







【学术前沿】PATHWAYS:谷歌大规模异构计算编排调度系统(Jeff Dean 和 Sanjay Ghemawat联合出品)
本文提出了一种新的加速器大规模编排层的设计。Pathways系统旨在探索新系统和机器学习研究思路,同时保持当前模型的最新性能。Pathways使用异步运算符的分片数据流图,这些运算符消耗和生成futures,并在数千个加速器上有效地联合调度异构并行计算,同时协调其专用互连上的数据传输。Pathways利用了一种新颖的异步分布式数据流设计,该设计允许控制平面并行执行,而不管数据平面中的依赖关系。通过精心设计,这种设计允许Pathways采用单个控制器模型,从而更容易表达复杂的新并行模式。试验证明,当在2048个TPU上运行SPMD计算时,Pathways可以与最先进的系统实现性能对等(约100%的加速器利用率),同时还可以提供与跨16级流水线或跨数据中心网络连接的两个加速器岛分片的Transformer模型的SPMD情况相当的吞吐量。
论文原作:https://arxiv.org/pdf/2203.12533
沐神解读:https://www.bilibili.com/video/BV1xB4y1m7Xi/?share_source=copy_web&vd_source=36ba379bf9240e380aa11e6759cd5b7f

摘要
PATHWAYS是Google的大规模异构计算编排调度系统,专为机器学习而设计。
- 采用了分片的数据流图,操作时异步的,负责消费和生成未来值(futures);
- 高效地跨数千个加速器并行调度异构计算任务,并在专用互连上协调数据传输;
- 采用了新颖的异步分布式数据流设计,使控制平面能够在数据平面存在依赖性的情况下并行执行;
- 采用单控制器模型,从而更便于表达复杂的新型并行模式;
当利用PATHWAYS系统在2048个TPU上运行单程序多数据(SPMD)计算时,其性能表现与当前顶尖系统不相上下,加速器利用率近乎完美,达到了接近100%的水平。
另外,PATHWAYS系统通过16个节点的流水线运行Transformer模型,也能保持与SPMD场景相仿的高吞吐量,这表明该系统在处理复杂模型时同样表现出色。
1 引言
在过去的十年里,深度学习在图像理解到自然语言处理等多个领域取得了显著成就。机器学习(ML)领域迅猛发展,其特点在于ML模型、加速硬件以及将两者紧密相连的软件系统之间的协同进化。然而,这种协同进化也带来了一种风险,即系统可能过于专注于当前的工作负载,而难以预见未来的需求。PATHWAYS,一个为分布式机器学习构建的新系统。它的设计目标是满足我们认为的未来机器学习工作负载所需要的特定能力,但当前最先进的系统对这些能力的支持还很不足。
解读: 这里我们认为的未来机器学习工作负载,主要具备以下几个特点<来自jeff dean:Introducing Pathways: A next-generation AI architecture>:Introducing Pathways: A next-generation AI architecture (blog.google)
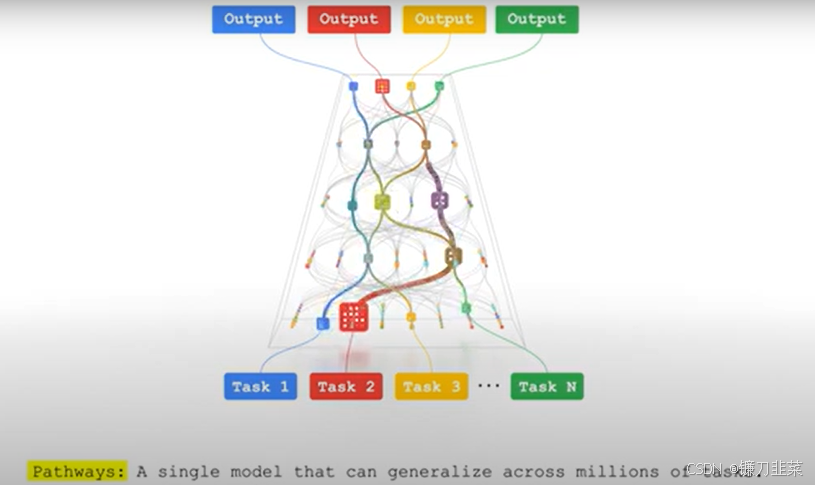
- 多任务:今天的模型通常被训练只做一件事,未来我们希望能够训练单个模型来执行数千或数百万件事情,该模型不仅可以处理许多单独的任务,还可以利用并结合其现有技能,以更快、更有效地学习新任务。
