









 本文介绍了一种基于深度学习的DenseV-Network算法,用于腹部CT图像的多器官自动分割。该算法在90个病例的交叉验证中,相比于基于MALF、深度学习的VoxResNet和统计模型,实现了对8个器官(包括胰腺、胃肠道、肝、胆囊等)更高的分割精度,特别是在小器官如胆囊和食道的分割上。研究还发现,网络的密集连接和多尺度V-Network结构对提高分割性能至关重要。此方法有望为内窥镜导航提供支持。
本文介绍了一种基于深度学习的DenseV-Network算法,用于腹部CT图像的多器官自动分割。该算法在90个病例的交叉验证中,相比于基于MALF、深度学习的VoxResNet和统计模型,实现了对8个器官(包括胰腺、胃肠道、肝、胆囊等)更高的分割精度,特别是在小器官如胆囊和食道的分割上。研究还发现,网络的密集连接和多尺度V-Network结构对提高分割性能至关重要。此方法有望为内窥镜导航提供支持。
Automatic Multi-Organ Segmentation on Abdominal CT With Dense V-Networks

Abstract
腹部解剖在CT图像上的自动分割可以支持诊断、治疗计划和治疗提供流程,分割方法基于统计模型和多图谱标签融合(MALF)需要对象间图像配准,这对腹部图像来说是具有挑战性的,但是对于大多数腹部器官,没有配准的替代方法还没有达到更高的准确率。我们提出了一种基于深度学习的无配准分割算法,对内窥镜胰腺和胆道手术中与诊断相关的8个器官,包括胰腺、胃肠道(食道、胃和十二指肠)以及周围器官(肝、脾、左肾和胆囊)进行分割。在一个包含90个对象的多中心数据集的交叉验证中,我们直接比较了提出的方法和现有的深度学习和MARF方法的分割精度。对于所有的器官,我们提出的方法产生了显著更高的Dice分数,而对于大多数器官,平均绝对距离明显更低,包括胰腺的Dice分数分别为0.78和0.71、0.74和0.74,胃的Dice分数分别为0.90和0.85、0.87和0.83,食道的Dice分数分别为0.76和0.68、0.69和0.66。我们的结论是,基于深度学习的分割方法代表了一种用于多器官腹部CT分割的免配准方法,其准确率可以超过现有方法,为胃肠道内窥镜检查中的图像导航提供了潜在的支持。
Index Terms
腹部CT、分割、深度学习、胰腺、胃肠道、胃、十二指肠、食管、肝、脾、肾、胆囊。
Introduction
腹部图像中器官的成像可以支持多个领域的临床工作流程,包括诊断干预、治疗计划和治疗交付。器官分割是计算机辅助诊断和生物标志物测量系统中至关重要的一步[1]。治疗量和器官风险的划分也是计划放射治疗的核心[2]。更广泛地说,基于分割的特定于患者的解剖模型可以通过术中图像引导系统支持手术计划和交付[3]。
在内窥镜胰胆手术中,内窥镜被口头插入,并通过胃肠道导航到胃或十二指肠壁上的特定位置,以便进行胰胆成像和干预。由于内窥镜视野小,缺乏视觉定位提示,这项导航任务很有挑战性,特别是对于内窥镜新手来说[4]。显示配准解剖模型的图像引导将提供位于内窥镜视野之外或在内窥镜图像上具有挑战性的定向和目标提示。为了支持定位和导航,需要分割多个器官:胰腺、胃肠器官(食道、胃和十二指肠)以及附近用作导航标志的器官(肝、胆囊、脾和左肾)。
手工分割3D腹部图像是劳动密集型的,对于大多数临床工作流程来说是不切实际的,这激发了(半)自动分割工具[2]。由于临床流行,对这些工具的研究集中在计算机断层扫描(CT)和三种方法上:统计模型(SM)[5]、[6]、多图谱标记融合(MALF)[6]-[10]和免配准方法[11]-[14]。SM和MARF在I-A.1节中进行了更详细的回顾,它们依赖于在不同受试者的图像之间建立解剖学对应,由于器官形状和外观以及软组织变形的高度受试者之间的变异性,这项任务仍然具有挑战性[15]。免配准方法用配准挑战换来了构建变异和变形不变特征(“手动调整”或学习)的挑战,这些特征表征了未配准训练数据集中的解剖学特征。尽管这种方法声称具有优势,但与基于配准的方法相比,免配准方法实现的多器官分割的精确度较低[16]。
更复杂的免配准方法,包括深度完全卷积网络(FCN),有望提高分割精度[17]。I-A.2节详细讨论的FCNs特别适合于多器官腹部分割,因为它们既不需要明确的解剖学对应关系,也不需要手动调整图像特征。在多器官腹部分割中,它们已经单独使用[18],或与预处理或后处理一起使用,如Level Set[19]和MARF[20],显示了它们的潜在价值。然而,对于大多数器官来说,这些管道仍然没有达到比最精确的基于配准的方法更高的精确度[16]。
本文介绍了Dense V-Network FCN(DenseVNet)及其在腹部CT多器官分割中的应用,取得了比现有的三种方法更高的准确率。这项工作的贡献有四个方面:
- 提出了DenseVNet分割网络,该网络通过高效内存丢弃和特征重用来实现高分辨率激活图。
- 提出了一种分批空间丢弃方案,降低了丢弃的内存和计算开销。
- 使用交叉验证对来自多个中心的90多个手动分割图像进行交叉验证,评估DenseVNet用于腹部CT多器官分割的准确性。结果表明,与最先进的MALF方法和两个现有的FCN相比,可以实现更高的分割精度。
- DenseNet中对准确性至关重要的部分通过比较网络变体的准确性来确定。
这建立在我们的前期工作[21]的基础上,改进了网络架构,增加了数据集,并与其他算法和网络变体进行了更广泛的比较。
Related work
常用的多器官分割方法
