






在人工智能领域,注意力机制模拟人类“选择性关注”的认知能力,使模型能够聚焦关键信息,从而提升任务表现,在计算机视觉、自然语言处理等方向展现出巨大潜力。
传统CNN与RNN在建模长距离依赖方面存在局限,而注意力机制通过“动态权重分配”有效增强特征表达能力,成为Transformer及其变体的核心思想。
当前研究正致力于解决其计算效率、局部与全局信息平衡、多模态融合等挑战,推动注意力机制向更轻量、更具泛化能力的方向发展。理解其内在逻辑,有助于把握深度学习的发展脉络,并加速实际应用落地。
我精选了76篇附带开源代码的最新论文,均来自权威平台,涵盖全局注意力、局部注意力、线性注意力、交叉注意力、多尺度注意力等方向,便于读者复现与验证,助力研究高效推进。
关注VX公众号【学长论文指导 】发送暗号 9 领取
【论文1:全局注意力+局部注意力】TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition
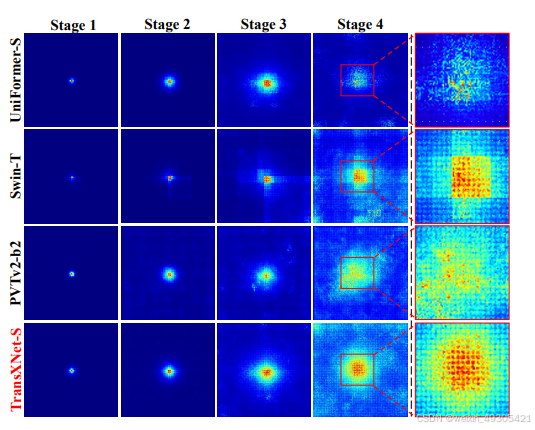
Visualization of effective receptive fields (ERF)
研究方法
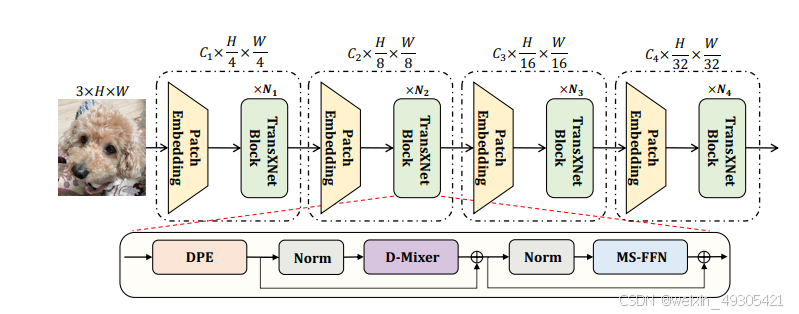
The overall architecture of the proposed TransXNet
