






在快节奏的金融世界中,获取最新的准确的股票市场数据对于投资者、交易者和分析师至关重要。Google Finance是一个宝贵的资源,它提供实时股票报价、历史财务数据、新闻和汇率。学习如何使用Python抓取这些数据对于那些希望汇总数据、进行情绪分析、进行市场预测或有效管理风险的人来说,将大有裨益。
为什么抓取Google Finance?
抓取Google Finance有很多好处,包括:
- 实时股票数据 – 获取最新的股票价格、市场趋势和历史表现。
- 自动化市场分析 – 大规模收集财务数据,用于趋势分析、投资组合管理或算法交易。
- 公司洞察 – 收集财务摘要、收益报告和股票表现,用于投资研究。
- 竞争对手和行业研究 – 监控竞争对手的财务状况和行业趋势,以做出数据驱动的决策。
- 新闻和情绪分析 – 提取与特定股票或行业相关的新闻文章和更新,用于情绪追踪。
将要抓取的内容
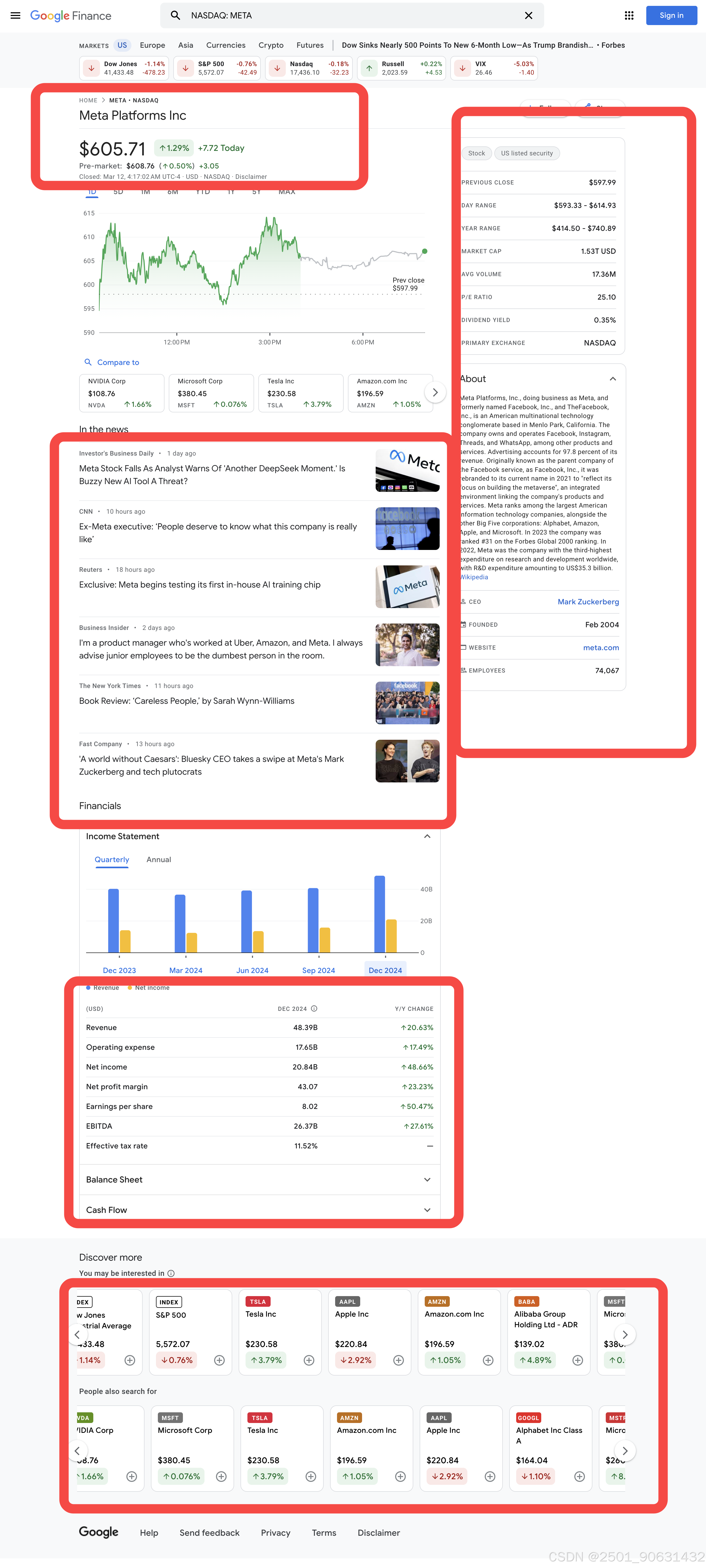
如何使用Python抓取Google Finance股票代码报价数据
步骤1. 配置环境
-
Python: 软件 是运行Python的核心。您可以从下面的官方网站下载我们需要的版本。但是,不建议下载最新版本。您可以下载比最新版本早1.2个版本的软件。
-
Python IDE: 任何支持Python的IDE都可以,但我们推荐PyCharm。它是一个专门为Python设计的开发工具。对于PyCharm版本,我们推荐免费的PyCharm社区版
