








文章链接:https://arxiv.org/pdf/2412.01243

亮点直击
提出了时间预测扩散模型(TPDM),该模型可以在推理过程中自适应地调整噪声调度,实现图像质量和模型效率之间的平衡。
为了训练TPDM,通过强化学习最大化图像质量,并根据去噪步骤数折扣,直接优化最终的性能和效率。
模型在多个评估基准上表现优越,在减少推理步骤的同时取得了更好的结果。
总览全文
扩散模型和流模型在文本到图像生成等多种应用中取得了显著成功。然而,这些模型通常在推理过程中依赖于相同的预定去噪调度策略,这可能限制了推理效率以及在处理不同提示时的灵活性。本文认为,最优的噪声调度应该适应每个推理实例,并提出了时间预测扩散模型(TPDM)来实现这一目标。
TPDM采用了一个即插即用的时间预测模块(TPM),该模块在每个去噪步骤中根据当前的隐空间特征预测下一个噪声水平。使用强化学习来训练TPM,目标是最大化一个奖励,该奖励通过去噪步骤的数量来折扣最终图像质量。通过这种自适应调度器,TPDM不仅生成与人类偏好高度一致的高质量图像,还能动态调整去噪步骤的数量和时间,从而提升性能和效率。
在多个扩散模型基准上训练了TPDM。在Stable Diffusion 3 Medium架构下,TPDM实现了5.44的美学评分和29.59的人类偏好评分(HPS),同时使用大约50%更少的去噪步骤,取得了更好的性能。
动机
以下图4中的几张图像为例,右侧的图像内容丰富,需要更多的去噪步骤来捕捉更细致的细节。相比之下,左侧的图像相对简单,可以使用较少的步骤生成,而不影响质量。此外,Karras也证明了不同的噪声调度对生成质量有很大影响。
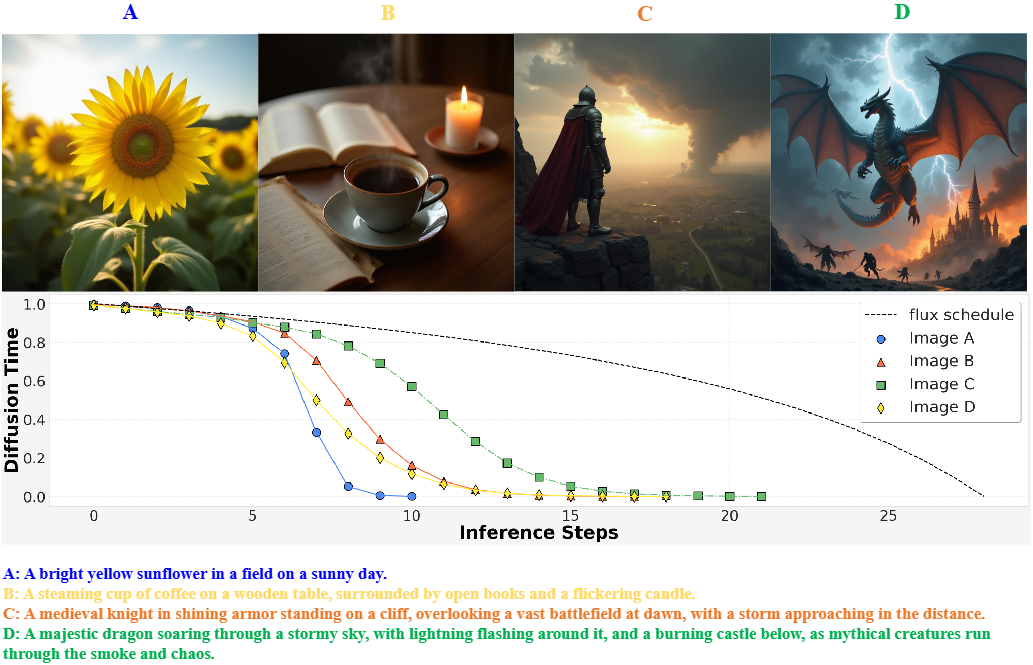
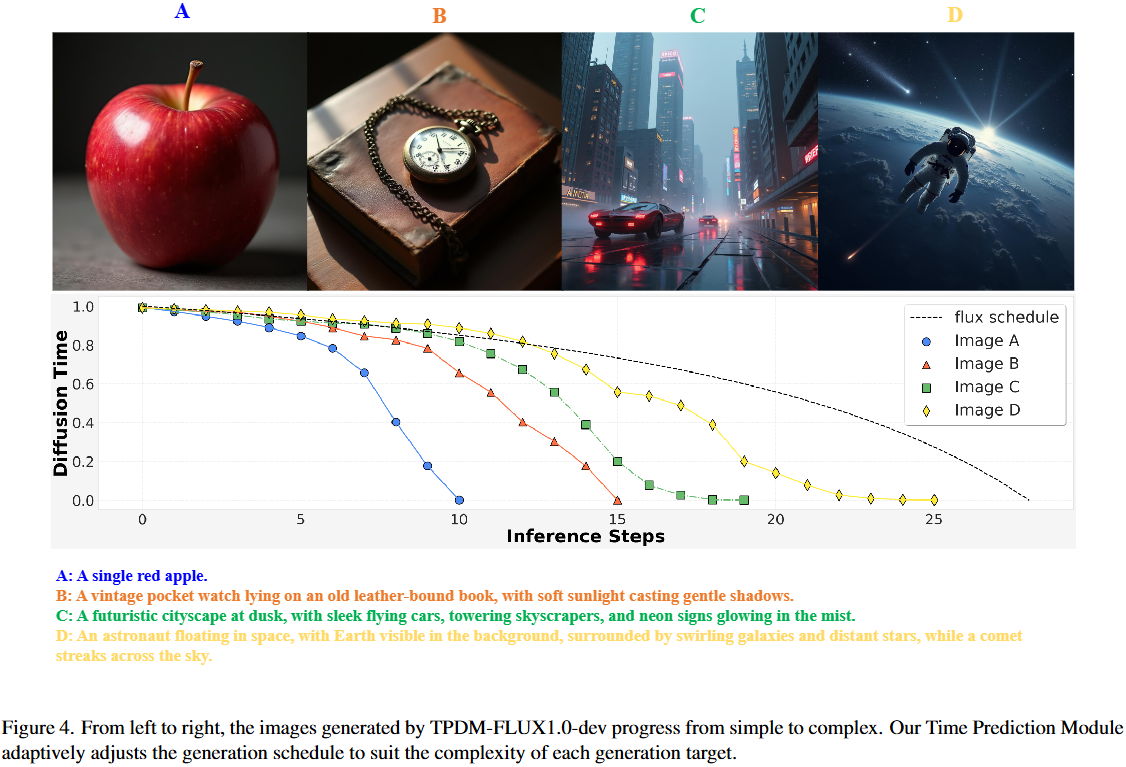
那么,不禁要问:是否可以在推理过程中自适应地调整去噪步骤的数量和每个步骤的噪声水平,而无需用户的手动干预?