统计模型[5]、[6]涉及共同配准训练数据集中的图像以估计解剖对应,构建训练数据中相应解剖的形状[22]和/或外观[23]的分布的统计模型,以及将所得到的模型拟合到新图像以生成分割。多图集标签融合方法[6]-[10]将训练数据集中的图像配准到每个新图像,并组合传播的参考分割以生成新的分割。统计模型和多图谱方法受到图像配准精度的限制。这项登记虽然被广泛研究,但仍然具有挑战性[15]。腹部器官的大小、形状、外观和相对位置因自然变异性、疾病状态和以前的治疗而在患者之间和由于软组织变形而在每个患者中有很大差异。为了避免挑战配准,免配准方法在未配准的图像上训练体素分类器。一些方法依赖于手工制作的特定于器官的图像特征[11],[12],但许多最近的方法涉及到对选定的(但通常与器官无关的)图像特征训练分类器[13],[14]。尽管存在配准挑战,对于大多数器官,MALF已经产生了比免配准方法更准确的多器官腹部CT分割[16]。然而,最近免配准方法的进步可能会改变这一点。
用于分割的FCNs
FCN是具有可训练参数的简单图像到图像函数的组合,包括与线性核的卷积和体素非线性。对于需要像分割这样的图像输出的基于深度学习的任务,FCN是一种有效的架构。
最近,FCNs已被应用于医学图像分析中的体积图像分割[18]、[19]、[24]-[26],其中此类图像是常见的。体积图像的分割面临着特殊的挑战,这主要是因为需要在内存受限的情况下处理大体积图像。
限制内存使用的一种策略是处理较小的图像:较大图像的小patch或较低分辨率的图像。图像patch分割考虑各种patch类型-单个2D切片、相邻2D切片的切片或更小的裁剪区域-以及方向-单轴对齐切片、来自多个轴的多个切片或倾斜切片。这些方法提高了存储效率,但损失了空间上下文。相比之下,Milletari等人[25]和圣伊塞克等人[24]通过按顺序对图像进行下采样来使用整个图像的3D表示,以便大多数图像特征仅在低分辨率下表示。我们以前的工作[21]通过使用密集块[27]来使用具有较少但较高分辨率的特征的3D表示,其中每一层的输入包括所有先前堆栈层的输出,以补偿使用较少特征的情况。
另一种限制内存使用的策略是限制网络深度。但是,这会影响FCN感受场(即影响每个输出体素的图像区域的大小),该场随网络深度线性增长。较大的卷积核通过增加线性增长率来缓解这一问题;但是,这可能会导致非常高的参数计数(在3D中增长为内核大小的立方体)。如上所述的顺序下采样也减轻了这种影响,因为感受野随着下采样级数呈指数增长。膨胀卷积[28],在我们以前的工作[21]中使用,取而代之的是使用大而稀疏的核来给出具有很少参数的指数感受场大小。
多器官分割带来了额外的挑战。首先,必须通过网络传播更多信息,这会加剧上述存储挑战。不同器官损失的相对权重(高容量不平衡)可能会对收敛和最终误差产生不可预测的影响;使用Dice系数很常见,但仍不能很好地描述。在特定器官之间施加形状[29]和拓扑[30]约束也仍然具有挑战性。尽管有这些挑战,深度学习已经被单独用于腹部多器官CT分割[18],[31],或者作为更大的分割管道的一部分[19],[20]。周等人[18]在2D切片上对19个腹部器官在轴位、矢状位和冠状位进行分割,并使用多数投票标记融合技术将结果合并。Roth et al.[31]使用基于3D UNET的两级分层管道分割7个器官[24]。Hu等人[19]使用3D FCN分割4个器官,以生成器官概率图作为基于水平集的分割的特征。Larsson等人[20]使用MARF识别每个器官的感兴趣区域,并使用具有手动调整的输入特征的3D FCN来完成分割。在最近的一次分割挑战中,与基于配准的方法相比[16],这些方法在胆囊方面的准确度大大提高(>2%的Dice得分提高),在肝脏、左肾、右肾上腺和主动脉方面达到平价(在2%以内),但对于胰腺、胃肠道(食道、胃)和其他器官(脾、右肾、下腔静脉、门静脉/脾静脉和左肾上腺)的准确率较低。
Data
采用90幅腹部CT图像和相应的脾、左肾、胆囊、食管、肝、胃、胰腺和十二指肠的参考标准分割进行研究。CT图像和部分分割来自两个公开可用的数据集:43名受试者来自癌症影像档案馆胰腺CT数据集[26]、[32]、[33],其中47名受试者来自“超越颅腔”(BTCV)分割挑战[16],其中除十二指肠外的所有器官都进行了分割。其余的参考标准分割在我们的中心进行。已完成的fenge和主题标识符已公开提供(doi:http://doi.org/10.5281/zenodo.1169361).
Image Data
胰腺CT数据集包括美国国立卫生研究院临床中心从肾切除前健康的肾脏捐赠者或既没有主要腹部病变也没有胰腺癌病变的患者那里获得的腹部CT[33]。BTCV数据集包括V Anderbilt大学医学中心从转移性肝癌患者或术后腹疝患者获取的腹部CT[15]。图像的体素大小在前后(AP)和左右(LR)轴上为0.6-0.9 mm,在下-上(IS)轴为0.5-5.0 mm。图像被手动横向裁剪到肋骨和腹腔,范围在肝或脾的上方和肝或肾的下方,视野范围为172-318 mm AP,246-367 mm LR和138-283 mm IS。
参考标准分割
在可用的情况下使用来自胰腺CT和BTCV数据集的分割。成像研究员(例如)在具有8年胃肠CT和MRI图像解释经验(例如)的董事会认证放射科医师的监督下,在两个数据集上交互式分割未分割的器官并编辑分割的器官以确保一致的分割协议,使用Matlab 2015b和ITK-SNAP 3.2(http://itksnap.com).