注意:如果您是Windows用户,请不要忘记在安装向导过程中选中“将python.exe添加到PATH”选项。这将允许Windows在终端中使用Python和命令。由于Python 3.4或更高版本默认包含它,因此您无需手动安装它。
现在,您可以通过打开终端或命令提示符并输入以下命令来检查是否已安装Python:
Copy
python --version步骤2. 安装依赖项
建议创建一个虚拟环境来管理项目依赖项,并避免与其他Python项目冲突。在终端中导航到项目目录,并执行以下命令来创建一个名为google_lens的虚拟环境:
Copy
python -m venv google_finance根据您的系统激活虚拟环境:
- Windows:
languageCopy
google_finance_env\Scripts\activate- MacOS/Linux:
languageCopy
source google_finance_env/bin/activate激活虚拟环境后,安装Web抓取所需的Python库。Python中用于发送请求的库是requests,用于抓取数据的主要库是BeautifulSoup4。使用以下命令安装它们:
languageCopy
pip install requests
pip install beautifulsoup4
pip install playwright步骤3. 抓取数据
要从Google Finance提取股票信息,我们首先需要了解如何使用网站的URL来抓取所需的股票。让我们以纳斯达克指数为例,其中包含我们可以从中获取信息的多种股票。要访问每只股票的代码,我们可以使用此链接中的纳斯达克股票筛选器。现在让我们将META作为我们的目标股票。有了指数和股票,我们可以构建脚本的第一段代码。
