







一、引言
随着人工智能技术的飞速发展,智能问答机器人已成为企业客户服务、教育、智能助理等领域的关键技术工具。RagFlow(Retrieval-Augmented Generation Flow)作为一种结合了信息检索和生成的对话系统框架,能够高效地处理用户问题并提供准确的回答。本文将详细介绍如何基于RagFlow快速搭建一个功能强大的智能问答机器人,帮助读者从零开始,逐步掌握从环境准备到部署测试的全过程。通过本教程,您将学会如何利用RagFlow的核心机制,从数据准备、模型训练到最终部署,实现一个能够满足实际需求的智能问答系统。
二、RAG概述
RAG(Retrieval-Augmented Generation)是一种结合信息检索和文本生成的技术,旨在提高自然语言处理任务的性能。其核心思想是通过检索外部知识库中的信息,并将这些信息作为上下文输入到生成模型中,从而生成更加准确、相关和丰富的回答。
虽然当前的大模型发展百花齐放,开源模型急剧增加,但是,RAG技术仍然具有重要意义。首先,大模型虽然强大,但存在一些局限性,如依赖训练数据、容易产生幻觉、信息时效性差等问题。RAG通过引入外部知识库,能够动态地获取最新信息,解决传统大模型无法实时更新的问题。其次,RAG在特定领域(如金融、医疗等)中表现出色,因为它能够针对特定领域的知识进行优化,避免了通用大模型的泛化问题。
RAG技术的优势主要体现在以下几个方面:
-
提高准确性:通过与外部知识库的关联,RAG能够减少语言模型中的幻觉问题,生成更准确的回答。
-
保持信息时效性:RAG能够实时获取最新信息,确保生成内容的时效性和准确性。
-
降低训练成本:RAG不需要对整个大模型进行重新训练,只需在特定任务中引入外部知识库即可。
-
增强生成内容的可追溯性和隐私保护:生成内容的来源可以被追踪,同时支持私有化部署。
-
适应性强:RAG可以灵活应用于不同的大模型和任务场景,具有很高的可扩展性和灵活性。
三、什么是RagFlow
RagFlow是一个基于深度文档理解构建的开源RAG引擎,旨在为各种规模的企业和个人提供简化的RAG工作流程。该项目由infiniflow团队开发,于2024年4月开源,目前已在github上斩获40.8K星。该项目的初衷是通过结合大语言模型(LLM)和最新的检索技术,提供可靠且有理有据的问答服务,同时支持多种复杂格式数据的处理。
该项目具有以下功能:
-
高质量输入输出:从复杂格式的非结构化数据中提取知识并进行深度理解。
-
模板化分块:提供智能且可定制的模板,减少幻觉,通过可视化的文本分块允许人工干预。
-
基于引用的引用:减少幻觉,通过可视化分块快速查看关键引用和可追溯的答案。
-