基于此,本文提出了时间预测扩散模型(TPDM),该模型能够在推理过程中自适应地调整去噪步骤的数量和去噪强度。具体而言,TPDM通过实现一个即插即用的时间预测模块(TPM),该模块可以根据当前步骤的隐空间特征预测下一个扩散时间,从而使噪声调度能够动态调整。
TPM通过强化学习进行训练。将多步骤的去噪过程视为一个完整的轨迹,并将图像质量(经过去噪步骤数的折扣)作为奖励进行优化。图像质量通过与人类偏好对齐的奖励模型进行衡量。
TPM可以轻松集成到任何扩散模型中,几乎不增加额外的计算负担,并使模型能够自动调整超参数,例如样本步骤和每个步骤的噪声水平,从而在不需要人工干预的情况下实现图像质量和效率之间的平衡。此外,在训练过程中,模型的扩散过程与推理过程中保持一致,直接优化推理性能并减少去噪步骤。
在多个最先进的模型上实现了TPDM,包括Stable Diffusion和Flux。通过自适应噪声调度,模型在生成图像时平均使用了50%更少的步骤,且图像质量与Stable Diffusion 3持平或略有提高(0.322 CLIP-T,5.445美学评分,22.33选择评分,29.59 HPSv2.1)。这些结果表明,TPDM具有在追求高质量图像生成和提高模型效率之间找到平衡的潜力。
方法
在本节中,我们首先简要回顾扩散模型的基本原理,然后介绍时间预测模块(TPM),最后详细说明TPM的训练算法。
基础知识
扩散模型通过一个反向过程学习生成图像,该过程逐渐去除样本中的噪声。实现这一反向过程的主要范式是流匹配(Flow Matching)。因此,在此介绍流匹配模型的工作原理以及当前最先进模型的详细结构。
我们考虑一个生成模型,该模型在噪声分布 中绘制的样本 和数据分布 中的样本之间建立了一个映射。流匹配目标是直接回归一个向量场,该向量场生成一个概率流,使得从到 的过渡得以实现。
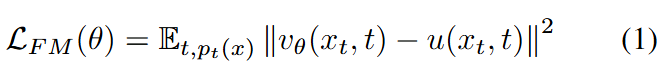
带有参数 的流匹配模型旨在预测噪声预测函数 ,该函数近似真实的速度场 ,并指导扩散过程从噪声分布转向生成样本的干净分布。因此,可以得到扩散常微分方程(ODE):
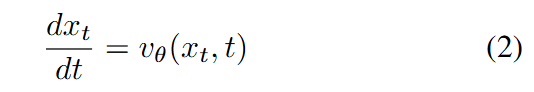
在推理过程中,假设我们生成一个图像需要 步,每一步都有一个时间 对应其噪声强度。则第 步的生成过程可以表示为:
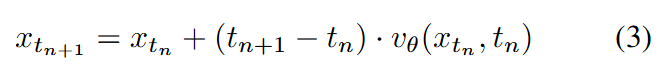
