-learning-resources-summary
www.dongaigc.com/p/dvlab-research/LISA
https://www.dongaigc.com/p/dvlab-research/LISA

















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









