






2024深度学习发论文&模型涨点之——多模态对齐
多模态本质就是alignment(对齐),那么问题就在于如何做对齐。有用entity的,有用attention的,有用event做alignment,然后再做fusion(融合)。融合有多种方法,例如Linking、Grounding、Structure等。
多模态对齐通过整合不同模态的信息,使得模型能够从更全面的数据中学习,从而提高分类、回归等任务的性能。例如,在视频分类、事件检测、情感分析等跨媒体分析中,多模态融合技术能够提高模型的准确率。
我整理了一些多模态对齐【论文+代码】合集,需要的同学公人人人号【AI创新工场】自取。
论文精选
论文1:
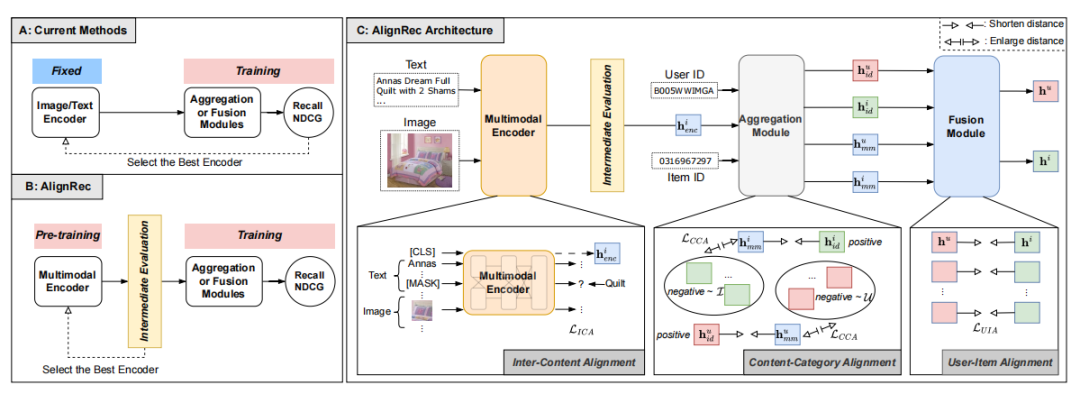
AlignRec: Aligning and Training in Multimodal Recommendations
AlignRec:多模态推荐中的对齐与训练
方法
推荐目标分解:将推荐目标分解为内容内对齐、内容与分类ID对齐以及用户与项对齐三个部分,每个部分都有特定的目标函数。
多模态特征预训练:首先预训练内容内对齐任务,以获得统一的多模态特征,然后使用这些特征作为输入,与后续两个对齐任务一起训练。
多模态编码器:使用基于注意力的跨模态编码器来对齐不同内容模态领域,输出单一项目的统一模态表示。
对齐目标函数:为每个对齐任务设计特定的目标函数,包括内容内对齐、内容-分类对齐和用户-项对齐。
创新点
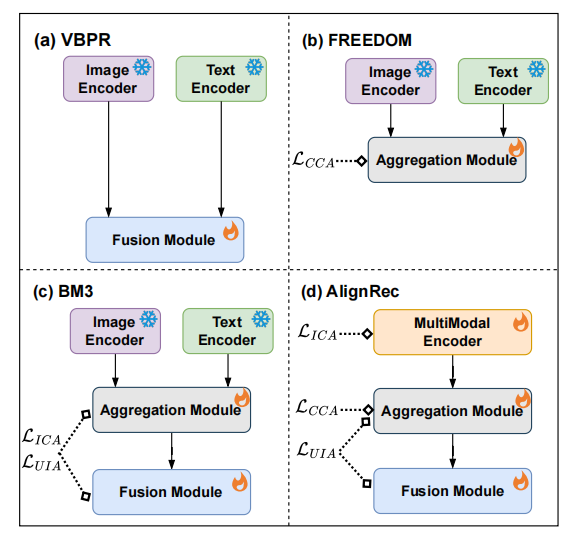