我们坚决保护网站的隐私。本博客中的所有数据都是公开的,仅用于演示抓取过程。我们不保存任何信息和数据。
languageCopy
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"现在我们可以使用Requests库对TARGET_URL发出HTTP请求,并创建一个Beautiful Soup实例来抓取HTML内容。
languageCopy
发出HTTP请求
page = requests.get(TARGET_URL)# 使用HTML解析器从“page”中获取内容
soup = BeautifulSoup(page.content, "html.parser")在开始抓取之前,我们首先需要通过检查网页来处理HTML元素(TARGET_URL)。
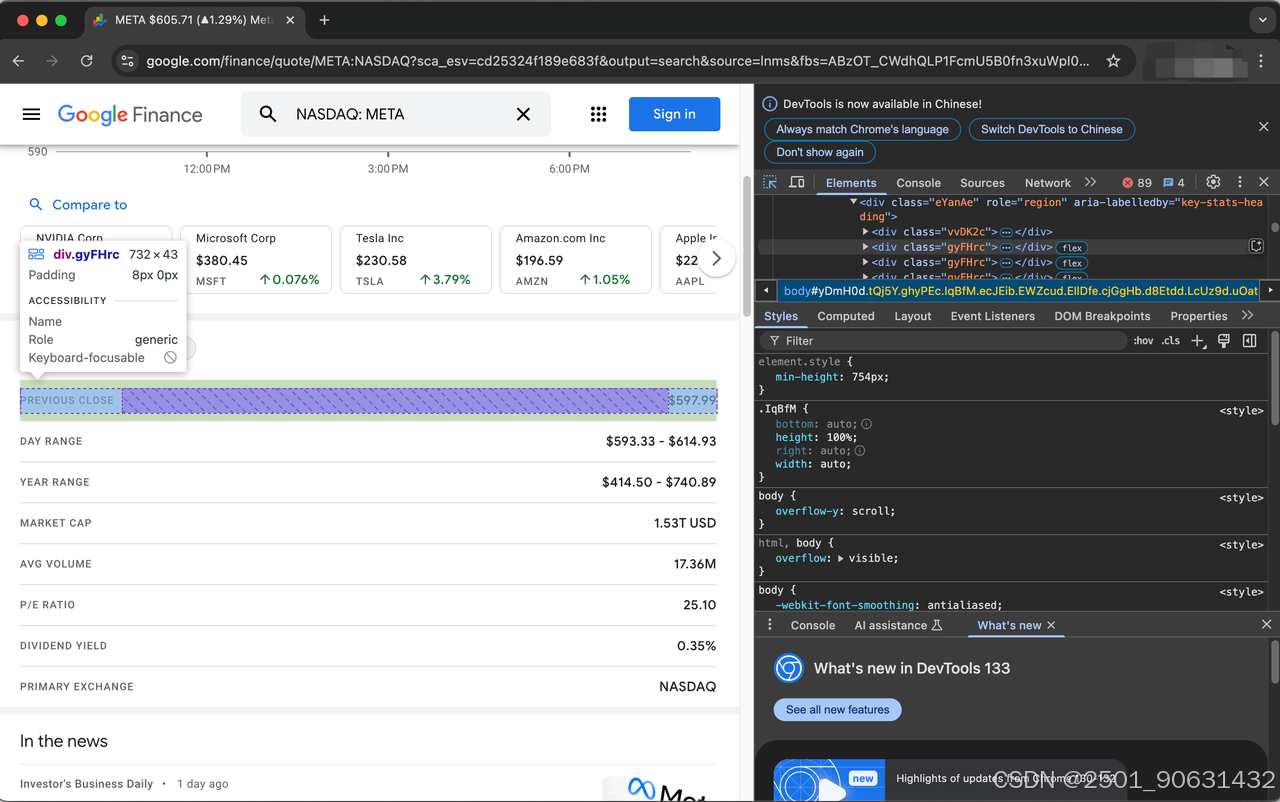
描述股票的项目由类gyFHrc表示。在每个这样的元素内部,都有一个表示项目标题(例如,“收盘价”)和相应值(例如,597.99美元)的类。标题可以从mfs7Fc类中获取,而值来自P6K39c类。
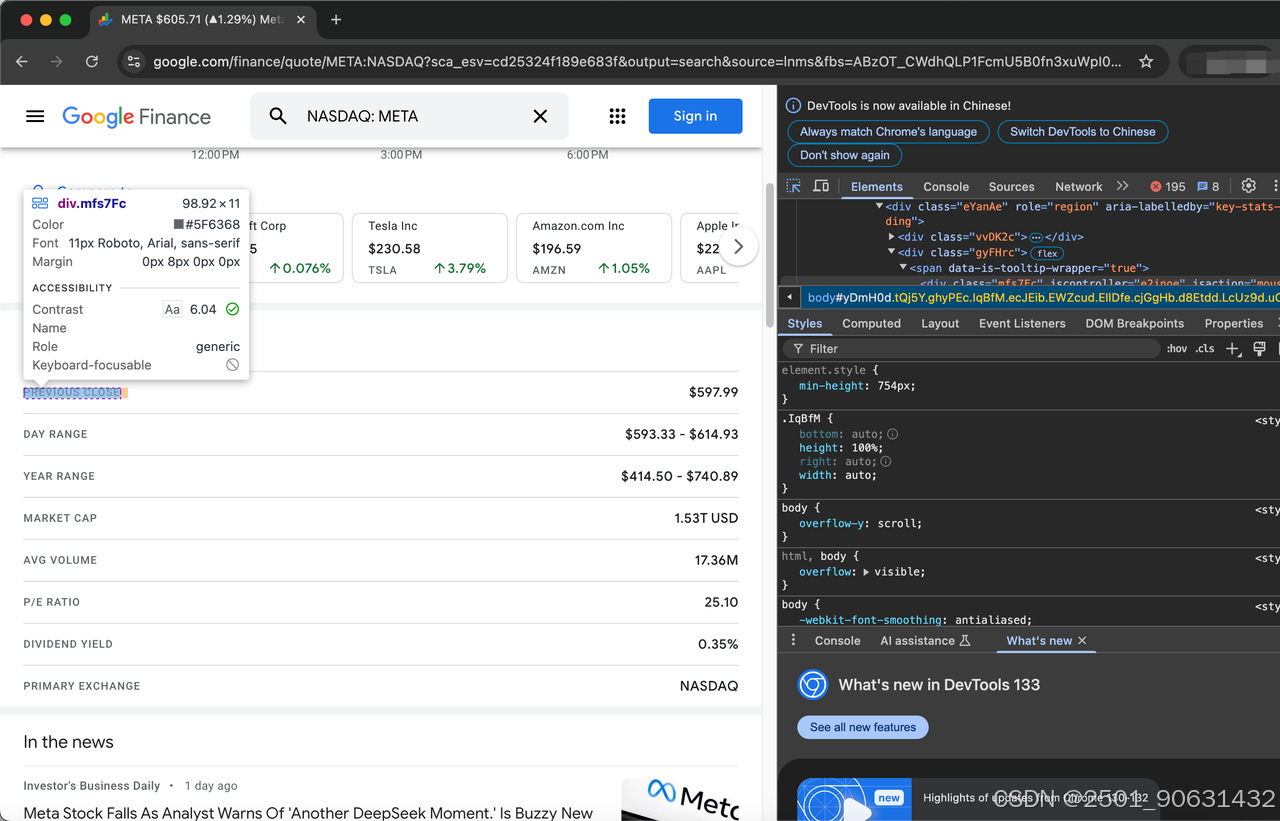
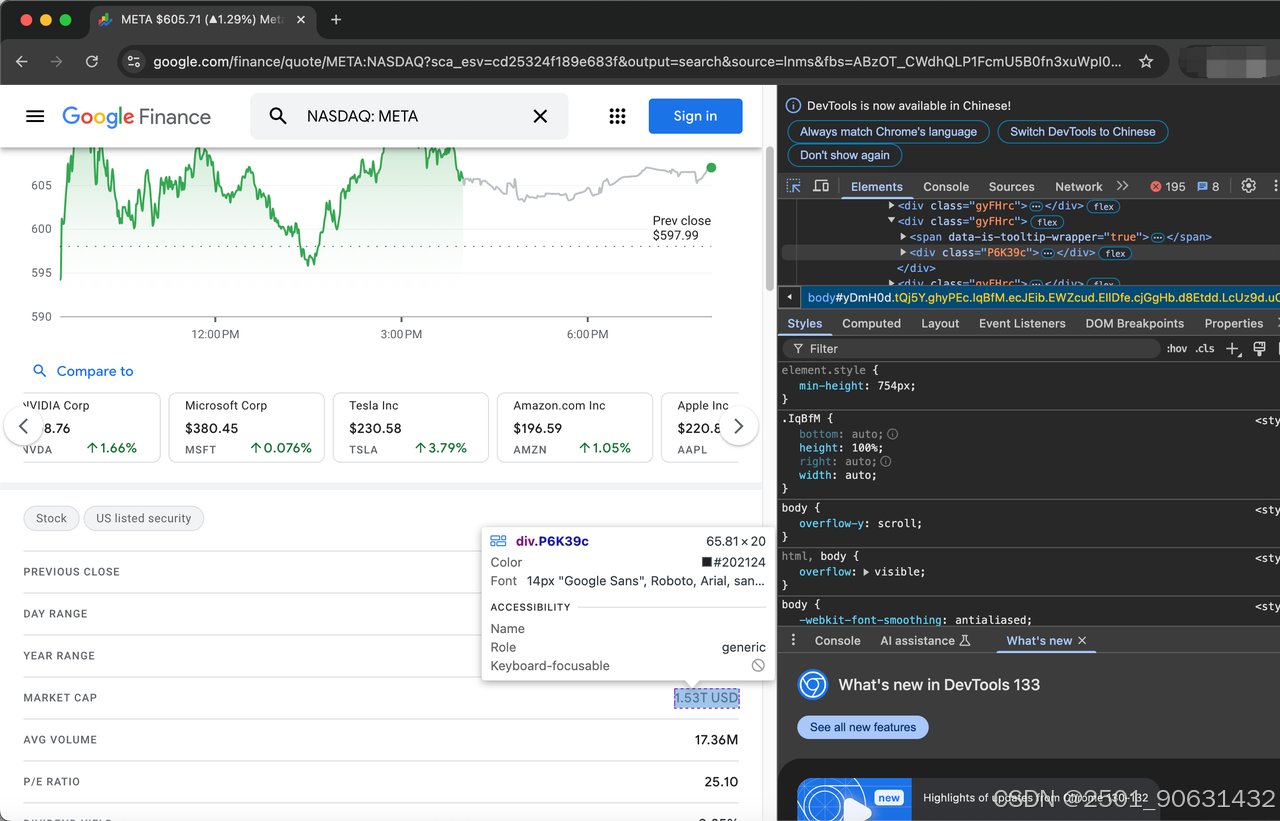
将要抓取项目的完整列表如下:
- 前收盘价
- 日波动范围
- 年波动范围
- 市值
- 平均成交量
- 市盈率
- 股息率
- 主要交易所
- CEO
- 成立时间
- 网站
- 员工人数
