







在深度学习领域,模型训练是一个关键环节,而训练时间和成本往往是研究人员和开发者最为关注的问题。今天,我们就来深入探讨一下,在预算有限的情况下,使用不同 GPU 配置训练一个 1000 亿参数模型需要花费多长时间。
训练时间的关键影响因素
- 模型训练所需的计算量:模型训练时间与计算量紧密相关,计算量通常由浮点运算(FLOPS)来衡量。对于一个 1000 亿参数的模型,我们粗略估算其训练所需的 FLOP 数为 1000 亿参数 ×1000 次更新 = 10²² FLOP。不过要注意,这只是一个非常粗略的估算,实际值会因模型结构和训练算法的不同而有所差异。
- 硬件配置的 FP16 算力:不同的 GPU 配置,其计算能力大不相同,特别是 FP16 算力,在深度学习模型训练中起着至关重要的作用。
- 预算与资源限制:我们设定每月的预算为 10000 元,基于这个预算,我们要根据不同配置的价格来计算能租用多少资源,进而估算出训练时间。
各 GPU 配置的详细信息
NeuronForge 云服务 GPU
- Cloud - A100 X:经济高效的入门之选,FP16 算力为 539.8 TFLOPS ,int8 算力为 1522.4 LOPS,显存 83GB,带宽 3512 GB/s ,价格为¥1999.99 / 月。适用于对成本敏感,但仍需强大算力的项目,如中小型模型训练、初步的 AI 研究等。
- Cloud - A100 X Pro:性能与成本达到完美平衡,FP16 算力 617.8 TFLOPS ,int8 算力 1930.4LOPS,显存 107GB,带宽 4448 GB/s ,价格为¥2299.99 / 月。适合需要更高性能以加速模型训练和推理的项目,例如大规模图像识别、自然语言处理等。
- Cloud - A100 Z:极致性能的巅峰之作,FP16 算力 1079.6TFLOPS,int8 算力 3044.8 LOPS,显存 166GB,带宽 7024 GB/s ,价格为¥3999.99 / 月。适用于对性能要求极高的大型项目,如超大规模深度学习模型训练、复杂科学计算、高精度模拟等。
腾讯云 GPU
- NVIDIA T4(8 核,30GB 内存):FP16 算力约 80 TFLOPS ,价格为¥1,988.25 / 月。
- NVIDIA V100(12 核,92GB 内存):FP16 算力约 125 TFLOPS ,价格为¥3,155.84 / 月。
- NVIDIA A100(16 核,125GB 内存):FP16 算力约 312 TFLOPS ,价格为¥5,117.53 / 月。
阿里云 GPU
- NVIDIA T4(16 核,62GB 内存):FP16 算力约 80 TFLOPS ,价格为¥2,635.75 / 月。
- NVIDIA A10(8 核,30GB 内存):FP16 算力约 140 TFLOPS ,价格为¥6,143.88 / 月。
- NVIDIA A100(16 核,125GB 内存):FP16 算力约 312 TFLOPS ,年租金为¥170,533,换算成月租金约为 14211.08 元 / 月。
基于预算的资源租用与训练时间计算
每月可租用的 GPU 数量
根据每月 10000 元的预算,我们可以计算出每种 GPU 能租用的台数:
- Cloud - A100 X:可租用约 5 台 (10000÷1999.99)。
- Cloud - A100 X Pro:可租用约 4 台 (10000÷2299.99)。
