








文章链接:https://arxiv.org/pdf/2407.03006
github地址:https://github.com/XiangGao1102/FCDiffusion

最近,大规模的文本到图像(T2I)扩散模型在图像到图像(I2I)转换中展现出强大的能力,允许通过用户提供的文本提示进行开放域的图像转换。本文提出了频率控制的扩散模型(FCDiffusion),一种基于扩散的端到端框架,从频域的角度提供了文本引导的I2I的创新解决方案。该框架的核心是一个基于离散余弦变换(DCT)的特征空间频域过滤模块,它在DCT域中过滤源图像的潜在特征,产生不同DCT频谱带的过滤图像特征,作为预训练的潜在扩散模型的不同控制信号。揭示了不同DCT频谱带的控制信号在源图像和T2I生成图像之间建立了不同的关联(如风格、结构、布局、轮廓等),从而实现了强调不同I2I关联的多样化I2I应用,包括风格引导的内容创作、图像语义操控、图像场景转换和图像风格转换。与相关方法不同,FCDiffusion建立了一个统一的文本引导I2I框架,通过在推理时切换不同的频率控制分支,适用于各种图像转换任务。通过大量定性和定量实验展示了FCDiffusion在文本引导I2I中的有效性和优越性。
频率控制扩散模型(FCDiffusion)用于文本引导的图像到图像(I2I)转换。FCDiffusion 基本上采用了ControlNet范式,该范式训练一个网络来控制预训练潜在扩散模型(Latent Diffusion Model)的文本到图像(T2I)去噪采样过程,其中控制信号是源图像的频域滤波潜在特征,这些特征带有一定的离散余弦变换(DCT)光谱带。在控制信号的条件下,模型通过配对的文本提示信息训练以重建源图像潜在特征中被移除的光谱成分。在推理时,可以通过填充任意编辑文本提示的信息来翻译源图像中缺失的DCT光谱区域。
如上图1所示,模型可以在不同频率控制模式下灵活处理各种I2I应用场景。
FCDiffusion的优点有三点:
-
通过应用不同的DCT滤波器构建相应的控制信号,适用于多种I2I任务;
-
它集成了多个可扩展的频率控制分支,允许在单一模型内灵活切换不同的I2I应用;
-
其学习目标简洁,对计算资源需求低,推理速度高效,并且在I2I视觉质量上具有竞争力。
方法
如下图2(a)所示,FCDiffusion基本上由三个组件组成:
-
预训练的LDM(Latent Diffusion Model)
-
频率过滤模块(FFM,Frequency Filtering Module)
-
频率控制网络(FCNet,FreqControlNet)。

预训练的LDM使用一个强大的自动编码器将源图像 压缩为紧凑的潜在表示 ,即 ,,其中 ,。一个DDPM在特征空间中训练,以从高斯分布中恢复 ,条件是配对的文本提示 :
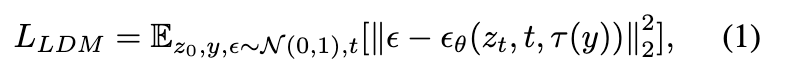