现在让我们看看如何使用Python代码获取这些项目。
Copy
# 获取描述股票的项目
items = soup.find_all("div", {"class": "gyFHrc"})
# 创建一个字典来存储股票描述
stock_description = {}
# 迭代项目并将它们添加到字典中
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value
print(stock_description)这只是一个简单的脚本示例,可以集成到交易机器人、应用程序或简单的仪表板中,以跟踪您最喜欢的股票。
完整代码
您可以从页面中获取更多数据属性,但目前,完整代码看起来像这样。
languageCopy
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"# 发出HTTP请求
page = requests.get(TARGET_URL)# 使用HTML解析器从“page”中获取内容
soup = BeautifulSoup(page.content, "html.parser")# 获取描述股票的项目
items = soup.find_all("div", {"class": "gyFHrc"})# 创建一个字典来存储股票描述
stock_description = {}# 迭代项目并将它们添加到字典中
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value以下是结果的一些示例:

抓取Google Finance时的限制
使用上述方法,您可以创建一个小型抓取器,但是如果您要进行大规模抓取,则此抓取器将无法继续为您提供数据。Google 对数据抓取非常敏感,最终会阻止您的IP。
一旦您的IP被阻止,您将无法抓取任何内容,您的数据管道最终会中断。那么,如何克服这个问题呢?有一个非常简单的解决方案,那就是使用Google Finance抓取API。
让我们看看如何使用此API从Google Finance抓取无限数据。
为什么使用Scrapeless Google Finance抓取API
数据质量和准确性
- 高精度数据:Scrapeless SerpApi始终提供准确、可靠和最新的Google Finance数据,确保用户可以获得最真实和最有用的市场信息。
- **实时更新:**能够实时获取Google Finance的最新数据,包括实时股票报价、市场趋势等,对于需要及时做出投资决策的用户至关重要。
多语言和位置支持
- **多语言支持:**支持多种语言,用户可以根据需要获取不同语言的财务数据,满足全球不同地区用户的需求。
- **位置自定义:**您可以根据指定的地理位置、设备类型和其他参数获取自定义搜索结果,这对于分析不同地区的市场状况或进行本地化市场研究非常有用。
性能和成本优势
- **超快速度:**Scrapeless SerpApi的平均响应时间仅为1-2秒,是市场上速度最快的搜索抓取API之一,可以快速为用户提供所需的数据。
- **经济高效:**Scrapeless SerpApi的Google搜索API价格仅为每千次查询0.1美元。这种定价模式对于大规模数据抓取项目来说非常经济高效。