论文提出了一种名为 Dual Dynamic Token Mixer(D-Mixer)的轻量级模块,并基于此设计了 TransXNet 网络用于视觉识别。D-Mixer 通过将输入特征沿通道维度均分为两部分,分别用重叠空间缩减注意力模块(OSRA)和输入相关的深度卷积(IDConv)进行处理,再将输出拼接,同时引入多尺度前馈网络(MS-FFN)探索多尺度信息,堆叠由 D-Mixer 和 MS-FFN 构成的基本块构建了 TransXNet 网络。
创新点
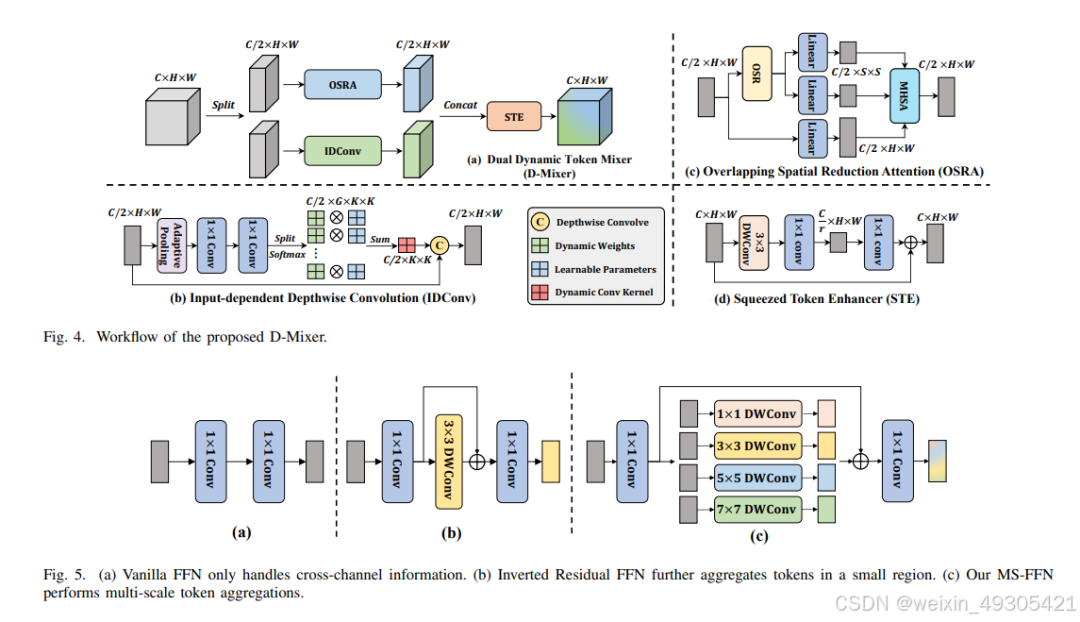
workflow
-
创新点:
-
动态捕捉全局和局部信息:D-Mixer能以输入相关的方式聚合稀疏全局信息和局部细节,赋予模型大的有效感受野和强归纳偏差。
-
强大的视觉骨干网络:设计的TransXNet网络以D-Mixer为基本构建块,在多种视觉任务上超越了先前方法,且计算成本更低。
-
泛化能力强:在不同的密集预测任务,如目标检测、语义分割和实例分割等任务中,TransXNet展现出了强大的泛化能力和优异的性能。
-
论文链接:https://arxiv.org/pdf/2310.19380v3
代码链接:https://github.com/LMMMEng/TransXNet
【论文2:小波+注意力】A Wavelet Guided Attention Module for Skin Cancer Classification with Gradient-based Feature Fusion
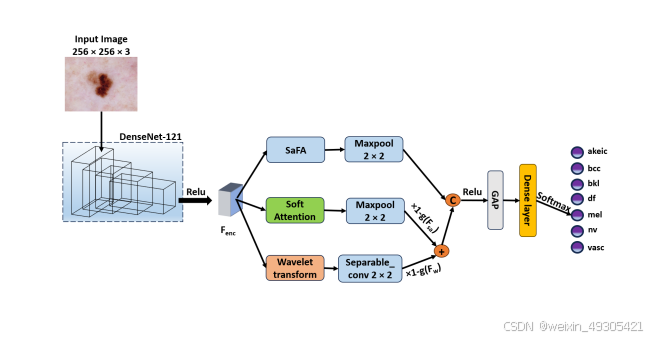
The proposed classification model utilizes the DenseNet-121 as the backbone for feature extraction.