通常,在典型的流匹配算法中,会有一个预定的调度策略,在每一步安排时间。
目前,许多最先进的扩散模型都基于DiT架构,它们只关注条件图像生成,并采用调制机制来条件化网络,既考虑扩散去噪步骤中的扩散时间,也考虑文本提示。
使用这样的模型,可以根据隐特征和当前噪声水平执行单个去噪步骤。
时间预测扩散模型(TPDM)
如前所述,需要一系列去噪步骤才能使用训练好的扩散模型生成图像。通常,在这个过程中会对所有提示应用固定的噪声调度,为每个步骤分配一个预定的噪声水平。
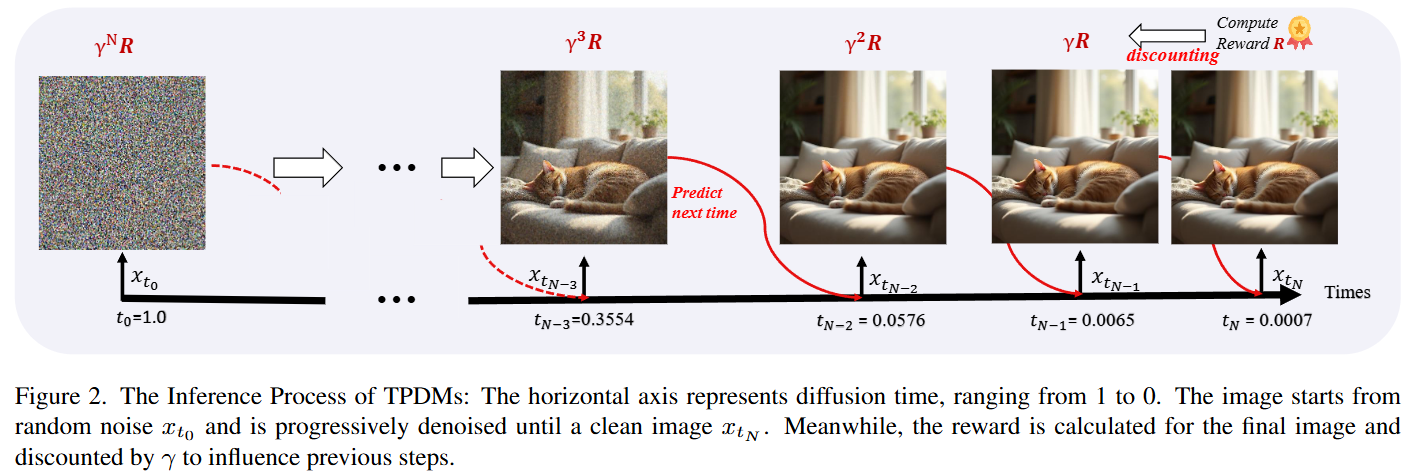
与此相对,为了使模型能够在推理时动态调整噪声调度,TPDM预测噪声强度 在相邻步骤之间的衰减方式。这确保噪声强度单调递减,反映去噪进程,避免出现反向进程。为了与下面的训练方法兼容,TPM估计去噪调度的分布,而不是预测一个精确的值。假设我们正在执行第 步去噪,除了当前步骤的去噪输出外,TPDM还预测衰减率 的分布。这个分布可以被参数化为一个Beta分布(0,1之间),其中TPDM需要估计两个参数 和。我们注意到,当 且 时,可以确保分布是单峰的。因此,重新参数化为TPDM预测两个实数 和 ,并通过公式(4)确定分布。然后,衰减率和下一个噪声级别可以通过公式(5)和(6)进行采样。
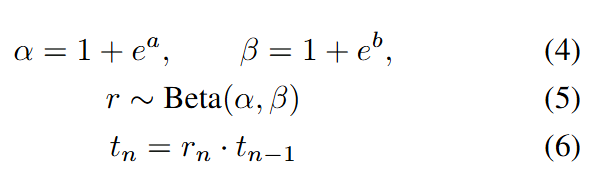
TPDM仅需要对原始扩散模型进行最小的修改:添加一个轻量级的时间预测模块(TPM),如下图3所示。该模块将transformer块前后的隐特征作为输入,从而考虑到当前噪声输入和本步骤的预测结果。经过几层卷积后,TPM将隐空间特征池化成一个单一的特征向量,并通过两个线性层预测 和 。我们还在TPM中使用了自适应归一化层,使模型能够感知当前的时间嵌入。
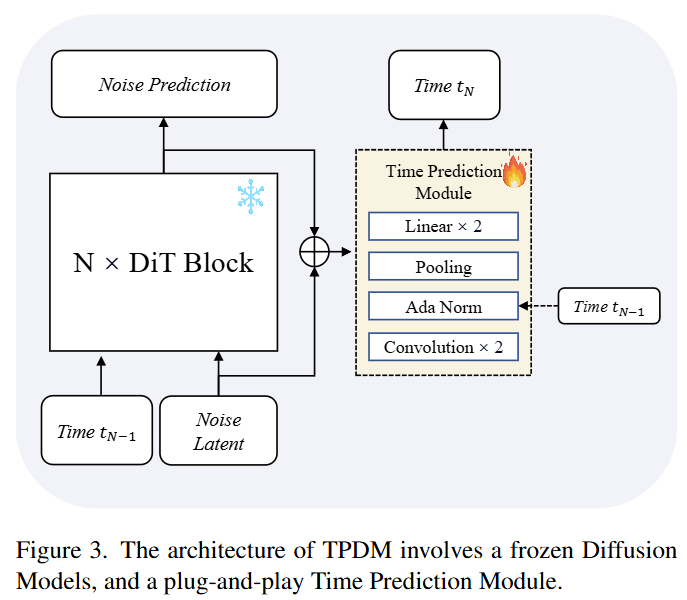
在训练过程中,冻结原始的扩散模型,只更新新引入的TPM。因此,模型在保持原有图像生成能力的同时,学习预测下一个扩散时间。
训练算法
为了训练TPM,需要至少执行两步去噪:在第一步预测下一个扩散时间,在下一步使用该时间进行去噪。一个简单的方法是将加噪图像作为输入提供给第一步,并通过在第二步计算重建损失来训练模型。梯度会通过预测的 反向传播,以更新第一步的TPM。然而,发现训练后的模型在推理时倾向于在很少的步骤内完成去噪过程,导致图像质量较差。我们假设,通过监督在两步后计算的损失,模型学会在两步后生成完全去噪的图像,并在中间停止以最小化损失函数。然而,重要的是整个扩散反向过程后的最终图像质量,而这一点在这种方法中被忽略。
