







一,RDD道路瑕疵数据集,一共两万多张图片,已经标注好,txt格式,已经划分好训练集和验证集,yolo模型可直接训练道路裂缝,坑洼,病害数据集
标签包括 纵向裂缝(0), 横向裂缝(1), 鳄鱼裂缝(2), 坑洼(3).
,一,道路裂缝两万张,已标注,txt,已划分训练集和验证集,yolo模型可直接训练 二,道路裂缝数据,坑洼,病害数据集无人机视角,摩托车视角,车辆视角覆盖道路所有问题八类16000
RDD2022道路瑕疵数据集介绍
数据集概述
此数据集专为道路瑕疵检测设计,包含了四种常见的道路瑕疵类型的高清图像及相应的标注文件。数据集涵盖了纵向裂缝、横向裂缝、鳄鱼裂缝和坑洼等常见的道路瑕疵类型,并且每个类别都有详细的标注信息。该数据集已经按照YOLO格式进行了标注,并且划分好了训练集和验证集,可以直接用于YOLO模型的训练。
数据集特点
- 高清影像:所有图像均为高清影像,适合用于精确的道路瑕疵检测。
- 详细标注:每张图像都标注了不同道路瑕疵的位置,可以用于训练模型来识别这些瑕疵。
- 多样性:涵盖了不同类型的道路瑕疵,适用于多种环境下的应用。
- 直接可用性:数据集已按照标准YOLO TXT格式标注,无需进一步处理即可直接用于模型训练。
- 多类别:数据集中标注了四种类别,适合进行多目标检测任务。
数据集统计
数据集结构
RDD2022RoadDefectDetectionDataset/
├── images/ # 图像文件
│ ├── train/ # 训练集图像
│ │ ├── image_00001.jpg
│ │ ├── image_00002.jpg
│ │ └── ...
│ └── val/ # 验证集图像
│ ├── image_00001.jpg
│ ├── image_00002.jpg
│ └── ...
└── labels/ # YOLO格式标注文件夹
├── train/ # 训练集标签
│ ├── image_00001.txt
│ ├── image_00002.txt
│ └── ...
└── val/ # 验证集标签
├── image_00001.txt
├── image_00002.txt
└── ...标注格式示例
YOLO格式
每行表示一个物体的边界框和类别:
class_id cx cy w hclass_id:类别ID(从0开始编号)- 0:
Longitudinal Crack(纵向裂缝) - 1:
Transverse Crack(横向裂缝) - 2:
Alligator Crack(鳄鱼裂缝) - 3:
Pothole(坑洼)
- 0:
cx:目标框中心点x坐标 / 图像宽度。cy:目标框中心点y坐标 / 图像高度。w:目标框宽度 / 图像宽度。h:目标框高度 / 图像高度。
例如:
0 0.453646 0.623148 0.234375 0.461111
1 0.553646 0.723148 0.134375 0.361111
2 0.353646 0.823148 0.154375 0.261111使用该数据集进行模型训练
1. 数据预处理与加载
首先,我们需要加载数据并将其转换为适合YOLOv5等模型使用的格式。假设你已经安装了PyTorch和YOLOv5。
import os
from PIL import Image
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class RoadDefectDetectionDataset(Dataset):
def __init__(self, image_dir, label_dir, transform=None):
self.image_dir = image_dir
self.label_dir = label_dir
self.transform = transform
self.image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg')]
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_name = self.image_files[idx]
img_path = os.path.join(self.image_dir, img_name)
