







引言
在现代人工智能技术中,RAG(Retrieval-Augmented Generation)系统正在为丰富文本生成和信息检索提供强有力的支持。传统的RAG系统主要依赖文本数据,利用文档和文本数据库来增强大语言模型(LLM)的上下文。然而,随着多模态数据(包括图像、音频、视频等)的日益普及,如何将多模态数据整合到RAG系统中,成为提升系统能力的重要课题。
RAG系统与多模态RAG的区别
传统RAG系统主要通过检索文本数据来增强生成任务的上下文。其流程通常包括以下步骤:
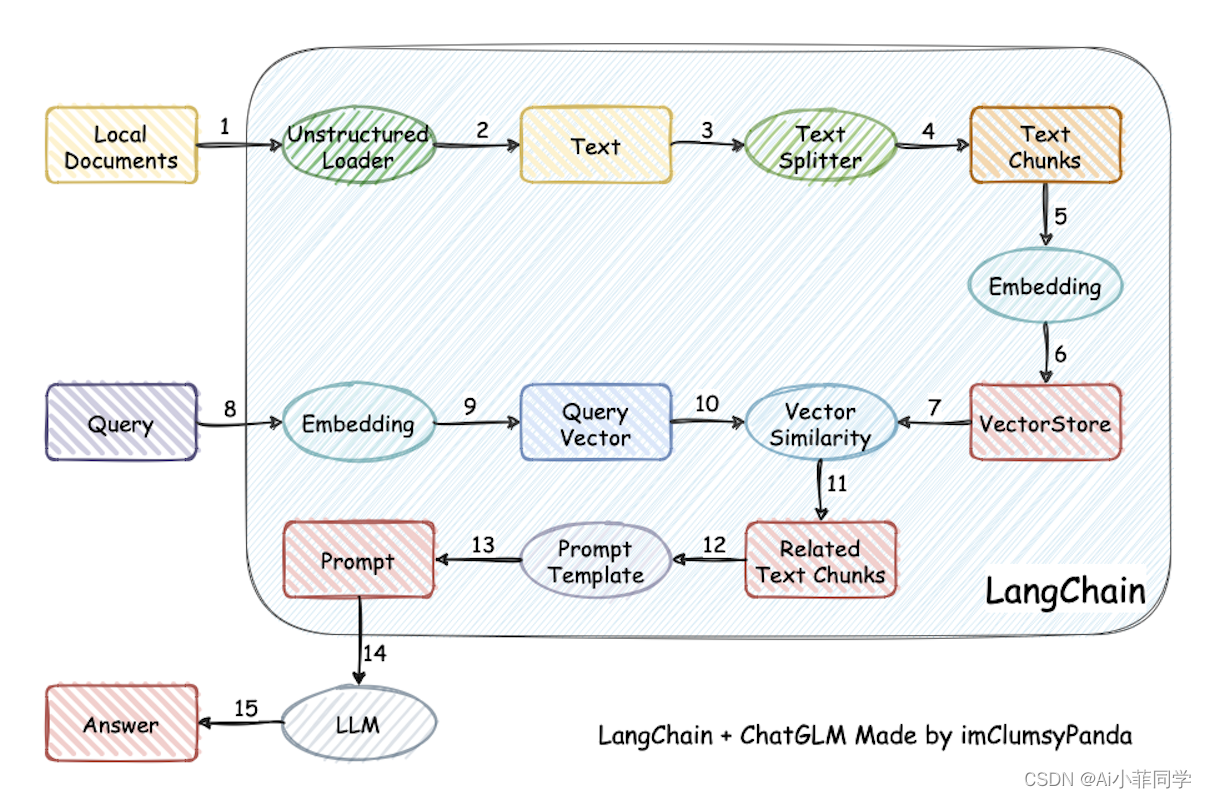
- 文档检索:根据输入查询在文本数据库中检索相关文档。
- 上下文整合:将检索到的文本信息整合到LLM的生成任务中。