其中, 表示采样的时间步, 是时间步 时的噪声特征, 是去噪 U-Net,它以 、时间步 和文本嵌入 作为输入,并输出在前向扩散过程中采样的高斯噪声的估计, 是 OpenCLIP 转换器文本编码器。
为了将 LDM 从文本到图像生成适配为文本引导的 I2I(图像到图像转换),构建了一个频率过滤模块(FFM),以在频域(DCT 频谱)中过滤源图像 的编码图像特征 ,过滤后的图像特征 作为控制信号,通过频率控制网络(FCNet)控制 LDM 的反向去噪采样过程。FCNet 接收包含 的部分频谱成分(某个 DCT 频谱带)的控制信号 ,并优化以引导 LDM 使用来自 的部分频谱信息和来自 的文本信息重建 。从频域的角度来看,FCNet 的训练可以看作是通过配对的文本提示 恢复 的移除频谱成分的过程。
频率过滤模块
如上图2(b)所示,在 FFM 中,首先应用channel-wise 2D DCT 将源域潜在特征 转换为频域对应特征 :
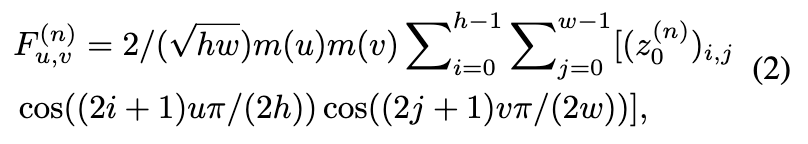
分别是 和 的第 个通道,。索引 表示空间域中的二维坐标,而 表示 DCT 频域中的二维坐标。在二维 DCT 频谱中,坐标较小的元素(靠近左上角原点)编码低频信息,而坐标较大的元素(靠近右下角)对应高频分量。如在介绍部分总结的那样,DCT 域中的不同频谱带编码了不同的图像视觉属性,因此可以用作条件指导,以控制不同的 I2I 关联。因此,手动设计了四个 DCT 滤波器(即 DCT 掩码),分别用于小通频、低通频、中通频和高通频域过滤,具体如下所述:
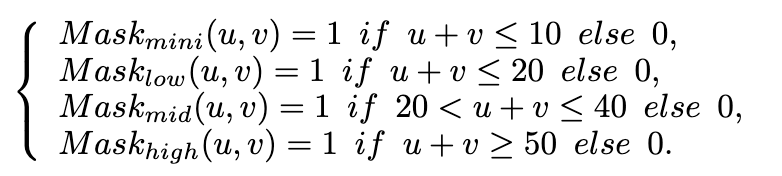
这些 DCT 滤波器分别提取仅包含微频率、低频率、中频率和高频率频谱带的 DCT 特征,通过与 直接相乘实现:
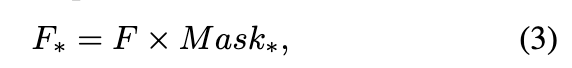
其中 。最后,使用二维逆离散余弦变换(2D IDCT)将过滤后的 DCT 特征 转换回空间域,作为最终的控制信号 :
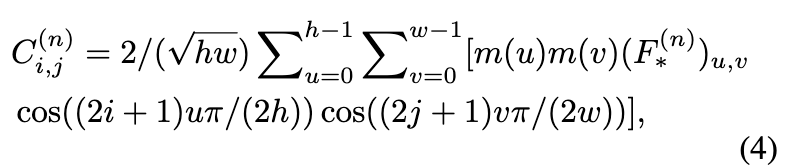
其中 和 分别是 和 的第 个通道,。通过微通频、低通频、中通频和高通频 DCT 过滤提取的控制信号 分别控制生成图像与源图像之间的风格、风格与结构、布局和轮廓一致性,从而允许多样化的 I2I 应用场景,强调不同的 I2I 关联。
从经验上看,观察到微通频过滤后的控制信号可能仍然包含一些图像结构信息,因此仍会在某种程度上限制生成图像的全局结构。为了消除结构约束并实现纯风格控制,提出并附加了一个等频扰动操作到微通频过滤分支的末端。在推理时,如图2(c)所示,该操作首先按频率水平(通过在 DCT 频谱中二维坐标的和量化)对 DCT 分量进行分组,然后在每组内对 DCT 元素进行扰动。等频扰动在不改变总体能量分布的情况下随机扰动 DCT 频谱,有助于消除源图像对生成图像的空间结构影响,同时保持 I2I 风格关联。