label_path = os.path.join(self.label_dir, img_name.replace('.jpg', '.txt'))
# 加载图像
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
# 加载标注
with open(label_path, 'r') as file:
lines = file.readlines()
boxes = []
labels = []
for line in lines:
class_id, cx, cy, w, h = map(float, line.strip().split())
xmin = (cx - w / 2) * image.width
ymin = (cy - h / 2) * image.height
xmax = (cx + w / 2) * image.width
ymax = (cy + h / 2) * image.height
boxes.append([xmin, ymin, xmax, ymax])
labels.append(int(class_id))
boxes = torch.tensor(boxes, dtype=torch.float32)
labels = torch.tensor(labels, dtype=torch.int64)
return image, boxes, labels
# 数据增强
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机颜色变换
transforms.Resize((640, 640)),
transforms.ToTensor(),
])
# 创建数据集
train_dataset = RoadDefectDetectionDataset(image_dir='RDD2022RoadDefectDetectionDataset/images/train/', label_dir='RDD2022RoadDefectDetectionDataset/labels/train/', transform=transform)
val_dataset = RoadDefectDetectionDataset(image_dir='RDD2022RoadDefectDetectionDataset/images/val/', label_dir='RDD2022RoadDefectDetectionDataset/labels/val/', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False, num_workers=4)2. 构建模型
我们可以使用YOLOv5模型进行目标检测任务。假设你已经克隆了YOLOv5仓库,并按照其文档进行了环境设置。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt创建数据配置文件 data/rdd2022_road_defect_detection.yaml:
train: path/to/RDD2022RoadDefectDetectionDataset/images/train
val: path/to/RDD2022RoadDefectDetectionDataset/images/val
nc: 4 # 类别数
names: ['Longitudinal Crack', 'Transverse Crack', 'Alligator Crack', 'Pothole']3. 训练模型
使用YOLOv5进行训练。
python train.py --img 640 --batch 16 --epochs 100 --data data/rdd2022_road_defect_detection.yaml --weights yolov5s.pt --cache4. 评估模型
在验证集上评估模型性能。
python val.py --img 640 --batch 16 --data data/rdd2022_road_defect_detection.yaml --weights runs/train/exp/weights/best.pt --task test5. 推理
使用训练好的模型进行推理。