- Cloud - A100 Z:可租用约 2 台 (10000÷3999.99)。
- NVIDIA T4(腾讯):可租用约 5 台 (10000÷1988.25)。
- NVIDIA V100(腾讯):可租用约 3 台 (10000÷3155.84)。
- NVIDIA A100(腾讯):可租用约 1 台(10000÷5117.53,取整)。
- NVIDIA T4(阿里巴巴):可租用约 3 台 (10000÷2635.75,取整)。
- NVIDIA A10(阿里巴巴):可租用约 1 台 (10000÷6143.88,取整)。
- NVIDIA A100(阿里巴巴):由于月租金超过预算,在本次预算下无法租用。
训练时间计算
以每台 GPU 的 FP16 算力为基础,计算出每秒的计算能力,从而得出训练时间:
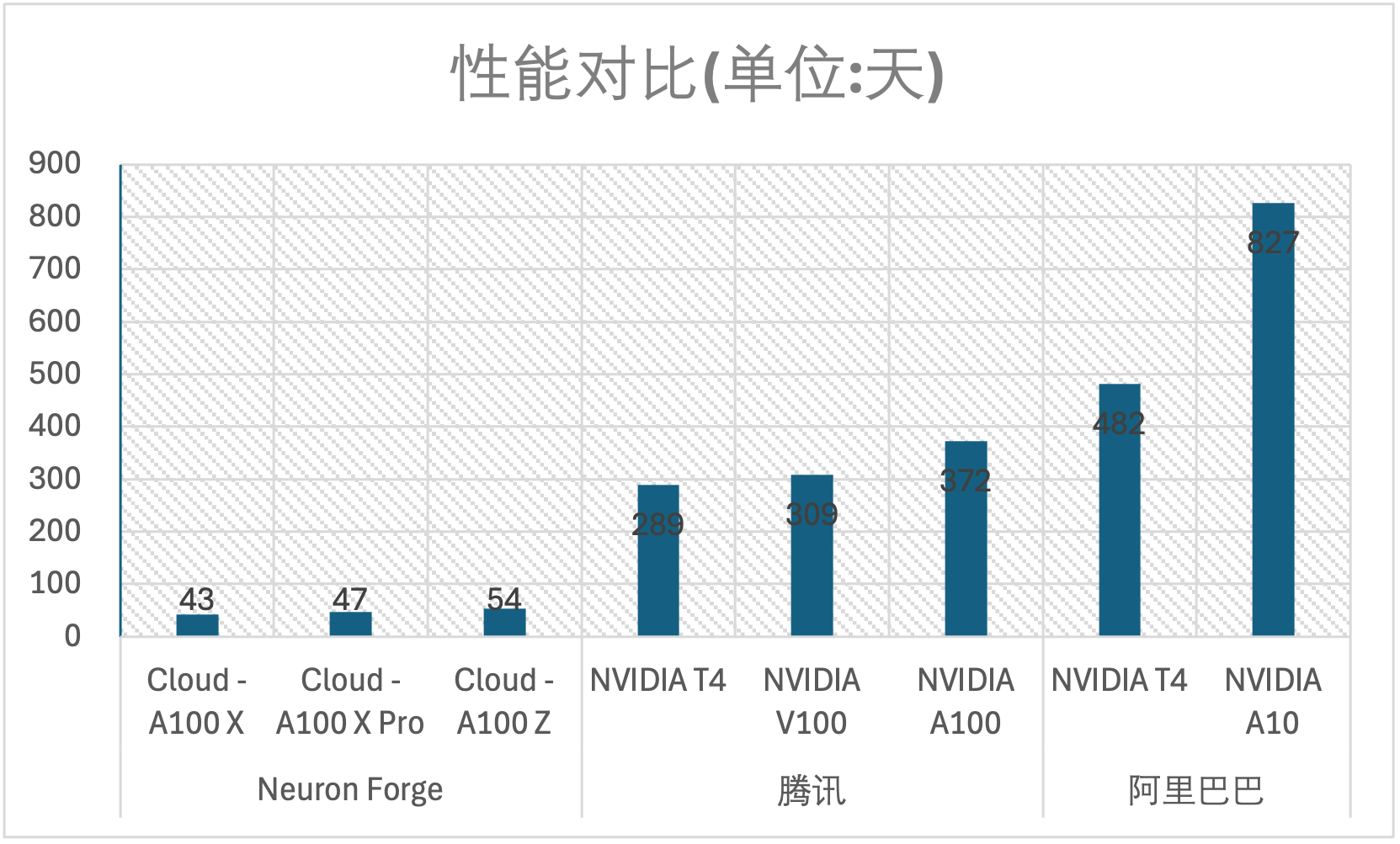
- Cloud - A100 X:单台训练时间约 214 天 (10²² FLOP÷(539.8×10¹² FLOP/s)换算成天),5 台并行训练时间约 43 天。
- Cloud - A100 X Pro:单台训练时间约 187 天 ,4 台并行训练时间约 47 天。
- Cloud - A100 Z:单台训练时间约 107 天 ,2 台并行训练时间约 54 天。
- NVIDIA T4(腾讯):单台训练时间约 1447 天 ,5 台并行训练时间约 289 天。
- NVIDIA V100(腾讯):单台训练时间约 926 天 ,3 台并行训练时间约 309 天。
- NVIDIA A100(腾讯):单台训练时间约 372 天 。
- NVIDIA T4(阿里巴巴):单台训练时间约 1447 天 ,3 台并行训练时间约 482 天。
- NVIDIA A10(阿里巴巴):单台训练时间约 827 天 。
综合对比与结论
通过以上计算,我们能直观看到不同 GPU 配置在预算限制下的训练时间差异。在众多选项中,Cloud - A100 系列产品脱颖而出,展现出卓越的性价比与性能优势。
Cloud - A100 X 凭借其亲民的价格和不错的算力,让预算有限的团队也能开启大规模模型训练的征程,5 台并行仅需约 43 天就能完成训练,极大地提升了效率,是追求低成本高效益方案的不二之选。
如果对性能有进一步要求,Cloud - A100 X Pro 在性能与成本之间找到了完美的平衡点。它能为大规模图像识别、自然语言处理等项目提供强劲动力,4 台并行大约 47 天的训练时长,助力项目快速推进,产出高质量成果。
而对于那些对性能要求近乎苛刻的超大规模深度学习模型训练、复杂科学计算等项目,Cloud - A100 Z 无疑是最佳拍档。其顶尖的算力配置,即使仅 2 台并行,也能在约 54 天内高效完成任务,为科研探索和商业创新提供坚实保障。
无论是从训练时间的高效性,还是满足不同项目需求的多样性来看,Cloud - A100 系列产品都展现出了强大的竞争力。如果你正在为深度学习模型训练的硬件选择而烦恼,不妨考虑 Cloud - A100 系列,它将为你的项目带来意想不到的惊喜与突破。大家在实际应用中如果有什么经验或者问题,欢迎在评论区留言交流!
官方网站: www.ituring.info

















 2503
2503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