Methods
本研究通过两个实验将我们提出的算法与多种自动分割算法进行了比较。首先,为了评估我们的算法对分割精度的改善程度,我们比较了下面详细描述的三种不同的算法:基于多图谱标签融合的DEDS+JLF[34],[35],基于深度学习的VoxResNet[36],以及提出的基于深度学习的DenseVNet。其次,为了阐明促成这些改进的体系结构因素,我们比较了所提出的DenseVNet体系结构的变体。
一种改进的算法:Dense V-Network 分割
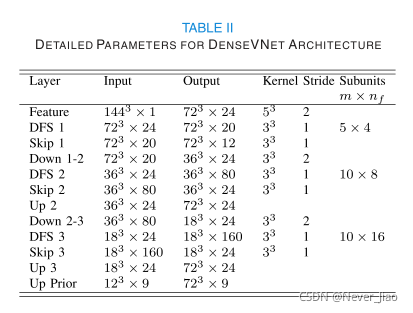
所提出的分割方法使用基于如图1所示组成的卷积单元的全卷积神经网络[37]。==体系结构设计可以根据下面描述的5个关键特征来理解:批量空间丢弃、密集的特征堆栈、VNet下采样和上采样、膨胀的卷积和明确的空间先验。==为清晰和精确起见,每一项都将从概念上进行描述,并在数学上加以具体说明。在线多媒体选项卡中提供的补充材料对网络的实施提供了指导。
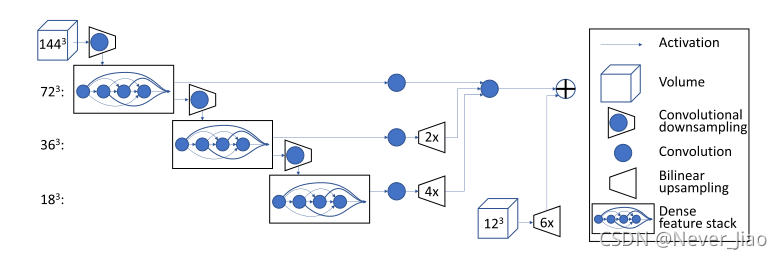
图1.DenseVNet网络体系结构。首先,使用stride卷积计算723个特征图。其次,密集特征堆栈和stride卷积的级联生成三种分辨率的激活图。第三,在减少特征数量的每个分辨率上应用卷积单元。第四,在双线性上采样回到723之后,将映射连接起来,并且最终卷积生成似然对数。最后,在生成分割日志之前,将这些添加到上采样的空间中。各个组件的参数给出了整型表II。
每个卷积单元由三个函数组成:(1)具有学习核的3D卷积,(2)促进稳健梯度传播的批量归一化[38](3)表示非线性函数的校正线性单元(ReLU)非线性[39]。具体而言,表示卷积单元,
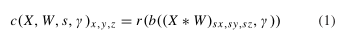
其中W为卷积核;批量归一化b(X,γ)将每个通道的平均值转换为0,将方差转换为每个通道的学习尺度参数γ,校正后的线性单位r(X)=max(0,X)会导致非线性。
为了提高计算和存储效率,我们引入了新的批量空间丢弃算法。在规则空间丢弃[40]中,为了使网络正规化,随机信道以独立的指定概率被丢弃(即设置为零),
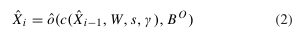
其中,ˆo(X,BO)将由随机二进制掩码BO的信道设置为零,并且ˆXi−1=ˆo(Xi−1,BI)是使用MaskBI退出后的前一单元的输出。标准实现会计算并存储不会影响后续层的丢弃激活。我们提出的批量空间丢弃通过修改卷积核而不是激活图来避免计算这些激活图,
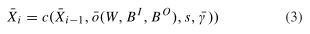
其中o(W,BI,BO)是没有BI和BO mask的输入输出通道的新内核,Xi−1是批量空间丢弃后上一个单元的输出,γ是未丢弃通道的比例参数。请注意,Xi与 ˆXi的未丢弃通道相同,但不计算或存储丢弃的通道,如果对后续卷积的内核进行类似修改,则后续卷积不受影响。为了实现效率的提高,进一步进行了两个改变。首先,为每个小批次中的所有图像丢弃相同的通道,以便可以对整个小批次使用相同的卷积内核。其次,更改丢弃通道的分布以限制最大内存使用量。在空间丢弃情况下,n个通道保持中断的概率分布为二项分布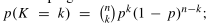
,虽然期望值[K=k]=pn,但最大值(对应于最大内存使用量)却不是。相反,所提出的分批空间丢弃使用相依伯努利分布来丢弃信道,从而保持固定数量的信道Pn。分段推理可以通过按nf/nfp缩放卷积单元输出来使用所有特征;这需要每个受试者比训练更多的内存,因为生成了所有的系数图。或者,可以通过使用丢弃来推断多个分割样本并组合它们来使用蒙特卡洛推断41。下面的实验对这两种方法都进行了评估。NiftyNet平台提供了批量空间丢弃的实现。
密集特征栈,改编自Huang等人[27]定义的密集块,是复合函数序列,其中每个函数的输入是所有前面函数的串联输出。与Huang的稠密块不同,我们的复合函数使用我们的批量空间丢弃进行正则化,并且不使用1×1的瓶颈层。具体地说,一个m层密集特征堆栈fm(X0)=[X0;X1;…;Xm]的输出,
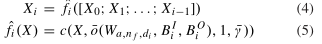