因此,我们优化TPM,以最大化整个去噪过程后的图像质量,从而实现精确的时间预测。图像质量通过图像奖励模型进行衡量。考虑到整个推理计算图过于深度,无法进行梯度反向传播,我们使用邻近策略优化(PPO)进行训练,其损失函数公式为:
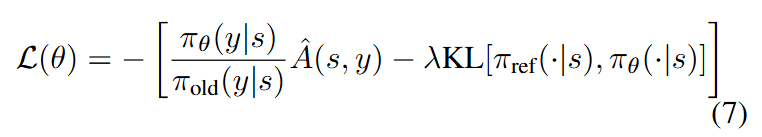
在我们的任务定义中,表示初始状态,包括输入提示 和高斯噪声;表示策略网络,例如我们的TPDM模型。表示用于采样轨迹的旧策略; 表示用于正则化的参考策略; 表示我们的策略所采取的动作,即调度时间; 表示在状态 下动作的优势。
将在后文中具体说明PPO中使用的动作和优势。
通常,当模型做出一系列预测时,PPO将每个单独的预测视为一个动作并以批量优化。然而,最近的RLOO研究指出,当奖励信号只出现在序列的末尾,并且环境动态完全确定时,可以将整个序列视为一个动作,而不会影响性能。因此,为简化起见,将整个生成过程,包括调度中的所有预测时间,视为一个单独的动作进行优化。
因此,在计算公式(7)中的期望时,将整个轨迹视为优化中的一个训练样本。然而,TPDM仅输出每个单独时间预测的分布,我们将其表示为。根据链式法则,整个生成过程的概率可以通过计算每次预测的乘积得到,如公式(8)所示:
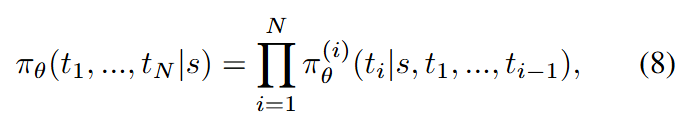
其中,(N) 表示生成步骤的总数。
在我们的模型中,概率策略网络 的每个因子是通过TPM计算的,TPM输出下一个步骤可能的扩散时间 的分布。
图像奖励与步骤数的折扣
在进行策略梯度训练时,通过当前的TPDM策略从高斯噪声生成图像来获得轨迹。由于这些生成的图像没有真实的真值,我们选择图像奖励模型,仅基于最后一步的最终图像分配奖励。考虑到我们不希望生成过程中出现过多的步骤,应用折扣因子 来折扣中间扩散步骤的奖励,并计算总的去噪步骤 的平均值。该轨迹的最终奖励如公式(9)所示:
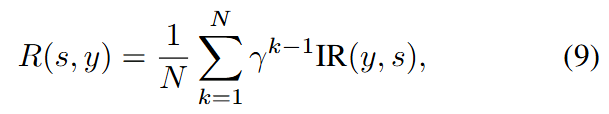
其中,表示图像奖励模型。
参考RLOO中如何直接从一个批次 计算优势 进行优化。在这个奖励函数中,TPDM将被鼓励生成高质量的图像,并在减少扩散步骤数的同时提高模型效率。通过调整 ,可以控制生成高质量图像时所应用的扩散步骤数。 值越小,允许的步骤数通常越少。