- 答案生成:LLM基于文本上下文生成输出内容。
多模态RAG系统则在此基础上,扩展到对多种模态数据的处理:
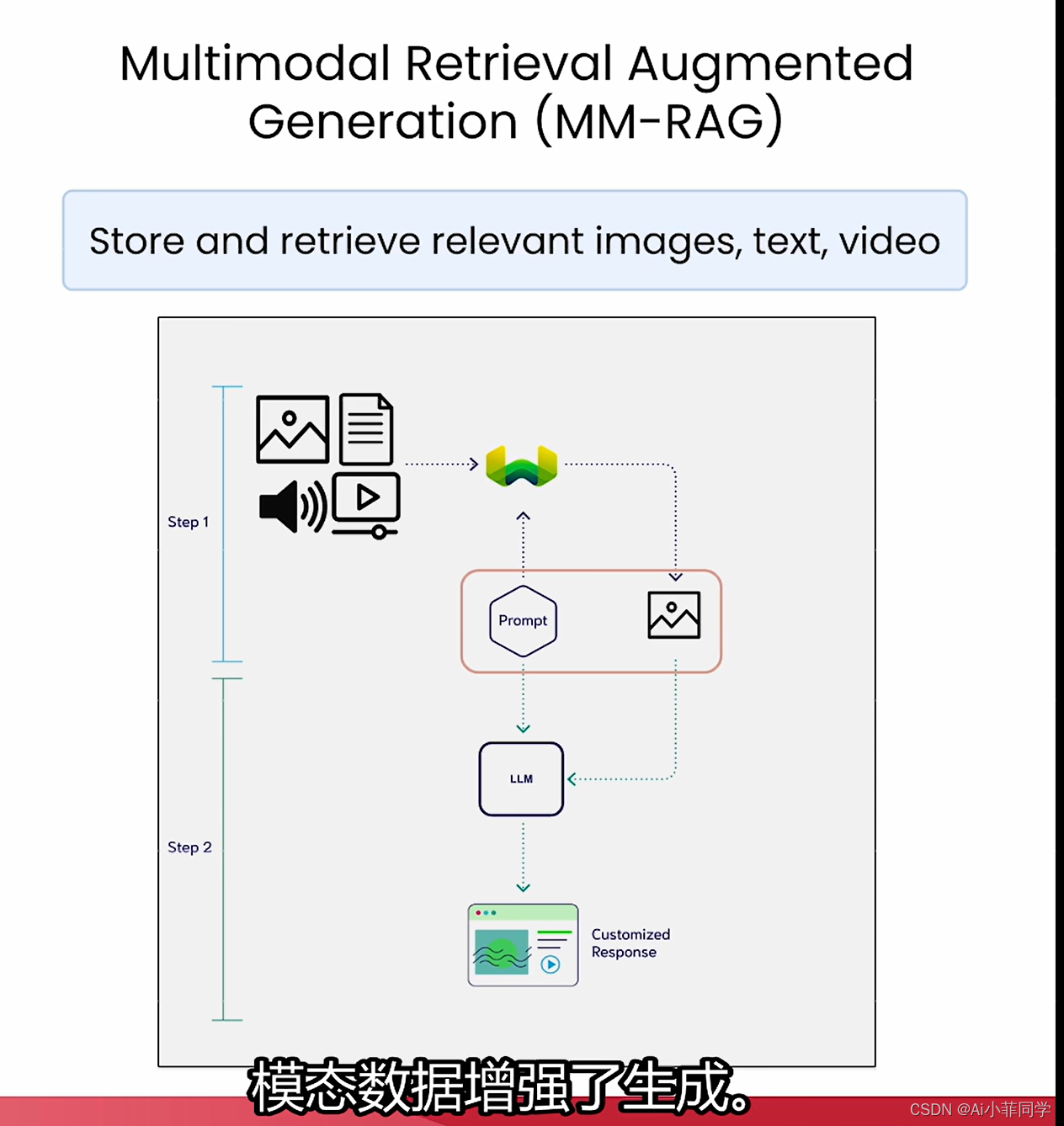
- 多模态检索:不仅检索文本,还包括图像、音频、视频等不同模态的数据。
- 上下文融合:将不同模态的上下文信息整合到LLM中,以提供更全面的上下文支持。
- 答案生成:LLM结合多模态上下文生成更丰富、准确的内容。
多模态RAG系统能够处理更加复杂的查询需求
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9254
9254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









