







 超级会员免费看
超级会员免费看
CLIP-Adapter: Better Vision-Language Models with Feature Adapters
论文地址:
https://arxiv.org/abs/2110.04544
代码地址:
https://github.com/gaopengcuhk/CLIP-Adapter
主要工作:
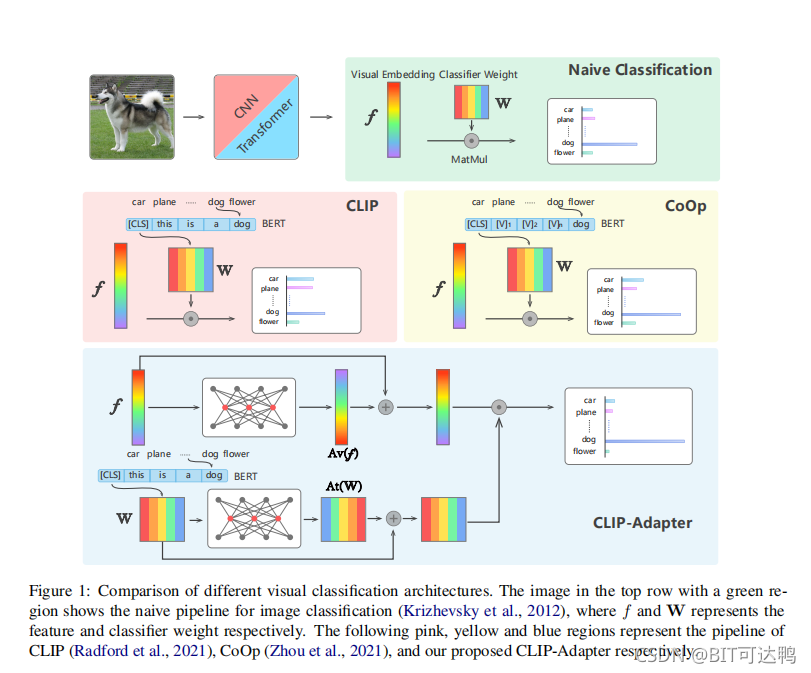
在本文中,作者证明了除了prompt tuning之外,还有另一种路径来实现更好的视觉语言模型。虽然提示调优是针对文本输入的,但作者建议CLIP-Adapter在视觉或语言分支上使用函数Adapter进行微调。具体来说,CLIP-Adapter采用了一个额外的瓶颈层来学习新特征,并执行与原始预训练特征相结合的残差样式特征混合。
因此,CLIP-Adapter能够优于上下文优化,同时保持一个简单的设计。对各种视觉分类任务的实验和广泛的消融研究证明了作者的方法的有效性。
具体实现:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











