







选自Google.research
机器之心编译
参与:黄小天、李泽南
在谷歌提交热点论文《Attention Is All You Need》和《One Model To Learn Them All》不久之后,这家公司很快就发布了最新研究的模型和训练集。昨天,谷歌发布了一个名为 Tensor2Tensor(T2T)的 TensorFlow 开源系统,希望能够以此提高机器学习社区的研究和开发速度,其中包含了谷歌近期提出的多个最新模型。此外,T2T 将深度学习所需的各个组件以模块化呈现,这意味着开发者和研究人员能够更快地实现自己的新想法。
链接:https://github.com/tensorflow/tensor2tensor
深度学习(DL)在很多技术领域中都已获得广泛应用,包括机器翻译、语音识别和物体识别等。在研究社区中,人们可以找到各类研究作者开源的代码,复制他们的结果,进一步发展深度学习。但这些深度学习系统大多为特定的任务进行了专门的设置,只适用于特定的问题和架构,这意味着人们难以开展新的实验并比较结果。
昨天,谷歌研究人员发布了 Tensor2Tensor(T2T),一个用于在 TensorFlow 中训练深度学习模型的开源系统。T2T 能够帮助人们为各种机器学习程序创建最先进的模型,可应用于多个领域,如翻译、语法分析、图像信息描述等,大大提高了研究和开发的速度。T2T 中也包含一个数据集和模型库,其中包括谷歌近期发布的几篇论文中提出的最新模型(Attention Is All You Need、Depthwise Separable Convolutions for Neural Machine Translation 和 One Model to Learn Them All)。
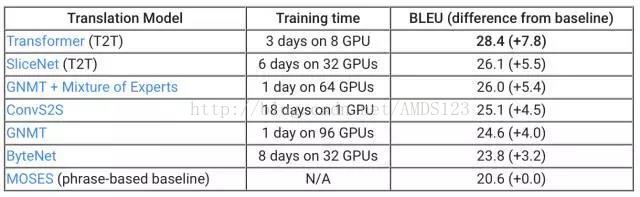
在标准 WMT 英语-德语 翻译任务中,各模型的 BLEU 分数(越高越好)。
作为举例,谷歌将 T2T 库应用于机器翻译任务中,如上表所示,T2T 库中的两个模型:SliceNet 和 Transformer 的表现超过了此前的业界最佳水平 GNMT+MoE。其中,Transformer 的分数超过 GNMT 模型 3.8 分,而 GNMT 已经超过基准水平(基于短语的翻译系统 MOSES)4 分了。值得注意的是,使用 T2T,你可以用一块 GPU,一天的时间实现此前业界最佳水准的表现:使用小型 Transformer 模型(上图未显示),在单 GPU 训练一天时间后可以达到 24.9 的 BLEU 分数。现在,所有人都可以自己构建最好的翻译模型了。
可参看 GitHub 说明:https://github.com/tensorflow/tensor2tensor/blob/master/README.md
模块化多任务训练
T2T 库构建于 TensorFlow 之上,定义了深度学习系统所需的各个组件:数据集、模型架构、优化器、学习速率衰减方案、超参数等等。最重要的是,它实现了所有这些组件之间的标准对接形式,并使用了目前最好的机器学习方法。这样,你可以选择任何一组数据集、模型、优化器,然后设定超参数,开始训练,并查看它的性能。通过架构的模块化,在输入和输出数据之间的每一块都是张量-张量的函数。这意味着如果你对模型架构有了新想法,你无须改动整个模型,你可以保留嵌入部分、损失函数和其他所有部分,仅仅用自己的函数替换模型体的一部分,该函数将张量作为输入,并返回一个张量。
这意味着 T2T 很灵活,训练无需局限在一个特定的模型或数据集上。它如此容易以至于像著名的 LSTM 序列到序列模型这样的架构可通过几行代码被定义。你也可以在不同领域的多任务上训练一个单一模型,你甚至还可以同时在所有的数据集上训练一个单一模型。很高兴我们的 MultiModel(就像这样被训练并包含在 T2T 中)在很多任务上获得了好结果,甚至是在 ImageNet、MS COCO、WSJ、 WM 和 Penn Treebank 解析语料库上进行联合训练也不例外。这是首次单个模型被证明可以同时执行多个任务。
内置的最佳实践
我们的首次发行也提供了脚本,可生成大量数据集(广泛用于研究社区),一些模型,大量超参数配置,trade 的其他重要技巧的一个执行良好的实现。尽管全部列举它们很难,如果你决定用 T2T 运行你的模型,将会免费获得序列的正确填充(padding),相应的交叉熵损失,调试良好的 Adam 优化器参数,自适应批处理,同步的分布式训练,调试良好的图像数据增强,标签平滑和大量的超参数配置(包括上述在翻译方面取得当前最佳结果的超参数配置)。
例如,考虑一下把英语语句解析成其语法选区树(grammatical constituency tree)。这个问题被研究了数十年,人们费了很大劲给出了可靠的方法。它可被称为序列到序列问题,可通过神经网络来解决,但它过去常常需要很多调试。借助 T2T,我们只需几天就可以添加解析数据集生成器,并调节我们的注意力转换器模型以训练这一问题。令我们高兴而惊讶的是,我们仅在一周内就获得了非常好的结果:
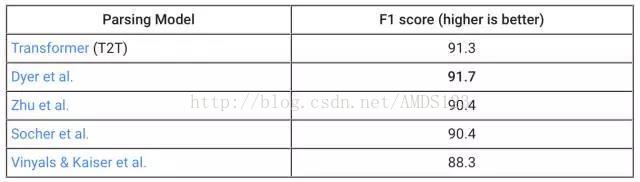
在 WSJ 23 节的标准数据集上解析 F1 分数。我们只在 Penn Treebank WSJ 训练集上比较了本文中被特殊训练过的模型,更多结果详见论文(https://arxiv.org/abs/1706.03762)。
为 Tensor2Tensor 做贡献
除了探索现有的模型和数据集之外,你还可以轻易定义自己的模型并把数据集添加到 T2T。我们相信已收录的模型将很好地执行诸多 NLP 任务,因此,只是添加你的数据集就会带来有趣的结果。通过构建 T2T 组件,我们可以使其很容易地为你的模型做贡献,并观察其如何执行不同任务。通过这种方式,整个社区可受益于基线库,并加速深度学习研究。因此,前往我们的 Github 库(https://github.com/tensorflow/tensor2tensor),尝试一些新模型,并贡献出你的吧。
论文:Attention Is All You Need