其中[A;B]表示通道级联;**Wa,nf,di是一个a×a×a卷积核(a=3),具有nf输出通道(高、中、低分辨率密集特征堆栈的输出通道分别为4、8和16)**和扩张率di(d2=3,d3=9,di∉{2,3}=1);BiI=[B0O;B1O;…;Bi-1O]选择所有先前计算的通道,B0O选择来自X0的所有通道,对其他的BiO进行随机采样,以便选择(pnf)上取整通道(p=0.5)。这种结构有几个优点。首先,与残差网络[42]一样,由于最终输出通道包括输入,因此特征栈固有地对身份函数进行编码。其次,它们组合了单个网络内的多个网络深度[43],允许梯度在网络中的有效传播(每个核权重位于深度为1的浅子图中)和复杂函数的表示(每个核权重位于深度为2的多个更深的子图中)。最后,当内存限制激活映射的数量时,来自较早层的信息只在内存中存储一次,但由较晚的层访问。存储器效率高的密集块[44]可以实现O(M)的存储器使用率,其中仔细实现特征级联避免存储特征图的多个副本。批量空间丢弃的改进可以与内存效率高的密集块的改进相结合,只需为计算的激活图数量分配共享内存存储,这对于依赖的Bernoulli分布是固定的。

V-Network体系结构包括下采样子网络和上采样子网络,通过跳过连接将更高分辨率的信息传播到最终分割。以前的V-Network[24]、[25]通常使用浅stride卷积下采样单元,然后是在每个分辨率内具有相加或级联跳跃连接的浅transpose卷积上采样单元。DenseVNet在几个方面不同:下采样子网络是通过下采样stride卷积连接的三个密集特征堆栈的序列;每个跳过连接是对应的密集特征堆栈输出的单个卷积,并且上采样网络包括到最终分割分辨率的双线性上采样。密集特征堆栈的存储效率和批量空间丢弃使更深层次的网络具有更高的分辨率,这有利于分割更小的结构。跳过连接到分割分辨率(723)的双线性上采样限制了转置卷积引起的伪影[45]。V-Network生成具有9个类别的Logit标签预测L。
膨胀卷积使用稀疏的卷积核来表示具有较大接受范围但较少可训练参数的函数。具体地说,扩张核Wa,k,d是一个(d(a−1)+1)3核,每一维都有一个可训练参数,其它地方为0。对于FCN的第i个卷积层,相对分辨率为πi j=1 1/sj,感受野大小递归表示为ri=ri−1+di(ai−1)π i−1 j=1 sj,其中di,si和ai是第一层的膨胀率、步长和核大小(膨胀前)。由于分辨率和感受野大小都取决于si,因此顺序下采样可以产生早期层的局部高分辨率特征,也可以产生全局低分辨率特征。相反,通过在si=1的情况下以二次指数增加di,膨胀卷积可以在早期层产生具有指数增长的感受野的高分辨率特征。这允许在后面的层中计算这些特征的更复杂的函数。低层的高分辨率大感受野特征可以帮助分割小结构(如食道),这些小结构的位置可以从附近的大结构中推断出来。
最后,我们使用了在我们以前的工作中引入的显式空间先验[21]。医学图像通常是在具有相对一致的器官位置和方向的标准解剖对齐视图中获取的,这激发了空间分割先验。由于卷积的边界效应或通过提供图像坐标作为输入通道,空间先验可以被隐式编码[46]。我们以前的工作[21]引入了一个显式的空间先验。**空间先验P是可训练参数的低分辨率3D图,其被双线性地提前上采样到分割分辨率,并被添加到V-Network的输出(即L’=u§+L)。**概念上,这可以将类别标签L在给定图像I的体素x处的后验对数概率L=logp(L|x,i)表示为由V-Network生成的对数似然L=logp(i|x,L)和由空间先验生成的先前对数概率u§=logp(L|x)之和。然而,空间先验参数被训练为端到端基于梯度的优化的一部分,并且可能不代表真实的先验概率。
实施详情
损失函数是L2正则化损失的加权和,该L2正则化损失具有标签平滑的概率Dice分数[47],该概率Dice分数是在每个小批次中的对象间平均的每个器官的概率Dice分数,
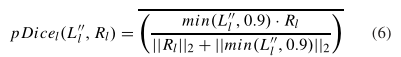
其中向量L’‘i=softmax(L’)i和Ri分别是算法对每个器官l中每个对象的概率分割和二进制参考标准分割。为了进一步缓解极端的等级失衡(例如,食道平均占图像的0.09%,肝脏平均为11.7%),Dice得分铰链损失严重惩罚Dice得分低于0.01和0.10,分别在25次和100次迭代热身后引入。迭代i的损失函数是
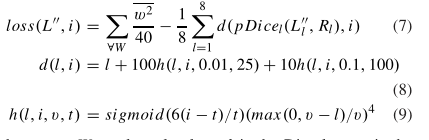
其中,w∈W是核大小,l是Dice loss,v是铰链损耗阈值,t是迭代延迟。
使用epsilon=0.001和mini-batch size为10的ADAM优化器对网络进行5,000次迭代(即625个历元)的训练。使用Titan X Pascal或P100 GPU(NVIDIA Corporation,Los Alamitos,CA)对网络的每个实例进行训练花费了大约6个小时。NiftyNet平台模型库(http://niftynet.io/model_zoo).)提供了训练有素的DenseVNet网络的TensorFlow实现。
