







项目地址:NVIDIA TensorRT
前言
TensorRT(GIE)是一个C++库,适用于Jetson TX1和Pascal架构的显卡(Tesla P100, K80, M4 and Titan X等),支持fp16特性,也就是半精度运算。由于采用了“精度换速度”的策略,在精度无明显下降的同时,其对inference的加速很明显,往往可以有一倍的性能提升,而且还支持使用caffe模型。目前网上关于TensorRT的介绍很少,这里博主尝试着写一些,有空还会继续补充。
TensorRT简介
TensorRT目前基于gcc4.8而写成,其独立于任何深度学习框架。对于caffe而言,TensorRT是把caffe那一套东西转化后独立运行,能够解析caffe模型的相关工具叫做 NvCaffeParser,它根据prototxt文件和caffemodel权值,转化为支持半精度的新的模型。
目前TensorRT 支持caffe大部分常用的层,包括:
- Convolution(卷积层), with or without bias. Currently only 2D convolutions (i.e. 4D input and output tensors) are supported. Note: The operation this layer performs is actually a correlation, which is a consideration if you are formatting weights to import via GIE’s API rather than the caffe parser library.
- Activation(激活层): ReLU, tanh and sigmoid.
- Pooling(池化层): max and average.
- Scale(尺度变换层): per-tensor, per channel or per-weight affine transformation and exponentiation by constant values. Batch Normalization can be implemented using the Scale layer.
- ElementWise(矩阵元素运算): sum, product or max of two tensors.
- LRN(局部相应归一化层): cross-channel only.
- Fully-connected(全连接层) with or without bias
- SoftMax: cross-channel only
- Deconvolution(反卷积层), with and without bias
不支持的层包括:
- Deconvolution groups
- PReLU
- Scale, other than per-channel scaling
- EltWise with more than two inputs
使用TensorRT主要有两个步骤(C++代码):