实验
实现细节
数据集
收集了用于训练模型的提示词。这些提示词是通过 Florence-2和 Llava-Next生成的,用于生成 Laion-Art和 COYO-700M数据集的图像描述,并利用这些提示词构成我们的训练集。
训练配置
使用 AdamW 优化器,, ,固定学习率为 ,最大梯度范数为 1.0。我们的 TPM 模块通常只需要大约 200 个训练步骤,批大小为 256。
主要结果
不同图像的动态调度
在前面图 4 中,展示了使用不同提示词生成的图像及其由 TPDM 预测的对应调度。当输入较短且简单的提示时,生成的图像包含较少的物体和细节,因此扩散时间会更快地下降,并在相对较少的步骤中达到 0。相反,当提供较长且更复杂的提示时,模型需要生成更多的视觉细节,因此扩散时间下降得较慢,以便生成精细的细节。在这种情况下,TPDM 在生成过程中需要更多的去噪步骤。
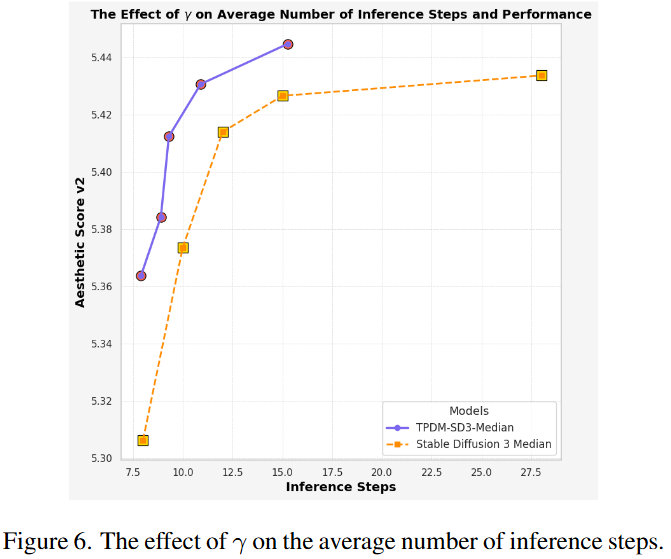
调整 γ 对不同步骤数的影响
公式(9)中的 γ 控制图像奖励在更多生成步骤中的折扣方式,从而影响扩散时间在去噪过程中的衰减速度,进而影响我们模型的平均去噪步骤数。
如下图 6 所示,当将 γ 从 0.97 降低到 0.85 时,TPDM 趋向于更快速地减少扩散时间,从而减少了采样步骤,从 15.0 步减少到 7.5 步。此外,与基准模型(黄色线)相比,TPDM(紫色线)在相同的推理步骤数下,始终能获得显著更高的美学分数,达到了模型效率和生成性能之间的良好平衡。
视觉对比
我们的方法在生成细粒度细节方面表现出色。TPDM 生成的图像相比 SD3-Medium(图 5C 中的图像)和结果中的图像,展示了更为真实的笔记本键盘。


定量结果
在多个最先进的扩散模型上应用了 TPM,包括 Stable Diffusion 3 Medium、Stable Diffusion 3.5 Large 和 Flux 1.0 dev,展示了 TPM 如何提升它们的性能。主要评估了两类指标:第一类是客观指标,包括 FID、与给定提示的对齐度(CLIP-T)以及人类偏好分数(美学分数 v2 和 HPSv2.1)。第二类是通过用户研究直接比较不同模型生成的图像。
定量指标
在表 1 中比较了 TPDM 和上述模型。尽管保持竞争力的性能,所有这些模型平均可以在推荐的步骤数的一半左右生成图像。
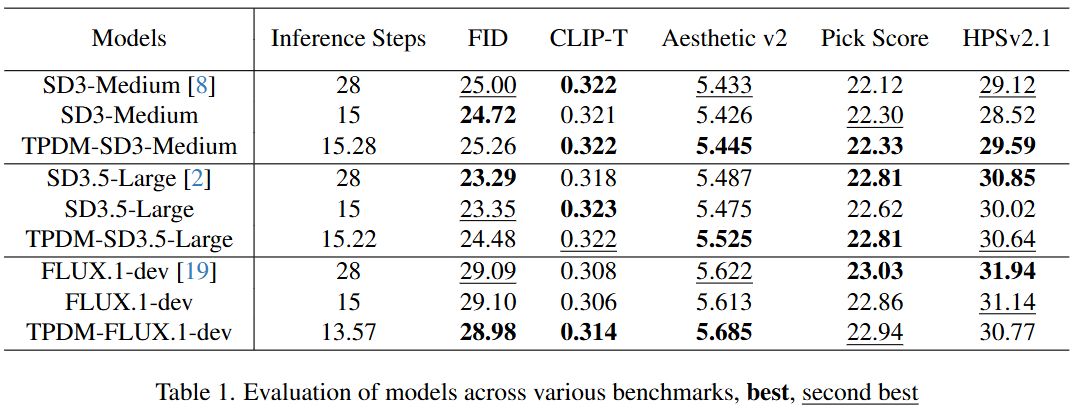