剪切的感兴趣区域横向范围为209-471个体素(172-367 mm),在IS轴上为32-450个体素(138-283 mm),重新采样为1443个体素体积。在训练过程中,为了增加数据,应用了仿射扰动,在每个维度上产生了0%到10%的偏斜子区域。对于算法比较中使用的基线DenseVNet,我们使用蒙特卡罗推理,使用30723个分割样本的模式(启发式地先验选择),每幅图像大约花费8-15秒。在后处理中,在Matlab中使用曲率流平滑[48]将723个分割标签重新采样到原始图像分辨率下的原始裁剪区域,迭代2次(视觉上先验地选择以避免量化伪影)。然后,对于每个器官,将包括分割的器官体积>10%(随机选择,先验的)的所有连通分量的并集作为最终掩码。
评价指标和统计方法
我们对90名受试者进行了9次交叉验证,比较了分割算法的准确性。对于每个折叠中的每个测试图像,我们使用三个度量将每个器官分割与参考标准分割进行比较:
- Dice coefficient – 2|A∩B|/(|A|+ |B|)
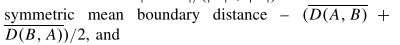
- 对称95%Hausdorff距离-(P95(D(A,B))+P95(D(B,A)/2
其中A和B是算法和参考分割,D(A,B)是从边界像素A,ΩA到ΩB中最近的边界像素的距离集合(即D(A,B)={min(x∈ΩB) ||x−y|| (y∈ΩA)}),并且P95(D)是D的第95个百分位数。Dice系数测量分割之间的相对体积重叠。平均边界和95%的Hausdorff距离反映了分割边界之间的一致性,后者对局部不一致更为敏感。
在每一次分析中,我们使用相关数据的符号测试[49],将提出的算法的精度与每个比较方法进行比较[49],这对我们的数据中观察到的精度差异的倾斜分布不敏感,并解释了由于共享训练集而导致的每一折内的值之间的相关性。采用本杰米尼-霍奇伯格错误发现率多重比较校正(α=0.0 5)进行配对检验。该校正分别针对初级分析比较算法和二级分析比较体系结构变体执行。在一些受试者中,有一个或多个器官由于之前的手术而没有出现在图像中;这些器官(7个胆囊,1个左肾和1个食道)被排除在上面的综合描述性统计和统计比较之外,因为在这种情况下使用的测量方法没有意义。在这些情况下,我们报告了这些器官的分割体积(理想情况下为0)(补充材料表II,可在在线多媒体选项卡中找到)。
主要分析:算法比较
我们将我们的算法与现有的两种算法的分割精度进行了比较:基于深度学习的VoxResNet方法[36]和基于MALF的Does+JLF方法[34],[35],如下所述。
比较算法1:Deep-Learning-Based VNet
为了评估我们的具体体系结构,我们将其与用于3D图像分割的基准V-Network体系结构VNet[25]进行了比较,该体系结构已被广泛使用和修改,并且具有公开可用的实现(https://github.com/faustomilletari/VNet).。因为原始VNet是为二进制分割而设计的,所以我们将损耗梯度∂Dice/∂L’‘lxyz修改为支持多个标记和缺失器官,从−1l(2R1,xyzU1−4L1,xyz I1)/U12分别修改为−(2Rl, xyzU1−4L’‘l,xyz Il)/(Ul2+epsilon),其中Ul和Il是RL和argmaxi(L’'i)=l的并集和交集的体积。epsilon=0.01是当缺少器官时数值稳定性的常数。VNet使用参数校正的线性单元激活功能,并且不使用批量归一化。下采样子网络包括具有用于下采样的stride卷积的5个分辨率的残差单元(即,串联加回到输入的一个或多个卷积单元)。上采样子网络将使用转置卷积进行上采样的特征与直接来自下采样子网络的“跳过”特征级联,并应用残差单元。我们使用Caffe和参考实现的改编来训练VNet,并应用了与DenseVNet相同的后处理。
比较算法2:Deep-Learning-Based VoxResNet
为了进一步评估我们的特定架构,我们将其与现有的用于多类分割的现成FCN VoxResNet[36]进行比较。VoxResNet已被评估用于分割大脑中的多种组织类型,但通过添加输出通道,它适用于多器官分割。