- 多模态:当前的模型通常一次只处理一种模式,而人脑依靠多种感官来感知世界,我们希望未来的模型同样能处理视觉、听觉和语言,这样模型更有洞察力,更少出错。甚至还可以处理抽象数据,发现复杂系统中的有用模式。
- 稀疏性:大多数现有模型都是“密集的”,即整个神经网络都会激活来完成任务,不论其难度如何。而人脑处理问题的方式不同,仅调用特定部分。我们可以构建一个“稀疏”激活的模型,仅在需要时激活网络的小路径,动态学习哪些部分擅长哪些任务。这种架构不仅更擅长多任务学习,而且更快、更节能,因为不需要为每项任务激活整个网络。
首先: 当今最先进的机器学习工作负载常采用SPMD模型,基于MPI理念,所有加速器同步执行相同的计算并通过AllReduce等集合通信进行同步。但SPMD在处理大型语言模型和MoE等模型时遇内存瓶颈,因此要跨加速器的细粒度控制流和异构计算。尽管系统设计师在基于MPI的系统上实现了这些模型,但MPI编程模型对用户和系统来说都过于局限。
其次: 随着新一代加速器的推出,机器学习集群变得日益异构化。为同质加速器资源池提供独占使用既昂贵又低效,因为单个程序难以保持所有加速器忙碌。这促使研究人员转向“多程序多数据”(MPMD)计算,将计算任务映射到较小的加速器资源池中,提供更大灵活性。为提高利用率,一些研究人员通过细粒度复用硬件实现了工作负载弹性和更高的容错能力。
最后: 研究人员正致力于标准化基础模型,这些模型在大规模数据上训练,可适应多个下游任务。训练和推理这些模型通过跨任务复用资源,提高集群利用率,并实现任务间状态共享。多个研究人员可同时使用相同的加速器微调基础模型的不同任务层,利用相关技术将不同任务的示例组合到单个批次中,提高加速器利用率。
2 设计动机
分布式机器学习系统的设计考量往往受到底层目标硬件加速器特性的深刻影响。本文则聚焦于分析当前分布式机器学习系统在设计与实施上的某些选择,这些选择如何成为支持大型、稀疏或不规则模型的障碍。
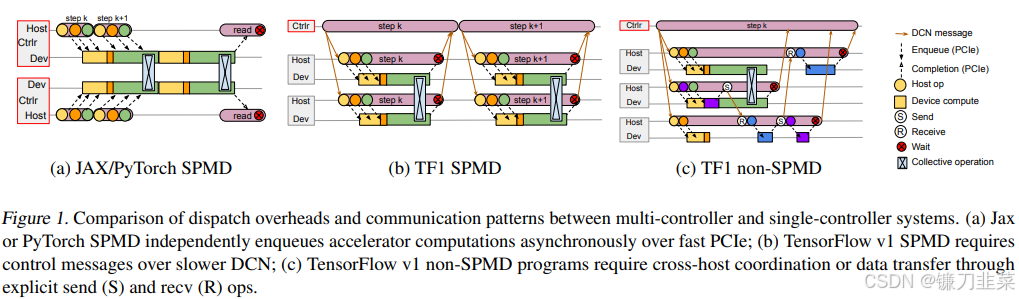
分布式机器学习系统通常采用多控制器架构来训练SPMD模型,在这种架构下,相同的客户端程序直接在所有主机上运行,并独占这些主机资源。典型的系统包括MPI、PyTorch、JAX以及TensorFlow的最新版本。该架构的主要优势在于分发加速器计算的低延迟(见图1a),因为每个主机上都有相同的用户程序,而分发只需要通过主机CPU和加速器设备之间PCIE链路进行通信。跨主机之间的所有其他通信仅通过使用专用互连(如NVLink和ICI)的集合操作进行,而不经过主机内存。
然而,这种架构与现代使用流水线或计算稀疏性的机器学习工作负载并不匹配。在多控制器系统中,任何超出标准集合操作的通信都需要用户自行实现协调原语。多控制器方法还通常假设对硬件资源的独占所有权。这不仅将提升资源利用率的责任转移给了用户,还使得资源虚拟化和多路复用等特性的设计变得复杂。
TensorFlow v1等单控制器系统提供了一个非常通用的分布式数据流模型,并且包括了图内控制流的优化。在TensorFlow中,Python客户端会构建一个计算图,并将其传递给运行时协调系统。这个系统会将图分割成多个子图,每个子图对应一个工作节点,并将子图的执行任务委派给各工作节点上的本地运行时环境,工作节点之间通过数据中心网络(DCN)传递消息来实现协调。尽管单控制器设计提供了灵活的编程模型和资源的虚拟化,但它也带来了实施上的挑战。