FCNet 结构细节
在每个时间步 ,FCNet 以当前的去噪结果 、控制信号 和文本嵌入 作为输入,并输出多尺度特征图,引导预训练的 LDM 重建 。借鉴 ControlNet (Zhang and Agrawala 2023),FCNet 是 LDM U-Net 编码器的一个可训练副本。如前面图 2(d) 所示,FCNet 中的每个 U-Net 块包含一个结合了时间嵌入的 ResBlock、一个自注意力块和一个结合了文本嵌入的交叉注意力块。FCNet 中的每个 ResBlock 有四个并行副本,分别对应于 FFM 中的四个 DCT 过滤分支。如图 2(e) 所示,这里也使用了 ControlNet 中提出的零卷积,用于平滑地将特征注入预训练的 LDM。同样,每个零卷积也有四个并行副本,分别对应于四个 DCT 过滤分支。
学习目标和训练细节
FCDiffusion是完全可微且端到端可训练的。目标是使用仅承载 部分 DCT 频谱带的控制信号 以及配对的文本提示 来重建源图像的潜在特征 。这相当于最小化以下条件噪声回归损失:
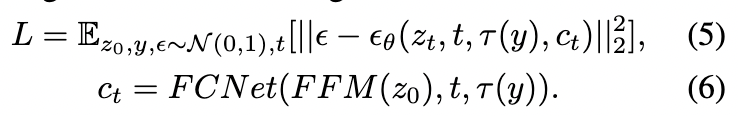
FCNet 是整个框架中唯一可训练的模块,其初始化来源于预训练的 LDM,除了额外的零卷积部分。在训练阶段,冻结 FCNet 中的所有自注意力和交叉注意力层,仅微调 ResBlock 和零卷积。观察到,冻结和共享注意力层可以减少可训练参数,而不会降低生成性能。本文的模型包含四个频率控制分支,分别由 [Mask∗, ResGroup∗, ZeroGroup∗] 组成,其中 ∗∈{mini, low, mid, high}。ResGroup∗ 表示参数组,包括与 DCT 过滤器 Mask∗ 对应的 FCNet 中所有 ResBlock∗ 复制品,ZeroGroup∗ 也是如此。这四个频率控制分支分别进行精细调节,并可以在推断时灵活切换,以适应不同的图像到图像应用场景。值得一提的是,模型中的控制分支可伸缩且可插拔,即通过设计相应的 DCT 滤波器并分配额外的 ResGroup 和 ZeroGroup 进行微调,可以简单实现更多的图像到图像控制效果。
实验
实验设置
在FCDiffusion中使用 Stable Diffusion v2-1-base 作为预训练的 LDM,并使用包含 625K 图像文本对的 LAION-Aesthetics 6.5+ 数据集作为数据集。将数据集随机分成训练集和测试集,比例为 9:1。在 512×512 的图像分辨率下进行训练,即 。将初始学习率设定为 。模型中的每个频率控制分支分别使用批量大小为 4,在单个 RTX 3090 Ti GPU 上进行 100K 次迭代的精细调节。在推断时,FCDiffusion 可以通过在不同频率控制分支之间切换,灵活适应各种图像到图像的应用场景。本文中所有结果均使用 DDIM 采样器生成,采样步骤为 50 步。