研究方法
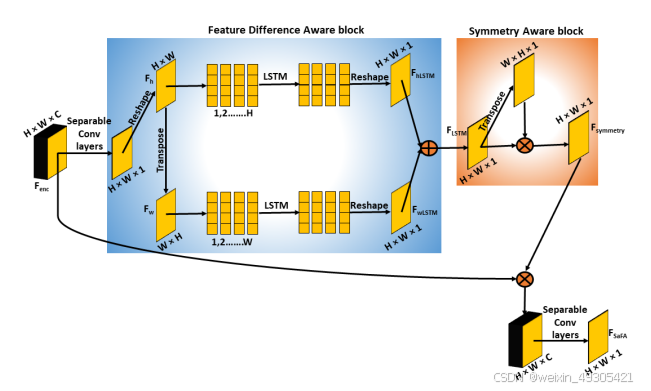
在这里插入图片描述
论文提出了利用 DenseNet121 作为特征提取骨干网络,引入对称感知特征注意力(SaFA)模块来提取病变对称性及空间维度特征变化信息。同时,通过基于梯度的特征融合机制,将小波特征和注意力辅助特征进行融合,强化病变边界信息,进而构建皮肤癌分类模型。
创新点
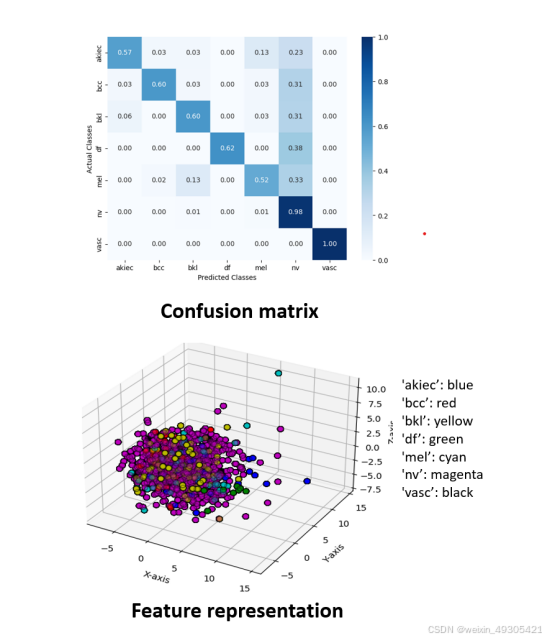
Confusion matrix and feature representation of the proposed model.
-
独特注意力机制:提出的SaFA模块能精准定位病变在空间维度和对称性上的特征差异,基于病变对称性、纹理和颜色均匀性等聚焦不同类别间的差异 。
-
梯度融合策略:采用基于梯度的小波和软注意力辅助特征融合方法,根据特征的归一化反向传播梯度动态分配权重,在不增加参数的情况下优化特征融合,增强病变边界信息提取。
-
模型性能优势:在高度类别不平衡的HAM10000数据集上进行测试,模型取得了91.17%的F1分数和90.75%的准确率,超越了现有方法。
论文链接:https://arxiv.org/pdf/2406.15128
【论文3:注意力 + UNet 】AMSA-UNet: An Asymmetric Multiple Scales U-net Based on Self-attention for Deblurring

Comparison of visualization on the GoPro.
研究方法
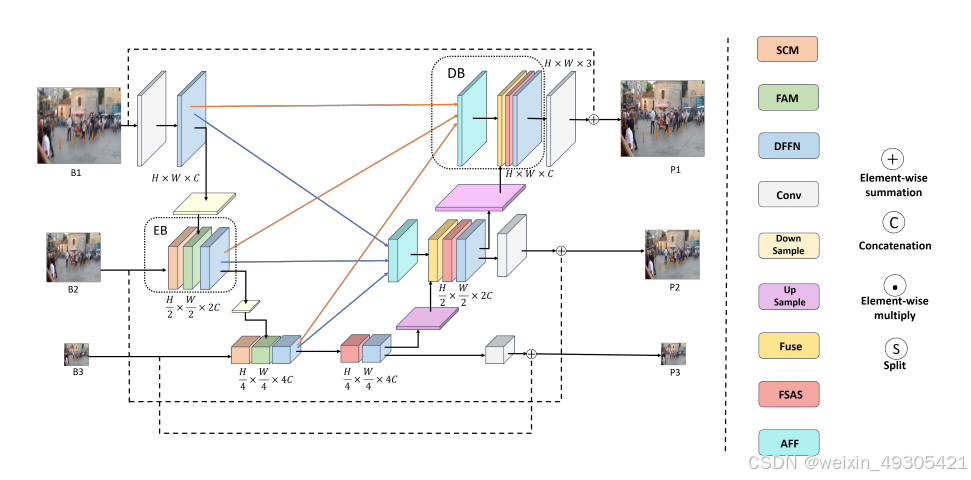
Overall Network Architecture
