






Casibase:开源AI知识库与企业级RAG解决方案
在人工智能和大语言模型快速发展的今天,如何有效管理企业知识并利用AI技术提升生产力,已成为众多组织面临的重要课题。Casibase作为一款开源的AI知识库和检索增强生成(RAG)系统,为这一需求提供了强大而灵活的解决方案。本文将全面介绍Casibase的特性、架构和应用场景,帮助读者了解这一创新工具如何赋能企业知识管理与智能化转型。
Casibase简介
Casibase是一个开源的AI知识库和RAG(检索增强生成)系统,提供Web界面和企业级单点登录功能,支持OpenAI、Azure、LLaMA、Google Gemini、HuggingFace、Claude、Grok等多种主流AI模型。它的核心目标是帮助企业构建智能化的知识管理系统,实现高效的信息检索和智能问答。
Casibase的主要特点包括:
- 开源免费:采用Apache 2.0开源协议,可以自由使用和定制。
- 多模型支持:集成了主流的AI语言模型,满足不同场景需求。
- Web界面:提供友好的用户界面,方便管理和使用。
- 企业级功能:支持单点登录(SSO)等企业级特性。
- RAG技术:采用检索增强生成技术,提高问答准确性。
- 多语言支持:支持中文、英文等多种语言。
系统架构
Casibase采用前后端分离的架构设计,主要包含以下两个部分:
- 前端:使用JavaScript和React开发,提供用户界面。
- 后端:采用Golang + Beego + Python + Flask + MySQL技术栈,实现服务器端逻辑和API。
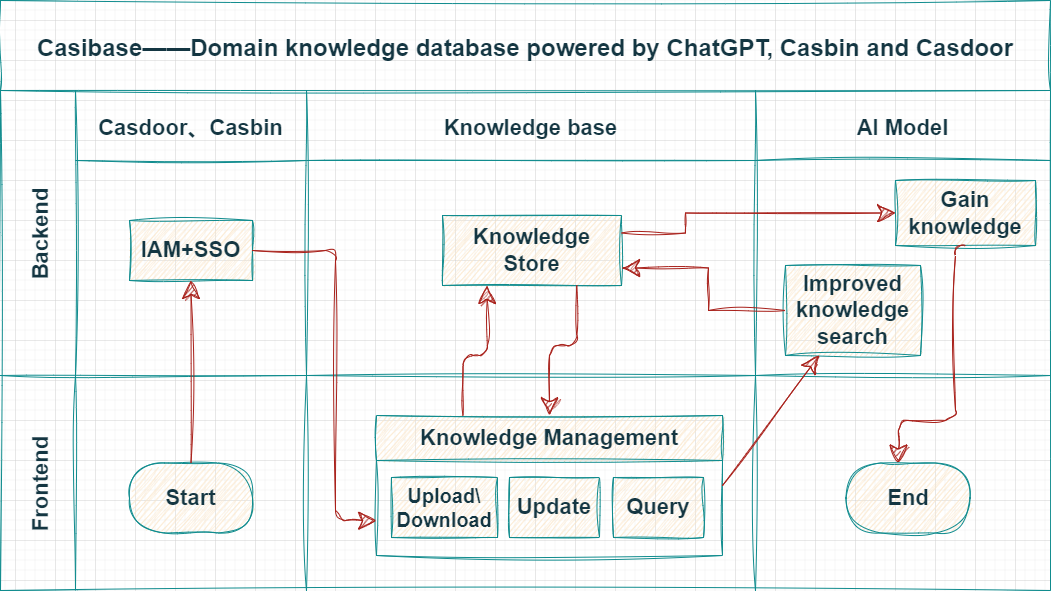
这种架构设计使得Casibase具有良好的可扩展性和可维护性,能够适应不同规模企业的需求。
核心功能
1. 多模型集成
Casibase支持多种主流AI语言模型,包括:
- OpenAI系列:GPT-3.5、GPT-4等
- Hugging Face模型:LLaMA、BLOOM等
- Claude
- Google Gemini
- 百度文心一言
- 讯飞星火
- ChatGLM
- MiniMax
这种多模型支持使得用户可以根据具体需求选择最适合的AI模型,在性能、成本和特性之间找到平衡点。
2. 文档处理与AI辅助
Casibase支持多种文档格式,包括txt、markdown、docx、pdf等。系统能够智能解析这些文档,并结合嵌入式AI助手提供实时在线聊天和手动会话交接功能。这一特性大大提升了知识管理的效率和智能化程度。
3. 企业级功能与多语言支持
作为面向企业用户的解决方案,Casibase提供了多用户和多租户功能,支持企业级单点登录(SSO)。同时,系统还具备全面的聊天会话日志记录功能,方便审计和分析。在语言支持方面,Casibase提供了中文、英文等多语言界面,满足国际化需求。
应用场景
Casibase的应用场景非常广泛,以下是几个典型的使用案例:
-
企业知识库:将公司的各类文档、规章制度、产品信息等整合到Casibase中,员工可以通过自然语言查询快速获取所需信息。
-
客户服务:构建智能客服系统,利用RAG技术提供准确的产品咨询和问题解答。
-
研发协作:在研发团队中部署Casibase,可以快速检索技术文档、代码示例等,提高开发效率。
-
培训系统:将培训材料导入Casibase,新员工可以通过对话式交互快速学习公司知识。
-
决策支持:管理层可以利用Casibase快速获取数据分析结果和市场洞察,辅助决策制定。
部署与使用
Casibase提供了多种部署方式,包括Docker容器化部署和源码安装。用户可以根据自身需求选择合适的方式。以下是使用Docker进行快速部署的步骤:
- 安装Docker
- 拉取Casibase镜像:
docker pull casbin/casibase - 运行容器:
docker run -p 8000:8000 casbin/casibase
部署完成后,可以通过浏览器访问http://localhost:8000来使用Casibase的Web界面。
社区与支持
Casibase拥有活跃的开源社区,用户可以通过以下渠道获取支持和参与贡献:
- GitHub仓库:GitHub - casibase/casibase: Spising: ⚡️Open-source AI LangChain-like RAG (Retrieval-Augmented Generation) knowledge database with web UI and Enterprise SSO⚡️, supports OpenAI, Azure, LLaMA, Google Gemini, HuggingFace, Claude, Grok, etc., chat bot demo: https://demo.casibase.com, admin UI demo: https://demo-admin.casibase.com
- 文档网站:https://casibase.org
- Discord社区:https://discord.gg/devUNrWXrh
对于有定制化需求的企业用户,Casibase团队也提供专业的技术支持和咨询服务。
未来展望
作为一个快速发展的开源项目,Casibase的未来发展方向包括:
- 持续集成更多AI模型,扩大兼容性。
- 优化RAG技术,提高问答准确性和效率。
- 增强数据安全和隐私保护功能。
- 开发更多行业特定的插件和模块。
- 提供更丰富的可视化和分析工具。
结语
Casibase作为一款功能强大的开源AI知识库和RAG系统,为企业提供了构建智能化知识管理平台的有力工具。它的多模型支持、企业级功能和灵活的架构设计,使其能够适应各种复杂的应用场景。随着AI技术的不断进步,Casibase也将持续演进,为用户提供更智能、更高效的知识管理解决方案。无论是中小企业还是大型组织,都可以通过Casibase释放知识的力量,提升生产力和创新能力。
文章链接:www.dongaigc.com/a/casibase-open-source-ai-knowledge-base-2
https://www.dongaigc.com/a/casibase-open-source-ai-knowledge-base-2
www.dongaigc.com/p/casibase/casibase
https://www.dongaigc.com/p/casibase/casibase

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