此外,代表人类偏好的指标提高得最多。例如,通过仅使用平均 15.28 步生成的图像,TPDM-SD3-Medium 获得了 29.59 的 HPS 分数,比使用相似步骤的 Stable Diffusion 3 高出 +1.07,比原始的 28 步结果高出 +0.47。这可能归因于我们在优化中使用的奖励模型,从而生成符合人类偏好的美学图像。
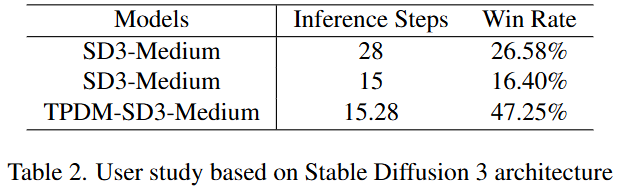
用户研究
为了更好地反映人类对这些模型的态度,通过邀请志愿者对比不同模型生成的图像,并选择他们偏好的图像,进行了用户研究。
具体来说,对于每个提示,我们提供了从 SD3-Medium 生成的 15 步和 28 步图像,以及从 TPDM-SD3-Medium 生成的图像。我们邀请了 15 名志愿者评估 50 个提示生成的图像。结果如表 2 所示,表明我们的模型生成的图像更符合人类的偏好。
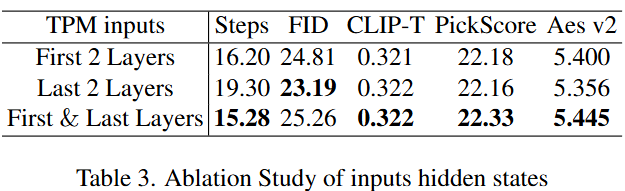
模块架构的消融实验
在本节中,我们对 TPM 输入的选择进行了消融实验。如表 3 所示,将第一层和最后一层的特征都输入到 TPM 中,比仅使用其中任意一层的特征表现更好。
结论与局限性
本文提出了时间预测扩散模型(TPDM),这是一个具有灵活去噪调度器的文本到图像扩散模型,可以针对不同的提示自动调整去噪调度。通过引入时间预测模块,通过强化学习和奖励模型有效地训练了 TPDM。基于当前领先的扩散模型架构(Stable Diffusion 3 Medium),我们训练了一个强大的 MM-DiT 基础 TPDM,并在多个文本到图像生成基准测试中表现出了竞争力的定量性能。
尽管 TPDM 展现了良好的性能,但仍有一些局限性。例如,在本文中,我们仅为 TPM 设计了一个相对简单的架构,如何改进该模块以获得更好的性能仍然是一个未解之题。其次,我们冻结了原始模型的参数,并采用我们的训练方法更新了扩散模型的参数,从而取得了更好的结果,这一方法还需要进一步探索。
参考文献
[1] Schedule On the Fly: Diffusion Time Prediction for Faster and Better Image Generation

















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