该论文提出用AMSA-UNet 模型将多输入多输出网络架构与 Transformer 模块相结合,用于图像去模糊任务。编码器采用多尺度输入策略和基于频域的前馈神经网络,减少特征信息丢失,判别有效频率信息;解码器通过融合不同尺度结果和引入基于频域的自注意力求解器,提升模型对长距离依赖关系的捕捉能力,实现更精准的去模糊效果。同时,利用傅里叶变换降低计算复杂度。
创新点
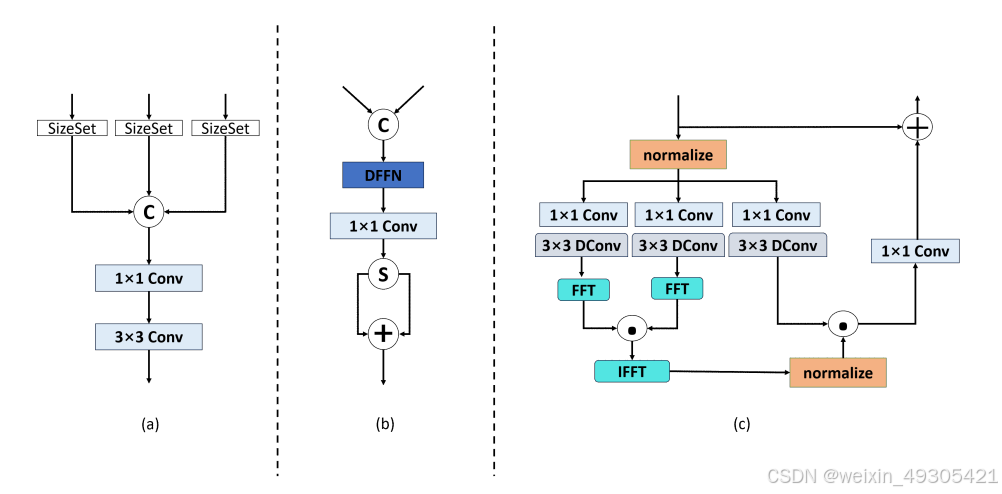
The Structure of Decoder Block. (a) AFF, (b) Fuse, (c) FSAS.
-
多尺度架构设计:引入多尺度U型结构,使网络能在全局关注模糊区域,在局部更好地恢复图像细节,有效解决单尺度U-Net处理图像时空间信息丢失的问题,提升去模糊精度。
-
自注意力机制应用:在解码器部分引入自注意力机制,扩大模型感受野,让模型更关注图像语义信息,相比传统卷积方法,能更有效地捕捉长距离依赖关系,生成更准确、视觉效果更好的去模糊图像。
-
频域计算优化:基于傅里叶变换的特性,将其应用于模型计算,降低计算复杂度,在保证模型精度的同时,提高了处理速度,使得模型在运行时间和准确性之间达到更好的平衡。
-
非对称结构优势:采用非对称U型网络架构,编码器仅使用DFFN模块,解码器使用DFFN和FSAS模块,这种结构使解码器更适合捕捉长距离依赖,避免编码器模块混淆清晰与模糊特征,提升去模糊效果 。
论文链接:https://arxiv.org/abs/2406.09015
【论文4:多尺度注意力】Multi-scale attention network (MSAN) for track circuits fault diagnosis
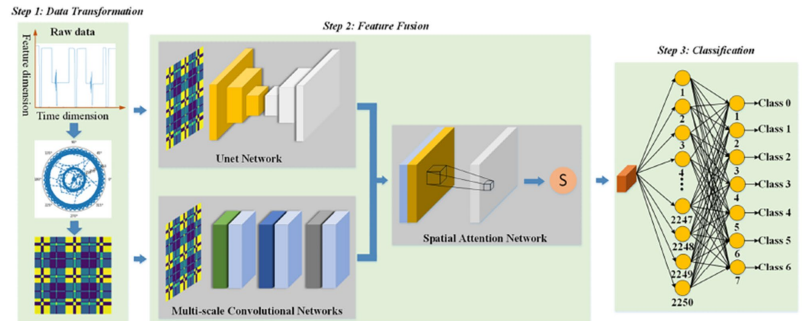
Overall framework diagram of MSAN.