集成 - **易于集成:**Scrapeless SerpApi支持与各种流行的编程语言(例如Python、Node.js、Golang等)集成,用户可以轻松地将其嵌入到自己的应用程序或分析工具中。
稳定性和可靠性 - **高可用性:**Scrapeless SerpApi具有高服务可用性和稳定性,可以在长期和高频数据抓取期间确保为用户提供不间断的服务。
- **专业支持:**Scrapeless SerpApi提供专业的技术支持和客户服务,帮助用户解决使用过程中遇到的问题,确保用户能够顺利获取和使用数据。
如何使用Scrapeless抓取Google Finance数据
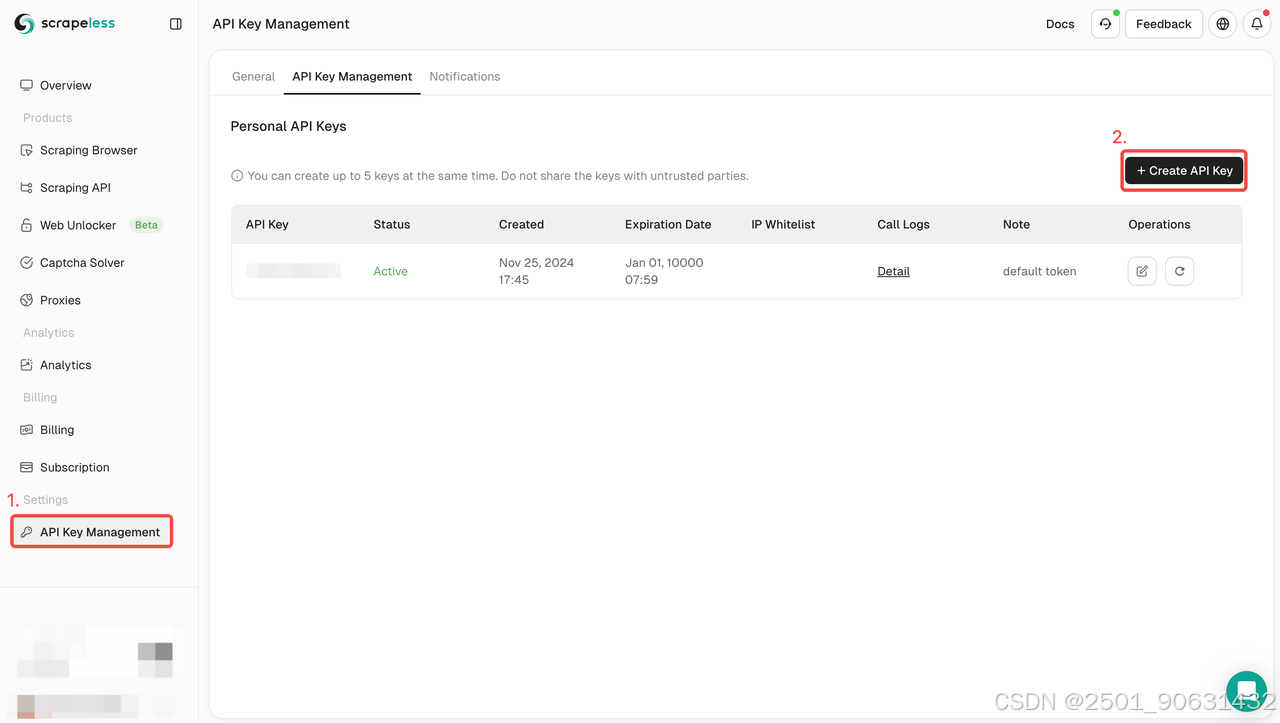
步骤1:注册Scrapeless并获取API密钥
- 如果你还没有Scrapeless帐户,请访问Scrapeless网站并注册。您可以获得20,000次免费搜索查询。
- 注册后登录,登录您的仪表板。
- 在仪表板中,导航到API密钥管理并单击创建API密钥。复制生成的API密钥,这将是您调用Scrapeless API时的身份验证凭据。
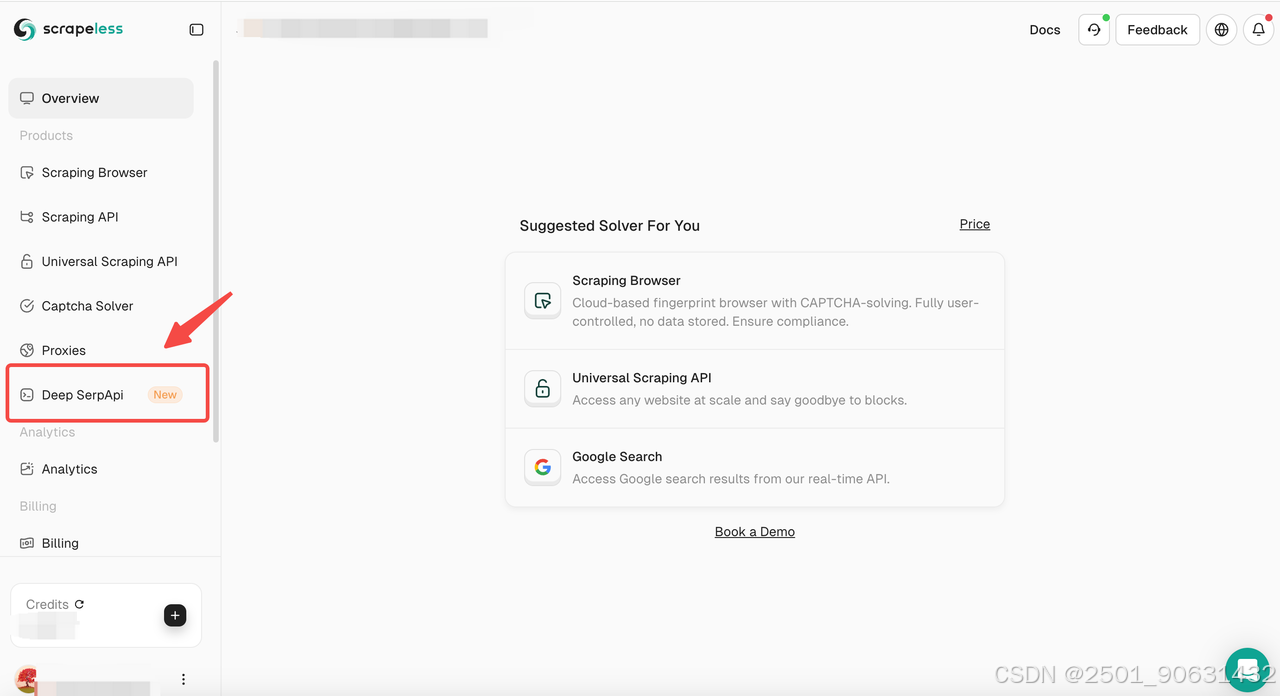
步骤2:访问Deep SerpApi Playground
- 然后导航到“Deep SerpApi”部分。
步骤3:设置搜索参数
- 在Playground中,输入您的搜索关键字,例如“GOOGL:NASDAQ”。
- 设置其他参数,例如查询词、语言、时间等。
您也可以点击查看Scrapeless的官方API文档,了解Google Finance的参数。