- In the build phase, the toolkit takes a network definition, performs optimizations, and generates the inference engine.
- In the execution phase, the engine runs inference tasks using input and output buffers on the GPU.
想要具体了解TensorRT的相关原理的,可以参看这篇官方博客:
Production Deep Learning with NVIDIA GPU Inference Engine
这里暂时对原理不做太多涉及,下面以mnist手写体数字检测为例,结合官方例程,说明TensorRT的使用步骤。
TensorRT运行caffe模型实战
获取TensorRT支持
首先,Jetson TX1可以通过Jetpack 2.3.1的完全安装而自动获得TensorRT的支持,可参考博主之前的教程。TX1刷机之后,已经添加了一系列的C++运行库去支持TensorRT,如果掌握API的话,写一个C++程序就可以实现功能。
没有TX1,只有Pascal架构的显卡(如TITAN X),那也能感受TensorRT的效果,方法是去官网申NVIDIA TensorRT请测试资格,需要详细说明自己的研究目的,一般经过一两次邮件沟通后就能通过。博主目前已经获得TensorRT 1.0和2.0的测试资格,有机会也会进行TITAN X的TensorRT测试。
运行官方例程
这里,博主就先以Jetson TX1为例,看看官方自带的例程是如何运行的。自带例程的地址是:/usr/src/gie_samples/samples,我们打开文件夹,发现如下文件:
其中,data文件夹存放LeNet和GoogleNet的模型描述文件和权值,giexec文件夹是TensorRT通用接口的源代码,剩下的文件夹是特定网络的接口源代码。Makefile是配置文件,在gie_sample文件夹位置打开终端,输入sudo make就能完成编译,生成一系列可执行文件,存放在bin文件夹中,那我们就来看看bin文件夹的内容:
首先测试giexec文件:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
可以看到,总共3个必选参数,若干个可选参数。其中必选参数是caffe的模型描述文件,caffe模型权值文件以及输出的Blob名称。可选参数中,其中最重要的是half2参数,直接决定是否使用半精度,剩下的参数按需设置。下面就比较一下mnist检测是否使用半精度的运行区别。
1.使用半精度:
- 1
- 2
- 1
- 2
输出结果为
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.不使用半精度:
- 1
- 2
- 1
- 2
输出结果为
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
二者比较的话,发现使用半精度的话,确实速度确实上去了一些,但是提升幅度一般,大约快了50%的样子。当然,博主认为这个mnist例子太简单了,可能并不具备太大的说服力,大家可以参看官方给出的加速效果图。