论文链接:https://arxiv.org/abs/1706.03762
在编码器-解码器配置中,显性序列显性转录模型(dominant sequence transduction model)基于复杂的 RNN 或 CNN。表现最佳的模型也需通过注意力机制(attention mechanism)连接编码器和解码器。我们提出了一种新型的简单网络架构——Transformer,它完全基于注意力机制,彻底放弃了循环和卷积。两项机器翻译任务的实验表明,这些模型的翻译质量更优,同时更并行,所需训练时间也大大减少。我们的模型在 WMT 2014 英语转德语的翻译任务中取得了 BLEU 得分 28.4 的成绩,领先当前现有的最佳结果(包括集成模型)超过 2 个 BLEU 分值。在 WMT 2014 英语转法语翻译任务上,在 8 块 GPU 上训练了 3.5 天之后,我们的模型获得了新的单模型顶级 BLEU 得分 41.0,只是目前文献中最佳模型训练成本的一小部分。我们表明 Transformer 在其他任务上也泛化很好,把它成功应用到了有大量训练数据和有限训练数据的英语组别分析上。
论文:One Model To Learn Them All

论文链接:https://arxiv.org/abs/1706.05137
深度学习在许多领域都获得了很好的成果,从语音识别、图像识别到机器翻译。但在每个问题上,深度学习模型都需要进行长时间的架构研究和调试。我们提出了一个单一模型,它在多个不同领域的任务中都产生了良好结果。这种单一模型同时在 ImageNet、多个翻译任务、图像抓取(COCO 数据集)、一个语音识别语料库和一个英文解析任务中获得训练。该模型架构整合了多个领域的组件。它包含卷基层、注意力机制和 sparsely-gated 层,其中的每个组件对于特定任务都是非常重要的,我们观察到添加这些组件并不会影响模型性能——在大多数情况下,它反而会改善任务中的表现。我们还展示了多个任务联合训练会让仅含少量数据的任务收益颇丰,而大型任务的表现仅有少量性能衰减。
原文链接:https://research.googleblog.com/2017/06/accelerating-deep-learning-research.html














 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