异构数据源兼容性:支持Word、PPT、Excel、TXT、图片、扫描副本、结构化数据、网页等多种数据格式。
-
自动化RAG工作流:提供定制化的RAG编排,包括可嵌入的LLM和模型,多重召回与融合重排,以及与业务系统的无缝集成。
-
系统架构:包括知识构建流和检索问答解析流,涵盖文档识别、数据解析、文本切片、向量构建和索引优化,以及查询处理、多轮召回、LLM生成和引用追踪。
该项目具有以下多个优势:
-
高效性:结合最新的检索技术和大型语言模型,提升生成内容的质量和相关性。
-
灵活性:支持多种数据格式和模型对接,适用于不同规模的企业和个人。
-
易用性:提供详细的指南和在线演示,帮助用户快速上手。
-
社区支持:开源社区活跃,用户可以贡献代码和反馈,促进项目的持续改进。
四、RagFlow系统搭建
(一)准备工作
在使用 ragflow 构建知识库之前,需要确保你的硬件和软件环境满足一定的条件。硬件方面,建议使用 CPU 不低于 4 核心,内存大于等于 16GB,磁盘空间大于50GB的设备,以保证系统的流畅运行。软件方面,需要安装 Docker 且版本不低于24.0.0,Docker Compose 版本不低于 v2.26.1。如果你的设备尚未安装 Docker,可以参考官方文档进行安装 。
(二)下载和部署服务
RagFlow项目支持在Windows电脑及Linux电脑中部署,部署的过程大同小异,有一些需要注意的地方后续补充,先说通用部分。
1、手动下载源码或者使用git命令克隆ragflow仓库
$ git clone https://github.com/infiniflow/ragflow.git
或者手动链接infiniflow/ragflow: RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding.下载源码。[Tips:这边有个问题需要注意,在使用git进行克隆的时候可能会因为网络原因,导致下载的仓库文件出现文件丢失问题,建议直接手动到官方链接中下载后进行本地解压。解压的时候要把文件解压至根目录,即解压后的ragflow文件位置应该为:/ragflow/*。]
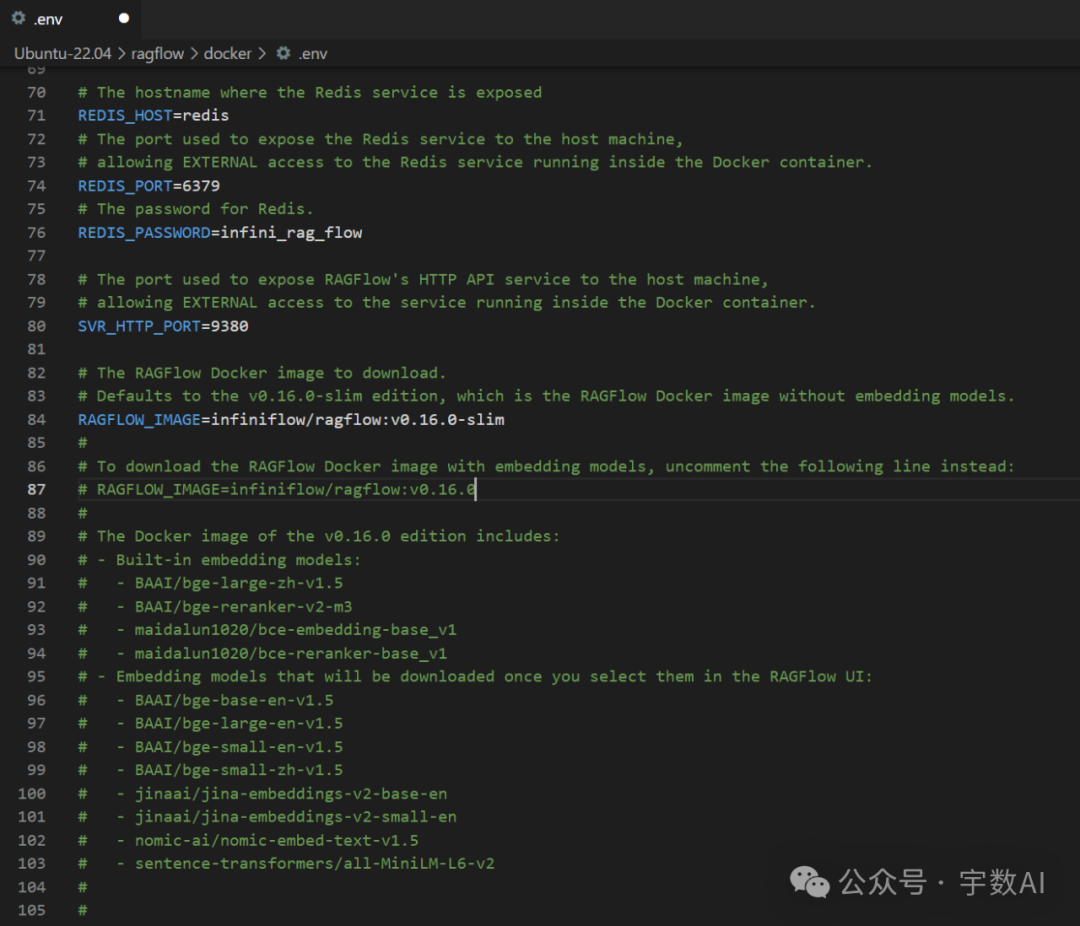
2、修改.env文件
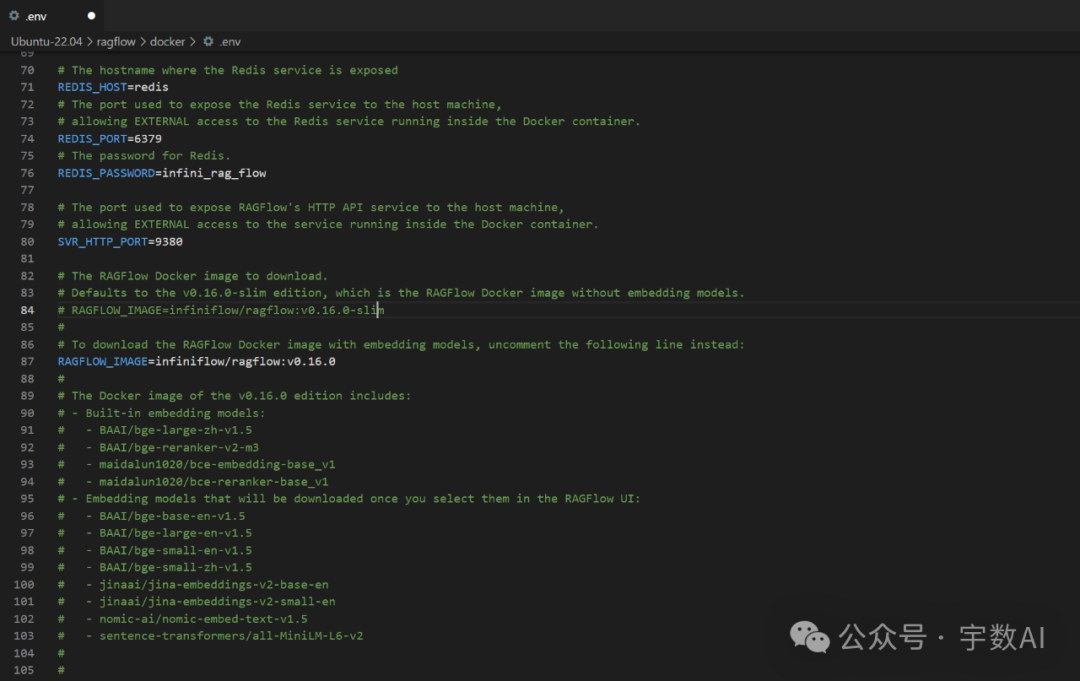
打开项目解压文件docker文件夹中的.env文件,对两行代码进行注释修改。区别是,默认的ragflow:v0.16.0-slim是没有带嵌入模型的,ragflow:v0.16.0带嵌入模型。
原文件:
修改后的文件:
3、部署安装
cd /ragflow/docker``docker compose -f docker-compose.yml up -d