VoxResNet比VNet更类似于我们的体系结构,它使用批量标准化和校正的线性单元非线性,并将所有上采样特征组合在一起,而不是在每个分辨率上递增。下采样子网络包括卷积单元和残差网络单元的组合。对于4个分辨率中的每一个,上采样子网络包括转置卷积,以将网络上采样到分割分辨率,然后是卷积单元;这些向上采样的logit求和以产生分割。我们使用相同的损失函数和优化协议训练VoxResNet,并应用与DenseVNet相同的后处理。
比较算法3:基于MALF的JLF
为了评估我们提出的方法相对于目前的技术水平,我们将其分割精度与现有的基于马尔夫的方法[34],[35],简称为JLF进行比较。首先,使用密集位移采样(DITEDS)将训练数据中的地图集图像配准到输入图像中[34]。然后,使用联合标签融合(JLF)[35]对转换后的参考标签进行组合。在仿射变换下,契约最小化自相似上下文度量,然后在基于扩散的正则化的自由形式变形下,使用离散化搜索空间。在6种公开可用算法的直接比较中,契约显示出最高的配准精度[15]。联合标签融合计算变换标签的加权平均值,其中权重是atlas图像和目标图像之间图像相似性的函数,用于补偿atlas图像之间的相关性。在BTCV分割挑战中,契兹和JLF的组合实现了最高的精确度[16]。契约和JLF计算使用公开的deedsRegSSC进行(http://www. mpheinrich.de/software.html)和PICSL Multi-Atlas分割工具(https://www.nitrc.org/projects/PICSL_-malf)的实现,分别使用已发布的契约腹部CT配准参数[15]和JLF的默认参数。分割后处理与DenseVNet相同。
二次分析:架构特征
为了分离和量化所提出架构的每个元素的贡献,我们进行了一系列“消融”实验,其中我们改变了架构的关键概念:密集特征堆栈、V型网络结构、铰链损耗、扩展卷积、空间先验、批式空间衰减、蒙特卡罗推断,和感受野大小。
为了评估密集特征堆栈,我们将DenseVNet与具有规则层间连接的变体进行了比较:NoDenseLow,其中密集特征堆栈被替换为规则卷积单元堆栈(每个单元仅连接到其前一个单元),具有与DenseVNet相同数量的通道,但可训练参数计数较低(由于连接性);NoDenseHigh,具有常规卷积单元堆栈,但有更多通道(12、24和48)以匹配DenseVNet的参数计数。
评估V-Network网络结构具有挑战性,因为它会产生几个特性:多尺度的表征、增加的层数、更大的感受野大小、更多的通道和更多可学习的参数。因为这些属性相互作用,所以在保持其他属性不变的情况下单独操纵它们是不可行的。相反,我们通过将我们的四分辨率网络与3个备选方案进行比较,来综合评估这些因素:ShallowV,具有三个分辨率(1443、723和363);NoVLow,只有两个分辨率(1443和723)和相应的低可训练参数计数;NoVHigh,具有两个分辨率,但每个卷积有更多通道(跳过连接中的nf=35和75特征),以匹配DenseVNet的参数计数。
为了评估铰链损失、扩展卷积、显式空间先验、批量空间丢失,我们将我们的网络与四个相应的备选网络进行了比较。
- 铰链损耗:用更简单的Dice分数pDicel(L’‘l,Rl),取代铰链损耗d(pDicel(L’'l, Rl),i)的网络, 缩写为NoHinge。
- 扩张卷积:每个扩张卷积都被标准的3×3×3卷积所取代的网络,缩写为NoDil。
- 显式空间先验:省略空间先验层的网络,缩写为NoPrior。
- 批处理空间丢失:在概率为0的密集特征堆栈中,使用标准伯努利分布通道空间丢失[40]的网络。5,缩写为NoBSDO。
为了评估蒙特卡罗推理,使用了经过训练的DenseVNet,但使用所有特征进行推理,没有中途退出;这些结果缩写为Deterministic。
为了进一步评估感受野大小的影响,我们将我们的网络与无扩张卷积的ShallowV结构(缩写为NoDilShallowV)网络进行了比较。
在这些实验中,批大小从10减少到8,这样就可以使用相同的批大小直接比较DenseVNet和内存效率较低的NoBSDO。
Results
初步分析:算法比较
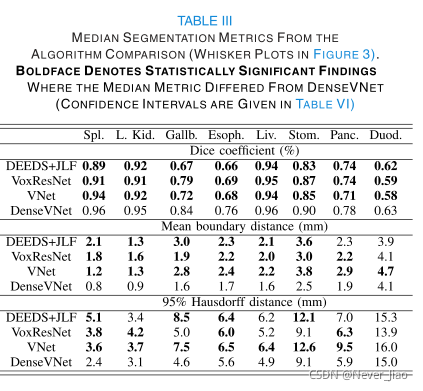
对于算法比较,表III中报告了每个器官的分割评估指标的中间值,图3中分别显示了胡须图。图2所示为Dice得分第25、50和75百分位的代表性分割。
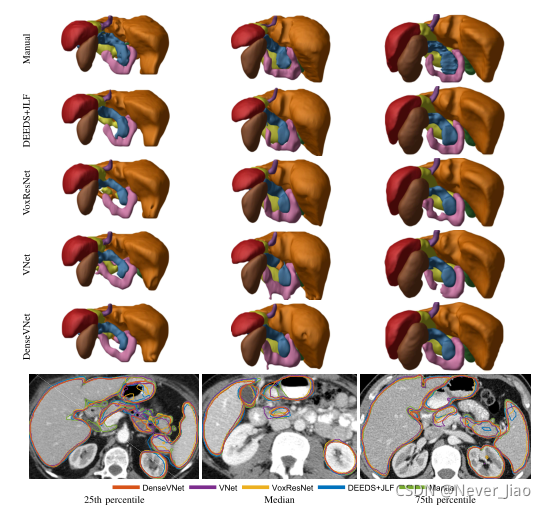
图2 Top:Dice评分最接近第25、50和75百分位的三名患者的分割后视图:胰腺(青色)、食道(紫色)、胃(黄色)、十二指肠(粉红色)、肝脏(橙色)、脾脏(红色)、左肾(棕色)和胆囊(绿色)。底部:重叠在CT上的分割。