python detect.py --source path/to/test/image.jpg --weights runs/train/exp/weights/best.pt --conf 0.5实验报告
实验报告应包括以下内容:
- 项目简介:简要描述项目的背景、目标和意义。
- 数据集介绍:详细介绍数据集的来源、规模、标注格式等。
- 模型选择与配置:说明选择的模型及其配置参数。
- 训练过程:记录训练过程中的损失变化、学习率调整等。
- 评估结果:展示模型在验证集上的性能指标(如mAP、准确率)。
- 可视化结果:提供一些典型样本的检测结果可视化图。
- 结论与讨论:总结实验结果,讨论可能的改进方向。
- 附录:包含代码片段、图表等补充材料。
数据增强
由于数据集规模较大,可以考虑使用数据增强技术来增加训练集的多样性,从而提高模型的泛化能力。可以使用的数据增强技术包括但不限于:
- 随机旋转和裁剪
- 随机水平翻转
- 随机颜色变换
依赖库
确保安装了以下依赖库:
pip install torch torchvision
pip install -r yolov5/requirements.txt总结
这个RDD2022道路瑕疵检测数据集提供了丰富的标注数据,非常适合用于训练和评估道路瑕疵检测模型。通过YOLOv5框架,可以方便地构建和训练高性能的道路瑕疵检测模型。实验报告可以帮助你更好地理解和分析模型的表现,并为进一步的研究提供参考。由于数据集规模较大,建议在训练过程中使用数据增强技术以提高模型的泛化能力。
二,道路裂缝,坑洼,病害数据集

包括无人机视角,摩托车视角,车辆视角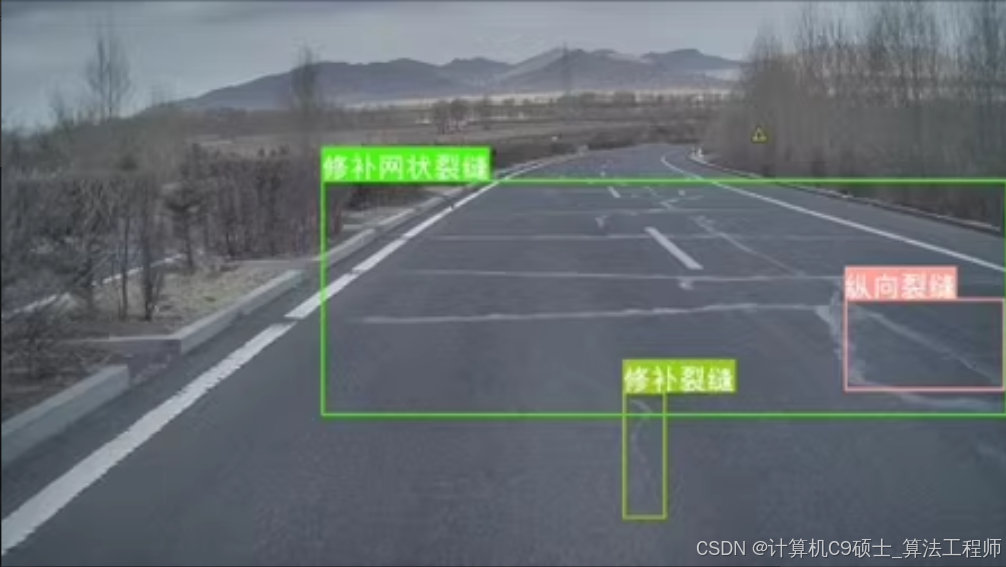
覆盖道路所有问题
一共有八类16000张

0到7依次为: ['横向裂缝', '纵向裂缝', '块状裂缝', '龟裂', '坑槽', '修补网状裂缝', '修补裂缝', '修补坑槽']

数据集概述
此数据集专为道路裂缝、坑洼及其他病害检测设计,包含了八种常见道路问题的高清图像及相应的标注文件。数据集涵盖了不同的视角(无人机视角、摩托车视角、车辆视角),并且每个类别都有详细的标注信息。该数据集已经按照YOLO格式进行了标注,并且划分好了训练集和验证集,可以直接用于YOLO模型的训练。
数据集特点
- 高清影像:所有图像均为高清影像,适合用于精确的道路病害检测。
- 详细标注:每张图像都标注了不同道路病害的位置,可以用于训练模型来识别这些病害。
- 多样性:涵盖了不同视角下的道路病害,适用于多种环境下的应用。
- 直接可用性:数据集已按照标准YOLO TXT格式标注,无需进一步处理即可直接用于模型训练。
- 多类别:数据集中标注了八种类别,适合进行多目标检测任务。
数据集统计
| 病害类型 | 类别ID | 图片数量 | 标注个数 |
|---|---|---|---|
| Transverse Crack (横向裂缝) | 0 | 未知 | 未知 |
| Longitudinal Crack (纵向裂缝) | 1 | 未知 | 未知 |
| Block Crack (块状裂缝) | 2 | 未知 | 未知 |
| Alligator Crack (龟裂) | 3 | 未知 | 未知 |
| Rut (坑槽) | 4 | 未知 | 未知 |
| Mesh Repair (修补网状裂缝) | 5 | 未知 | 未知 |
| Patch Repair (修补裂缝) | 6 | 未知 | 未知 |
| Patch Rut (修补坑槽) | 7 | 未知 | 未知 |
| 总计 | 16,000 | 未知 |
数据集结构
RoadCrackAndDefectDetectionDataset/
├── images/ # 图像文件
│ ├── train/ # 训练集图像
│ │ ├── image_00001.jpg
│ │ ├── image_00002.jpg
│ │ └── ...
│ └── val/ # 验证集图像
│ ├── image_00001.jpg
│ ├── image_00002.jpg
│ └── ...
└── labels/ # YOLO格式标注文件夹
├── train/ # 训练集标签
│ ├── image_00001.txt
│ ├── image_00002.txt
│ └── ...