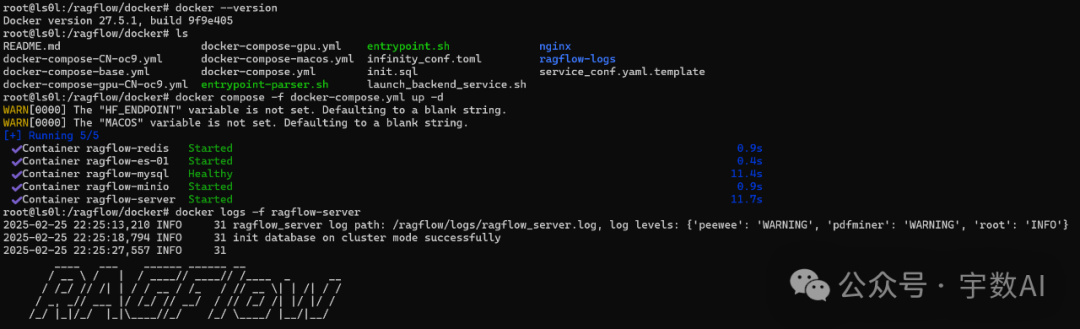
4、查看服务器状态
docker logs -f ragflow-server
出现下面的界面则说明服务器启动成功
`____ ___ ______ ______ __` `/ __ \ / | / ____// ____// /____ _ __` `/ /_/ // /| | / / __ / /_ / // __ \| | /| / /` `/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /` `/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/`` `` ``2025-02-25 22:25:27,557 INFO 31 RAGFlow version: v0.16.0 slim``2025-02-25 22:25:27,557 INFO 31 project base: /ragflow``2025-02-25 22:25:27,557 INFO 31 Current configs, from /ragflow/conf/service_conf.yaml:` `ragflow: {'host': '0.0.0.0', 'http_port': 9380}` `mysql: {'name': 'rag_flow', 'user': 'root', 'password': '********', 'host': 'mysql', 'port': 3306, 'max_connections': 100, 'stale_timeout': 30}` `minio: {'user': 'rag_flow', 'password': '********', 'host': 'minio:9000'}` `es: {'hosts': 'http://es01:9200', 'username': 'elastic', 'password': '********'}` `infinity: {'uri': 'infinity:23817', 'db_name': 'default_db'}` `redis: {'db': 1, 'password': '********', 'host': 'redis:6379'}``2025-02-25 22:25:27,557 INFO 31 Use Elasticsearch http://es01:9200 as the doc engine.