不包括十二指肠(下文讨论),拟定网络的Dice得分高于VNet、V-oxResNet和契兹JLF(均具有统计学意义)和较低的平均边界距离(除契兹JLF胰腺分段外,均具有统计学意义)。95%的Hausdorff距离具有更高的可变性,可能是由于95%分位数的鲁棒性较差;因此,虽然在20/21的比较中,所提出的方法具有较低的观察距离,但差异仅在15/21中达到统计学意义。
对于所有算法和所有指标而言,十二指肠分割的准确性最低。DenseVNet的Dice得分高于其他算法,平均边界距离低于VNet,但其他比较无统计学意义。虽然部分原因是由于患者间解剖变异较大以及与远端肠道的图像对比度较差而导致变异性较大,但观察到的中位准确度指标差异通常小于其他器官。
二次分析:架构特征
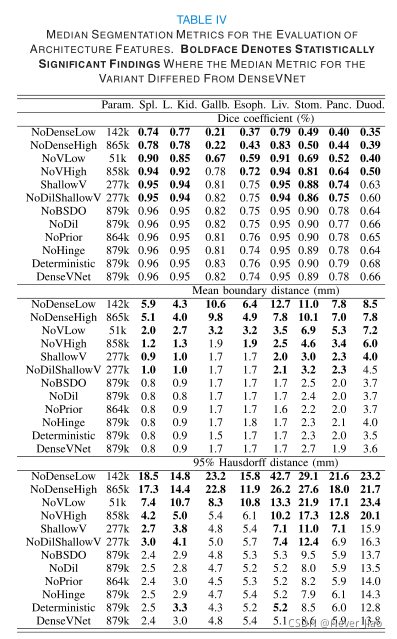
对于结构特征的评估,表IV中报告了每个器官的分割评估指标的中间值。在任何比较中,消除扩张卷积和显式空间先验时的准确性差异均无统计学意义。对于大多数器官,消除间歇式空间缺失或V-Network结构的一个下采样单元,所有指标的准确度都有小的损失,但对于最小的器官胆囊或食道(平均体素的0.17%和0.09%)的差异不显著。消除密集连接或完全消除V-Network网络会导致所有比较的准确度大大降低。
Discussion
本文提出了一种基于无配准深度学习的腹部CT多器官分割算法。为了便于内镜胰胆管介入术中的术中导航,将8个器官进行了分割:胰腺、内镜导航的胃肠道的3个器官(食道、胃和十二指肠)以及用作导航标志的4个邻近器官(肝、胆、脾和左肾)。
临床上可接受的分割精度尚未定义用于指导腹部干预,并取决于干预和指导系统。然而,胰腺(包含临床上重要的靶点)和胃肠道(内窥镜导航的地方)的准确性提高应优先于导航标志,因为内窥镜可以无精确边界定位。
将我们提出的方法与两种现有的基于深度学习的方法和一种最新的基于MALF的方法进行直接比较,结果表明,所有八个器官的重叠都得到了改善,其中七个器官的边界精度得到了提高。最大的改善是最小的器官(胆囊和食道)。这可能部分是由于在为MALF配准小器官时遇到的挑战,而无需配准的方法可以避免这一挑战,部分是由于DenseVNet中更深层的高分辨率功能。十二指肠的分割精度远低于其他器官,但有趣的是,这四种算法的分割精度非常相似。FCN方法也被发现更快(确定性推理小于1s,蒙特卡罗推理为8-15s)。契兹JLF每对配准花了60秒和融合80个配准地图集的标签花了78分钟。虽然这些时间不会成为全自动分割临床工作流程的限制因素,但深度学习方法足够快,可以用于更精确的半自动分割。
以往的许多研究都提出了腹部CT多器官分割的方法。许多这些研究都包括了一些必需的器官(胰腺、肝脏、肾脏和脾脏);然而,胃肠道分割受到的关注要少得多。只有另外一项研究[18]报道了十二指肠分割(与胃合并为单一分割)。将分割精度与以前的文献进行比较具有挑战性;由于数据集大小、成像协议和质量以及参考分割协议和质量的不同,定量度量不能直接进行比较。尽管如此,表V显示了许多已报道方法中分割器官的平均骰子分数。在大多数以前的工作和我们提出的方法中,肝、脾和肾的分割总是比其他解剖学产生更高的Dice评分。在这些器官上,许多节段产生节段,Dice评分在最高报道分数的0.02以内(我们的脾脏,Hu等人[19]用于左肾和左肝)。考虑到数据的可变性,这些差异不太可能在统计上或有意义地不同。其他器官的分割精确度变化更大。值得注意的是,Cerrolaza等人[5]据报道,胆囊、胃和胰腺分割的准确率最高,但通常非常精确的器官分割(脾、左肾和肝脏)的准确率要低得多。我们的方法对脾、食管、胃和胰腺的平均Dice得分最高,对肝和左肾的平均Dice得分在0.02以内。然而,胆囊的平均Dice评分低于其他几种方法,具有高度的偏态分布(Dice评分的中位数为0.84,但13/84的评分低于0.50)。这可能是因为我们的数据集中有6名患者没有胆囊;虽然这些患者的胆囊节段被排除在得分之外,但它们被包括在训练数据中,可能影响了训练。
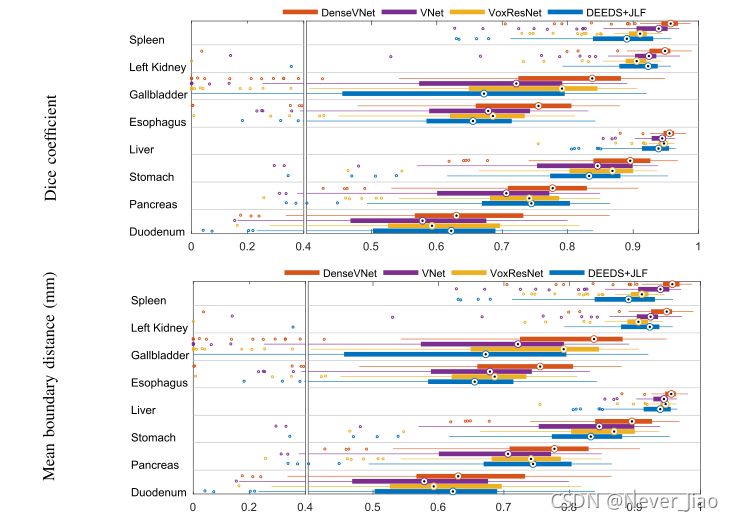
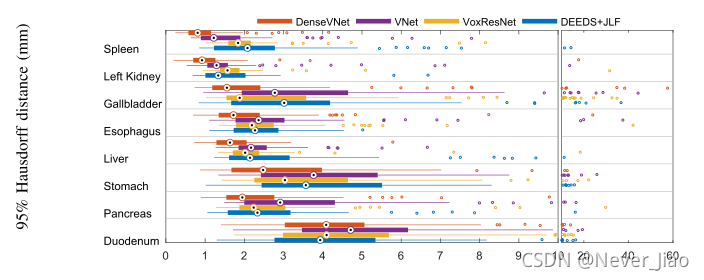
图3.用于算法比较的分割度量的框图和胡须图。方框显示第25到75个百分位数,胡须显示1.5个四分位数范围内的内部值,标记显示超出该范围的异常值。Dice分数越高越好,距离分数越低越好。