首先,虽然多控制器系统仅需要通过PCIe进行通信来分发加速计算(如图1a所示),但单控制器系统中的客户端则“距离更远”,分发延迟涉及到通过数据中心网络(DCN)进行通信,这通常比PCIe慢一个数量级(如图1b所示)。
其次,为了支持在共享加速器集群上运行MPMD程序(包括多个SPMD程序),运行时系统必须拥有某种机制来支持加速计算的批处理调度。在TPU的情况下,批处理调度尤为重要,因为它们是单线程的,并且只运行不可抢占的内核,所以如果通信计算没有以一致的顺序入队,系统将会出现死锁。即使对于能够执行并发计算的GPU或其他加速器,批处理调度也能使集合操作执行得更加高效。因此,单控制器系统需要一个分布式调度机制,以代表不同程序对入队的计算进行排序。
最后,设计用于现代机器学习工作负载的系统必须能够处理分布在数千个加速器上的计算,并首要支持分片表示和数据结构。例如,一个表示M路分片计算和N路分片计算的简单的数据流图需要M+N个节点和M×N条边,这很快就会变得难以管理。
TensorFlow v1的实现严重依赖集群独占规模不大的假设。这种过度专业化设计实际上使得TensorFlow难以应对当前或未来的机器学习工作负载。尽管TensorFlow可以通过发送和接收操作(如图1c所示)运行需要跨主机协调或数据传输的计算,但目的地主机侧的工作仅在传输完成后才会触发。比如有多个阶段的流水线模型,这种分发延迟会导致加速器利用率低下。虽然TensorFlow v1用户可以通过控制边(control edges)在单个程序内部(但效率不高)强制实现一致的批处理调度顺序,但像TensorFlow v1这样的单控制器系统中缺乏集中式调度器,使得无法确保跨程序计算之间的一致顺序。此外,TensorFlow还会物化完整的分片计算图,当分片数量达到数千时,这在图序列化和执行过程中都会引入大量开销,导致子计算之间产生数百万条图边。
PATHWAYS巧妙融合了单控制器框架的灵活性与多控制器的性能优势。我们采用单控制器模型,因为我们相信,在利用计算稀疏性和异质性,以及促进资源共享和虚拟化的集群管理系统方面,单控制器相较于多控制器更友好。我们的设计与旧式单控制器机器学习系统不同,它采用异步分发机制以达到多控制器系统的性能水平,支持一流能力的集中式资源管理和调度,专为SPMD(单程序多数据)加速器计算的批处理而设计,并采用分片数据流系统以实现高效的协调。
3 编程模型
JAX用户可以通过装饰器明确地将标准Python代码封装起来,以指示哪些片段应被编译成(潜在的SPMD)XLA计算。这些XLA计算通常具有已知的输入和输出类型及形状、有界循环以及极少的(或没有)条件语句,这使得提前估算计算所需的资源变得可行。我们将这些已知资源需求的计算称为“编译函数”。在PATHWAYS程序中,每个这样的函数都映射到一个单独的(分片)计算节点上。

PATHWAYS用户可以根据需要请求一组“虚拟设备”,并可选择性地设定设备类型、位置或互连拓扑的约束条件,然后能够在这些设备上部署特定的编译函数(如图2所示)。系统将自动处理依赖计算之间的所有数据移动和重新分片。
默认情况下,我们将每个编译函数转换为一个独立的PATHWAYS程序,其中仅包含一个(分片)计算。这意味着,如果用户想要连续运行多个函数,则需要对每个函数进行单独的Python调用和从客户端到协调器的远程过程调用(RPC)。因此,我们还实现了一个新的程序追踪器(如图2所示),调用多个编译函数。该追踪器会生成一个单一的PATHWAYS程序,其中每个编译函数在数据流图中由一个计算节点表示。