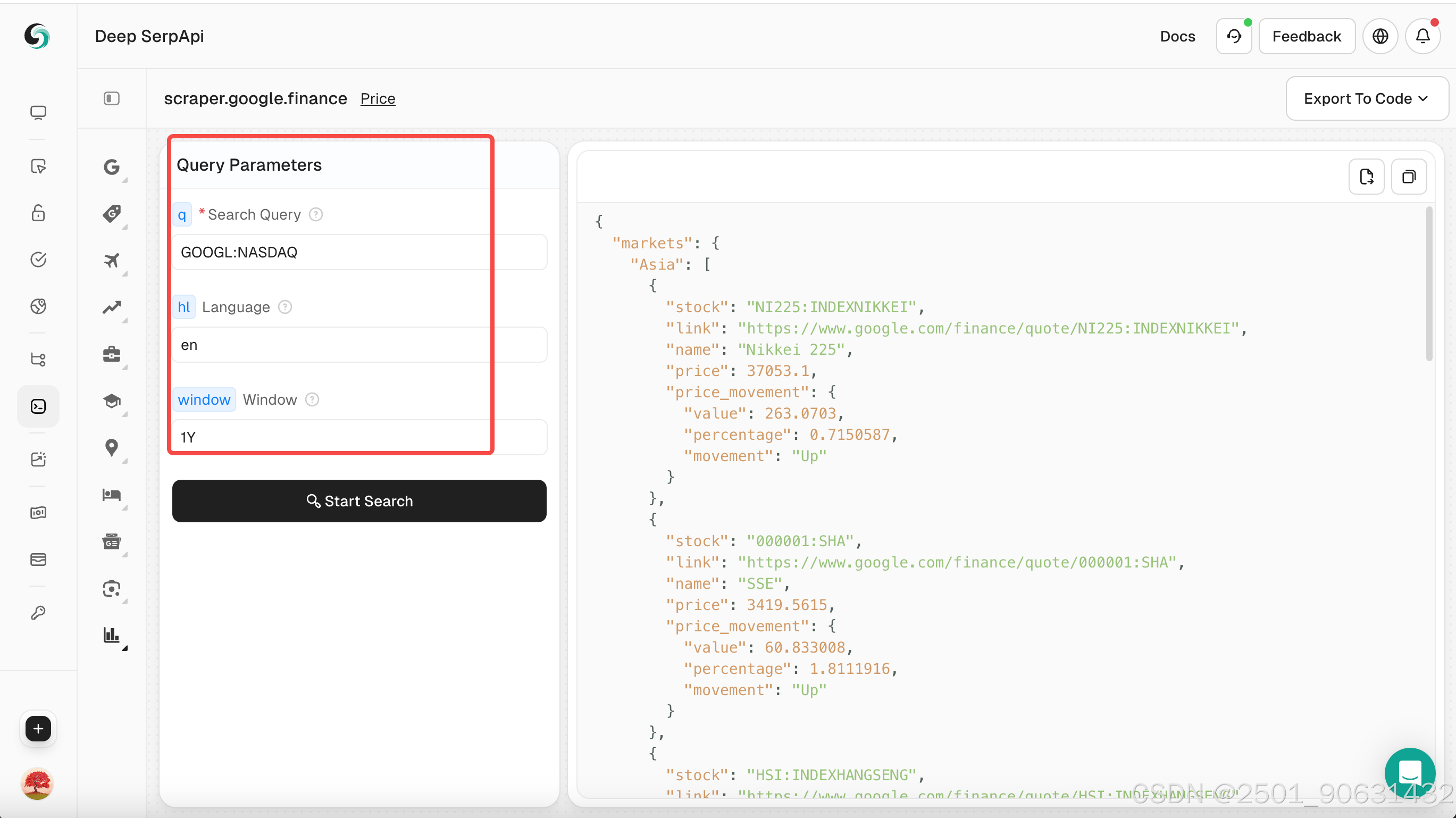
步骤4:执行搜索
- 点击“开始搜索”按钮,Playground将向Deep Serp API发送请求并返回结构化的JSON数据。
步骤5:查看和导出数据
- 浏览返回的JSON数据以查看详细信息。
- 必要时,您可以点击右上角的“复制”按钮,将数据导出为CSV或JSON格式,以便进一步分析。
免费开发者支持:
将Scrapeless Deep SerpApi集成到您的AI工具、应用程序或项目中(我们已经支持Dify,并将支持Langchain、Langflow、FlowiseAI和其他框架)。
在社交媒体上分享您的集成结果,您将获得1到12个月的免费开发者支持,每月最高使用量为500K。
抓住这个机会改进您的项目并享受更多开发支持!您也可以通过Discord联系Liam了解更多详情。
如何集成Scrapeless API
以下是使用Scrapeless API抓取Google Finance结果的示例代码:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "您的API密钥"
headers = {
"x-api-token": token
}
input_data = {
"q": "GOOG:NASDAQ",
"window": "MAX",
.....
}
payload = Payload("scraper.google.finance", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("错误:", response.status_code, response.text)
return
print("正文", response.text)
if __name__ == "__main__":
send_request()根据需要调整查询参数以获得更精确的结果。有关API参数的更多信息,您可以查看Scrapeless官方API文档
您必须将YOUR-API-KEY替换为您复制的API密钥。
其他资源
如何使用Python抓取Google新闻
如何使用Puppeteer绕过Cloudflare
如何使用Scrapeless抓取Google Lens结果
结论
总而言之,使用Python抓取Google Finance股票代码报价数据是一种强大的技术,可以访问实时的财务信息。通过使用requests和BeautifulSoup之类的库,或Selenium等更高级的工具,您可以有效地提取和分析市场数据,从而为您的投资决策提供信息。请记住遵守网站的服务条款,并在可用时考虑使用官方API来实现可持续的数据访问。
在无疑,我们仅访问公开可用的数据,同时严格遵守适用的法律,法规和网站隐私政策。 此博客中的内容仅用于演示目的,不涉及任何非法或侵权活动。 我们对此博客或第三方链接中信息的使用不承担任何保证,也不承担所有责任。 在进行任何刮擦活动之前,请咨询您的法律顾问并查看目标网站的服务条款或获得必要的许可。

















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