体系结构实验确定了两个对分割精度至关重要的特征:密集的连接和多尺度的V-Network结构显着提高了性能。首先,密集连接产生了最大的改善。NoDenseHigh和NoDenseLow之间相对较小的差异表明,这种改进不是由于额外的可训练参数,而是由于支持梯度传播和特征重用的连接结构。其次,具有多尺度V-Network结构的四分辨率DenseVNet的性能优于不具有多尺度V-Network结构的两分辨率NoVLow网络。其中一些差异可以归因于可训练参数较少,因为NoVHigh根据器官的不同恢复了38%-82%的差异;然而,NoVHigh的表现仍然远远逊于DenseVNet。DenseVNet与三分辨率ShallowV相比,对大多数器官产生了显著但非常小的改善,这表明即使是最小的多尺度结构也能提供绝大多数的好处。尽管多尺度网络的一个据称的优势是网络的感受野更大,但是ShallowV和NoDilShallowV产生了非常相似的性能,其中接受野覆盖了图像的50%-100%,而NoDilShallowV则覆盖了图像的5%-50%,这表明精确分割整个图像并不是必需的。
为了避免由于在多个变量中选择最好的变量来进行基线比较而导致的性能估计偏差,算法比较的网络结构是先验指定的。它包括以下特征,其中观察到的准确性差异没有达到统计学意义:扩张卷积,明确的空间先验,和铰链丢失。这表明DenseVNet可以省略这些功能,而对分割性能的影响最小。此外,我们省略了这些功能的实验给出了以下有关体系结构内信息传播的见解。扩张的卷积增加了网络早期特征的感受野,特别是高分辨率特征;高分辨率特征的感受野覆盖了有扩张卷积的网络中图像的一半,而没有扩张卷积的特征覆盖了网络中不到四分之一的图像。没有膨胀卷积的小性能差异表明,高分辨率全局信息或者在网络中较晚合并,或者对于实现观察到的分割精度是不必要的。我们的空间先验编码了体素标签概率,适用于粗对齐的图像(通过标准化采集或预处理)。我们的结果表明,当排除先验信息时,这种简单的空间信息可以隐含地编码在学习特征中,可能使用来自附近器官或图像边界伪像的特征。然而,编码全局依赖性的空间先验形式,例如拓扑[30]或形状表示[29]损失函数,仍然可以提高性能,并且值得研究。为了在不影响性能的情况下降低存储成本,引入了两个特性:批量空间丢弃和蒙特卡罗推断。在46/48的比较中,这些增加的差异没有达到统计学意义。我们的研究结果表明,DenseVNet实现中应该使用批量空间丢弃,并且可以根据内存或计算时间限制来选择推理方法。
虽然我们的实验主要集中在网络体系结构上,但数据管道也包括前处理和后处理。首先,为了限制记忆,图像被手动裁剪到腹腔。充分改变测试数据的裁剪协议(即,超出数据增强所产生的可变性)会影响分割精度。具体地说,当裁剪区域在每个轴向外调整5%(在数据增强变异性之外)时,Dice分数下降0.03±0.06(均值±SD);而当测试数据上的裁剪区域向外调整5%(在数据增强变异性内)时,Dice分数变化0.00±0.04。这表明数据增强变异性应该涵盖预期的作物变异性。其次,对数据进行后处理,滤除小的假阳性区域,平滑地对分割区域进行上采样。在事后比较中,去掉连通分量滤波器或使用双线性上采样而不是平滑上采样方案对分割性能的影响通常最小,中值Dice、MAD和Hausdorff距离分数的变化分别小于0.005.1 mm、0.1 mm和1.1 mm。
我们的结论有一定的局限性。在算法开发过程中,作者不会对手动分割视而不见;虽然交叉验证仅在算法开发完成后才运行,但设计决策可能已受到数据观察的影响。FCN方法的算法参数没有针对这一应用进行广泛的优化;DenseVNet、VNet和VoxResNet方法的报告性能可能低估了它们的潜在性能。统计比较考虑了每一折内的相关性,而不是由于训练数据的部分重叠而导致的折之间的相关性;对不相交的数据集进行独立评估将是有价值的。评估指标用手册参考来衡量分割的保真度,而不是所得到的分割用于辅助内窥镜导航的临床实用性;未来的工作将评估所提出的算法是否足够准确,以提供针对患者的3D解剖模型来辅助内窥镜导航。
综上所述,本文提出的基于深度学习的DenseVNet能够比以往使用深度学习或多图谱标签融合的方法更准确地分割胰腺、食道、胃、肝、脾、胆囊、左肾和十二指肠。密集的连接层和浅的V-Network结构对该网络的分割精度至关重要。扩张卷积的使用是不必要的,这表明全局高分辨率非线性特征对于腹部CT器官分割不是关键。显式空间先验的使用也是不必要的,这表明卷积神经网络隐含地编码空间先验,尽管据称它们具有平移不变性。腹部解剖自动生成的节段有可能在胰胆内窥镜检查过程中支持图像引导导航。

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