论文简述
轨道电路作为铁路信号系统三大室外部件之一,在保障列车运行安全和效率方面发挥着重要作用。因此,当故障发生时,需要快速准确地找出故障原因并及时处理,以避免影响列车运行效率和发生安全事故。论文提出了一种基于多尺度注意力网络的故障诊断方法,该方法利用格拉姆角场(Gramian Angular Field, GAF)将一维时间序列转换为二维图像,充分发挥卷积网络在处理图像数据方面的优势。设计了一种新的特征融合训练结构,以有效训练模型,充分提取不同尺度的特征,并通过空间注意力机制融合空间特征信息。最后,使用实际轨道电路故障数据集进行实验,故障诊断准确率达到99.36%,与经典和最先进的模型相比,本文模型表现出更好的性能。消融实验验证了所设计模型中的每个模块都起着关键作用。
论文链接:https://www.nature.com/articles/s41598-024-59711-2
【论文5:线性注意力机制】Agent Attention: On the Integration of Softmax and Linear Attention

Samples generated by Dreambooth and our Agent Dreambooth with the same seed.
研究方法
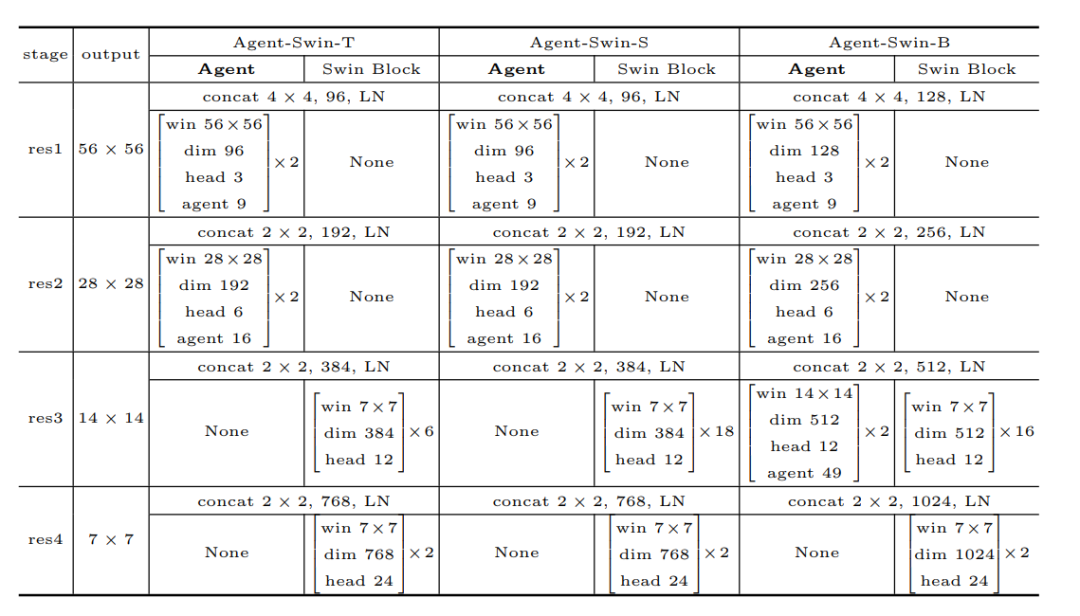
Architectures of Agent-Swin models.
论文提出 Agent Attention(AA)机制,引入一组代理令牌作为查询的 “代理”,通过将其与输入特征计算注意力权重,来整合信息 。其计算过程融入精心设计的代理偏差,并可结合如深度可分离卷积权重(DWC)等轻量级线性注意力增强技术,实现高效特征处理。同时,该机制可应用于多种模型,如在 Stable Diffusion 模型中,通过调整公式和 Softmax 注意力的尺度,在不额外训练的情况下加速生成、减少内存使用并提升图像生成质量。
创新点
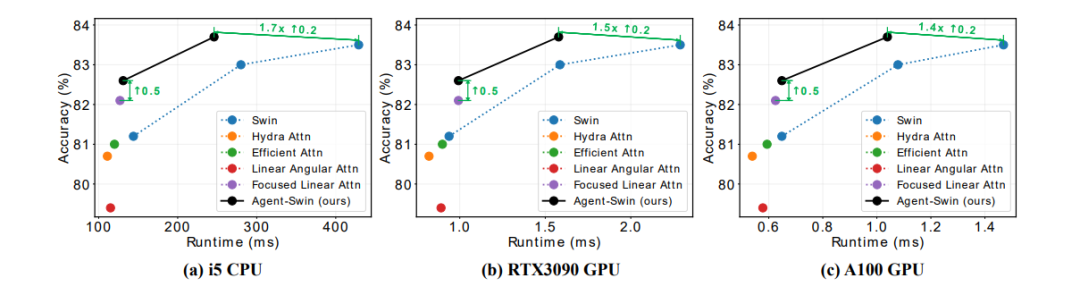
Runtime comparison with other linear attention methods.