系统性解决方案:首次提出AlignRec,系统性地分析并解决了多模态推荐中的对齐问题,该方法可以无缝集成到现有方法中。
预训练与联合训练策略:设计了先预训练内容对齐任务,然后根据推荐目标进一步训练对齐任务的训练策略,有效解决了内容模态和分类模态之间潜在的学习速度不一致问题。
中间评估协议:提供了三个新的中间评估协议来评估多模态特征的有效性,帮助选择更好的编码器,并加速推荐模型的迭代。
性能提升:在三个真实世界数据集上的广泛实验一致验证了AlignRec相比九个基线模型的优越性,性能提升包括在Recall@20指标上平均提升6.19%,在NDCG@20指标上平均提升4.88%。
论文2:
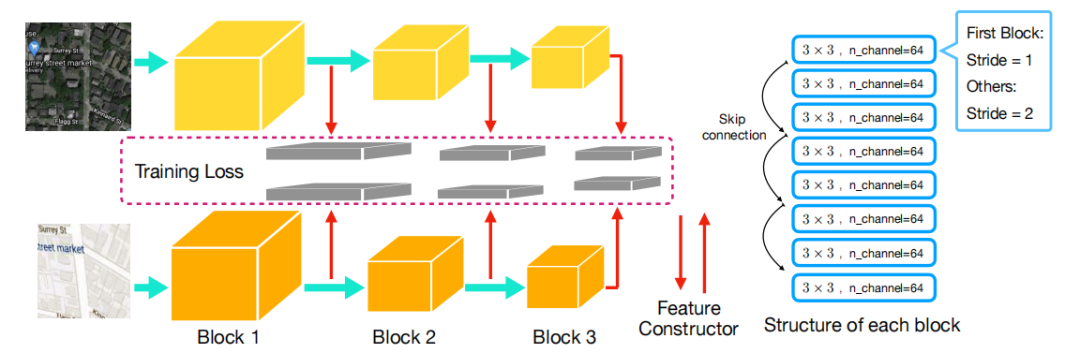
Deep Lucas-Kanade Homography for Multimodal Image Alignment
用于多模态图像对齐的深度Lucas-Kanade单应性
方法
深度Lucas-Kanade特征图(DLKFM):构建了DLKFM,能够自动识别在各种外观变化条件下的不变特征。
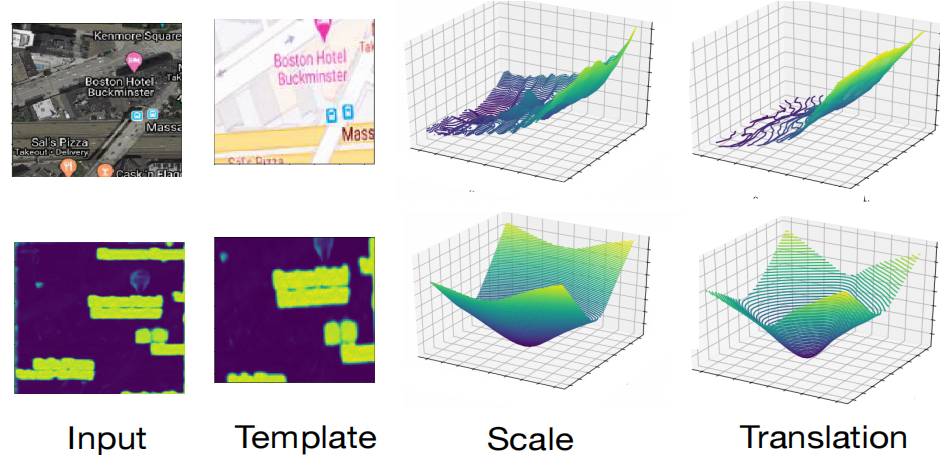
亮度一致性:模板特征图与输入特征图保持亮度一致性,使得它们在对齐时颜色差异很小。
光滑景观目标函数:基于DLKFM的Lucas-Kanade目标函数在真实单应性参数周围具有平滑的景观,使得迭代解可以轻松收敛到真实值。
创新点
DLKFM的提出:提出了深度Lucas-Kanade特征图(DLKFM),能够自动识别多模态情况下的不变特征,提高了对齐的准确性。