JAX支持追踪代码转换的理念与我们想要探索的研究方向高度契合。例如,JAX有一个名为FLAX(Heek et al., 2020)的配套库,用于表达分层DNN模型,而我们编写了一个库,该库能够自动将FLAX模型转换为流水线的PATHWAYS程序。此外,JAX支持将“按示例”的Python函数向量化,生成高效的批处理代码,这样的转换是探索新型数据依赖向量化控制流的基础。
4 系统架构
4.1 资源管理器
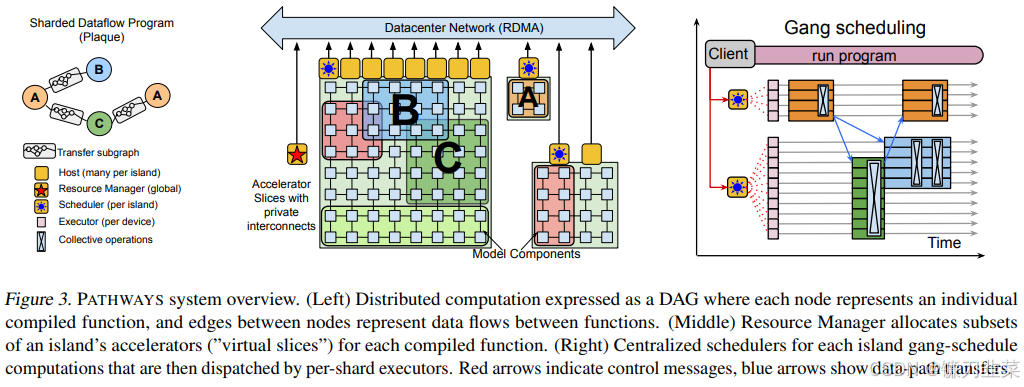
PATHWAYS后端由一组加速器组成,这些加速器被紧密耦合成多个island,并通过DCN(数据中心网络)相互连接(如图3所示)。PATHWAYS设有一个“资源管理器”,负责跨所有island对设备进行集中管理。客户端可以请求具有特定二维或三维网格形状的“虚拟分片”,以适应其通信模式。每个虚拟分片包含“虚拟设备”,允许客户端表达计算如何在网格上布局。资源管理器会动态地为虚拟设备分配物理设备,以满足所需的互连拓扑、内存容量等要求。
我们初步实现了一种简单的启发式方法,尝试通过将所有计算分散到所有可用设备上来静态平衡负载,并保持虚拟设备与物理设备之间的一对一映射。如果未来的工作负载需要,我们可以采用更复杂的分配算法,例如考虑所有客户端计算的资源需求和系统的当前状态,以近似最优地将物理设备分配给计算。
PATHWAYS允许动态地添加和移除后端计算资源,资源管理器会跟踪可用设备。我们单控制器设计所实现的虚拟设备与物理设备之间的间接层,将在未来支持透明挂起/恢复和迁移等功能,即在不需要用户程序配合的情况下,可以临时回收或重新分配客户程序的虚拟设备。
4.2 客户端
当用户希望运行一个追踪程序时,它会调用PATHWAYS客户端库。该库首先为任何尚未运行的计算分配虚拟设备,并将这些计算注册到资源管理器中,从而触发服务器在后台编译这些计算。随后,客户端为程序构建一个与设备位置无关的PATHWAYS中间表示(IR),该表示采用自定义的MLIR语言进行表达。
通过一系列标准的编译器传递过程,IR逐步“降级”为包含物理设备位置的低级表示。这个低级程序会考虑物理设备之间的网络连接,并包含将输出从源计算分片传输到目标分片位置的操作,包括在需要数据交换时进行的分散和聚集操作。在常见的虚拟设备位置不变的情况下,重复运行低级程序是高效的,如果资源管理器更改了虚拟设备与物理设备之间的映射,则可以重新对程序进行降级。
在传统单控制器架构中,客户端由于需要协调数千个独立计算以及分布在成千上万加速器上的各个计算分片所对应的数据缓冲区,很容易成为系统性能的瓶颈。PATHWAYS客户端使用分片缓冲区抽象来表示可能分布在多个设备上的逻辑缓冲区。这种抽象有助于客户端通过在逻辑缓冲区的粒度上分摊记账任务(包括引用计数)的成本来扩展。
4.3 协调器
PATHWAYS 依赖 PLAQUE进行跨主机协调。PLAQUE 是 Google 内部的分片数据流系统,这些服务需要高扇出或高扇入通信,并且对可扩展性和延迟都有严格要求。PATHWAYS 的低级中间表示(IR)直接转换为 PLAQUE 程序,以数据流图的形式表示。PATHWAYS 对协调基础设施有严格的要求,而 PLAQUE 都能满足这些要求。