定性分析
如下图 3 所示,FCDiffusion通过在不同频率控制分支之间切换,在多种图像到图像的场景中产生高质量的结果。在微频率控制下,转换图像仅保留原始风格信息,没有源图像的结构约束,从而实现了基于风格的内容创建应用,即根据文本提示重新创建任何图像内容而不改变图像风格。在低频率控制下,生成图像保留了源图像的风格和空间结构,适合进行源图像的小规模编辑,即图像语义操作。在高频率控制下,转换图像在物体轮廓上与源图像保持一致,对风格外观的约束较少,允许根据文本提示操控图像风格,即图像风格转换。此外,还实现了图像场景转换的应用,其中唯一的图像到图像关联是图像布局,因此使用中频率控制来绕过源图像在低频率风格和高频率轮廓方面的约束。

实验结果比较
在下图 4 中,在一些具有挑战性的图像到图像转换示例上,定性比较了FCDiffusion与相关先进方法。为了简洁起见,将 Prompt-to-Prompt 方法简写为 Pro2Pro,InstructPix2Pix 简写为 insPix2Pix,Plug-and-Play 简写为 PAP。在图像语义操作方面,Pro2Pro、insPix2Pix 和 PAP 在生成语义上忠实的结果方面能力较弱,尽管在风格外观和空间结构上具有较高的一致性。Text2LIVE 的结果存在严重的伪影。VQCLIP 和 DiffuseIT 未能保留源图像的原始风格分布。在风格引导内容创建方面,Pro2Pro 难以生成与文本提示相符的图像内容。insPix2Pix 的结果在内容语义上更符合文本提示,但在风格保留方面相对较弱。其他方法要么未能生成忠实的内容,要么未能保持原始的风格外观。对于图像风格转换,VQCLIP 的结果展现出根据文本指导的准确风格分布,但失去了源图像的原始轮廓信息。相反,Text2LIVE 在保留图像轮廓方面做得很好,但未能精确根据文本提示转换图像风格。其他方法要么未能保持轮廓一致性,要么未能忠实地转换图像风格。

此外,还与不同噪声强度的 SDEdit 进行了比较(显示在括号中)。SDEdit(0.5) 基本上可以保留源图像的空间结构,但在图像语义操作方面在保持风格外观方面效果较差,为风格引导内容创建创建了结构不变的内容,并且在图像风格转换方面改变了足够的图像风格。对于较大的噪声强度,SDEdit(0.85) 的结果由于与源图像的弱连接,在所有图像到图像任务中失去了相应的关联。相比之下,FCDiffusion在所有图像到图像应用中有效地实现了所需的高质量性能。
如下图 5 所示,基于本文方法的低频率控制,FCDiffusion 可以处理图像语义操作,不仅能够处理狭窄的语义差距,还能处理源图像与目标文本提示之间的大语义差异。转换的图像可以在语义上与文本保持一致,并同时保留源图像的原始“风格+结构”,即使目标文本与源图像在语义上不相关。