亮度一致性与收敛性:设计了特殊的损失函数,使两个特征图满足亮度一致性,并帮助Lucas-Kanade算法通过塑造优化目标的景观来成功收敛。
多模态图像对齐:通过扩展传统的Lucas-Kanade方法到多模态图像对齐,提供了一种新的通用多模态图像对齐管道,显著提高了对齐精度。
论文3:
MM-Instruct: Generated Visual Instructions for Large Multimodal Model Alignment
MM-Instruct:为大型多模态模型对齐生成的视觉指令
方法
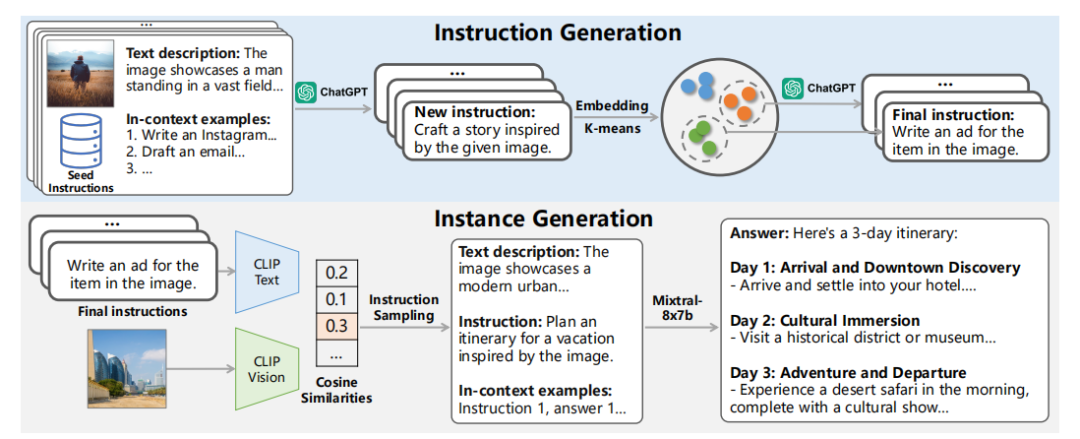
自动化指令生成:利用ChatGPT从少量种子指令自动生成多样化的指令。
指令-图像匹配:使用预训练的CLIP模型将生成的指令与相关图像匹配。
指令遵循答案生成:利用强大的LLM生成与指令-图像对一致的答案。
数据过滤:通过一系列启发式规则过滤低质量实例,确保数据集的高质量。
创新点
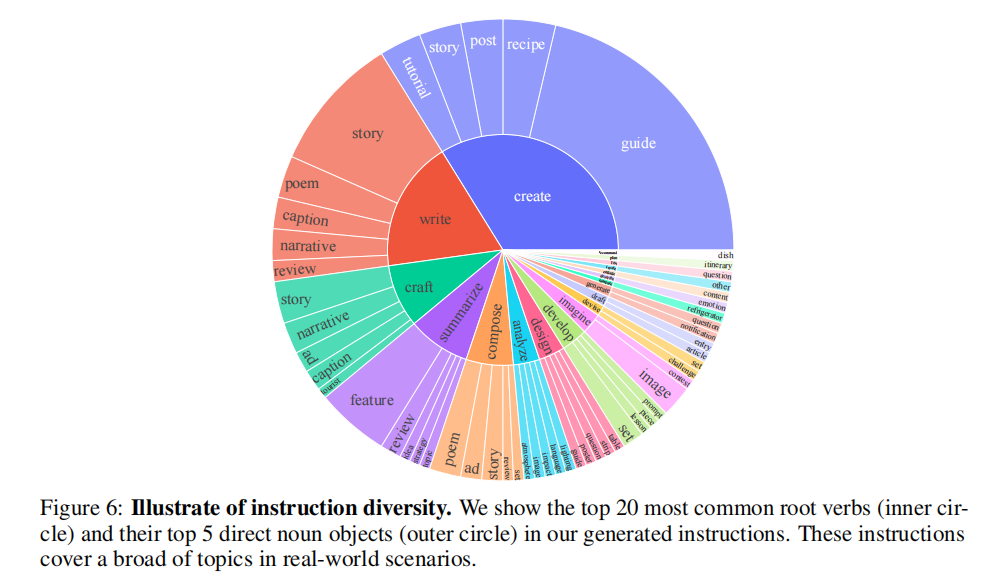
指令数据生成:提出了一种新颖的方法来构建MM-Instruct,利用现有LLMs的指令遵循能力,从传统的图像描述数据集中生成新的视觉指令数据。
基准测试:引入了基于生成的指令数据的基准测试,以评估现有LMMs的指令遵循能力。
性能提升:通过在生成的数据上训练LLaVA-1.5模型(称为LLaVA-Instruct),展示了MM-Instruct数据集的有效性,该模型在指令遵循能力上相较于LLaVA-1.5模型有显著提升,根据GPT-4V的偏好判断,LLaVA-Instruct-7B在72%的情况下产生同等或更优的响应。