首先,用于描述PATHWAYS中间表示(IR)的表示方法必须为每个分片计算包含一个单独的节点,以确保跨多个分片的计算能够得到紧凑的表示。当两个计算A和B各自包含N个分片并顺序执行时,数据流图应简洁地表示为:参数 → 计算(A) → 计算(B) → 结果,这一表示与N的具体值无关。PLAQUE运行时系统中,每个节点会生成带有目标分片标签的输出数据元组,从而在进行数据并行处理时,N个数据元组将按顺序流动,确保每个相邻的IR节点对之间正确传递数据。
PATHWAYS系统的协调运行时必须支持在分片边缘进行稀疏数据交换,允许消息在动态选定的分片子集间发送。这一过程利用标准的进度跟踪技术来确保所有分片的消息都已接收完毕。这种高效的稀疏通信机制是避免数据中心网络(DCN)成为加速器上数据依赖控制流的瓶颈的关键,也是PATHWAYS致力于提供的能力之一。
协调底层架构用于发送DCN消息,这些消息对于传递调度信息和数据句柄至关重要(参见图4),因此必须以低延迟发送关键消息,并在需要高吞吐量时,将目标相同的主机的消息进行批量处理。
此外,PATHWAYS也可以利用一个可扩展的通用数据流引擎来处理DCN通信,这不仅方便了协调底层的实现,也为后台维护任务提供了便利,如分发配置信息、监控程序、清理资源、在失败时传递错误等。
我们相信,完全有可能使用其他分布式框架,比如#Ray#(来重新实现PATHWAYS的设计,以构建低级协调框架)。在这种实现方式中,PATHWAYS的执行器和调度器将由长期运行的Ray actor替代,这些actor将在Ray集群调度的基础上实现PATHWAYS的调度机制,执行器也可以利用PyTorch进行GPU计算和集体操作。为了达到与现有系统相当的性能,可能需要增加一些功能,例如Ray目前缺乏的HBM对象存储,或者在GPU互连上高效传输远程对象的机制。
4.4 组调度动态分发
在一组共享的加速器上支持单程序多数据(SPMD)计算的一个要求是能够支持高效的组调度。PATHWAYS 运行时包括每个island上的一个集中式调度器,该调度器会一致地对island上的所有计算进行排序。当 PATHWAYS 将程序加入执行队列时,PLAQUE 数据流程序负责:(一)在每个加速器上加入本地编译函数的执行队列,以缓冲期货(buffer futures)作为输入;(二)将函数执行输出的缓冲期货通过网络发送到远程加速器;(三)与调度器通信,以确定岛上运行的所有程序中函数执行的一致顺序。调度器必须实现以毫秒为时间尺度的加速器分配策略。我们当前的实现只是简单地以先进先出(FIFO)的顺序加入工作,但更复杂的调度器可能会根据估计的执行时间对计算进行重新排序。
4.5 异步并行分发
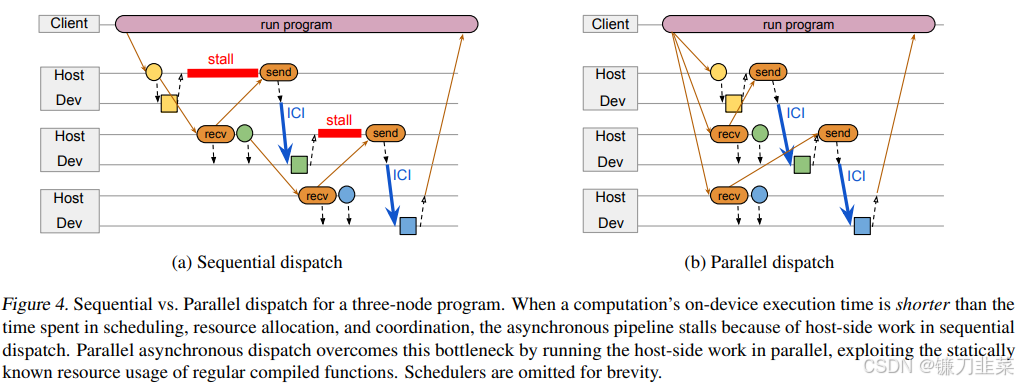
在加速器上运行计算时,系统可以利用异步API将计算与协调重叠进行。以图4a中的三节点图为例,其中正方形代表在分别连接到主机A、B、C的加速器上运行的三个节点A、B、C。所有节点计算都是常规的编译函数。主机A将节点A加入队列,接收A的输出期货(future),并将其传输给主机B。主机B分配B的输入,将输入缓冲区地址传输给主机A,并执行大部分准备工作以启动节点B的函数。当节点A完成时,其输出通过加速器互连直接发送到节点B的输入缓冲区,然后主机B启动节点B。从一个节点完成到下一个节点开始之间的延迟可以缩短到仅略高于数据传输时间。
