






本文的数据集GeoPlant是一个欧洲尺度的植物物种分布数据集,它包含多个类型的数据,涵盖环境变量、遥感影像、气候数据等。
GeoPlant数据集的主要任务是物种分布建模(Species Distribution Modeling,SDM),具体目标是预测特定位置的植物物种组成。简单来说就是,给定某个地理坐标,利用环境特征和遥感数据,模型需要预测该位置可能存在的植物物种。
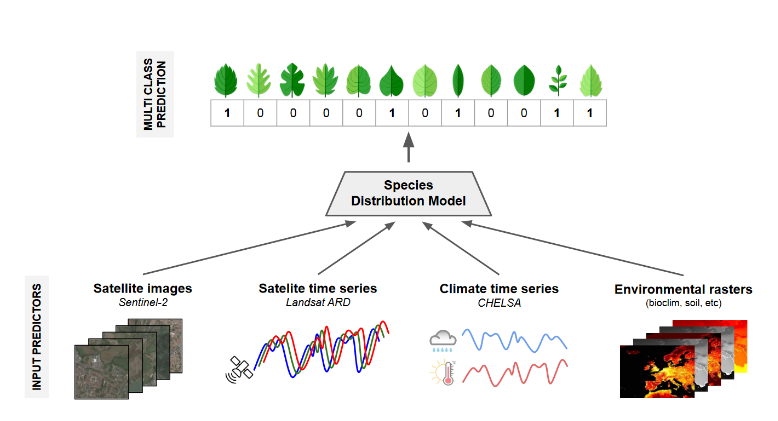
1.物种观察数据
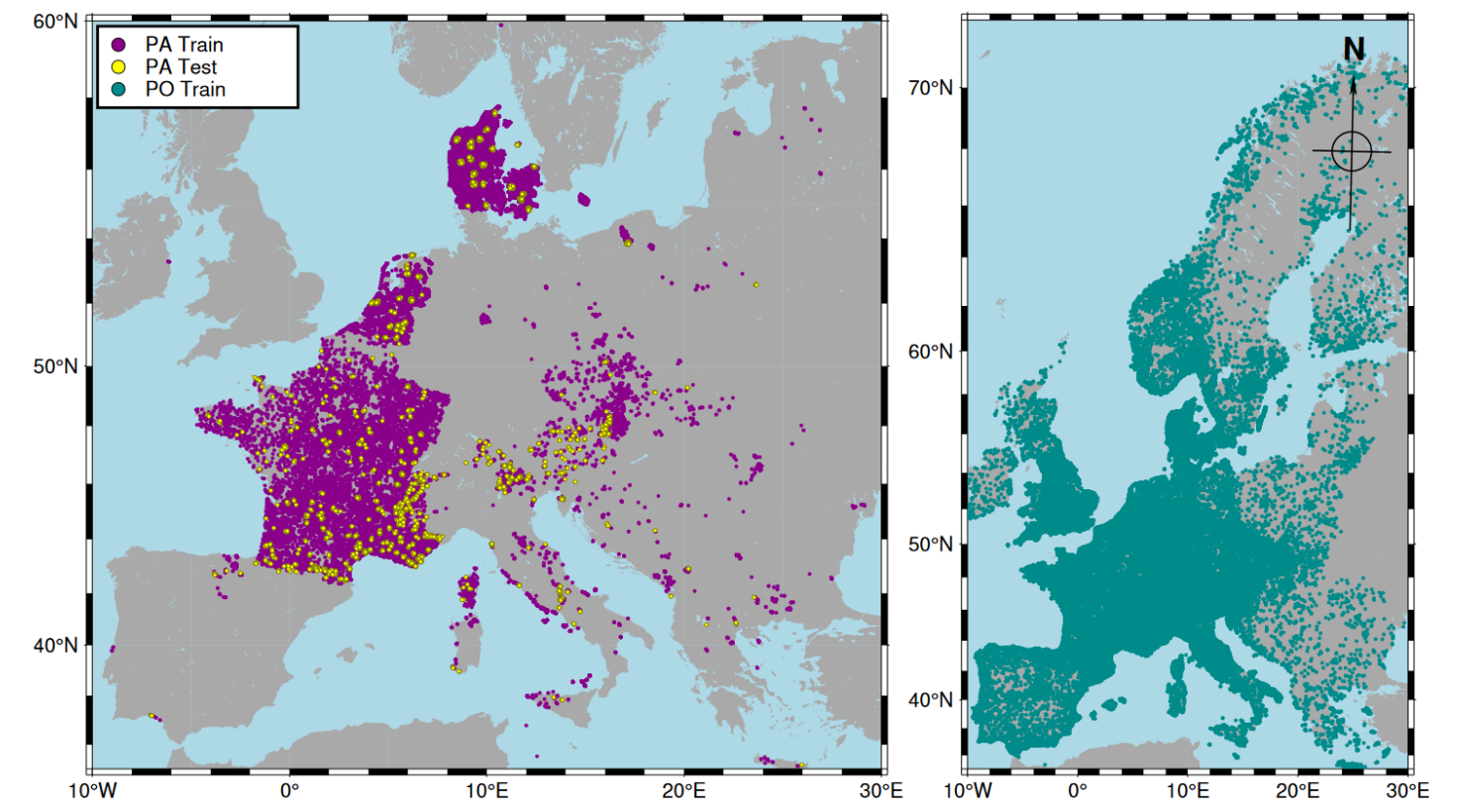
存在-缺失(Presence-Absence, PA)数据:约9万条记录,由专业植物学家在指定小区域内(通常10-400平方米)采集。这些数据通过标准化调查方法记录了某区域内的物种出现与否,代表一个完整的物种清单。
仅存在(Presence-Only, PO)数据:约500万条记录,来源于公民科学平台(如iNaturalist、Pl@ntNet),具有地理坐标,但未提供物种缺失信息。这些记录由于缺乏标准化采样协议而存在偏差,且主要集中在易访问和人口密集的区域。
2.环境栅格数据
土地利用和人类足迹:包括中分辨率土地覆盖数据和低分辨率人类活动影响数据。土地利用数据源自MODIS,提供欧洲范围的土地覆盖类型及其变化;人类足迹数据则包含不同年份(1993和2009)的人口密度、道路、耕地等指标,能够反映人类活动对物种分布的影响。
土壤属性:来自SoilGrids数据库,包含了pH值、土壤颗粒构成等9种土壤属性的低分辨率栅格,分辨率约1公里。
高程:采用ASTER全球数字高程模型(DEM)提供的高分辨率数据,涵盖整个数据集的空间范围,用于分析地形对物种分布的影响。
3.卫星图像数据
Sentinel-2图像:每个物种观测点周围128×128像素的10米分辨率RGB和NIR图像,用于捕捉该位置的植被和地表信息。图像经过预处理,去除了云和阴影干扰,并使用gamma校正以提高可视化效果。
Landsat时间序列:覆盖1999至2020年的每季多光谱数据(包括红、绿、蓝、近红外、短波红外1和2波段),用于追踪植被季节性变化和重大环境事件(如火灾)。