-
设计新颖且实用:与相关工作不同,Agent Attention的代理令牌直接从查询空间获取,可在无额外训练的情况下应用于现有模型,而其他方法需训练投影或MLP,应用受限。
-
独特的广义线性注意力视角:从广义线性注意力角度出发,能借助轻量级线性注意力增强(如DWC)发挥Agent Attention的潜力,而相关工作需依赖其他复杂技术来达到类似效果。
-
通用性强:Agent Attention可作为通用模块替代Softmax注意力,而GPViT和GRL不是即插即用模块,仅适用于特定任务。
-
提升模型性能:在多个任务(图像分类、目标检测、语义分割等)和模型(如DeiT、PVT、Swin等)中,用Agent Attention替代Softmax注意力后,模型性能得到一致提升,且运行速度与其他线性注意力方法相当。
论文链接:https://link.springer.com/chapter/10.1007/978-3-031-72973-7_8
【论文6:交叉注意力机制】FCAnet: A novel feature fusion approach to EEG emotion recognition based on cross-attention networks
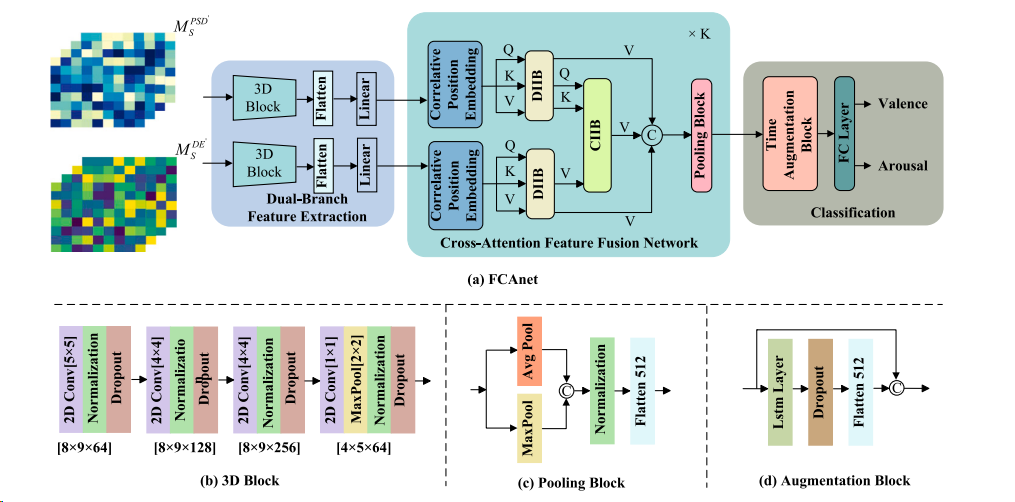
(a) The overall structure of FCAnet. (b) The simplified structure of 3D Block in dual feature extraction module. (c) The details of the pooling block. (d) The details of the Augmentation block in the classification unit.