消融研究
从以下四个方面对本文的模型设计进行了消融研究:
-
注入时间嵌入到FCNet的必要性;
-
注入文本嵌入到FCNet的必要性;
-
Equifrequency Shuffle操作在消除源图像与转换图像之间空间结构相关性中的有效性;
-
频率带范围对文本引导的图像到图像转换的影响。
通过删除所有包含时间嵌入的层来进行第一项研究。对于第二项研究,在训练期间不修改交叉注意力层,而是向FCNet输入空文本。如下图 6 中定性显示的那样,从FCNet中删除时间嵌入注入会导致图像转换结果不稳定,出现明显的噪声和伪影,这表明FCNet学习为LDM提供时间相关的引导特征是重要的。

此外,从FCNet中删除文本嵌入注入也会导致质量较低的图像结果,这表明文本信息对于FCNet在向LDM提供更精细控制方面是有用的。第三项研究的示例结果显示在下图 7 中,没有Equifrequency Shuffle进行的风格引导内容创建结果仍然在全局结构上与源图像相似,而使用Equifrequency Shuffle进行的结果在空间结构上与源图像更加分离,这证明了该操作在风格引导内容创建任务中解耦空间结构方面的有效性。

对于最后一项研究,在低频率控制下,定性比较了在不同低通滤波阈值(即提取的低频谱带的带宽变化)下实现的图像语义操作结果。如下图 9 所示的结果显示,阈值越高,转换图像越接近源图像。直观地说,提高低通滤波阈值会导致控制信号C承载更宽的源图像潜在特征的DCT谱带。因此,保留的源图像信息增加,转换图像更接近源图像。相反,降低低通滤波阈值会导致控制信号C中源图像的谱信息减少。在这种情况下,保留的源图像信息较少,因此转换图像与源图像的相似性较低。

定量评估
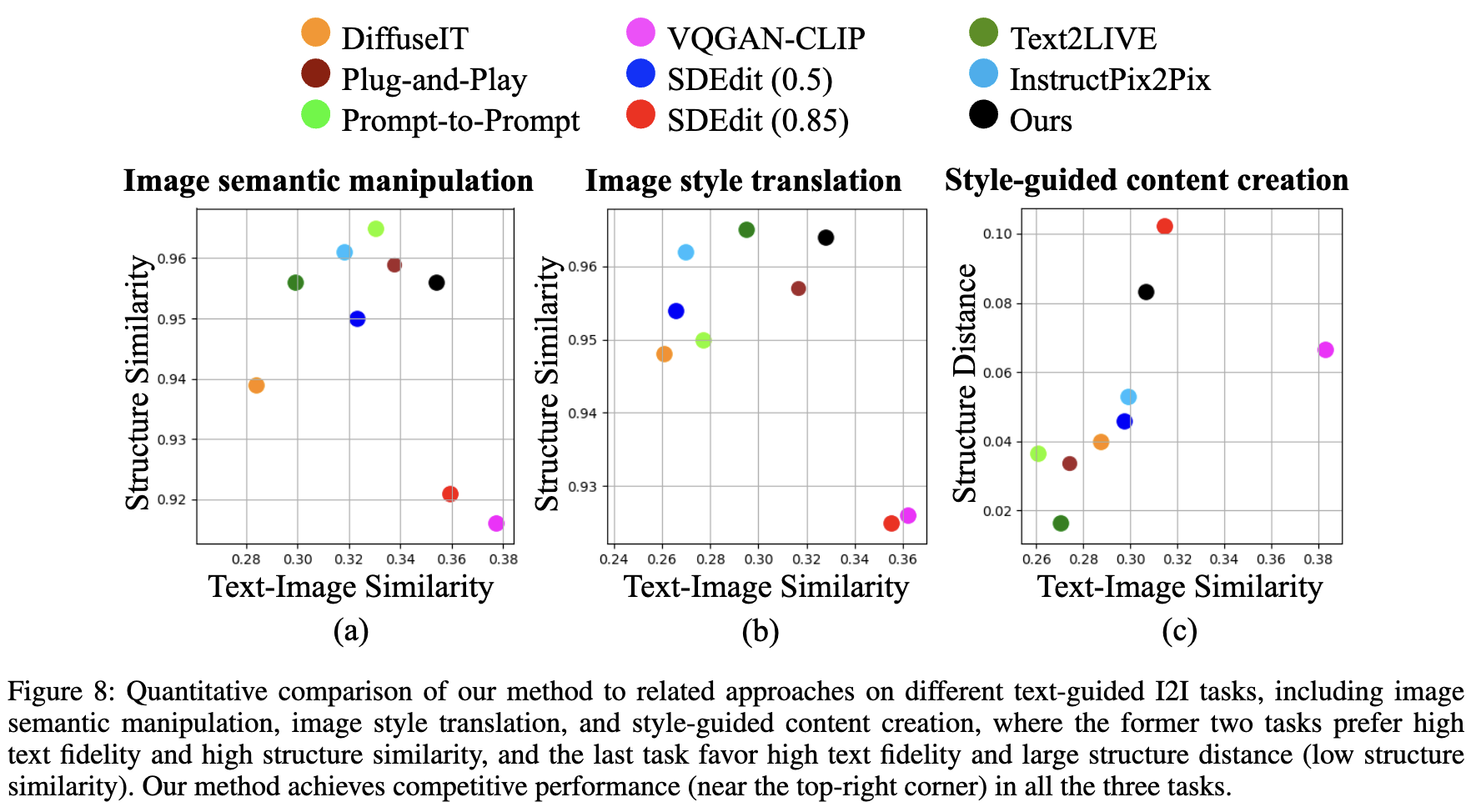
对于定量评估,针对每个图像到图像的应用场景进行了200次文本引导的图像转换,并计算了文本-图像相似性分数和图像到图像结构距离的平均值。文本-图像相似性分数用于衡量转换图像与目标文本提示的准确度(即文本保真度),使用CLIP余弦相似度作为度量标准。图像到图像结构距离旨在衡量源图像与转换图像之间的空间结构差异,使用DINO-ViT自相似性距离作为度量标准。相应地,定义图像到图像结构相似性为1减去结构距禒。
对于图像语义操作和图像风格转换任务,方法期望在文本保真度和图像到图像结构相似性上都能达到高分。尽管这两个指标存在矛盾,FCDiffusion在下图 8(a) 和 8(b) 中却取得了最佳的结果,显示出在文本保真度和结构相似性之间的最佳平衡。对于风格引导内容创建任务,方法被鼓励生成在内容描述上符合文本提示的空间结构分离的图像转换结果。因此,在这种情况下,希望高文本保真度和低结构相似性(即大结构距离)。如图 8(c) 所示,FCDiffusion在这两个方面都取得了竞争性能。尽管在此任务中,SDEdit(0.85) 和 VQGAN-CLIP 比FCDiffusion更靠近图 8(a) 和图 8(b) 的右上角位置,但这两种方法在前两个应用中的结构相似性非常低,这些应用偏好图像到图像结构一致性,如图 8(a) 和图 8(b) 所示。