当前节点的前置节点计算时间超过调度、资源分配和主机间协调所需时间时,上述设计效果良好。然而,如果计算时间太短(如图中所示),异步流水线将停滞,主机端的工作成为执行整个计算序列的关键瓶颈。鉴于所有编译函数都是常规的,实际上可以在前置计算甚至加入队列之前就计算出后继节点的输入形状。
因此,我们引入了一种新颖的并行异步分发设计,如图4b所示,该设计利用常规编译函数静态已知的资源使用情况,以并行方式执行计算节点的大部分主机端工作,而不是将节点的工作串行化,等待其前置节点加入队列后再进行。由于只有在函数常规时才能并行调度工作,因此PATHWAYS将并行调度视为一种优化手段,并在节点的资源需求直到前置计算完成后才可知(例如,由于数据依赖的控制流)时,回退到传统模型。当可以静态调度计算的一个子图时,程序会向调度器发送一条消息(描述整个子图),调度器能够连续执行子图中所有活动分片。使用单条消息旨在最小化网络流量,但并不要求调度器实际上将子图的所有分片作为一批次加入队列:计算仍然可以与其他并发执行的程序提交的计算交错进行。
4.6 数据管理
每个主机都管理一个分片对象存储,该存储类似于Ray的对象存储,但进行了扩展,以跟踪每个分片中加速器HBM中持有的缓冲区。客户端程序可以持有远程主机或加速器内存中对象的引用,客户端和服务器使用不透明的句柄来引用这些对象,以便系统在需要时能够迁移它们。中间程序值也保存在对象存储中,例如,当系统正在等待在加速器之间传输这些值,或将其传递给后续计算时。这些对象会被标记上所有权标签,以便在程序或客户端失败时能够进行垃圾回收。如果由于其他计算的缓冲区暂时占用了HBM而无法分配内存,我们可以使用简单的背压机制来暂停计算。
6 总结
PATHWAYS在单租户SPMD模型上的性能与最先进水平相媲美,并确保了与多控制器JAX的兼容性。PATHWAYS颠覆了JAX程序的执行模式,将用户代码重新拉回到单控制器模型中,并在客户端与加速器之间插入了一个集中式的资源管理和调度框架。这种单控制器编程模型使用户能够更简便地访问更为丰富的计算模式。
资源管理和调度层则重新引入了集群管理策略,包括多租户共享、虚拟化和弹性扩展等,这些策略均根据机器学习工作负载和加速器的需求量身定制。
我们的微基准测试展示了并发客户端工作负载的交错执行和高效的流水线作业,有力地证明了我们所构建的系统机制既快速又灵活,为探索和利用这些新策略奠定了坚实的基础。
解读: JAX(Just-in-Time Accelerated XLA)是一个由Google开发的机器学习库。在标准的JAX程序中,计算图被发送到加速器(如GPU或TPU)上执行,以利用这些硬件的并行计算能力。这种执行模式通常涉及到计算图的优化、分割和分发到不同的硬件设备上。
在传统的分布式或多设备编程模型中,用户代码可能需要显式地处理多个计算节点或设备之间的通信和同步。这增加了编程的复杂性,特别是当处理大型集群或异构计算环境时。PATHWAYS简化了这一过程,在单控制器模型中,用户只需要编写针对单个逻辑单元的代码,而资源管理和调度等复杂任务则由框架内部的中央控制器来处理。这意味着用户不需要直接关心计算资源在物理上的分布,可以更加专注于算法和逻辑的实现。



















 1456
1456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