研究方法
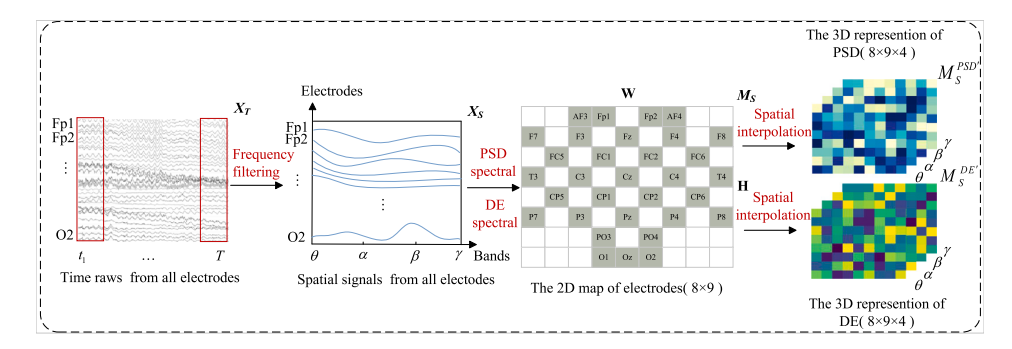
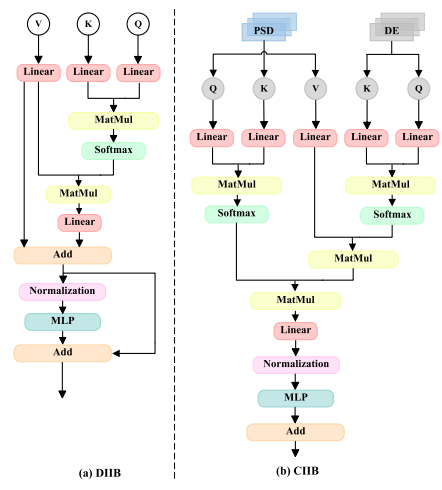
论文提出了一种基于交叉注意力机制结合特征融合的 EEG 情感识别新方法 FCAnet。该方法先通过双分支特征提取模块(DBFE)获取 EEG 的 3D 差分熵(DE)和 3D 功率谱密度(PSD)特征图,接着利用交叉注意力特征融合网络(CAFFN)融合差异和共同特征,最后借助时间增强模块(TAB)恢复高层表示中丢失的信息。
创新点
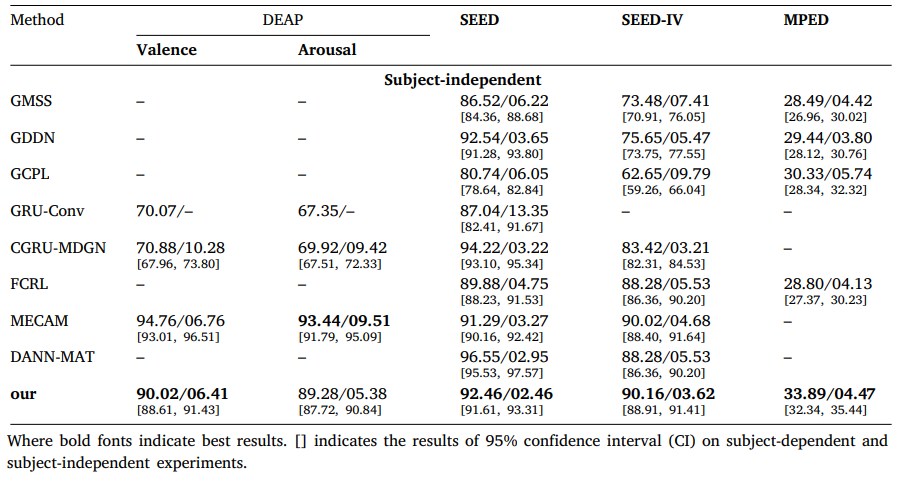
Comparison of EEG emotion recognition ACC/STD (%) in subject-independent on datasets DEAP, SEED, SEED-IV, and MPED
-
提出新型EEG情感识别模型:FCAnet将差异和共同特征与注意力模块集成到深度学习网络中,相比常用的自注意力网络,在EEG情感分类上更准确高效。
-
设计可学习位置编码:基于电极连接的可学习位置编码(PE),能从局部 - 全局表示中进一步学习空间信息,有助于推断电极的图拓扑结构。
-
开发双分支特征提取模块:DBFE模块可获取PSD和DE特征的时间、空间和频谱特性,避免了单编码路径方法的浅层特征混淆和情感信息提取不足的问题。
-
设计时间增强模块:通过在LSTM层使用独特的门控机制引入时间连接,调整时间参数时能有效克服梯度消失问题,保留EEG的长期信息。
论文链接:https://www.sciencedirect.com/science/article/pii/S092523122500774X

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