4.气候数据
月度气候时间序列:2000年至2019年间的气候变量(包括平均温度、最高温度、最低温度和降水量),分辨率约为1公里。
长期气候均值数据:基于1981至2010年的19项气候变量统计数据,如年均温度、降水季节性等,以捕捉长时间气候趋势对物种分布的影响。
5.数据格式和分布
所有数据均以标准化格式(GeoTIFF和CSV)提供,空间坐标系为WGS84,确保跨数据类型的兼容性。
数据覆盖整个欧洲的38个国家,数据集按10×10公里的网格划分,确保数据在空间上的平衡性,以避免因偏差引起的模型误差。
6.额外资源
GeoPlant还在Kaggle上提供了数据集的基准测试,并发布了用于深度SDM的预训练模型、基线模型等资源,方便研究者在不同数据模态和模型架构之间进行比较和验证。
7.GeoPlant 基准
GeoPlant数据集在Kaggle上提供了一个基准测试平台,方便研究人员进行物种分布建模(SDM)的评估。这个基准测试具备以下特点:
平台优势:在Kaggle上进行托管,提供了便捷的模型分享和代码开发环境,并且支持免费GPU资源,便于社区成员参与。
评价指标:主要使用样本平均的F1分数作为模型性能的衡量指标。该指标评估了预测的物种集合与实际存在的物种集合的重叠情况,确保测试集上的预测与真实数据一致。
资源支持:除了数据集,基准测试还提供了一系列资源,包括用于深度SDM训练的PyTorch框架(Malpolon)、数据加载器、基准测试的Jupyter Notebook,以及预训练模型。研究者可以直接在Kaggle上使用这些资源进行模型训练和评估。
Kaggle数据下载:https://www.kaggle.com/datasets/picekl/geoplant

















 669
669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