``2025-02-25 22:25:27,630 INFO 31 GET http://es01:9200/ [status:200 duration:0.071s]``2025-02-25 22:25:27,634 INFO 31 HEAD http://es01:9200/ [status:200 duration:0.004s]``2025-02-25 22:25:27,635 INFO 31 Elasticsearch http://es01:9200 is healthy.``2025-02-25 22:25:27,640 WARNING 31 Load term.freq FAIL!``2025-02-25 22:25:27,643 WARNING 31 Realtime synonym is disabled, since no redis connection.``2025-02-25 22:25:27,646 WARNING 31 Load term.freq FAIL!``2025-02-25 22:25:27,649 WARNING 31 Realtime synonym is disabled, since no redis connection.``2025-02-25 22:25:27,650 INFO 31 MAX_CONTENT_LENGTH: 134217728``2025-02-25 22:25:27,650 INFO 31 SERVER_QUEUE_MAX_LEN: 1024``2025-02-25 22:25:27,650 INFO 31 SERVER_QUEUE_RETENTION: 3600``2025-02-25 22:25:27,650 INFO 31 MAX_FILE_COUNT_PER_USER: 0``2025-02-25 22:25:29,117 INFO 33 task_executor_0 log path: /ragflow/logs/task_executor_0.log, log levels: {'peewee': 'WARNING', 'pdfminer': 'WARNING', 'root': 'INFO'}``2025-02-25 22:25:29,360 INFO 33 init database on cluster mode successfully``2025-02-25 22:25:34,492 INFO 33 TextRecognizer det uses CPU``2025-02-25 22:25:34,586 INFO 33 TextRecognizer rec uses CPU``2025-02-25 22:25:34,603 INFO 33` `______ __ ______ __` `/_ __/___ ______/ /__ / ____/ _____ _______ __/ /_____ _____` ``/ / / __ `/ ___/ //_/ / __/ | |/_/ _ \/ ___/ / / / __/ __ \/ ___/`` `/ / / /_/ (__ ) ,< / /____> </ __/ /__/ /_/ / /_/ /_/ / /``/_/ \__,_/____/_/|_| /_____/_/|_|\___/\___/\__,_/\__/\____/_/`` ``2025-02-25 22:25:34,604 INFO 33 TaskExecutor: RAGFlow version: v0.16.0 slim``2025-02-25 22:25:34,604 INFO 33 Use Elasticsearch http://es01:9200 as the doc engine.``2025-02-25 22:25:34,609 INFO 33 GET http://es01:9200/ [status:200 duration:0.004s]``2025-02-25 22:25:34,611 INFO 33 HEAD http://es01:9200/ [status:200 duration:0.002s]``2025-02-25 22:25:34,611 INFO 33 Elasticsearch http://es01:9200 is healthy.``2025-02-25 22:25:34,614 WARNING 33 Load term.freq FAIL!``2025-02-25 22:25:34,615 WARNING 33 Realtime synonym is disabled, since no redis connection.``2025-02-25 22:25:34,618 WARNING 33 Load term.freq FAIL!``2025-02-25 22:25:34,619 WARNING 33 Realtime synonym is disabled, since no redis connection.``2025-02-25 22:25:34,619 INFO 33 MAX_CONTENT_LENGTH: 134217728``2025-02-25 22:25:34,619 INFO 33 SERVER_QUEUE_MAX_LEN: 1024``2025-02-25 22:25:34,619 INFO 33 SERVER_QUEUE_RETENTION: 3600``2025-02-25 22:25:34,619 INFO 33 MAX_FILE_COUNT_PER_USER: 