那么剩下的几个可执行程序分别有什么用呢?我们还是来一一试验,结果如图:
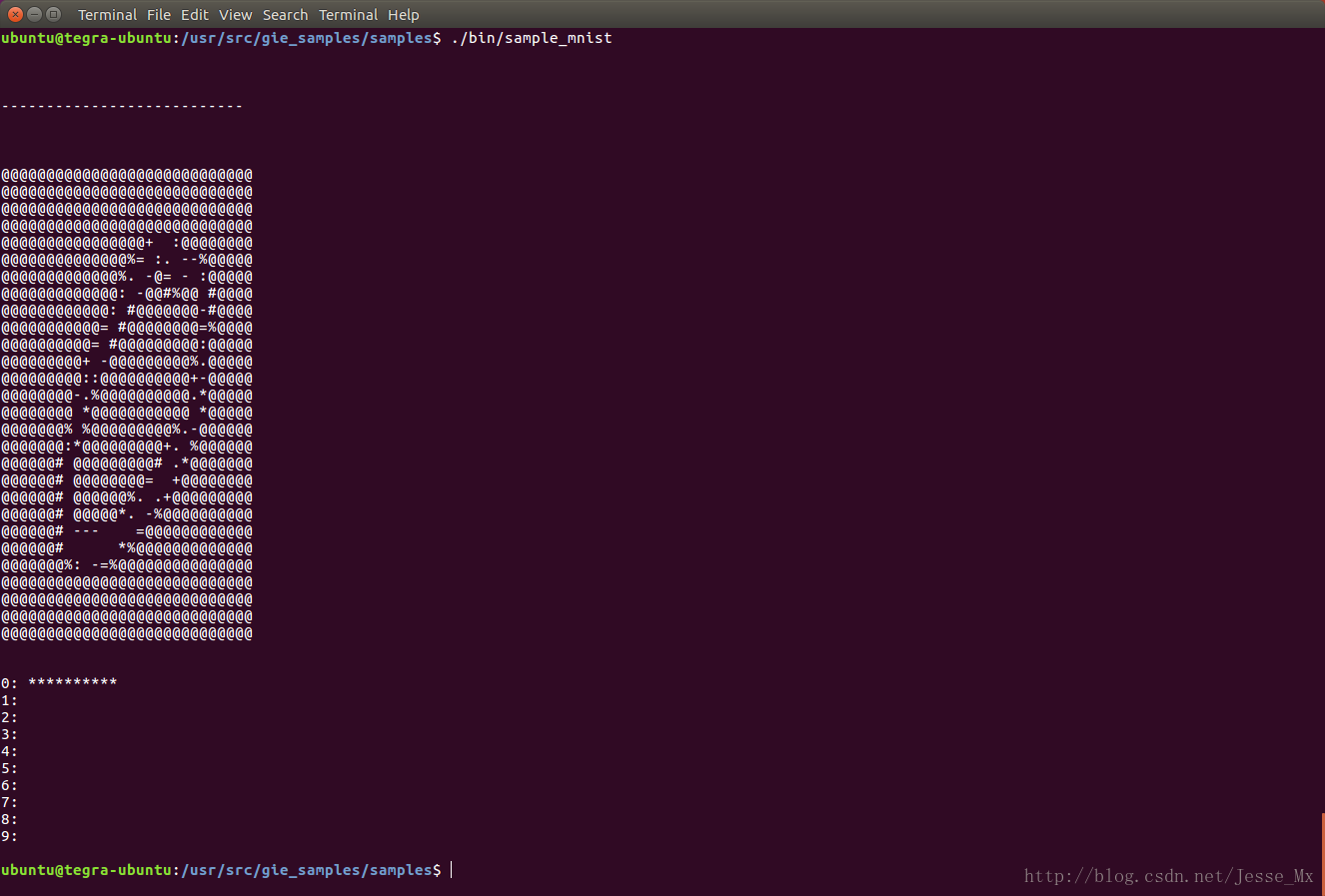
./bin/sample_mnist
./bin/sample_mnist_gie
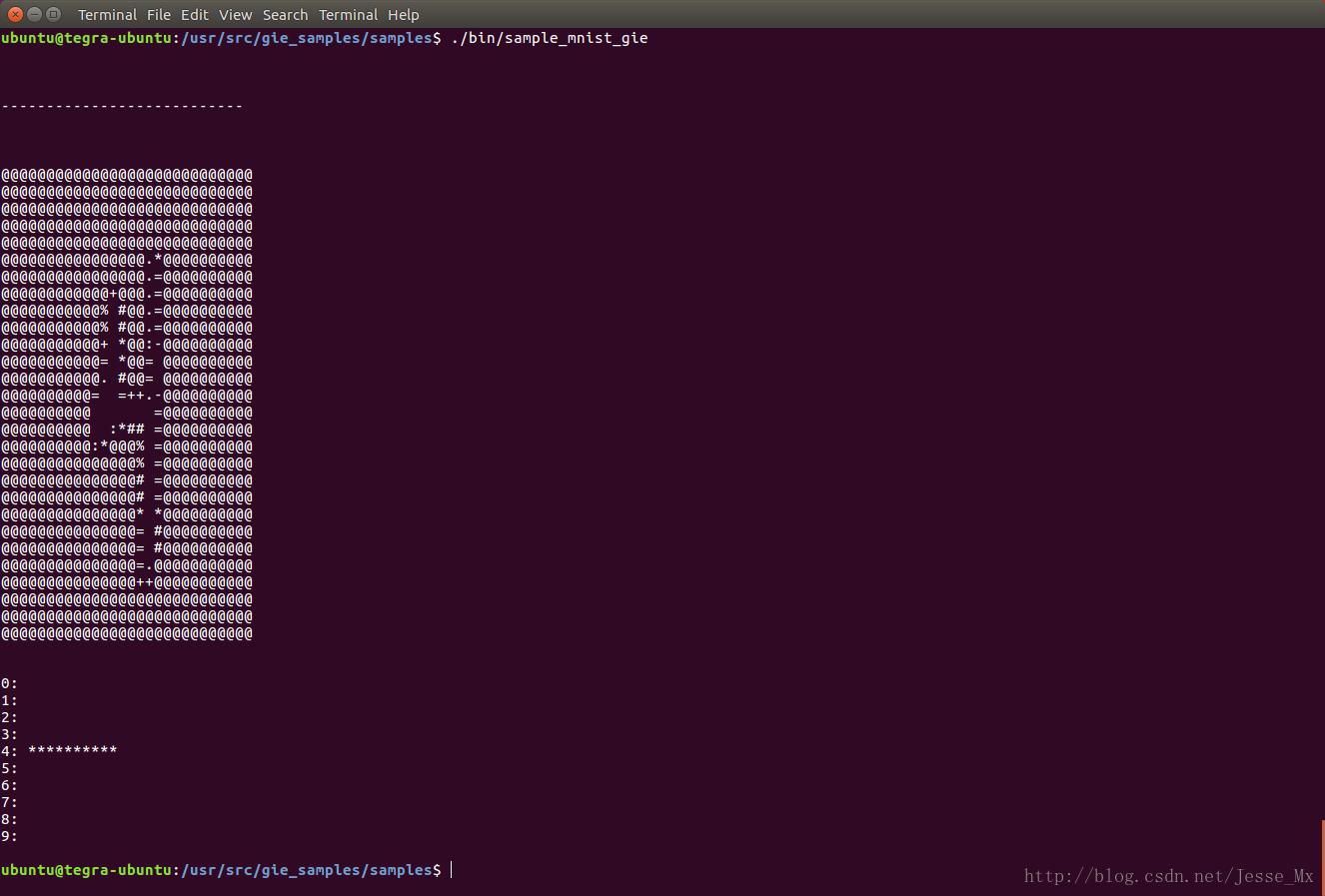
以上二者并没有带什么参数,貌似都在进行随机图片的检测,具体区别需要看源代码。
./bin/sample_googlenet

这个也没有参数可选,只是跑了一遍,最后得出一个时间。
写在后面
TX1自带的TensorRT例程操作起来并不难,博主认为,其最重要的价值在于那些cpp源代码,只有参考这些官方例程,我们才能独立写出C++代码,从而加速自己的caffe模型。giexec.cpp总共代码300多行,还是有点长的,虽然有些注释,但是如果没有仔细研究其API的话,里面的很多函数还是不会用。TensorRT的API文档内容有点多,本人暂时没空研究。
拥有Jetson TX1的小伙伴可以打开/usr/share/doc/gie/doc/API/index.html查看官方API文档,我这里连同例程源代码一起,都上传到了csdn,有兴趣者可以下载来看看。(貌似离开了TX1,API文档效果不佳)
TensorRT之例程源代码
TensorRT之官方API文档
有小伙伴在我之前的博客问道,TensorRT能不能加快目标检测框架如SSD的运行速度呢。博主所知道的是,目前还不能。因为现在的TensorRT有较大的局限性,仅支持caffe模型转化后进行前向推理(inference),训练部分还不支持。而且在我看来,目前应用99%都是在图片分类上,比如实现一下Alexlet或者GoogleNet模型的半精度转化,这样就把图片分类的速度提升一倍。由于SSD等目标检测框架含有特殊层以及结构复杂的原因,现有的那些TensorRT函数根本无法去进行转化和定义。
不过Nvidia官方已经开始重视目标检测这一块了,博主和Nvidia技术人员的邮件往来中,获悉未来的TensorRT将会支持Faster RCNN以及SSD,他们已经在开发中了,相信到时使用Jetson TX1进行目标检测,帧率达到10fps以上不是梦。
You mentioned the SSD Single Shot Detector. We are working on SSD right now. I think you’ll find there are some layers needed for SSD that aren’t supported in the versions of TensorRT available through these early release programs. We are adding a custom layer capability to the next version and providing support using that mechanism for Faster R-CNN and SSD.















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