└── val/ # 验证集标签
├── image_00001.txt
├── image_00002.txt
└── ...标注格式示例
YOLO格式
每行表示一个物体的边界框和类别:
class_id cx cy w hclass_id:类别ID(从0开始编号)- 0:
Transverse Crack(横向裂缝) - 1:
Longitudinal Crack(纵向裂缝) - 2:
Block Crack(块状裂缝) - 3:
Alligator Crack(龟裂) - 4:
Rut(坑槽) - 5:
Mesh Repair(修补网状裂缝) - 6:
Patch Repair(修补裂缝) - 7:
Patch Rut(修补坑槽)
- 0:
cx:目标框中心点x坐标 / 图像宽度。cy:目标框中心点y坐标 / 图像高度。w:目标框宽度 / 图像宽度。h:目标框高度 / 图像高度。
例如:
0 0.453646 0.623148 0.234375 0.461111
1 0.553646 0.723148 0.134375 0.361111
2 0.353646 0.823148 0.154375 0.261111使用该数据集进行模型训练
1. 数据预处理与加载
首先,我们需要加载数据并将其转换为适合YOLOv5等模型使用的格式。假设你已经安装了PyTorch和YOLOv5。
import os
from PIL import Image
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class RoadCrackAndDefectDetectionDataset(Dataset):
def __init__(self, image_dir, label_dir, transform=None):
self.image_dir = image_dir
self.label_dir = label_dir
self.transform = transform
self.image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg')]
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_name = self.image_files[idx]
img_path = os.path.join(self.image_dir, img_name)
label_path = os.path.join(self.label_dir, img_name.replace('.jpg', '.txt'))
# 加载图像
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
# 加载标注
with open(label_path, 'r') as file:
lines = file.readlines()
boxes = []
labels = []
for line in lines:
class_id, cx, cy, w, h = map(float, line.strip().split())
xmin = (cx - w / 2) * image.width
ymin = (cy - h / 2) * image.height
xmax = (cx + w / 2) * image.width
ymax = (cy + h / 2) * image.height
boxes.append([xmin, ymin, xmax, ymax])
labels.append(int(class_id))
boxes = torch.tensor(boxes, dtype=torch.float32)
labels = torch.tensor(labels, dtype=torch.int64)
return image, boxes, labels
# 数据增强
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机颜色变换
transforms.Resize((640, 640)),
transforms.ToTensor(),
])
# 创建数据集
train_dataset = RoadCrackAndDefectDetectionDataset(image_dir='RoadCrackAndDefectDetectionDataset/images/train/', label_dir='RoadCrackAndDefectDetectionDataset/labels/train/', transform=transform)
val_dataset = RoadCrackAndDefectDetectionDataset(image_dir='RoadCrackAndDefectDetectionDataset/images/val/', label_dir='RoadCrackAndDefectDetectionDataset/labels/val/', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False, num_workers=4)2. 构建模型
我们可以使用YOLOv5模型进行目标检测任务。假设你已经克隆了YOLOv5仓库,并按照其文档进行了环境设置。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txttrain: path/to/RoadCrackAndDefectDetectionDataset/images/train
val: path/to/RoadCrackAndDefectDetectionDataset/images/val
nc: 8 # 类别数
names: ['Transverse Crack', 'Longitudinal Crack', 'Block Crack', 'Alligator Crack', 'Rut', 'Mesh Repair', 'Patch Repair', 'Patch Rut']3. 训练模型
使用YOLOv5进行训练。
python train.py --img 640 --batch 16 --epochs 100 --data data/road_crack_and_defect_detection.yaml --weights yolov5s.pt --cache4. 评估模型
在验证集上评估模型性能。
python val.py --img 640 --batch 16 --data data/road_crack_and_defect_detection.yaml --weights runs/train/exp/weights/best.pt --task test5. 推理
使用训练好的模型进行推理。
python detect.py --source path/to/test/image.jpg --weights runs/train/exp/weights/best.pt --conf 0.5实验报告
实验报告应包括以下内容:
- 项目简介:简要描述项目的背景、目标和意义。
- 数据集介绍:详细介绍数据集的来源、规模、标注格式等。
- 模型选择与配置:说明选择的模型及其配置参数。
- 训练过程:记录训练过程中的损失变化、学习率调整等。
- 评估结果:展示模型在验证集上的性能指标(如mAP、准确率)。
- 可视化结果:提供一些典型样本的检测结果可视化图。
- 结论与讨论:总结实验结果,讨论可能的改进方向。
- 附录:包含代码片段、图表等补充材料。
数据增强
由于数据集规模较大,可以考虑使用数据增强技术来增加训练集的多样性,从而提高模型的泛化能力。可以使用的数据增强技术包括但不限于:
- 随机旋转和裁剪
- 随机水平翻转
- 随机颜色变换
依赖库
确保安装了以下依赖库:
pip install torch torchvision
pip install -r yolov5/requirements.txt总结
这个道路裂缝、坑洼、病害检测数据集提供了丰富的标注数据,非常适合用于训练和评估道路病害检测模型。通过YOLOv5框架,可以方便地构建和训练高性能的道路病害检测模型。实验报告可以帮助你更好地理解和分析模型的表现,并为进一步的研究提供参考。由于数据集规模较大,建议在训练过程中使用数据增强技术以提高模型的泛化能力。

















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