论文4:
Ovis: Structural Embedding Alignment for Multimodal Large Language Model
Ovis:结构化嵌入对齐用于多模态大型语言模型
方法
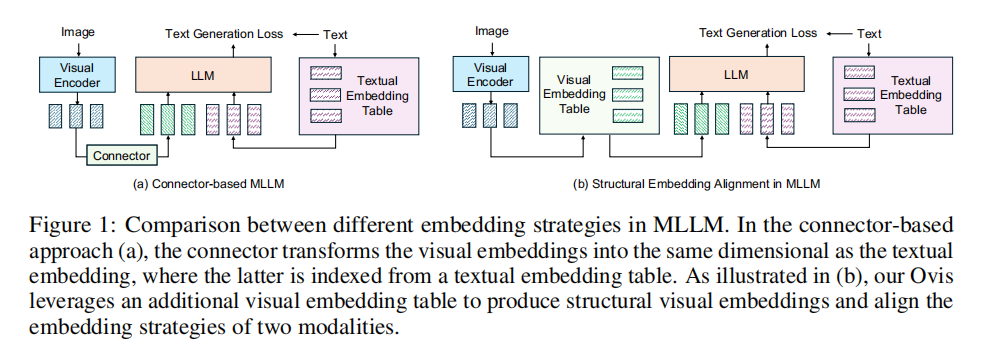
结构化视觉嵌入表:引入一个额外的可学习视觉嵌入表,将连续的视觉标记转换为结构化的视觉嵌入。
概率化视觉标记:每个图像补丁通过多次索引视觉嵌入表,生成最终的视觉嵌入,这是索引嵌入的统计组合。
三阶段训练策略:Ovis通过三阶段训练策略进行优化,避免了因缺乏文本指导而在视觉-语言任务中表现不佳的风险。
创新点
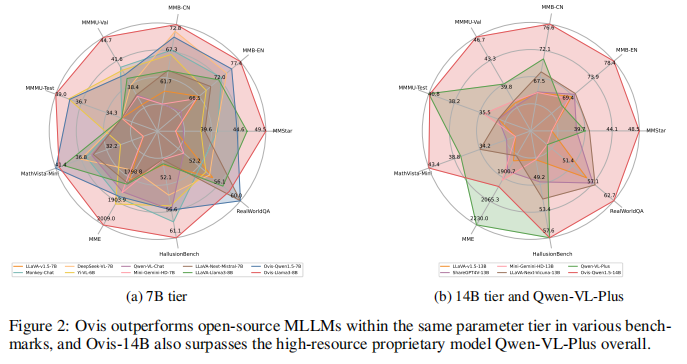
结构化视觉表示:Ovis通过结构化的视觉表示,在各种多模态基准测试中显示出比类似参数规模的开源MLLMs更好的性能,甚至在总体上超过了专有模型Qwen-VL-Plus。
概率化视觉标记:通过概率化视觉标记,Ovis能够捕获单个视觉补丁中的丰富语义,这可能包含多个视觉词汇的模式。
跨模态性能提升:在7B和14B参数规模的模型中,Ovis在多个基准测试中均优于开源MLLMs,特别是在MMStar和MMMU基准测试中,Ovis-8B和Ovis-14B的性能提升显著。

















 1550
1550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