0``2025-02-25 22:25:34,626 WARNING 33 RedisDB.queue_info rag_flow_svr_queue got exception: no such key``2025-02-25 22:25:34,627 INFO 33 task_consumer_0 reported heartbeat: {"name": "task_consumer_0", "now": "2025-02-25T22:25:34.626+08:00", "boot_at": "2025-02-25T22:25:34.603+08:00", "pending": 0, "lag": 0, "done": 0, "failed": 0, "current": null}``2025-02-25 22:25:43,056 INFO 31 init web data success:5.194876432418823``2025-02-25 22:25:43,057 INFO 31 RAGFlow HTTP server start...``2025-02-25 22:25:43,058 INFO 31 WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.` `* Running on all addresses (0.0.0.0)` `* Running on http://127.0.0.1:9380` `* Running on http://172.18.0.6:9380`
(三)安装过程
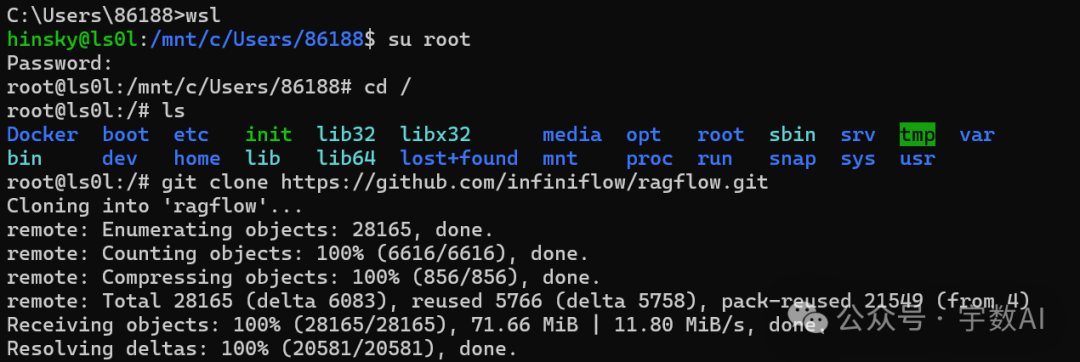
1、wsl克隆
2、下载docker desktop:https://www.docker.com/
3、下载并启动镜像
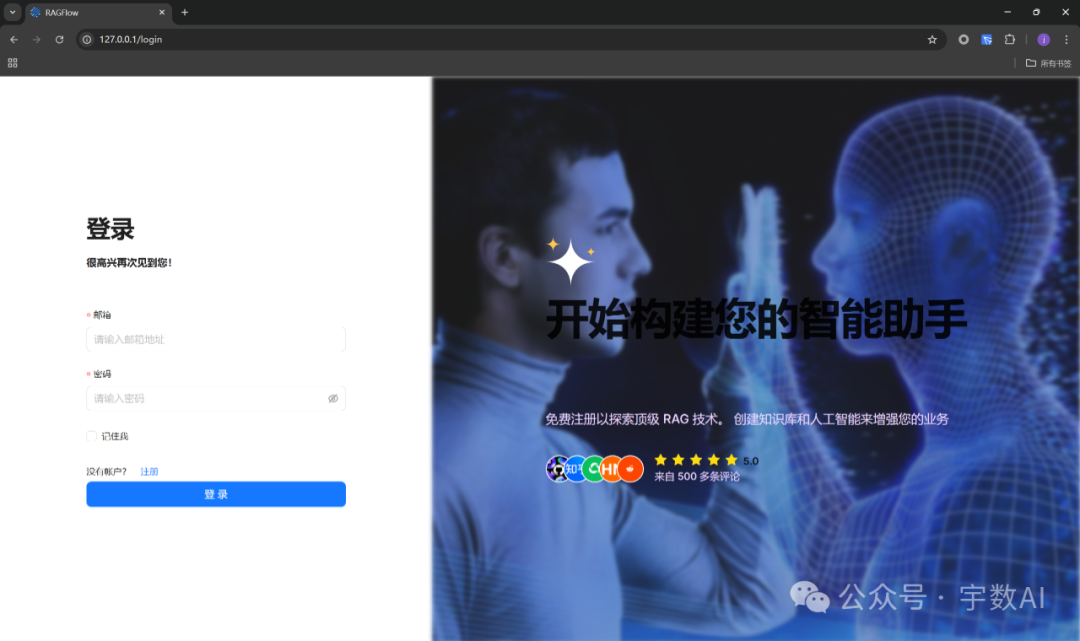
4、进入http://127.0.0.1:80访问RagFlow
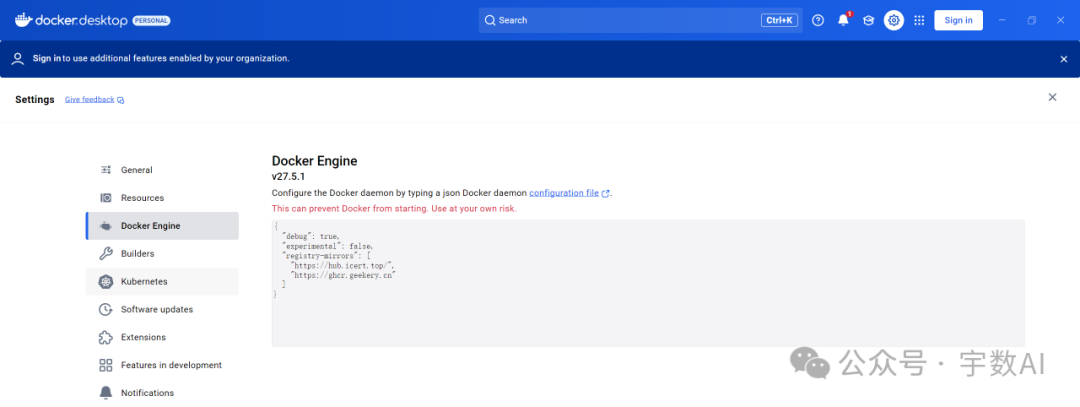
5、docker compose如果在拉取镜像时遇到网络问题,可以更改镜像源来解决问题
{`` ` `"debug": true,`` ` `"experimental": false,`` ` `"registry-mirrors": [`` ` `"https://hub.icert.top/",`` ` `"https://ghcr.geekery.cn"`` ` `]`` ``}
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