进一步通过计算单个512×512图像转换的平均运行时间,比较了FCDiffusion与相关文本引导的图像到图像方法在推理速度上的差异。在NVIDIA RTX 3090 Ti GPU上评估的不同方法的结果报告如表 1 所示。基于CLIP的方法,如VQCLIP、DiffuseIT和Text2LIVE,由于需要在线优化过程驱动的CLIP损失来操作带文本的图像,因此速度显著较慢。基于反演的方法,如Prompt-to-Prompt和Plug-and-Play,大部分时间花费在DDIM反演(将源图像反演到高斯噪声空间的扩散轨迹)和DDIM重构(从反转的噪声特征重构源图像的去噪轨迹)上,使得图像转换仍然耗时。相反,FCDiffusion和insPix2Pix在推理速度上具有显著优势,因为它们不涉及任何反演或在线优化过程。
结论与讨论
本文从新颖的频域视角提出了一种文本引导的图像到图像(I2I)解决方案。所提出的模型,FCDiffusion,将预训练的文本到图像生成模型扩展到了文本引导的I2I领域,通过在DCT域中过滤源图像特征并利用带有不同DCT频谱带的过滤图像特征来控制潜在扩散模型的反向扩散过程。本文的方法可以解释为学习如何利用配对文本提示的文本信息填补源图像潜在特征的DCT频谱中移除的频谱成分。通过设计不同模式的DCT滤波器以及分配和训练相应的控制分支,本文的方法实现了对源图像到文本引导生成图像的多样化控制效果,包括通过迷你频率控制实现的风格引导内容创建,通过低频控制实现的图像语义操作,通过中频控制实现的图像场景转换,以及通过高频控制实现的图像风格转换,其中源图像和转换图像在图像风格、图像风格和结构、图像布局以及图像轮廓方面存在相关性。
本文的方法在推理时间和生成质量方面均具有优势,通过在推理时在不同控制分支之间进行切换,有效地适应多样化的I2I任务。尽管在多样性方面具有优势,FCDiffusion在设计新的DCT滤波器时仍需要分配和训练新的频率控制分支,这在某种程度上限制了其灵活性和效率。未来的工作中,将探索无需训练和即插即用的频谱带控制机制,使得在推理时可以插入任意的DCT滤波器,从而实现连续的控制效果。
参考文献
[1] Frequency-Controlled Diffusion Model for Versatile Text-Guided Image-to-Image Translation















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









